
Introduction:
Redis can easily support 100k+ QPS, and is inseparable from I/O Multiplexing based on the Reactor model, In-memory operation, and single-threaded execution of commands to avoid static consumption. Although the performance can meet most of the application scenarios, how to continue to optimize in the iteration and use the advantages of multithreading in the multi-core era are also the focus of everyone's attention. We know that performance optimization can start from I/O and CPU at the system resource level. For Redis, its function does not rely too much on CPU computing power, that is, it is not a CPU-intensive application, and In-memory operations are also bypassed Usually slow performance disk I/O is dragged, so in Redis 6.0 version, starting with network I/O, introducing Threaded I/O to assist read and write, in some scenarios, a substantial performance improvement has been achieved. This article will introduce the event model of Redis, analyze how Threaded I/O can help improve performance, and the principle of its implementation.
Introduction
Redis has introduced Threaded I/O since version 6.0 in order to improve the network I/O performance before and after executing commands. This article will start with the analysis of the main process of Redis, explain where the network I/O occurs, and the existing network I/O model, then introduce the new model, implementation and effective scenarios of Threaded I/O, and finally conduct a scenario test , Compare the performance difference between Threaded I/O being turned off and on, and the performance difference between enabling Threaded I/O and building a cluster on a single instance. If you have already understood Redis's cycle process, you can skip directly to the related part of Threaded I/O ; if you only care about the actual improvement of new features, you can skip to the performance test part to check.
How Redis works
Event loop
main
The entrance of Redis is located under server.c, and the main() method flow is shown in the figure.
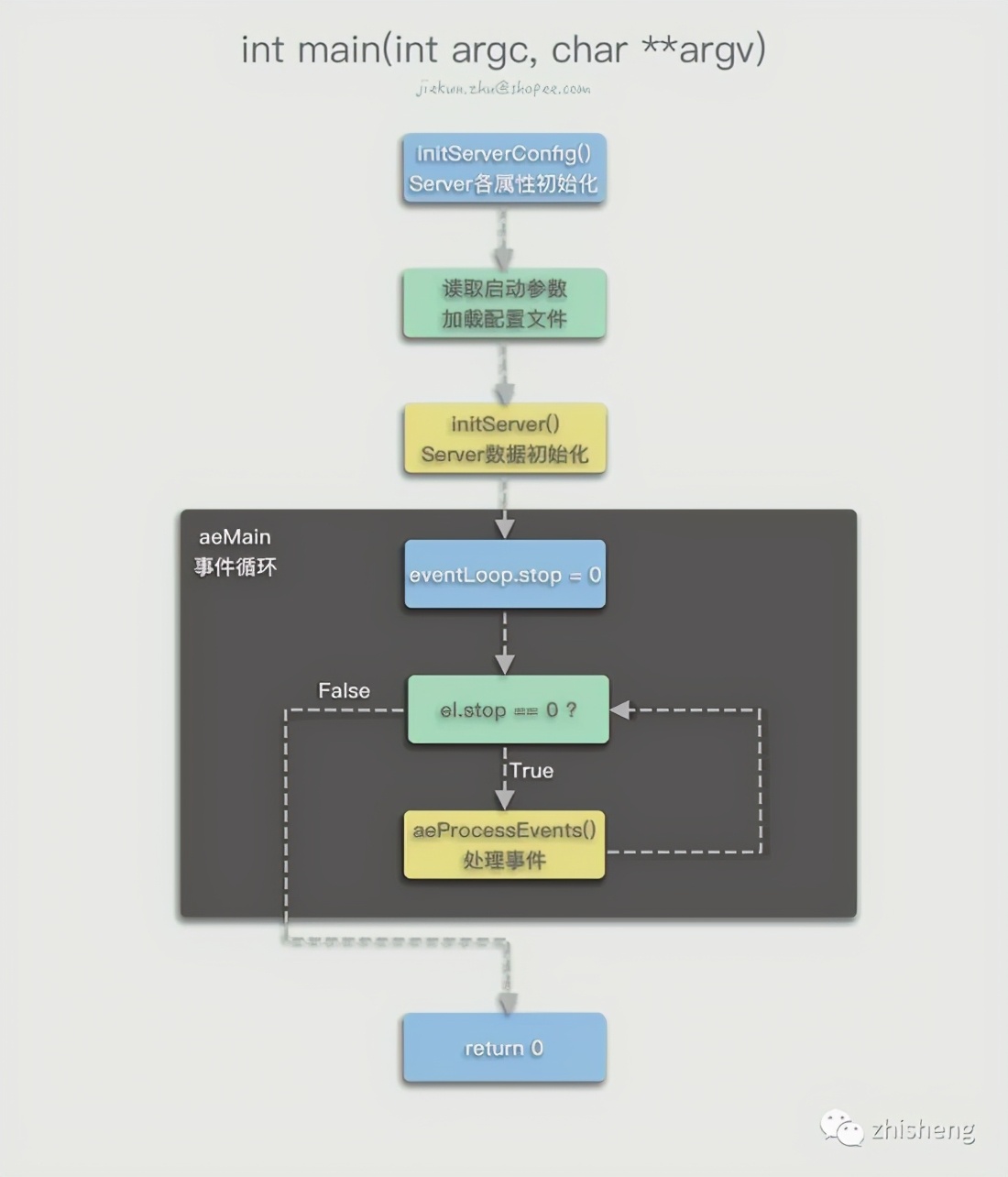
The first thing Redis needs to do in the main() method is to initialize various libraries and service configurations . Specific examples:
- crc64_init() will initialize a Lookup Table for crc verification
- getRandomBytes() fills hashseed with random elements as the initialization value, which is used as the seed of the hash table
- ...
- A large number of initialization operations on server object properties are performed in initServerConfig():
- Initialize server.runid, such as 16e05f486b8d41e79593a35c8b96edaff101c194
- Get the current time zone information and store it in server.timezone
- Initialize the server.next_client_id value so that the client id of the connected client increases from 1
- ...
- ACLInit() is the initialization operation of the new ACL system in Redis 6.0, including information such as initializing user list, ACL log, default user, etc.
- Initialize the module system and SSL through moduleInitModulesSystem() and tlsInit()
- ...
After the initialization is over, it starts to read the user's startup parameters . Similar to most configuration loading processes, Redis also analyzes the argc and argv[] input by the user through string matching. This process may happen:
- Get the configuration file path, modify the value of server.configfile, and then load the configuration file
- Get the startup option parameters, such as loadmodule and the corresponding Module file path, and save them in the options variable
After parsing the parameters, execute loadServerConfig(), read the configuration file and merge it with the content of the command line parameter options to form a config variable, and set the name and value into the configs list one by one. For each config, there is a corresponding switch-case code. For example, for loadmodule, the queueLoadModule() method will be executed to complete the actual configuration loading:
...
