I. Overview
Redis persistence is to save memory data to the hard disk. Redis persistent storage is divided into two modes: AOF and RDB, and RDB is enabled by default.
Second, RDB endurance
RDB writes data into a temporary file dump.rdb at a certain point in time. After persistence is over, this temporary file is used to replace the last persisted file to achieve data recovery and use binary files for storage.
2.1 Features
1) Advantages
- Using a separate child process for persistence, the main process will not perform any IO operations, ensuring the high performance of redis.
2) Disadvantages
- RDB is persisted at intervals. If redis fails during persistence, data loss will occur.
Through the description of the above two characteristics, we can know that the RDB persistence method is suitable for use when the data requirements are not rigorous.
The time point when data is written to the temporary file can be determined by configuration. Redis is configured to perform an RDB operation if more than m keys are modified within n seconds. This operation is similar to saving all data of redis at this point in time, and a snapshot of data. Therefore, the persistence method is also called snapshots.
2.2 Opening method
RDB is enabled by default, and the configuration parameters in redis.conf are as follows:
#dbfilename:持久化数据存储在本地的文件
dbfilename dump.rdb
#dir:持久化数据存储在本地的路径,如果是在/redis/redis-3.0.6/src下启动的redis-cli,则数据会存储在当前src目录下
dir ./
##snapshot触发的时机,save
##如900秒后,至少有一个变更操作,才会snapshot
##对于此值的设置,需要谨慎,评估系统的变更操作密集程度
##可以通过"save """来关闭snapshot功能
#save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key300s进行存储;更改10000个key60s进行存储。
save 900 1
save 300 10
save 60 10000
##当snapshot时出现错误无法继续时,是否阻塞客户端"变更操作","错误"可能因为磁盘已满/磁盘故障/OS级别异常等
stop-writes-on-bgsave-error yes
##是否启用rdb文件压缩,默认为"yes",压缩往往意味着"额外的cpu消耗",同时也意味这较小的文件尺寸以及较短的网络传输时间
rdbcompression yes
The meaning of save 900 1 is: when the time reaches 900 seconds, if the redis data has changed at least once, bgsave is executed; save 300 10 and save 60 10000 are the same. When any one of the three save conditions is met, bgsave will be called.
2.3 The realization principle
of save mn Redis save mn is realized through serverCron function, dirty counter, and lastsave timestamp.
serverCron is a periodic operation function of the Redis server, which is executed every 100ms by default; this function maintains the status of the server. One of the tasks is to check whether the conditions of the save mn configuration are met, and if so, execute bgsave.
The dirty counter is a state maintained by the Redis server. It records how many times the server state has been modified (including additions, deletions, and modifications) after the last execution of the bgsave/save command; and when the save/bgsave execution is completed, the dirty is reset to 0 .
For example, if Redis executes set mykey helloworld, the dirty value will be +1; if sadd myset v1 v2 v3 is executed, the dirty value will be +3; note that dirty records the number of changes made by the server, not the client. How many commands to modify the data.
The lastsave timestamp is also a state maintained by the Redis server, which records the time of the last successful execution of save/bgsave.
The principle of save mn is as follows: every 100ms, execute the serverCron function; in the serverCron function, traverse the save conditions of the save mn configuration, as long as one condition is met, bgsave is performed. For each save mn condition, only the following two conditions are satisfied at the same time:
(1) Current time-lastsave> m
(2)dirty >= n
2.4 bgsave execution process
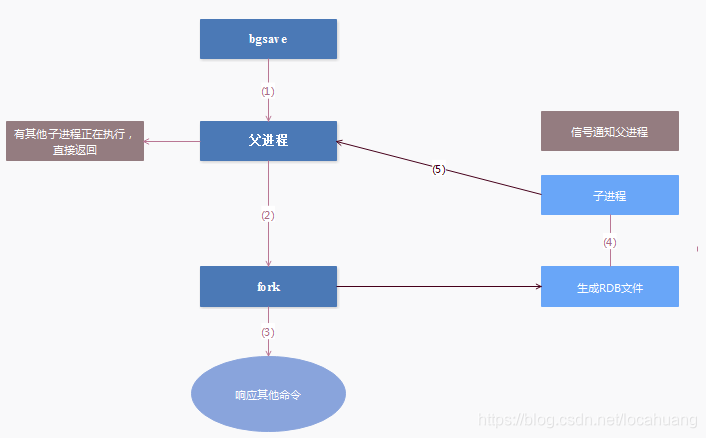
Step analysis
(1) The Redis parent process first judges whether it is currently executing save, or a child process of bgsave/bgrewriteaof, if it is executing, the bgsave command returns directly. The child processes of bgsave/bgrewriteaof cannot be executed at the same time, mainly based on performance considerations: two concurrent child processes simultaneously perform a large number of disk write operations, which may cause serious performance problems.
