table of Contents
What is the difference between meta-learning and traditional machine learning?
What is the difference between MAML and pre-training?
2. Different optimization ideas
The advantages and characteristics of MAML
Basic understanding
Meta Learning, translated as meta learning, can also be regarded as learn to learn.
What is the difference between meta-learning and traditional machine learning?
Knowing that the blogger "South You Qiaomu" is understanding meta-learning and traditional machine learning. Here is an easy-to-understand example to share with you:
The training algorithm is analogous to the student's learning in school. The traditional machine learning task corresponds to training a model on each subject , while meta-learning is to improve the student's overall learning ability and learn to learn .
In schools, some students have good grades in all subjects, but some students have partial subjects.
- Good grades in all subjects indicate that students have strong " meta-learning" abilities , have learned how to learn, and can quickly adapt to the learning tasks of different subjects.
- Partial subject students ’ "meta-learning" ability is relatively weak , and they can only achieve good results in a certain subject, and they cannot change subjects. Will not draw inferences by analogy.
The deep neural networks that are often used now are all "partial students". The network models corresponding to classification and regression are completely different. Even if it is the same classification task, the network architecture of face recognition may not be able to achieve very good results. High accuracy rate.
There is one more difference:
- Traditional deep learning methods are learning from scratch (training) , that is, learning from scratch, which consumes more computing power and time.
- Yuan stressed that learning from a number of different small tasks small sample to learn a sample of the unknown unknown category has good judgment and generalization of the model
Basic idea
Written in front: The pictures are all from the teaching video of teacher Li Hongyi
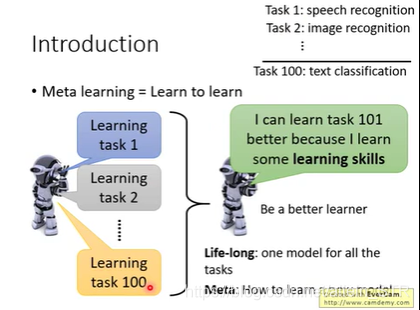
Explanation of Figure 1:
Meta learning, also known as learn to learn, means to let the machine "learn to learn" and have the ability to learn.
The training samples and test samples of meta-learning are task-based. Train models through different types of tasks , update model parameters, master learning skills, and then learn other tasks better . For example, task 1 is speech recognition, task 2 is image recognition,..., task 100 is text classification, task 101 is different from the previous 100 tasks, the training task is these 100 different tasks, and the test task is the first 101 tasks.
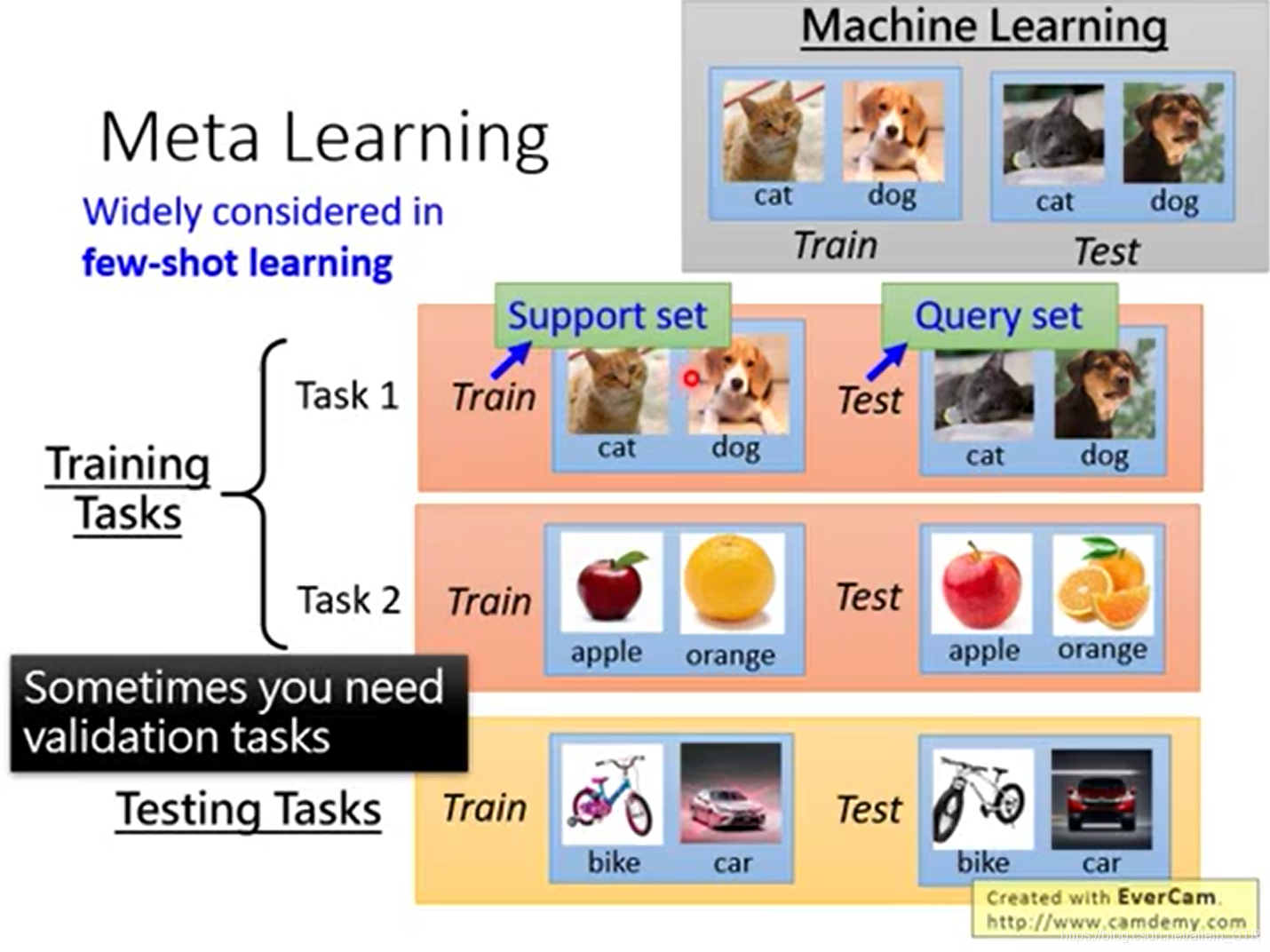
Explanation of Figure 2:
In machine learning, the training set in the training sample is called the train set, and the test set is called the test set. Meta-learning is widely used in small-sample learning. In meta-learning, the training set in the training sample is called the support set, and the test set in the training sample is called the query set.
Note: In machine learning, there is only one large sample data set. This large data set is divided into two parts, called train set and test set;
But in meta-learning, there is more than one data set. There are as many data sets as there are different tasks. Then each data set is divided into two parts, called support set and query set.
The validation set is not considered here.