} else if (!strcasecmp(argv[0],"logfile") && argc == 2) {
... } else if (!strcasecmp(argv[0],"loadmodule") && argc >= 2) {
queueLoadModule(argv[1],&argv[2],argc-2);
} else if (!strcasecmp(argv[0],"sentinel")) {
...Back to the main method process, Redis will start to print the startup log, execute the initServer() method, and the service will continue to initialize the content for the server object according to the configuration items, for example:
- Create event loop structure aeEventLoop (defined in ae.h) and assign it to server.el
- According to the configured number of db, allocate a memory space of sizeof(redisDb) * dbnum, and server.db saves the address pointer of this space
- Each db is a redisDb structure, and the dictionary that saves the key and saves the expiration time in this structure is initialized to an empty dict
- ...
After that, there are some initializations according to different operating modes. For example, when the normal mode is running, it will record the normal log and load the persistent data on the disk; and when the sentinel mode is running, it will record the sentinel log and not load the data.
After all preparation operations are completed, Redis begins to fall into the aeMain() event loop, in which aeProcessEvents() will be executed continuously to process various events that occur, until Redis exits.
Two events
There are two types of events in Redis: time events and file events .
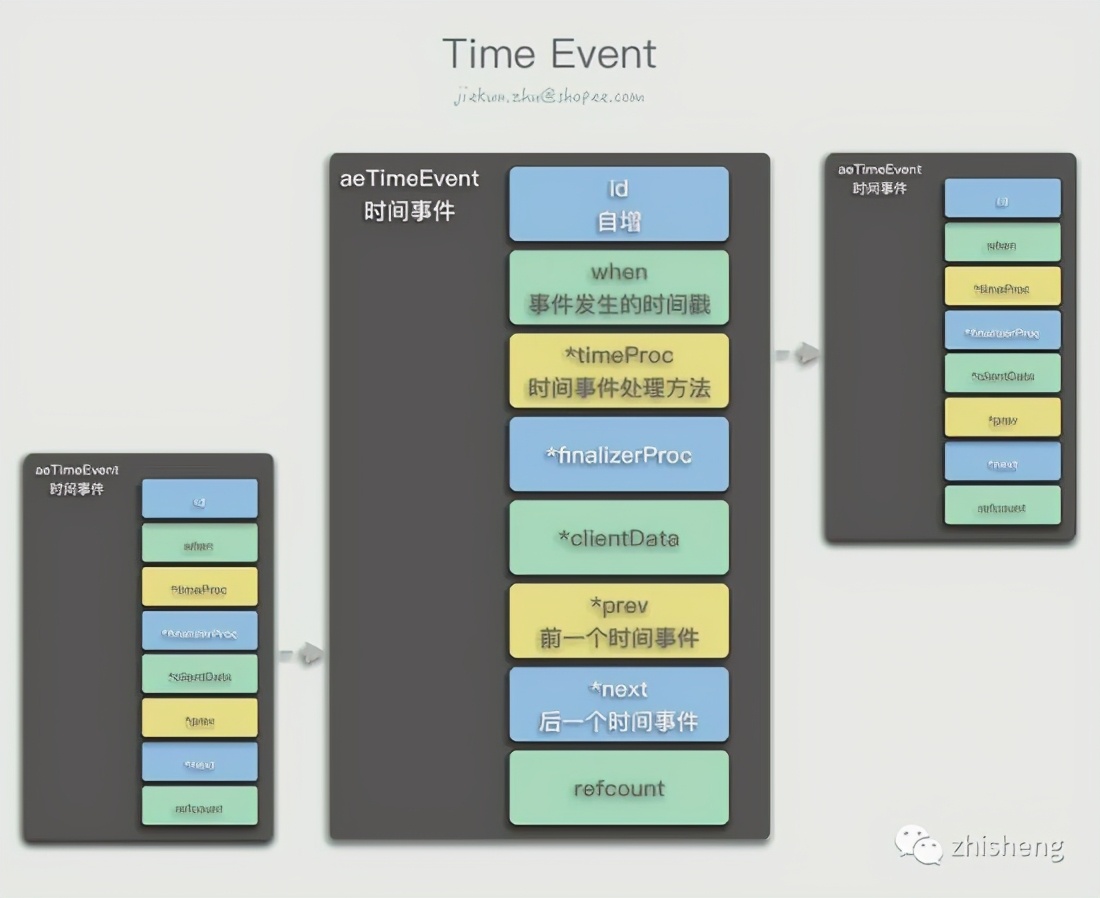
Time events are events that will occur at a certain time. They are recorded as a linked list in Redis. Every time a new time event is created, an aeTimeEvent node is inserted at the head of the linked list, which stores where the event will be. When happens, what method needs to be called to deal with. By traversing the entire linked list, we can know how long it is until the most recent time event is about to occur, because the nodes in the linked list are arranged in the order of self-increasing id, and they are out of order in the dimension of the time of occurrence.
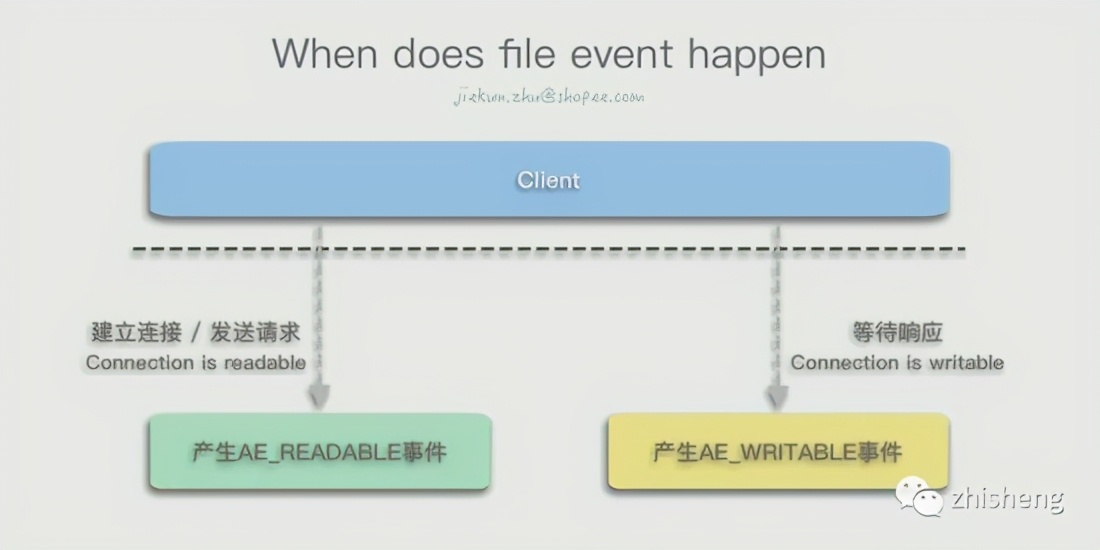
File events can be regarded as events caused by I/O. Sending commands by the client will cause the server to generate a read I/O, corresponding to a read event; also when the client is waiting for a message from the server, it needs to become writable to allow the service Write content at the end, so it will correspond to a write event. The AE_READABLE event occurs when the client establishes a connection, sends a command, or other connections become readable, and the AE_WRITABLE event occurs when the client connection becomes writable.