(2) The parent process executes the fork operation to create a child process. During this process, the parent process is blocked, and Redis cannot execute any commands from the client.
(3) After the parent process forks, the bgsave command returns the "Background saving started" message and no longer blocks the parent process, and can respond to other commands.
(4) The child process creates an RDB file, generates a temporary snapshot file based on the memory snapshot of the parent process, and atomically replaces the original file after completion.
(5) The child process sends a signal to the parent process to indicate completion, and the parent process updates statistics.
Note: Using RDB mode, the following two shutdown modes have different effects:
1) If you shut down redis-cli directly, then update dump.rdb after shutting down, because there is still a redis process in the memory, it will be automatically backed up when shutting down;
2) But If you directly kill the process or shut down directly, redis will not update dump.rdb because redis has disappeared from memory.
Three, AOF persistence
AOF (Append-only file), append "operation + data" to the end of the operation log file by formatting instructions. After the append operation returns (has been written to the file or will be written), the actual data is performed For changes, the "log file" saves all historical operations; when the server needs data recovery, you can directly replay this log file to restore all operations.
AOF is relatively reliable. It is similar to bin.log, apache.log in mysql, and txn-log in zookeeper. The content of the AOF file is a string, which is very easy to read and parse.
3.1 Features
1) Advantages
- Can support higher data integrity. If the time to append the file is set to 1s, if redis fails, at most 1s of data will be lost; and if the log write is incomplete, redis-check-aof is supported for log repair; the aof file is not rewrite before (the file is too large) Commands will be merged and rewritten at times), and some of them can be deleted (such as the incorrectly operated flushall).
2) Disadvantages
- AOF files are larger than RDB files and the recovery speed is slower.
We can simply think:
- AOF file is a log file, this file only records "change operations" (such as set, del, etc.)
- If a large number of change operations continue in the server, the AOF file will be very large, which means that after the server fails, the data recovery process will be very long.
- In fact, after multiple changes to a piece of data, multiple AOF records will be generated. In fact, as long as the current state is saved, the historical operation records can be discarded, because AOF persistence is accompanied by "AOF rewrite".
The characteristics of AOF determine that it is relatively safe. If you expect less data loss, you can use high AOF mode. If the server fails suddenly while the AOF file is being written, the last record of the file may be incomplete. We can detect and correct the incomplete record manually or programmatically, so that the recovery through the AOF file can be normal; colleagues need to remind If you have AOF in your redis persistence method, you need to check the integrity of the AOF file before restarting after the server fails.
3.2 Opening method
AOF is closed by default, and can be opened by modifying the redis.conf configuration file
##此选项为aof功能的开关,默认为"no",可以通过"yes"来开启aof功能
##只有在"yes"下,aof重写/文件同步等特性才会生效
appendonly yes
##指定aof文件名称
appendfilename appendonly.aof
##指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec
appendfsync everysec
##在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示"不暂缓","yes"表示"暂缓",默认为"no"
no-appendfsync-on-rewrite no
##aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,默认"64mb",建议"512mb"
auto-aof-rewrite-min-size 64mb
##相对于"上一次"rewrite,本次rewrite触发时aof文件应该增长的百分比。
##每一次rewrite之后,redis都会记录下此时"新aof"文件的大小(例如A),那么当aof文件增长到A*(1 + p)之后
##触发下一次rewrite,每一次aof记录的添加,都会检测当前aof文件的尺寸。
auto-aof-rewrite-percentage 100
Some attributes indicate that
AOF is a file operation. For servers with intensive change operations, it will increase the load of disk IO. In addition, Linux adopts a "delayed write" method for file operations. Not every write operation triggers the actual hard disk operation, but enters the buffer. When the buffer data reaches the threshold, the actual write is triggered (there are other timings). It is Linux's optimization of the file system, but it also brings hidden dangers. If the buffer is not flushed to the disk, the physical machine fails (such as power failure), which may cause the last one or more AOF records to be lost.