Explanation of Figure 3 :
Figure 3 shows the operation of traditional deep learning, namely:
- Define a network architecture;
- Initialization parameters
- Update the parameters through the optimizer of your choice ;
- Update parameters through two epochs;
- Get the final output of the network .
Where is the connection between meta-learning and traditional deep learning?
The things in the red box in Figure 3 are all defined by human design, which is what we often call "hyperparameters", and the goal of meta-learning is to automatically learn or replace the things in the box. Different alternatives are invented Different meta-learning algorithms .

Explanation of Figure 4:
Figure 4 briefly introduces the principle of meta-learning.
In the neural network algorithm, it is necessary to define a loss function to evaluate the quality of the model. The loss of meta-learning is obtained by adding the test losses of N tasks. The test loss defined on the nth task is ![]() , then for N tasks, the total loss is
, then for N tasks, the total loss is ![]() , which is the optimization goal of meta-learning.
, which is the optimization goal of meta-learning.
Suppose there are two tasks, Task1 and Task2. Through training task 1, the loss function l1 of task 1 is obtained. Through training task 2, the loss function l2 of task 2 is obtained. Then the loss functions of these two tasks are added to obtain the whole The loss function of the training task is the formula in the upper right corner of Figure 4.
If the previous article does not have enough understanding of meta-learning, there is a more detailed explanation later:
There are many algorithms for Meta Learning. Some high-level algorithms can output different neural network structures and hyperparameters for different training tasks, such as Neural Architecture Search (NAS) and AutoML. Most of these algorithms are quite complex, and it is difficult for us ordinary people to implement. Another Meta Learning algorithm that is easier to implement is the MAML and Reptile described in this article. They do not change the structure of the deep neural network, but only change the initialization parameters of the network.
MAML
To understand the meaning and derivation process of the loss function of the MAML algorithm, we must first distinguish it from pre-training.
Explanation of Figure 5:
We define the initialization parameter as ![]() , the initialization parameter is
, the initialization parameter is ![]() , the model parameter after training on the nth test task is defined as
, the model parameter after training on the nth test task is defined as ![]() , so the total loss function of MAML is
, so the total loss function of MAML is ![]() .
.

