Using paging as the core mechanism to implement virtual memory may bring higher performance overhead. Because paging is to be used, the memory address space must be divided into a large number of fixed-size units (pages), and the address mapping information of these units needs to be recorded. Because these mapping information are generally stored in physical memory, when converting virtual addresses, paging logic requires an additional memory access. Every time an instruction is fetched, explicitly loaded or saved, an additional read of the memory is required to obtain the conversion information, which is unacceptably slow. Therefore, we face the following problems:
Key question: how to speed up address translation
How can we speed up virtual address translation and avoid additional memory access as much as possible? What kind of hardware support is needed? How should the operating system support it?
To make something faster, the operating system usually needs some help. Help often comes from old friends of operating systems: hardware. We need to increase the so-called (for historical reasons [CP78]) address translation bypass buffer memory (translation-lookaside buffer, TLB [CG68, C95]), which is the hardware cache for frequently occurring virtual to physical address translation. Therefore, a better name would be address-translation cache. For each memory access, the hardware first checks the TLB to see if there is the expected conversion mapping, and if there is, the conversion is completed (soon) without accessing the page table (which has all the conversion mappings). TLB brings a huge performance improvement, in fact, it makes virtual memory possible [C95].
19.1 Basic algorithm of TLB
Figure 19.1 shows a general framework that illustrates how the hardware handles virtual address translation. It is assumed that a simple linear page table (linear page table, that is, the page table is an array) and hardware-managed TLB (hardware-managed TLB, that is, the hardware is responsible for many Responsibility for page table access, there will be more explanation below).
1 VPN = (VirtualAddress & VPN_MASK) >> SHIFT
2 (Success, TlbEntry) = TLB_Lookup(VPN)
3 if (Success == True) // TLB Hit
4 if (CanAccess(TlbEntry.ProtectBits) == True)
5 Offset = VirtualAddress & OFFSET_MASK
6 PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
7 AccessMemory(PhysAddr)
8 else
9 RaiseException(PROTECTION_FAULT)
10 else // TLB Miss
11 PTEAddr = PTBR + (VPN * sizeof(PTE))
12 PTE = AccessMemory(PTEAddr)
13 if (PTE.Valid == False)
14 RaiseException(SEGMENTATION_FAULT)
15 else if (CanAccess(PTE.ProtectBits) == False)
16 RaiseException(PROTECTION_FAULT)
17 else
18 TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
19 RetryInstruction()Figure 19.1 TLB control flow algorithm
The general flow of the hardware algorithm is as follows: first extract the page number (VPN) from the virtual address (see Figure 19.1, line 1), and then check whether the TLB has a conversion mapping for the VPN (line 2). If so, we have a TLB hit, which means that the TLB has a conversion map for that page. success! Next, we can take the page frame number (PFN) from the related TLB entry, combine it with the offset in the original virtual address to form the desired physical address (PA), and access the memory (lines 5-7), assuming The protection check did not fail (line 4).
If the CPU does not find the conversion map in the TLB (TLB miss), we have some work to do. In this example, the hardware accesses the page table to find the translation map (lines 11-12), and uses the translation map to update the TLB (line 18), assuming that the virtual address is valid and we have the relevant access rights (line 13, 15 lines). The above series of operations are expensive, mainly because additional memory references are required to access the page table (line 12). Finally, when the TLB update is successful, the system will try the instruction again. At this time, there is this conversion mapping in the TLB, and the memory reference is quickly processed.
TLB is similar to other caches, provided that under normal circumstances, the conversion mapping will be in the cache (ie, hit). If so, only a small amount of overhead is added, because the access speed of the design is very fast near the TLB processor core. If the TLB misses, it will bring a lot of paging overhead. The page table must be accessed to find the translation map, resulting in an additional memory reference (or more, if the page table is more complex). If this happens frequently, the program will slow down significantly. Compared with most CPU instructions, memory access is expensive, and TLB misses cause more memory accesses. Therefore, we hope to avoid TLB misses as much as possible.
19.2 Example: Accessing an array
In order to clarify the operation of TLB, let's look at a simple virtual address tracing and see how TLB can improve its performance. In this example, suppose there is an array of 10 4-byte integers, and the starting virtual address is 100. Suppose further that there is a small 8-bit virtual address space with a page size of 16B. We can divide the virtual address into a 4-bit VPN (with 16 virtual memory pages) and a 4-bit offset (with 16 bytes in each page).