Through the above configuration file, we know that redis provides 3 kinds of AOF record synchronization options:
- always : Every aof record is synchronized to the file immediately . This is the safest way. At the same time, it also requires more disk operations and blocking delays, and the IO overhead is large.
- everysec : Synchronize once per second , the performance and security are relatively moderate, and it is also the recommended method for redis . If you encounter a physical failure, it may cause the AOF record to be lost in the last second (may be a partial loss).
- no : Redis does not directly call file synchronization, but hands it to the operating system to handle it . The operating system can trigger synchronization according to the buffer filling situation/channel idle time, etc.; this is a common file operation method. The performance is better. When the physical server fails, the amount of data loss will be related to the OS configuration.
The AOF file will continue to grow, its size directly affects the "failure recovery" time, and the historical operations in the AOF file can be discarded.
The AOF rewrite operation is the process of "compressing" AOF files. Of course, redis does not use the "original AOF file" method to rewrite, but adopts a snapshot-like method: based on copy-on-write, full traversal of data in memory , And then sequence into the aof file one by one.
Therefore, AOF rewrite can correctly reflect the current state of memory data, which is exactly what we need.
During the rewrite process, new changes will still be written to the original AOF file, and these new changes will also be collected by redis (buffer, copy-on-write, the most extreme may be all The key is modified during this period, which will consume 2 times the memory). After the memory data is written to the new AOF file, the new changes collected will also be added to the new AOF file. The new aof file will be renamed appendonly.aof, and all subsequent operations will be written to the new aof file. If a failure occurs during the rewrite process, it will not affect the normal work of the original AOF file. The file will be switched only after the rewrite is completed, because the rewrite process is relatively reliable.
The timing of triggering rewrite can be declared through the configuration file, and the bgrewriteaof instruction can be used for manual intervention in redis.
redis-cli -h ip -p port bgrewriteaof
Because rewrite operations/aof record synchronization/snapshot all consume disk IO, redis adopts a "schedule" strategy: whether it is "manual intervention" or system trigger, snapshot and rewrite need to be executed one by one.
The AOF rewrite process does not block client requests. The system will start a child process to complete.
Fourth, the difference between RDB and AOF
1) AOF is more secure and can synchronize data to files in a more timely manner , but AOF requires more disk IO expenses. AOF file size is larger, and file content recovery data is relatively slow.
2) RDB has poor security. It is the best method for data backup and master-slave data synchronization during normal periods . The file size is small and data recovery is faster .
Selection strategy
1) In a well-structured environment, the master usually uses AOF and the slave uses RDB. The reason is that the master first ensures data integrity, and it is the first choice for data backup; the slave provides read-only services, and the main purpose is to respond quickly to customers End read request.
2) If the network stability is poor/the physical environment is bad, it is recommended that both master and slave adopt AOF. When the roles of master and slave are switched, the time cost of manual data backup/manually guided data recovery can be reduced.
3) If everything in your environment is very good, and the service needs to receive intensive write operations, it is recommended that the master adopt RDB and the slave adopt AOF.
Q : Will the value of redis disappear after redis is down?
will not. Redis turns on RDB storage by default.
With RDB persistence, the value of redis will be persisted to dump.rdb only when a specific amount of modification is reached at a specific time, but after disconnection, dump.rdb will be automatically updated [generate if no] to realize automatic backup . It should be noted that if you directly kill the process or directly shut down/restart the service, the data may be lost. In this case, dump.rdb will not be automatically backed up.