What is the difference between MAML and pre-training?
1. Different loss functions
The loss function of MAML is ![]() .
.
The loss function of pre-training is ![]() .
.
The intuitive understanding is that the loss measured by MAML is the test loss after task training , while pre-training is to calculate the loss directly on the original basis without training . As shown in Figure 6.

2. Different optimization ideas
Let me first share the most appropriate description of the loss function I have seen: ( https://zhuanlan.zhihu.com/p/72920138 )
The mystery of the loss function: the initialization parameters control the audience, and the task parameters are independent


As shown in Figure 7 and Figure 8:
In the above figure, the abscissa represents the network parameters, and the ordinate represents the loss function. The light green and dark green curves represent the change curve of the loss function of the two tasks with parameters.
Assuming that the ![]() sum
sum ![]() vector of model parameters is one-dimensional,
vector of model parameters is one-dimensional,
The original intention of model pre-training is to find a state ![]() that minimizes the sum of losses of all tasks from the beginning . It does not guarantee that all tasks can be trained to the best
that minimizes the sum of losses of all tasks from the beginning . It does not guarantee that all tasks can be trained to the best ![]() . As shown in the figure above, it converges to the local optimum . It can be seen from Figure 7 that the loss value reached the minimum according to the calculation formula
. As shown in the figure above, it converges to the local optimum . It can be seen from Figure 7 that the loss value reached the minimum according to the calculation formula ![]() , but at this time the task2 (light green) line can only converge to the green point on the left, that is, the local minimum, and from the overall perspective, the global minimum
, but at this time the task2 (light green) line can only converge to the green point on the left, that is, the local minimum, and from the overall perspective, the global minimum ![]() Appears on the right.
Appears on the right.
The original intention of MAML is to find an unbiased ![]() , so that whether it is on the loss curve of task 1 or the loss curve of task 2, it can drop to the respective global optimal . FIG 8 is seen from, Loss value is calculated according to the minimum value reached
, so that whether it is on the loss curve of task 1 or the loss curve of task 2, it can drop to the respective global optimal . FIG 8 is seen from, Loss value is calculated according to the minimum value reached ![]() at this time, may converge to Task1 green dot at the left, at the right Task2 may converge to the green dot, both of which are global minimum.
at this time, may converge to Task1 green dot at the left, at the right Task2 may converge to the green dot, both of which are global minimum.
Teacher Li Hongyi gave a very vivid analogy here: He compares MAML to choosing to study for a PhD, that is, he is more concerned about the future development potential of students; and model pre-training is equivalent to choosing to graduate and go directly to a big factory. Cash out the skills you learned right away, caring about how you perform right now. As shown in Figure 9.

The advantages and characteristics of MAML
As shown in Figure 10: MAML
- Fast calculation
- All update parameter steps are limited to one, namely one-step
- When using this algorithm, it can be updated more times when testing the performance of a new task .
- Suitable for situations with limited data

MAML working mechanism
In the paper introducing MAML, the algorithm given is shown in Figure 11:

A detailed explanation of each step is given below: Reference ( https://zhuanlan.zhihu.com/p/57864886 )
- Require1: task distribution, that is, randomly select several tasks to form a task pool
- Require2: The step size is the learning rate. MAML is based on a double gradient. Each iteration includes two parameter update processes, so there are two learning rates that can be adjusted.
- Randomly initialize the parameters of the model
- Cycle, can be understood as an iterative process or an epoch
- Randomly sample several tasks to form a batch.
- Loop through each task in the batch
- Use the support set in a task in the batch to calculate the gradient of each parameter. Under the setting of N-way K-shot, there should be NK in the support set . (N-way K-shot means there are N different tasks, and each task has K different samples).
- The first gradient update.
- End the first gradient update
- The second gradient update. The sample used here is query set. After step 8 is over, the model ends the training in the batch, starts to return to step 3, and continues to sample the next batch.
There is a more intuitive diagram of the MAML process:

The interpretation of Figure 12 is:

MAML application: Toy Example
The goal of this toy example is to fit a sine curve:, ![]() where a and b are random numbers, and each group of a, b corresponds to a sine curve, sample K points from the sine curve, and use their horizontal and vertical coordinates as a group task, the abscissa is the input of the neural network, and the ordinate is the output of the neural network.
where a and b are random numbers, and each group of a, b corresponds to a sine curve, sample K points from the sine curve, and use their horizontal and vertical coordinates as a group task, the abscissa is the input of the neural network, and the ordinate is the output of the neural network.
We hope that through learning on many tasks, we learn a set of initialization parameters of the neural network, and then input the K points of the test task, after fast learning, the neural network can fit the sine curve corresponding to the test task.

On the left is the initialization of neural network parameters using the conventional fine-tune algorithm. We observe that when the sum of the loss functions of all training tasks is used as the total loss function to directly update the network parameters ![]() , no matter what coordinates are input to the test task, the predicted curve is always the curve near 0, because a and b can be arbitrary Set, so all possible sine functions add up, and their expected value is 0. Therefore, in order to obtain the global minima of the sum of the loss functions of all training tasks, the neural network will output 0 regardless of the input coordinates.
, no matter what coordinates are input to the test task, the predicted curve is always the curve near 0, because a and b can be arbitrary Set, so all possible sine functions add up, and their expected value is 0. Therefore, in order to obtain the global minima of the sum of the loss functions of all training tasks, the neural network will output 0 regardless of the input coordinates.
On the right is the network trained by MAML. The initial result of MAML is a green line, which is different from the orange line. But as the finetuning progressed, the result was closer to the orange line.
In response to the MAML introduced earlier, a question is raised:
When updating the network of the training task, only one step is taken, and then the meta network is updated. Why is it one step, can it be multiple steps?
Teacher Li Hongyi's course mentioned:
-
Only update once, the speed is faster ; because in meta learning, there are many subtasks, all of which are updated many times, and the training time is longer.
-
The initialization parameters that MAML hopes to get are effective when finetuning in a new task . If you update it only once, you can get good performance on the new task. Treating this as a goal can make meta network parameter training very good (the goal is consistent with the demand).
-
When initialization parameters to specific tasks, but also to finetuning many times .
-
Few-shot learning tends to have less data .
Reptile
Reptile is similar to MAML, and its algorithm diagram is as follows:

In Reptile, every time ![]() it is updated , it needs to sample a batch task (batchsize=1 in the figure), and apply multiple gradient descents on each task to obtain the corresponding task
it is updated , it needs to sample a batch task (batchsize=1 in the figure), and apply multiple gradient descents on each task to obtain the corresponding task ![]() . Then calculate the difference vector with
. Then calculate the difference vector with ![]() the parameters
the parameters ![]() of the main task as the update
of the main task as the update ![]() direction. Iterate repeatedly in this way, and finally get the global initialization parameters.
direction. Iterate repeatedly in this way, and finally get the global initialization parameters.
The pseudo code is as follows:


In Reptile:
-
The training task network can be updated multiple times
-
reptile no longer calculates the gradient like MAML (thus it brings improvement in engineering performance), but directly
 updates the meta network parameters by multiplying a parameter by the difference between the meta network and the network parameters of the training task
updates the meta network parameters by multiplying a parameter by the difference between the meta network and the network parameters of the training task -
From the effect point of view, Reptile effect is basically the same as MAML
The above is an in-depth understanding of meta-learning. MAML mathematical formula derivation may follow. Interested readers will leave a message~
Reference
[1] https://zhuanlan.zhihu.com/p/72920138
[2] https://zhuanlan.zhihu.com/p/57864886
[3] https://zhuanlan.zhihu.com/p/108503451
[4] MAML paper https://arxiv.org/pdf/1703.03400.pdf
【5】 https://zhuanlan.zhihu.com/p/136975128