The structure of a file event is much simpler. aeFileEvent records whether it is a readable event or a writable event, the corresponding processing method, and user data.

If two events occur at the same time, Redis will give priority to the AE_READABLE event.
aeProcessEvents
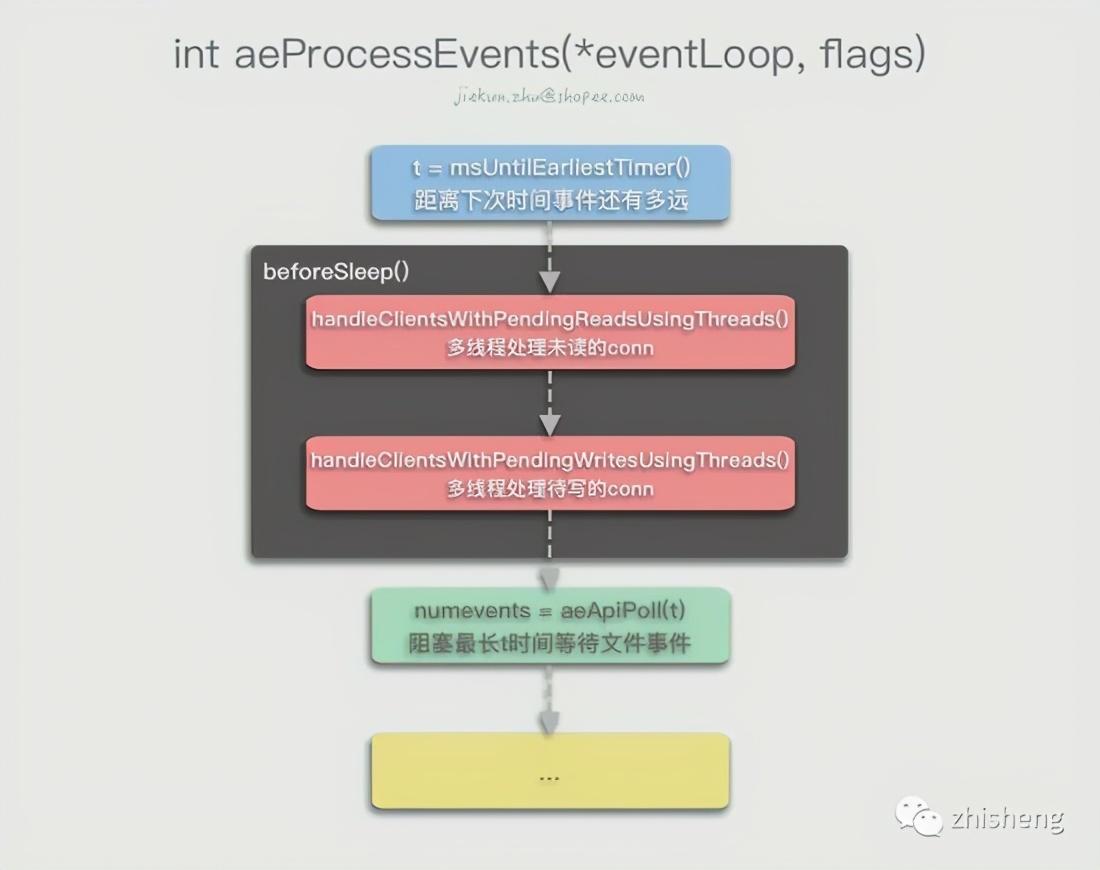
The aeProcessEvents() method handles various events that have occurred and are about to occur.
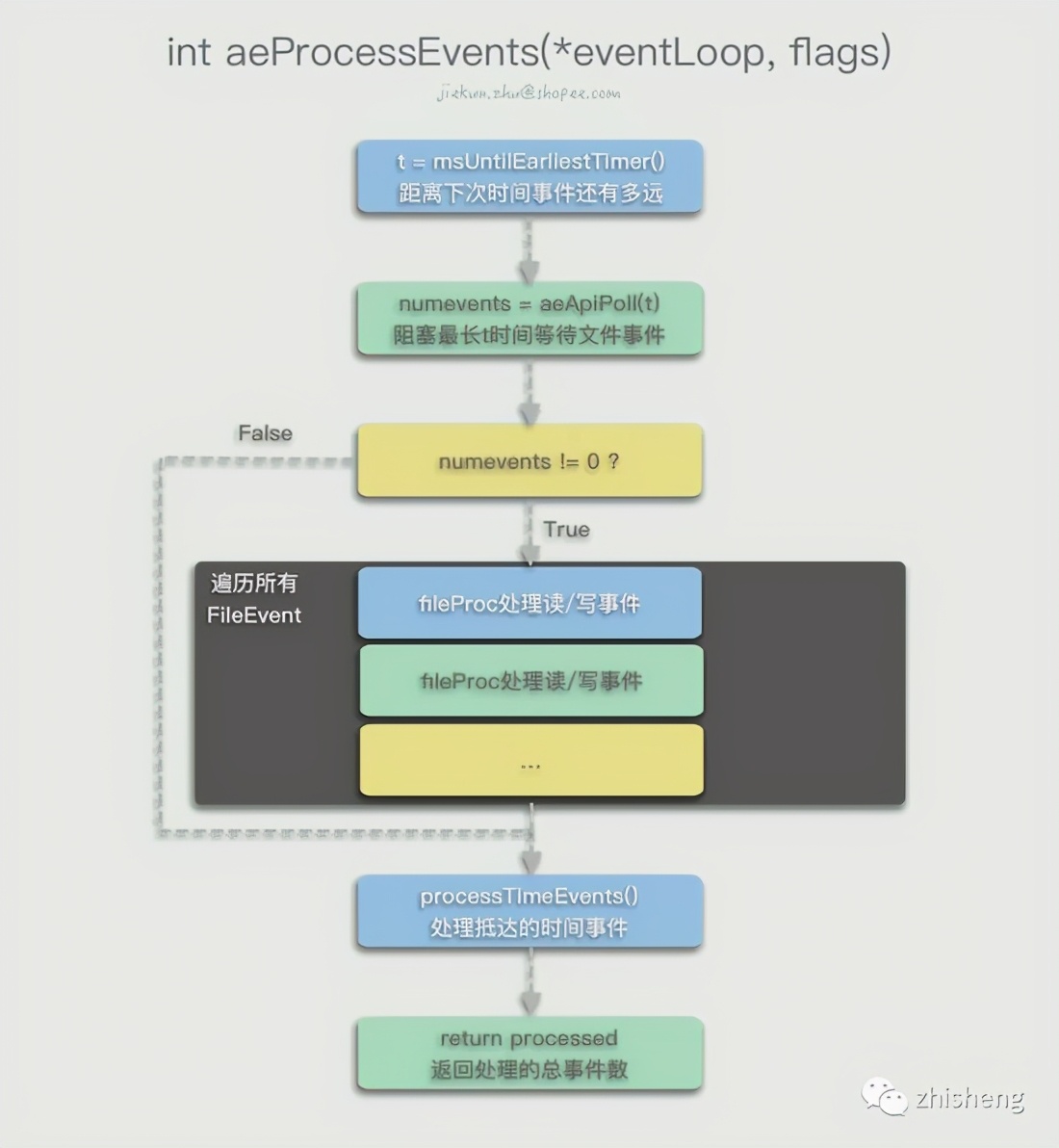
After the aeMain() loop enters the aeProcessEvents(), Redis first checks when the next time event will occur. During the period before the time event occurs, you can call the multiplexed API aeApiPoll() to block and Wait for the occurrence of the file event. If no file event has occurred, 0 will be returned after the timeout, otherwise the number of file events that have occurred numevents will be returned.