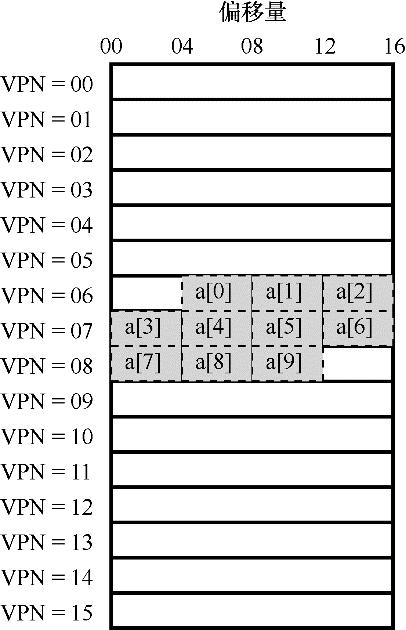
Figure 19.2 Example: An array in a small address space
Figure 19.2 shows the layout of this array on 16 16-byte pages in the system. As you can see, the first item (a[0]) of the array starts at (VPN=06, offset=04), and only three 4-byte integers are stored on this page. The array continues on the next page (VPN=07), which has the next 4 items (a[3]… a[6]). The last 3 items (a[7]… a[9]) of the 10-element array are located on the next page of the address space (VPN=08).
Now consider a simple loop, accessing each element in the array, similar to the following C program:
int sum = 0;
for (i = 0; i < 10; i++) {
sum += a[i];
}For simplicity, we pretend that the memory access generated by the loop is only for the array (ignoring the variables i and sum , and the instruction itself). When accessing the first array element (a[0]), the CPU will see the virtual memory address 100 loaded. The hardware extracts the VPN (VPN=06) from it, and then uses it to check the TLB to find a valid conversion mapping. Suppose this is the first time the program accesses the array, and the result is a TLB miss.
Next visit a[1], here is the good news: TLB hit! Because the second element of the array is after the first element, they are on the same page. Because we have already visited this page when we visited the first element of the array, the conversion map of this page is cached in the TLB. So it hits successfully. Access to a[2] is also successful (hit again) because it is on the same page as a[0] and a[1].
Unfortunately, when the program accesses a[3], it will cause a TLB miss. But again, the next few items (a[4]… a[6]) will all hit the TLB because they are on the same page in memory.
Finally, access to a[7] will result in the last TLB miss. The system will look up the page table again, figure out the location of this virtual page in physical memory, and update the TLB accordingly. The last two visits (a[8], a[9]) benefited from this TLB update. When the hardware looked up their conversion mapping in the TLB, they hit both times.
Let's summarize the behavior of the TLB in these 10 access operations: miss, hit, hit, miss, hit, hit, hit, miss, hit, hit. Dividing the number of hits by the total number of visits gives a TLB hit rate of 70%. Although this is not very high (in fact, we want the hit rate to be close to 100%), but it is not zero, and we would be surprised if it is zero. Even though this is the first time the program has accessed the array, the TLB still improves performance thanks to spatial locality. The elements of the array are stored closely in several pages (that is, they are closely adjacent in space), so only access to the first element in the page will result in a TLB miss.
Also pay attention to the effect of page size on the results of this example. If the page size doubles (32 bytes instead of 16), the array access will encounter fewer misses. The size of a typical page is generally 4KB. In this case, intensive, array-based access will achieve excellent TLB performance, and each page access will only encounter one miss.
There is one last point about TLB performance: if the program accesses the array again soon after this cycle, we will see better results, assuming that the TLB is large enough to cache the required transformation mapping: hit, hit, hit , Hit, hit, hit, hit, hit, hit, hit. In this case, due to temporal locality, which refers to the memory item again in a short period of time, the TLB hit rate will be high. Like other caches, the success of TLB relies on spatial and temporal locality. If a program exhibits such locality (as many programs do), the TLB hit rate may be high.
Tip: Use cache whenever possible
Cache is one of the most basic performance improvement techniques in computer systems, and is used time and time again to make "common situations faster" [HP06]. The idea behind hardware caching is to take advantage of the locality of instruction and data references. There are usually two types of locality: temporal locality and spatial locality. Temporal locality means that the most recently accessed instruction or data item may be accessed again soon. Think of loop variables or instructions in a loop, they are repeatedly accessed many times. Spatial locality means that when a program accesses memory address x, it may quickly access memory adjacent to x. Think about traversing some kind of array, accessing one element after another. Of course, these properties depend on the characteristics of the program, not an absolute law, but more like a rule of thumb.
