vlog-4
Model estimation and selection
Empirical error and overfitting

Distillation method
Data set three or seven points, seven points training set, three points test set

Cross-validation
K-fold cross-validation method-in simple terms, the data set is divided into k points, and then permutation and combination selection, such as 5 fold, is to take one of them as the test set, and the rest as the training set. Can take 5 times. Return the average of test results

Self-help method
For the returned data collected m times, the probability of each data being collected is 1/m. When m tends to infinity, the probability that some samples cannot be collected is 1/e.

Thinking: Since some of the data sets cannot be taken, how can they be used as test sets?
Performance measurement
In the figure below, one is continuous and the other is discrete

Error rate and accuracy
As the name suggests, one is discrete and the other is continuous

Recall rate and F1
For example, the data set has 5 dogs and 5 cats. Our model classification
Dog category: [Dog 1 Dog 2 Dog 3 Cat 1 Cat 2]
Cats: [Cat 3 Cat 4 Cat 2 Dog 4 Dog 5].
TP is the real dog in the dog category = 3, FP is the fake dog in the dog category-cat 1 cat 2 = 2
FN is the real dog in the cat category = 3, FP is the fake cat in the cat category-dog 4 dog 5 = 2

Explained here
Here we acquiesce that it is all true before the check. As the check increases, that is, the recall rate increases, errors begin to occur, and the precision rate decreases.
Curve B includes curve C, that is, the precision of A is basically greater than that of B
Compare the A curve with the B curve, that is, use a slope of 1. The precision of A is greater than that of B until the recall is about 0.9, so the model of A is better, so as long as the balance point is judged to be greater, then the overall is greater than


A zero point, we assume that there is a decision whether it is a dog, the probability is [o.1 o.5 0.7 1],
We take all judgments greater than or equal to 0.1 as dogs, p1
The ones greater than or equal to 0.5 are all dogs, p2
And so on

ROC and AUC

I didn't understand ducks either
Cost sensitive error rate and cost curve

Function f(x)! =y Enumerate all the data in the data set to determine whether it is a real example, if cost01=1, if not cost01=0. In this way, all errors/total number of samples = error rate

hypothetical test
Picking out all negative is equivalent to picking out all positive
The error rate of our model is ϵ \epsilonϵ , the counterexample rate of the data set isϵ ^ \widehat{\epsilon}ϵ . Then the total number of counterexamples is ϵ ^ ∗ m \widehat{\epsilon}*mϵ ∗m . It is not difficult to use the binomial distribution to get
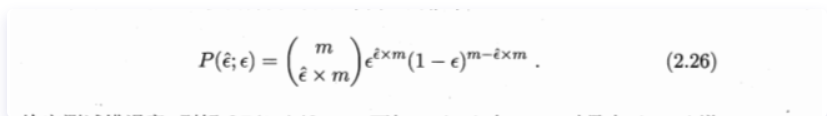
The data is discrete, that is, add up the bar graphs to find the minimum error rate

Bias and variance

Personally understand that noise is an outlier, which is data [1.1 1 0.9 10000]. Obviously 10000 is wrong data. Then we used 10000 when fitting the data to increase the generalization error

The derivation formula is as follows