In the case of file events to be processed, Redis will call the rfileProc method of the AE_READABLE event and the wfileProc method of the AE_WRITABLE event to process:
...
if (!invert && fe->mask & mask & AE_READABLE) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; fe = &eventLoop->events[fd]; } if (fe->mask & mask & AE_WRITABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->wfileProc(eventLoop,fd,fe->clientData,mask); fired++; } }...After completing the previous processing, Redis will continue to call processTimeEvents() to process time events. Traverse the entire linked list of time events. If a period of time has passed (blocking waiting or processing file events takes time) and a time event occurs, then call the timeProc method of the corresponding time event to process all time events that have passed:
...
if (te->when <= now) {
... retval = te->timeProc(eventLoop, id, te->clientData); ... processed++; ... }...If the latest time event has not been reached after the file event is executed, no time event will be executed in this aeMain() loop, and the next loop will enter.
What happened before and after the command was executed
When the client connects to Redis, by executing connSetReadHandler(conn, readQueryFromClient), when a read event occurs, readQueryFromClient() is used as the Handler for the read event.
When receiving a command request from the client, Redis performs some checks and statistics, and then calls the read() method to read the data in the connection into the client.querybuf message buffer:
void readQueryFromClient(connection *conn) {
... nread = connRead(c->conn, c->querybuf+qblen, readlen); ...static inline int connRead(connection *conn, void *buf, size_t buf_len) {
return conn->type->read(conn, buf, buf_len);
}static int connSocketRead(connection *conn, void *buf, size_t buf_len) {
int ret = read(conn->fd, buf, buf_len);
...}Then enter processInputBuffer(c) to start reading the message in the input buffer, and finally enter processCommand(c) to start processing the input command.
After the command is executed, the result will be stored in client.buf first, and the addReply(client *c, robj *obj) method will be called to append the client object to the server.clients_pending_write list. At this time, the current command, or the AE_READABLE event, has basically been processed. Except for some additional statistical data and post-processing, no more response messages will be sent.
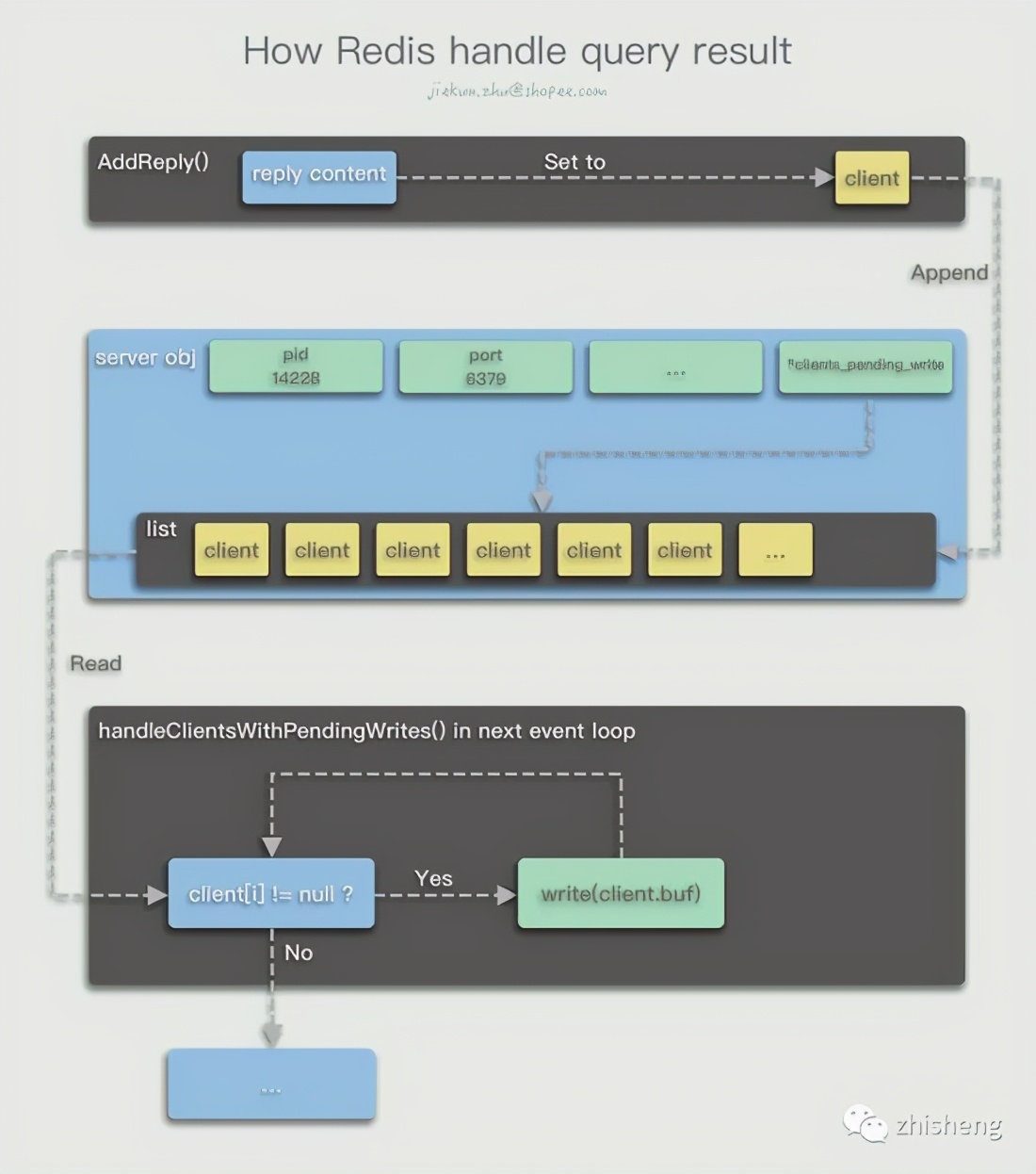
After the current aeProcessEvents() method ends, enter the next cycle . The second cycle calls the I/O multiplexing interface to wait for the file event to occur. Redis will check server.clients_pending_write whether there is a client that needs to reply, if so , It is convenient to point to the server.clients_pending_write list of each client to be replied, delete the client from it one by one, and reply the content to be replied through writeToClient(c,0)
int writeToClient(client *c, int handler_installed) {
... nwritten = connWrite(c->conn,c->buf+c->sentlen,c->bufpos-c->sentlen); ...static inline int connWrite(connection *conn, const void *data, size_t data_len) {
return conn->type->write(conn, data, data_len);
}static int connSocketWrite(connection *conn, const void *data, size_t data_len) {
int ret = write(conn->fd, data, data_len);
...}Threaded I/O模型
I/O problems and the introduction of Threaded I/O
If you want to say that Redis will have any performance problems, then from the I/O perspective, because it does not use disk like other databases, there is no disk I/O problem. Before data enters the buffer and when writing from the buffer to the Socket, there is a certain amount of network I/O, especially writing I/O has a greater impact on performance. In the past, we would consider pipelining to reduce network I/O overhead, or deploy Redis as a Redis cluster to improve performance.
