Introduction: Cloud Native Community Activity ---Analysis of Kubernetes Source Code Phase One and Week Two
This week is the second week of the first phase of the K8S Source Code Research Institute. The content of learning is to learn the Informer mechanism. This article will start with this topic.
The president of the study club was very busy this week. I postponed this course until the end of the next week. Everything is the same. The plan may be broken by other things, but in the end, as long as it can return to the corresponding main line, it is nothing. problem. Just like participating in open source, the initial open source is just the beginning, what you need is to be able to persist, and this is often very important.
Okay, let's start the text.
Topic of this article:
- Overview of Informer mechanism architecture design
- Reflector understanding
- DeltaFIFO understanding
- Indexer understanding
If the content of resources is involved, this article uses Deployment resources to describe the relevant content.
Overview of Informer mechanism architecture design
Below is a data flow diagram that I drew based on my understanding, and look at the overall trend of the data from a global perspective.
The dotted lines represent the methods in the code.
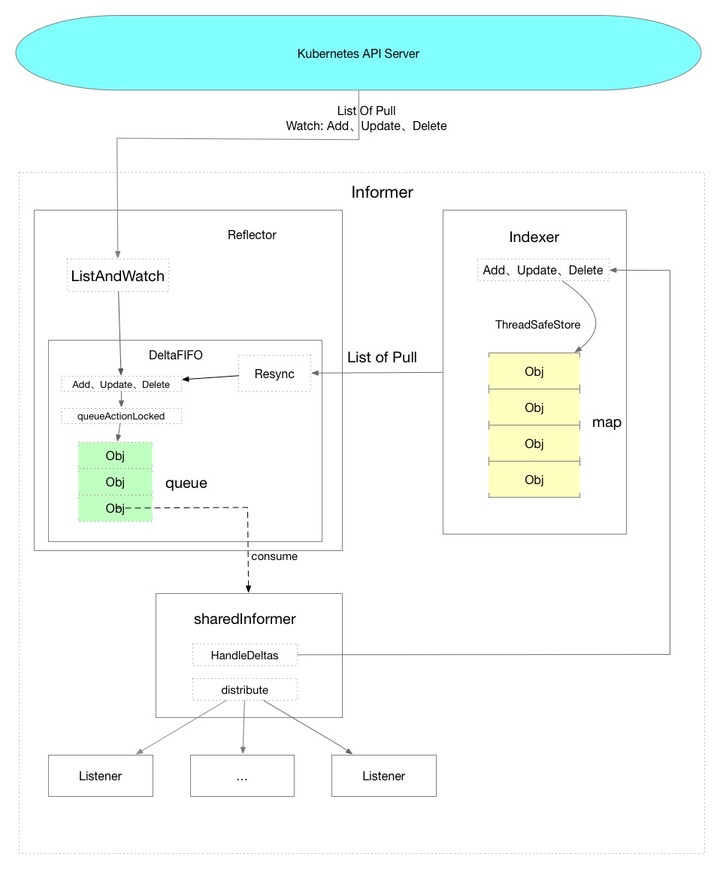
Let me talk about a conclusion:
In the case of obtaining data through the Informer mechanism, all Objects corresponding to the Resource will be obtained from the Kubernetes API Server during initialization, and then only the data pushed by the API Server will be received through the Watch mechanism, and data will not be actively pulled from the API Server. Directly use the data in the local cache to reduce the pressure on the API Server.
The Watch mechanism is based on the HTTP Chunk implementation and maintains a long connection, which is an optimization point to reduce the amount of requested data. The second optimization point is SharedInformer, which allows the same resource to use the same Informer. For example, when the v1 version of the Deployment and the v1beta1 version of the Deployment exist at the same time, they share the same Informer.
In the above figure, you can see that Informer is divided into three parts, which can be understood as three major logics.
Among them, Reflector mainly puts the data obtained from the API Server data into the DeltaFIFO queue, acting as a producer.
SharedInformer mainly obtains data from the DeltaFIFIO queue and distributes the data, acting as a consumer.
Finally, Indexer exists as a storage component of the local cache.
Reflector understanding
In Reflector, it is enough to mainly look at Run, ListAndWatch, and watchHandler.
The source code location is tools/cache/reflector.go
// Ruvn starts a watch and handles watch events. Will restart the watch if it is closed.
// Run will exit when stopCh is closed.
