Memory physical structure
Let's take a look at the physical structure of the memory, the general image of the memory is as follows:

Figure 1 Memory outline
A memory is composed of several black memory particles. Each memory particle is called a chip. Each chip is composed of 8 banks. Its structure is as follows:

Figure 2 Internal structure of chip
Each bank is a matrix on a two-dimensional plane, as we mentioned in the previous article. Each element in the matrix stores 1 byte, which is 8 bits.
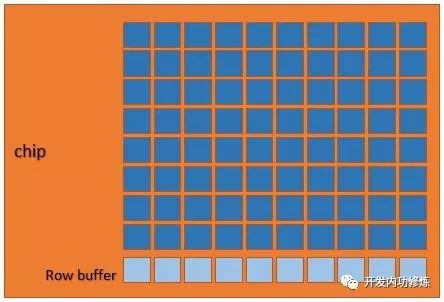
Figure 3 Bank internal structure
Memory addressing method
So for the 8 bytes with consecutive addresses in the memory in our application, such as 0x0000-0x0007, are they located on the bank? Intuitively, should it be on the first bank? In fact, it is not. From the programmer's point of view, the consecutive addresses 0x0000-0x0007 are actually located in 8 banks, and each bank only stores one byte. Physically, they are not continuous. The picture below illustrates the actual situation well.
Figure 4 The actual distribution of continuous 8 bytes in the memory
You may be wondering why this is because the circuit works efficiently. The 8 banks in the memory can work in parallel. If you want to read addresses 0x0000-0x0007, each bank will work once, and the data will be the data you want together, and the IO efficiency will be higher. But if you want to store it in a bank, then the bank can only do its own work. It can only be read serially, and it needs to be read 8 times, which will be much slower.
in conclusion
Therefore, the bottommost reason for memory alignment is that memory IO is performed in units of 8 bytes and 64 bits. For a memory with a 64-bit data width, if the cpu is also a 64-bit cpu (this is basically the case in computers nowadays), each time the memory IO gets data, it reads a byte from each of the 8 banks in the same column and puts it together. of. Starting from address 0 of the memory, the data of 0-7 bytes can be read out by IO at one time, and the data of 8-15 bytes can also be read out at one time.
For another example, if you specify that you want to get 0x0001-0x0008, which is also 8 bytes, but does not start with 0, how does the memory work? There is no good way, the memory has to work once to take out 0x0000-0x0007, and then take out 0x0008-0x0015, and return the results of both times to you. The hardware limitations of CPU and memory IO make it impossible to perform IO in the middle of two data widths at once. In this way, your application program will slow down, which can be regarded as a small penalty for the computer because you don't understand memory alignment.
Extension 1: In fact, the compiler and linker will automatically align the memory for the developer, try to help you ensure that a variable does not cross-column addressing. But he can't be perfect.
Extension 2: In fact, on the memory hardware layer, there is also the operating system layer. The operating system also manages the primary, secondary, and tertiary caches of the CPU. I don't know if you have any impressions. Our previous article said that the Cache Line in the cache is 64 bytes, which is 8 times the memory IO unit, which will not waste memory IO.