After Redis 6.0, due to the introduction of Threaded I/O, Redis began to support the threading of network read and write, allowing more threads to participate in this part of the action, while maintaining the single-threaded execution of commands. Such changes can improve performance to some extent, but also avoid the need to introduce locks or other methods to solve the static problem of parallel execution by threading the command execution.
What is Threaded I/O doing
In the implementation of the old version, Redis saves the command execution results of different clients in their respective client.buf, and then stores the client to be replied in a list, and finally writes the contents of buf to the corresponding Socket in the event loop. . Corresponding to the new version, Redis uses multiple threads to complete this part of the operation.
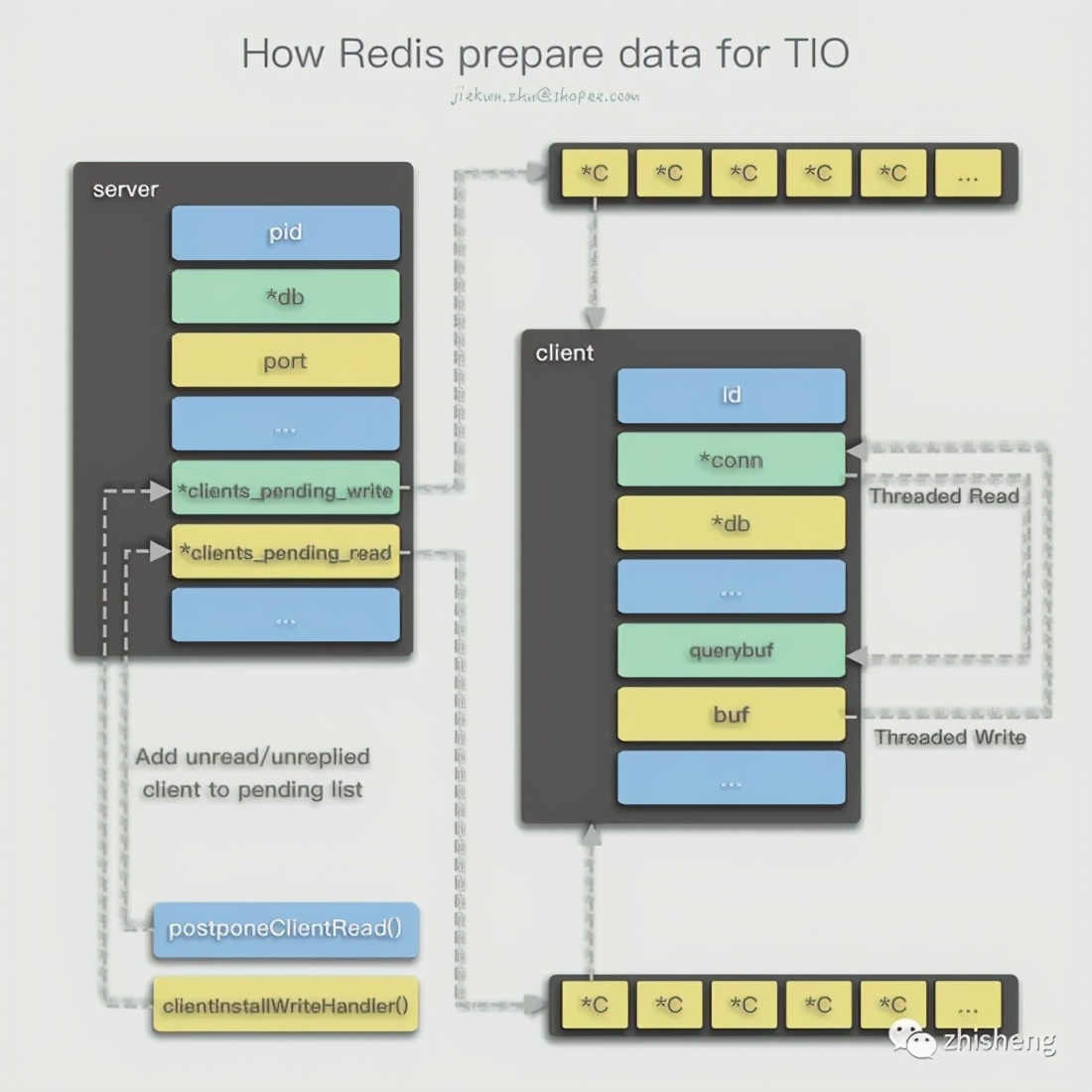
For read operations, Redis also adds a clients_pending_read property to the server object. When a read event comes, it determines whether the threaded read condition is met. If it is met, the delayed read operation is performed and the client object is added to server.clients_pending_read List. Like the write operation, multiple threads are used to complete the read operation until the next event loop.
Implementation and Limitations of Threaded I/O
Init phase
When Redis is started, if the corresponding parameter configuration is met, the I/O thread initialization operation will be performed.
void initThreadedIO(void) {
server.io_threads_active = 0;
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}...Redis will perform some routine checks to see if the configuration number meets the requirements for enabling multi-threaded I/O.
...
for (int i = 0; i < server.io_threads_num; i++) {
io_threads_list[i] = listCreate();...Create an io_threads_list list with a length of the number of threads. Each element of the list is another list L. L will be used to store multiple client objects to be processed by the corresponding thread.