Hardware cache, whether it is instructions, data, or address translation (such as TLB), takes advantage of locality to store a copy of the memory in a small and fast on-chip memory. The processor can first check whether there is a nearby copy in the cache, rather than having to access the (slow) memory to satisfy the request. If it exists, the processor can access it very quickly (for example, within a few CPU clocks) and avoid spending a lot of time accessing memory (many nanoseconds).
You may be wondering: Since a cache like TLB is so good, why not make a larger cache and hold all the data? It is a pity that here we have encountered more basic laws, just like the laws of physics. If you want to cache quickly, it must be small because the speed of light and other physical limitations will play a role. Large caches are destined to be slow, so they cannot achieve their goals. Therefore, we can only use small and fast caches. The remaining question is how to make good use of the cache to improve performance.
19.3 Who will deal with TLB misses
There is one question we must answer: who will deal with TLB misses? There may be two answers: hardware or software (operating system). The previous hardware had a complex instruction set (sometimes called Complex-Instruction Set Computer, CISC), and the people who built the hardware did not trust those who worked on the operating system. Therefore, the hardware is fully responsible for handling TLB misses. In order to do this, the hardware must know the exact location of the page table in memory (via the page-table base register, used in line 11 of Figure 19.1), and the exact format of the page table. When a miss occurs, the hardware will "traverse" the page table, find the correct page table entry, fetch the desired conversion map, update the TLB with it, and retry the instruction. This "old" architecture has TLB for hardware management. An example is the x86 architecture, which uses a fixed multi-level page table (see Chapter 20 for details). The current page table is indicated by the CR3 register [I09 ].
More modern architectures (for example, MIPS R10k [H93], Sun’s SPARC v9 [WG00], are reduced instruction set computers, Reduced-Instruction Set Computer, RISC), there are so-called software-managed TLB (software-managed TLB) ). When a TLB miss occurs, the hardware system will throw an exception (see Figure 19.3, line 11), which will suspend the current instruction flow, raise the privilege level to kernel mode, and jump to the trap handler. Next, as you might have guessed, this trap handler is a piece of code of the operating system to handle TLB misses. When this code is running, it will look up the conversion map in the page table, then update the TLB with a special "privileged" instruction, and return from the trap. At this time, the hardware will retry the instruction (causing a TLB hit).
1 VPN = (VirtualAddress & VPN_MASK) >> SHIFT
2 (Success, TlbEntry) = TLB_Lookup(VPN)
3 if (Success == True) // TLB Hit
4 if (CanAccess(TlbEntry.ProtectBits) == True)
5 Offset = VirtualAddress & OFFSET_MASK
6 PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
7 Register = AccessMemory(PhysAddr)
8 else
9 RaiseException(PROTECTION_FAULT)
10 else // TLB Miss
11 RaiseException(TLB_MISS)Figure 19.3 TLB control flow algorithm (operating system processing)
A few important details are discussed next. First of all, the return from trap instruction here is slightly different from the previously mentioned return from trap that serves system calls. In the latter case, returning from the trap should continue to execute the instruction after the operating system is trapped, just like returning from a function call, it will continue to execute the statement after the call. In the former case, after returning from the TLB missed trap, the hardware must continue execution from the instruction that caused the trap. This retry will therefore cause the instruction to be executed again, but this time it will hit the TLB. Therefore, according to the cause of the trap or exception, the system must save a different program counter when it gets into the kernel so that it can continue to execute correctly in the future.
Second, when running TLB miss handling code, the operating system needs to be extra careful to avoid infinite recursion that causes TLB misses. There are many solutions, for example, you can put TLB miss trap handlers directly into physical memory [they are not mapped (unmapped), without address translation]. Or keep some items in the TLB, record the permanent and valid address translation, and leave some of the permanent address translation slot blocks to the processing code itself. These wired address translations will always hit the TLB.
The main advantage of the software management method is flexibility: the operating system can use any data structure to implement the page table without changing the hardware. Another advantage is simplicity. It can be seen from the TLB control flow (see line 11 of Figure 19.3, compared to lines 11 to 19 of Figure 19.1) that the hardware does not need to do much work on misses, it throws exceptions, and the operating system’s miss handling The program will take care of the rest.