//开始时执行Run,上一层调用的地方是 controller.go中的Run方法
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(3).Infof("Starting reflector %v (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.Until(func() {
//启动后执行一次ListAndWatch
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
...
// and then use the resource version to watch.
// It returns error if ListAndWatch didn't even try to initialize watch.
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
// Attempt to gather list in chunks, if supported by listerWatcher, if not, the first
// list request will return the full response.
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
//这里是调用了各个资源中的ListFunc函数,例如如果v1版本的Deployment
//则调用的是informers/apps/v1/deployment.go中的ListFunc
return r.listerWatcher.List(opts)
}))
if r.WatchListPageSize != 0 {
pager.Pa1geSize = r.WatchListPageSize
}
// Pager falls back to full list if paginated list calls fail due to an "Expired" error.
list, err = pager.List(context.Background(), options)
close(listCh)
...
//这一部分主要是从API SERVER请求一次数据 获取资源的全部Object
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedTypeName, err)
}
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(li
st)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v: %v", r.name, list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion()
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
initTrace.Step("Objects extracted")
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
initTrace.Step("SyncWith done")
r.setLastSyncResourceVersion(resourceVersion)
initTrace.Step("Resource version updated")
...
//处理Watch中的数据并且将数据放置到DeltaFIFO当中
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
switch {
case apierrs.IsResourceExpired(err):
klog.V(4).Infof("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
}
}
return nil
}
...
}The data production is over, just two points:
- Request data from API Server during initialization
- Monitor subsequent data pushed from Watch
DeltaFIFO understanding
First look at the data structure:
type DeltaFIFO struct {
...
items map[string]Deltas
queue []string
...
}
type Delta struct {
Type DeltaType
Object interface{}
}
type Deltas []Delta
type DeltaType string
// Change type definition
const (
Added DeltaType = "Added"
Updated DeltaType = "Updated"
Deleted DeltaType = "Deleted"
Sync DeltaType = "Sync"
)The queue stores the id of the Object, and the items stores the event list of the Object with the ObjectID as the key.
You can imagine such a data structure, with Key on the left and an array object on the right, where each element is composed of type and obj.
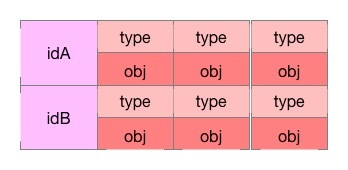
DeltaFIFO, as its name implies, is a first-in, first-out queue that stores Delta data, which is equivalent to a data transfer station, which transfers data from one place to another.
The main content is queueActionLocked, Pop, Resync
queueActionLocked method:
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
...
newDeltas := append(f.items[id], Delta{actionType, obj})
//去重处理
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
...
//pop消息
f.cond.Broadcast()
...
return nil
}Pop method:
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
//阻塞 直到调用了f.cond.Broadcast()
f.cond.Wait()
}
//取出第一个元素
id := f.queue[0]
f.queue = f.queue[1:]
...
item, ok := f.items[id]
...
delete(f.items, id)
//这个process可以在controller.go中的processLoop()找到
//初始化是在shared_informer.go的Run
//最终执行到shared_informer.go的HandleDeltas方法
err := process(item)
//如果处理出错了重新放回队列中
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
...
}
}Resync mechanism:
Small summary: Every time the data obtained from the local cache Indexer is re-placed in the DeltaFIFO to execute the task logic.
The place to start Resync is the resyncChan() method of reflector.go, and the call in the ListAndWatch method of reflector.go starts to be executed regularly.
go func() {
//启动定时任务
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
//定时执行 调用会执行到delta_fifo.go的Resync()方法
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
func (f *DeltaFIFO) Resync() error {
...
//从缓存中获取到所有的key
keys := f.knownObjects.ListKeys()
for _, k := range keys {
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}
func (f *DeltaFIFO) syncKeyLocked(key string) error {
//获缓存拿到对应的Object
obj, exists, err := f.knownObjects.GetByKey(key)
...
//放入到队列中执行任务逻辑
if err := f.queueActionLocked(Sync, obj); err != nil {
return fmt.Errorf("couldn't queue object: %v", err)
}
return nil
}SharedInformer consumption message understanding
Mainly look at the HandleDeltas method, which consumes messages and then distributes the data and stores the data in the cache
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
...