...
if (i == 0) continue;
...For the main thread, the initialization operation ends here.
...
pthread_t tid;
pthread_mutex_init(&io_threads_mutex[i],NULL);
io_threads_pending[i] = 0;
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
} io_threads[i] = tid; }}...io_threads_mutex is a list of mutex locks, io_threads_mutex[i] is the lock of the i-th thread, used for subsequent blocking I/O thread operations, and temporarily locked after initialization. Then perform the creation operation on each thread, tid is its pointer, and save it in the io_threads list. The new thread will always execute the IOThreadMain method, we will explain it to the end.
Reads/Writes
Multi-threaded reading and writing are mainly done in handleClientsWithPendingReadsUsingThreads() and handleClientsWithPendingWritesUsingThreads(). Because the two are almost symmetrical, only the read operation is explained here. Students who are interested can check what is the difference between the write operation and why .
int handleClientsWithPendingReadsUsingThreads(void) {
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
if (tio_debug) printf("%d TOTAL READ pending clients\n", processed);
...Similarly, Redis will routinely check whether threaded reads and writes are enabled and threaded reads are enabled (only the former is enabled, only write operations are threaded), and whether there are clients waiting to read.
...
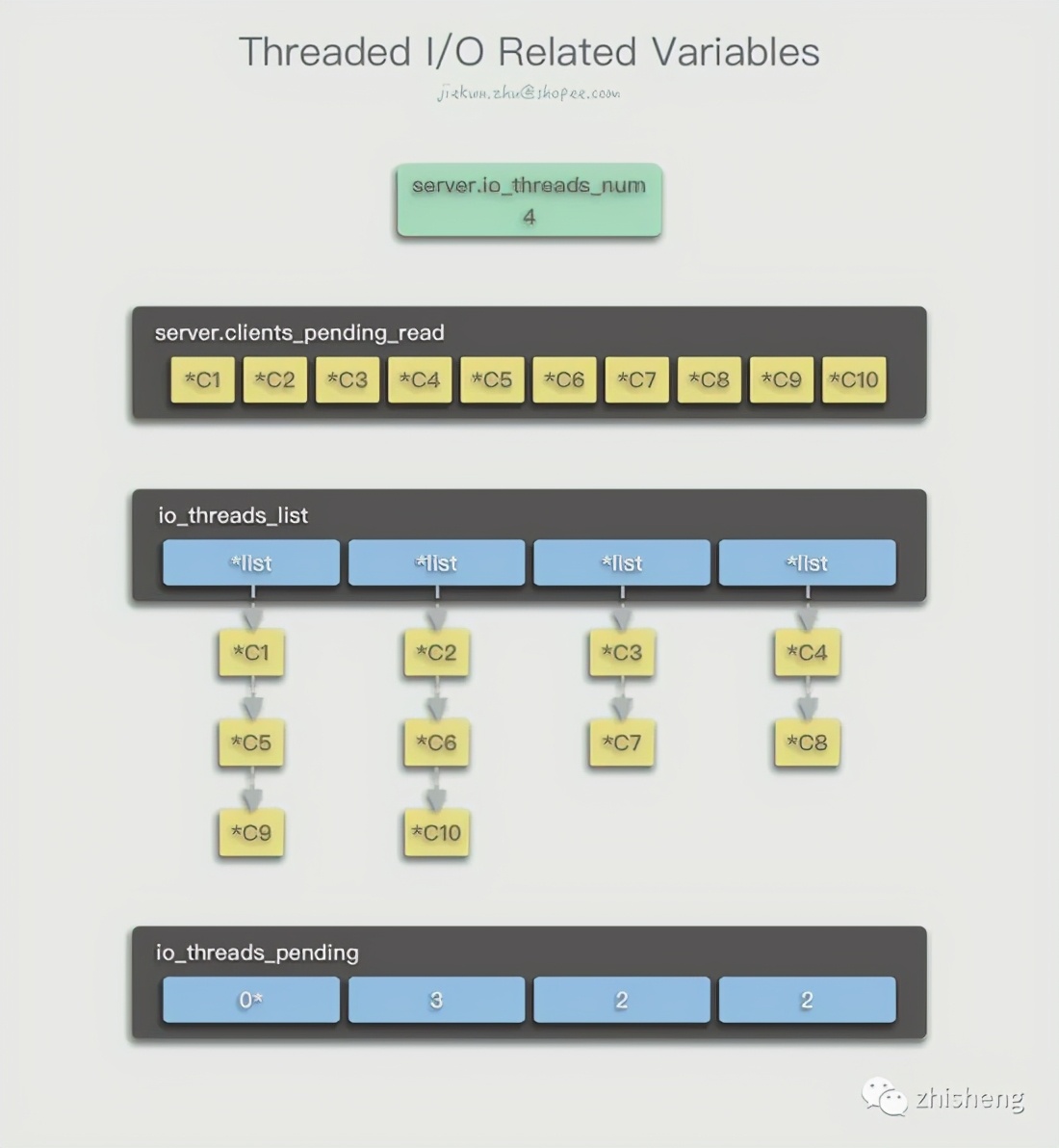
listIter li; listNode *ln; listRewind(server.clients_pending_read,&li); int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c); item_id++; }...Here, the list of server.clients_pending_read is converted into a linked list that is convenient to traverse, and then each node (*client object) of the list is assigned to each thread in a manner similar to Round-Robin. The read and write sequence of each client does not need to be guaranteed. , The order in which the commands arrive has been recorded in the server.clients_pending_read/write list, and will be executed in this order in the future.
...
io_threads_op = IO_THREADS_OP_READ;
...Set the status flag to identify the current status of multi-threaded reading. Due to the existence of the mark, Redis's Threaded I/O can only be in a read or write state instantaneously, and cannot be read or written by part of the thread.
...
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count; }...Record the number of clients that need to be processed for each thread. When different threads read that their pending length is not 0, they will start processing. Note that j starts from 1, which means that the pending length of the 0 main thread is always 0, because the main thread will complete its tasks synchronously in this method immediately, without knowing the number of tasks waiting.
...
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
} listEmpty(io_threads_list[0]);
...The main thread now finishes processing the client it wants to process.
...
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j]; if (pending == 0) break;
} if (tio_debug) printf("I/O READ All threads finshed\n");
...Stuck in a loop waiting, pending is equal to the sum of the remaining tasks of each thread. When all threads have no tasks, this round of I/O processing ends.
...
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read); client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln); if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~CLIENT_PENDING_COMMAND;
if (processCommandAndResetClient(c) == C_ERR) {
continue;
} } processInputBuffer(c);
}...We have read the contents of conn into the client.querybuf input buffer of the corresponding client in the respective threads, so we can traverse the server.clients_pending_read list, execute the command serially, and remove the client from the list at the same time.
