Supervised learning
Imaginary unit
xi, i = 0, 1, 2, nx x_i, i = 0,1,2, n_xxi,i=0,1,2,nx
yi, i = 0, 1, 2, ny y_i, i = 0,1,2, n_y andi,i=0,1,2,nand, Ie nx n_xnxBelong to category xxsample of x ,ny n_ynandBelong to category yyThe sample of y
learns the inherent characteristics of the data distribution through the given data labeling information. The inherent principle that this method can work is that all (to be precise, most) data under the same label have similar feature distributions.
Unsupervised learning
In Contrastive learning, most of them are unsupervised, and at this time our data set has no labels.
Learning a network under such a data set can cluster the features of x near x and cluster the features of y near y. How to realize it without label?
The answer is to enhance t (.) T (.) through datat ( . ) Create label.
即 t 1 ( x 1 ) , t 2 ( x 1 ) t_1(x_1),t_2(x_1) t1(x1),t2(x1) Are allx 1 x_1x1 Expanded, then they must be the same category, and the rest are all different categories.
There is a problem here, x 1 x_1x1And x 2 x_2x2Etc. xi x_ixi They should all be classified into the same category, and they should not all be classified as negative samples.
Here comes the problem of statistics. As long as I have enough negative samples, there are several positive samples in the negative samples that have relatively small impact. Statistically classifying them all into negative samples is a desirable method, so Contrastive The requirement of the learning method for the number of negative samples is also quite large, because the more negative samples thereafter, the smaller the proportion of positive samples processed as negative samples, and the higher the learning network performance.
This explains why things like MOCO , SIMCLR and their advanced versions are working hard to increase negative samples
It can be said that through augmentation of the data set, the distance between the sample and other samples is enlarged, the distance between the changes of the sample itself is reduced, and the inherent characteristics of the data distribution are learned.
The inherent principle that this method can work is that the data that should actually belong to the same category have potentially similar feature distributions.
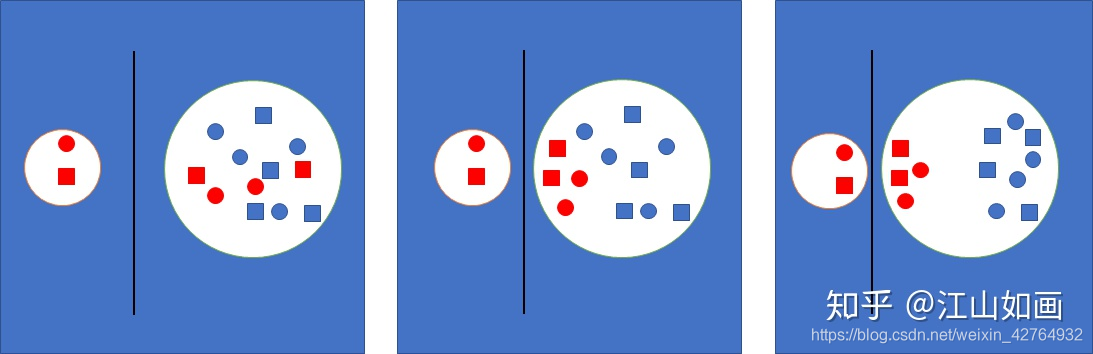
The above figure approximates the training process of simulated contrastive learning. Red represents the same category, blue represents other categories, and the circles and squares are different data expansion methods.
What the entire network training needs to do is to increase the distance between the two circles while reducing the radius of the left circle.
However, the data of the same category has potentially similar distributions, so in the continuous training process, the positive samples in the negative samples will gradually approach the dividing line, and the other true negative samples will continue to move away, and the final result is the same category Data gathered together.
Here is a quote.
How to evaluate Deepmind's new self-supervised work BYOL? -Picturesque answer-Zhihu
https://www.zhihu.com/question/402452508/answer/1352959115
Thanks for the explanation of Zhihu, suddenly enlightened
MOCO "Momentum Contrast for Unsupervised Visual Representation Learning"