//查一下是否在Indexer缓存中 如果在缓存中就更新缓存中的对象
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
//把数据分发到Listener
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
//没有在Indexer缓存中 把对象插入到缓存中
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
...
}
}
return nil
}Indexer understanding
This section will not cover much content, because I think the most important thing about the Informer mechanism is the flow of the previous data. Of course, this does not mean that the data storage is not important, but first clarify the overall idea, and then update the stored part in detail later.
Indexer uses the threadSafeMap in threadsafe_store.go to store data. It is a thread-safe map with indexing function. The data will only be stored in memory, and each operation involved will be locked.
// threadSafeMap implements ThreadSafeStore
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
indexers Indexers
indices Indices
}Indexer also has an index-related content, so I won’t expand on it for now.
Example code
-------------
package main
import (
"flag"
"fmt"
"path/filepath"
"time"
v1 "k8s.io/api/apps/v1"
"k8s.io/apimachinery/pkg/labels"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/util/homedir"
)
func main() {
var err error
var config *rest.Config
var kubeconfig *string
if home := homedir.HomeDir(); home != "" {
kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "[可选] kubeconfig 绝对路径")
} else {
kubeconfig = flag.String("kubeconfig", filepath.Join("/tmp", "config"), "kubeconfig 绝对路径")
}
// 初始化 rest.Config 对象
if config, err = rest.InClusterConfig(); err != nil {
if config, err = clientcmd.BuildConfigFromFlags("", *kubeconfig); err != nil {
panic(err.Error())
}
}
// 创建 Clientset 对象
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err.Error())
}
// 初始化一个 SharedInformerFactory 设置resync为60秒一次,会触发UpdateFunc
informerFactory := informers.NewSharedInformerFactory(clientset, time.Second*60)
// 对 Deployment 监听
//这里如果获取v1betav1的deployment的资源
// informerFactory.Apps().V1beta1().Deployments()
deployInformer := informerFactory.Apps().V1().Deployments()
// 创建 Informer(相当于注册到工厂中去,这样下面启动的时候就会去 List & Watch 对应的资源)
informer := deployInformer.Informer()
// 创建 deployment的 Lister
deployLister := deployInformer.Lister()
// 注册事件处理程序 处理事件数据
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: onAdd,
UpdateFunc: onUpdate,
DeleteFunc: onDelete,
})
stopper := make(chan struct{})
defer close(stopper)
informerFactory.Start(stopper)
informerFactory.WaitForCacheSync(stopper)
// 从本地缓存中获取 default 命名空间中的所有 deployment 列表
deployments, err := deployLister.Deployments("default").List(labels.Everything())
if err != nil {
panic(err)
}
for idx, deploy := range deployments {
fmt.Printf("%d -> %sn", idx+1, deploy.Name)
}
<-stopper
}
func onAdd(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("add a deployment:", deploy.Name)
}
func onUpdate(old, new interface{}) {
oldDeploy := old.(*v1.Deployment)
newDeploy := new.(*v1.Deployment)
fmt.Println("update deployment:", oldDeploy.Name, newDeploy.Name)
}
func onDelete(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("delete a deployment:", deploy.Name)
} In the above example code, the program will pull the Deployment data once after it is started, and after the data is pulled, list the Deployment resources in the default namespace from the local cache and print them, and then Resync the Deployment resources every 60 seconds.
QA
Why do we need Resync?
A classmate raised one this week. After seeing this problem, I also felt very strange, because Resync is from the local cache data cache to the local cache (from the beginning to the end), why do you need to take out the data again? Go through the process? At that time, I couldn't understand it. Later I thought about it from a different angle.
The data comes from the API Server and is processed and put in the cache, but the data may not be processed normally, which means that an error may be reported, and this Resync is equivalent to a retry mechanism.
You can try to practice: Deploy a stateful service, use LocalPV for storage (you can also change to something you are familiar with). At this time, the pod will fail to start because the storage directory does not exist. Then create the corresponding directory after the pod fails to start. The pod will start successfully after a while. This is a situation I understand.
to sum up:
Informer mechanism is the cornerstone of communication between various components in K8S. A thorough understanding is very helpful. I am still in the process of further understanding. Welcome to communicate.
Pre-reading:
Originated from Four Coffee Beans , please declare the source for reprinting.
Follow the Gong Zong Number -> [Four Coffee Beans] Get the latest content