...
server.stat_io_reads_processed += processed; return processed;
}After the processing is completed, the processed quantity is added to the statistical attribute, and then returned.
IOThreadMain
The specific work content of each thread has not been explained before, and they will always be trapped in the loop of IOThreadMain, waiting for the time to perform read and write.
void *IOThreadMain(void *myid) {
long id = (unsigned long)myid;
char thdname[16];
snprintf(thdname, sizeof(thdname), "io_thd_%ld", id);
redis_set_thread_title(thdname); redisSetCpuAffinity(server.server_cpulist);...Perform some initialization content as usual.
...
while(1) {
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
} if (io_threads_pending[id] == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
} serverAssert(io_threads_pending[id] != 0);
if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id]));
...The thread will detect the length of its pending client list, and execute it when the waiting queue length is greater than 0, otherwise it will reach the beginning of the endless loop.
Here, the mutex lock is used to give the main thread the opportunity to lock, so that the I/O thread is stuck in the execution of pthread_mutex_lock(), so that the I/O thread can stop working.
...
listIter li; listNode *ln; listRewind(io_threads_list[id],&li); while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
} }...Convert the client list of io_threads_list[i] into a linked list that is convenient for traversal, and traverse one by one. Use the io_threads_op flag to determine whether you want to perform multi-threaded read or multi-threaded write, and complete the operation of the client you want to handle.
...
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}}Clear the client list that you want to process, and modify your pending number to 0 to end this round of operations.
Limitation
By looking at the code, the enabling of Threaded I/O is affected by the following conditions:
- The configuration item io-threads needs to be greater than 1, otherwise it will continue to use single-threaded operations to read and write I/O
- The configuration item io-threads-do-reads controls whether read I/O uses threading
- postponeClientRead() CLIENT_PENDING_READ client CLIENT_PENDING_READ
- handleClientsWithPendingWritesUsingThreads() stopThreadedIOIfNeeded() server.clients_pending_write
- initThreadedIO() server io_threads_active server.io_threads_active server.io_threads_active
Performance Testing
We compiled the unstable version of Redis for performance testing. The testing tool is redis-benchmark that comes with Redis, and the RPS value of the statistical output is used as a reference.
Server实例: AWS / m5.2xlarge / 8 vCPU / 32 GB
Benchmark Client实例: AWS / m5.2xlarge / 8 vCPU / 32 GB
Command: redis-benchmark -h 172.xx.xx.62 -p 6379 -c 100 -d 256 -t get,set -n 10000000 --threads 8
Threaded I/O off vs. Threaded I/O on
We compared the performance of the original single-threaded I/O and the Threaded I/O with 2 threads/4 threads, and the results are shown in the figure.
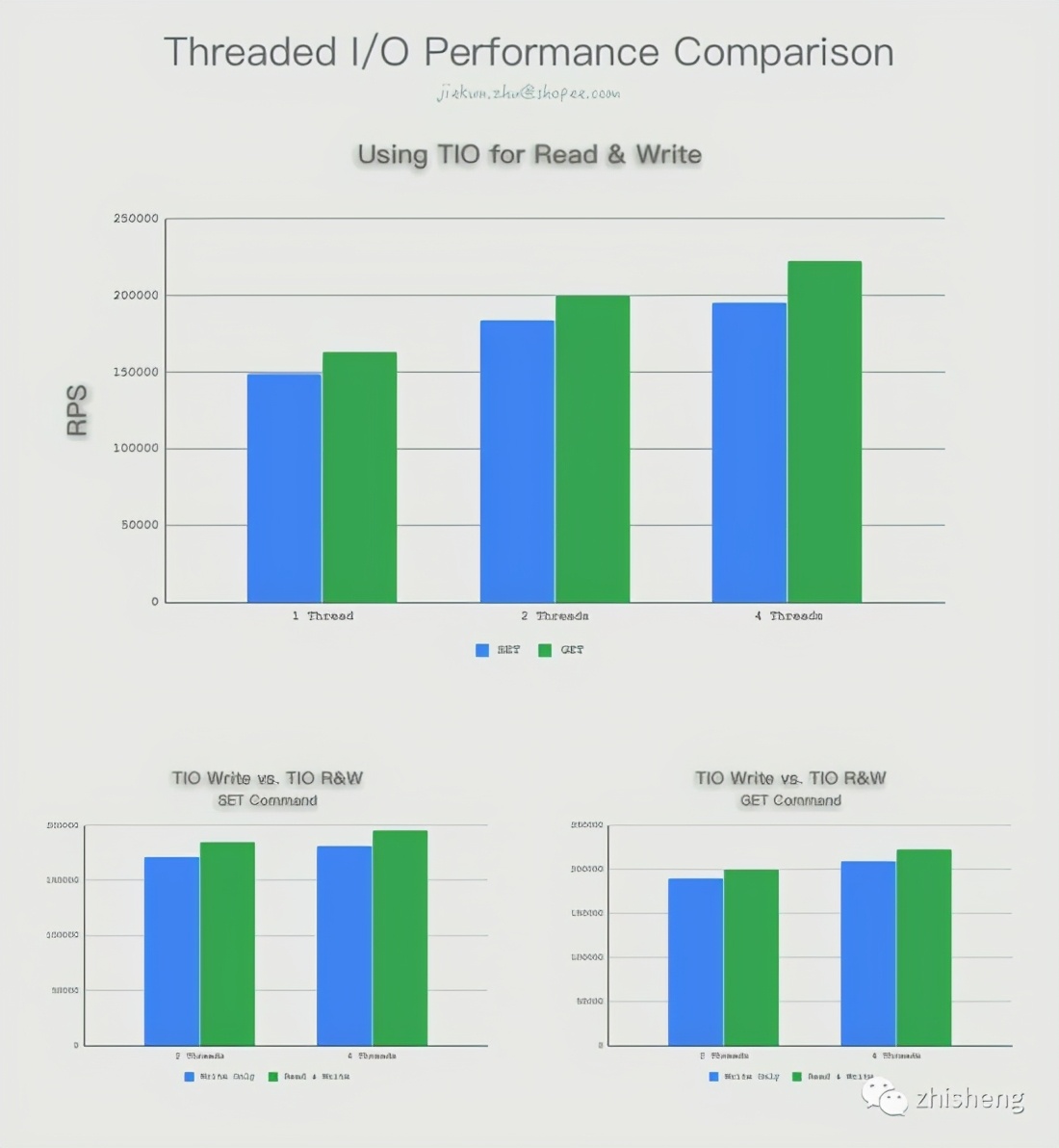
With the io-threads-do-reads option turned on, Threaded I/O acts on read operations, which can also further improve performance, but does not significantly improve write I/O threading. In addition, we also tried to use a large-volume payload (-d 8192) for testing, and found that the percentage increase in the results did not differ much.
