The full text is 1031 words, and the expected learning time is 3 minutes

Source: unsplash
Decision trees are one of the most popular and powerful classification algorithms used in machine learning. As the name suggests, decision trees are used to make decisions based on a given data set. In other words, it helps to select appropriate features to divide the tree into sub-parts similar to the human thought context.
In order to construct decision trees efficiently, we use the concepts of entropy/information gain and Gini impurity. Let's see what Gini impurity is and how it can be used to build decision trees.
What is Gini impurity?
Gini impurity is a method used in decision tree algorithm to determine the best split of the root node and subsequent splits. This is the most popular and easiest way to split a decision tree. It only applies to classification targets because it only performs binary splits.
The formula for Gini impurity is as follows:
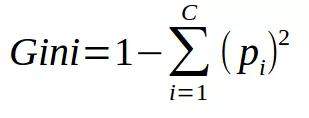
The lower the Gini impurity, the higher the homogeneity of the node. The Gini impurity of pure nodes (same class) is zero. Take a data set as an example to calculate the Gini impurity.
The data set contains 18 students, 8 boys and 10 girls. According to their performance, they are classified as follows:
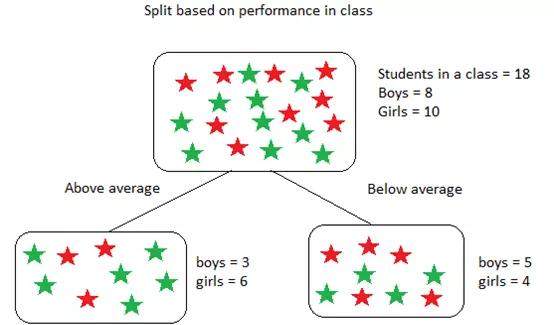
The above-mentioned Gini impurity is calculated as follows:

In the above calculation, in order to find the weighted Gini impurity of the split (root node), we use the probability of the student in the child node. For "above average" and "below average" nodes, the probability is only 9/18. This is because the number of students in the two child nodes is equal, even if the number of boys and girls in each node The performance is different, and so is the result.
The following are the steps to split the decision tree using Gini impurity:
· Similar to the approach in entropy/information gain. For each split, calculate the Gini impurity of each child node separately.
· Calculate the Gini impurity of each split as the weighted average Gini impurity of the child nodes.
· Choose the cut with the lowest Gini impurity value.
· Repeat steps 1-3 until you get the same kind of nodes.
Gini impurity summary:
· Helps to find root nodes, intermediate nodes and leaf nodes to develop decision trees.
· Used by CART (Classification and Regression Tree) algorithm for classification trees.
· When all conditions in the node belong to a goal, the minimum value (zero) is reached.
All in all, Gini impurity is more popular than entropy/information gain because it has a simple formula and does not use computationally intensive and difficult logarithms.

Share the dry goods of AI learning and development together
Welcome to follow the full platform AI vertical self-media "core reading"
(Add the editor WeChat: dxsxbb, join the reader circle, and discuss the freshest artificial intelligence technology together~)