Threaded I/O vs. Redis Cluster
In the past, developers tried to make Redis use more CPU resources by deploying Redis Cluster on a single instance. We also tried to compare the performance in this scenario.
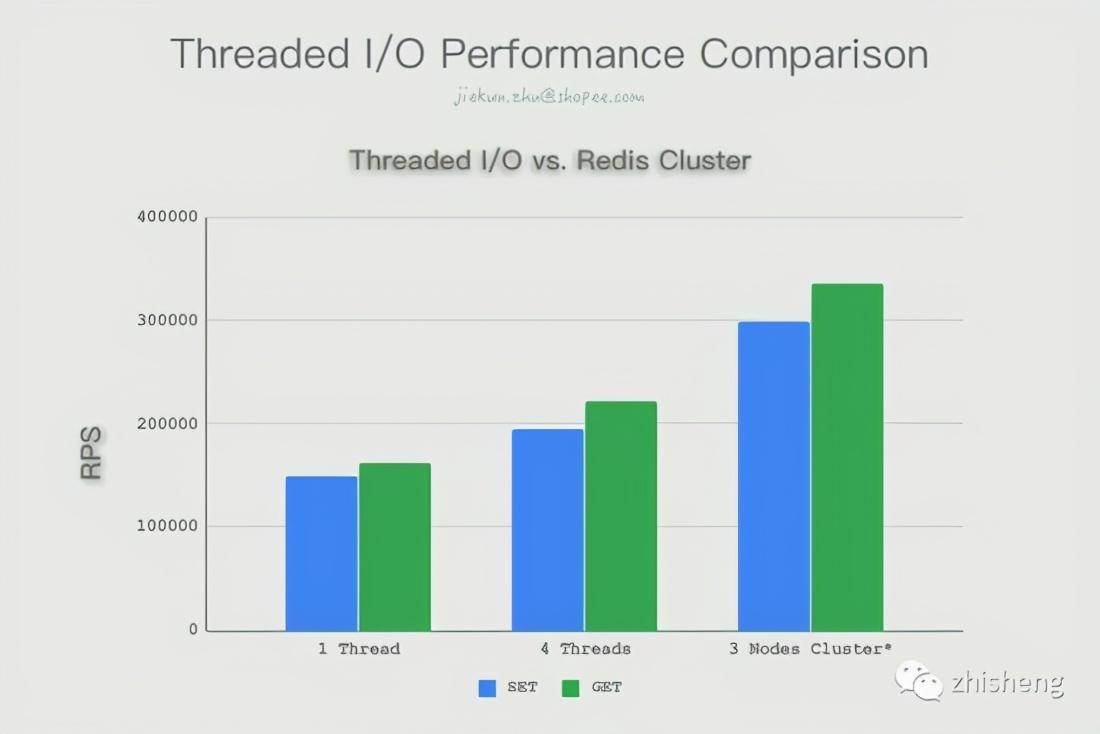
In the new version, redis-benchmark has also been updated to support the testing of Redis Cluster. The cluster mode and configuration can be detected by turning on the --cluster parameter. We have seen the powerful performance of single-instance cluster construction in this set of comparative tests. In actual tests, the CPU usage of the three processes are all 80%-90%, indicating that there is still room for improvement. When the test parameter -c 512 is used instead, the cluster can run more than 400,000 RPS. Although the test and actual use will be different, and we chose not to include a Slave when building the cluster, we can still see that in several models, building a Cluster can really use multithreading for network I/O and command execution , The performance improvement is also the biggest.
Summary and reflection
The Threaded I/O introduced by Redis 6.0 delays Socket reading and writing and threading, which brings certain performance improvements to Redis in the direction of network I/O, and the threshold for use is relatively low. Users do not need to make too many changes. That is to say, idle thread resources are used for nothing without affecting the business.
On the other hand, judging from the test results, this part of the improvement may not make it possible for users in Redis 5 or even Redis 3 to have enough motivation to upgrade, especially considering that the performance of Redis in many business scenarios is not bad. Bottlenecks, and the benefits of the new version have not been verified on a large scale, which will inevitably affect the stability of the service that more users pay attention to in enterprise applications. At the same time, there seems to be a certain gap between the improvement of TIO and the performance of clusters, which may make enterprise users who are already in the cluster architecture ignore this feature.
But in any case, users are definitely happy to see more new features, more optimizations and improvements appear on Redis. On the premise of maintaining consistent stability, this version can be said to be the biggest update of Redis since its birth. Not only Threaded I/O, including RESP3, ACLs and SSL, we look forward to these new features in more application scenarios The download has been promoted, verified and used, and I hope that future versions can bring more surprises and better experience to users.
Further Reading: Understanding Redis
As a developer who has never used C/C-like languages, Redis's concise code and detailed comments have provided a great help for me to read and understand its implementation. At the end of the article, I want to share some ways, tools and methods for learning Reids.
README.md should be the entry point for us to understand Redis, not a global search for the main() method. Please pay attention to the content under the summary of Redis internals. Here we introduce the code structure of Redis. Each file of Redis is a "general idea". Part of the logic and code of server.c and network.c has been introduced in this article. Aof.c and rdb.c related to transformation, db.c related to database, object.c related to Redis objects, and replication.c related to replication are all worth paying attention to. Other commands, including Redis, can be found in the README.md in the format in which they are coded, so that we can quickly locate them when we read the code further.
The Documentation homepage [1] and redis-doc repo [2] are collections of Redis documents. Please note that there are many interesting topics in the topics directory of the latter. My definition of "interesting" is an article like this:
- Redis Cluster Specification [3]
- Redis server-assisted client side caching [4]
As a developer, in the stage of in-depth learning, these contents can make everyone change from "using" to "understanding", and then discover that Redis can do more. So if you lack time to read and debug the source code, reading over 60 documents under topics is probably the fastest way to understand Redis.
Finally, if you can see here, maybe you will be a little bit interested in the Redis source code. Because I don't know the C language, I might choose to use an IDE to put a breakpoint in main(), and then start looking at the beginning of the process. In fact, I did this. Several other key points of the code have actually appeared in this article:
- main(), the starting point
- initServer(), initialization
- aeMain(), event loop
- readQueryFromClient(), the Handler of the read event
- processInputBuffer(), the entry point for command processing
If you want to understand the content of the network like this article, you can break at aeMain(), and then focus on the method in network.c; if you want to pay attention to the content related to specific commands, you can break at processInputBuffer(), and then Pay attention to the methods in $command.c or similar files. The naming format of command methods has also been introduced in the README.md file, which is very easy to locate. Other actions that frequently occur, such as persistence, replication, etc., probably occur before and after the command is executed, or within time, and may also be in beforeSleep(). The redisServer and client defined in server.h are two very important structures in Redis. A lot of business content is transformed into operations related to their attributes, so pay special attention.