Supplement: RISC and CISC
In the 1980s, there was a heated discussion in the field of computer architecture. One is the CISC camp, that is, Complex Instruction Set Computing (Complex Instruction Set Computing), and the other is RISC, that is, Reduced Instruction Set Computing (Reduced Instruction Set Computing) [PS81]. The RISC camp is represented by David Patterson of Berkeley and John Hennessy of Stanford (they wrote some very famous books [HP06]), although John Cocke later won the Turing Award for his early work on RISC [CM00].
The CISC instruction set tends to have many instructions, and each instruction is more powerful. For example, you might see a string copy that accepts two pointers and a length, and copies some bytes from the source to the target. The idea behind CISC is that instructions should be high-level primitives, which makes assembly language itself easier to use and more compact code.
The RISC instruction set is just the opposite. The key point behind RISC is that the instruction set is actually the ultimate goal of the compiler, and all compilers actually require a small number of simple primitives that can be used to generate high-performance code. Therefore, RISC advocates advocate that unnecessary things (especially microcode) should be removed from the hardware as much as possible, and the remaining things should be simple, unified, and fast.
Early RISC chips had a huge impact because they were significantly faster [BC91]. People wrote many papers, and some related companies were established one after another (such as MIPS and Sun). But over time, CISC chip manufacturers like Intel have adopted many of the advantages of RISC chips, such as adding early pipeline stages to convert complex instructions into some micro-instructions, so they can run like RISC. These innovations, coupled with the increase in the number of transistors in each chip, have allowed CISC to remain competitive. The controversy finally subsided, and now both types of processors can run very fast.
19.4 TLB content
Let's take a closer look at the contents of the hardware TLB. A typical TLB has 32, 64 or 128 items, and is fully associative. Basically, this means that an address map may exist anywhere in the TLB, and the hardware will look up the TLB in parallel to find the desired conversion map. The content of a TLB entry may look like the following:
VPN | PFN | Other bits
Note that VPN and PFN exist in the TLB at the same time, because an address mapping may appear anywhere (in hardware terms, TLB is called a fully-associative cache). The hardware looks for these items in parallel to see if there is a match.
Supplement: the effective bit of TLB! = the effective bit of the page table
A common mistake is to confuse the effective bit of the TLB and the effective bit of the page table. In the page table, if a page table entry (PTE) is marked as invalid, it means that the page has not been requested for use by the process, and the normally running program should not access the address. When a program tries to access such a page, it will fall into the operating system, and the operating system will kill the process.
The effective bit of TLB is different, it just points out whether the TLB item is a valid address mapping. For example, when the system is started, all TLB entries are usually initialized to an invalid state because there is no address translation map cached here. Once the virtual memory is enabled, when the program starts to run and accesses its own virtual address, the TLB will be filled up slowly, so valid items will quickly fill up the TLB.
The TLB valid bit plays an important role in system context switching, which we will discuss further later. By setting all TLB items as invalid, the system can ensure that the process to be run will not mistakenly use the virtual-to-physical address translation mapping of the previous process.
More interesting is the "other bits". For example, TLB usually has a valid bit, which is used to identify whether the item is a valid conversion map. There are usually some protection bits to identify whether the page has access rights. For example, the code pages are identified as readable and executable, while the pages of the heap are identified as readable and writable. There are other bits, including address-space identifier (address-space identifier), dirty bit, etc. More information will be introduced below.
19.5 TLB handling during context switching
With TLB, when switching between processes (and therefore address space switching), you will face some new problems. Specifically, the virtual-to-physical address mapping contained in the TLB is only valid for the current process and has no meaning for other processes. Therefore, when a process switch occurs, the hardware or operating system (or both) must take care to ensure that the process that is about to run does not misread the address map of the previous process.
In order to better understand this situation, let's look at an example. When a process (P1) is running, assume that the TLB caches the address mapping valid for it, that is, the page table from P1. For this example, suppose that the virtual page number 10 of P1 is mapped to the physical frame number 100.
In this example, suppose there is another process (P2), and the operating system soon decides to perform a context switch and run P2. It is assumed here that the virtual page number 10 of P2 is mapped to the physical frame number 170. If the address mappings of these two processes are in the TLB, the contents of the TLB are shown in Table 19.1.
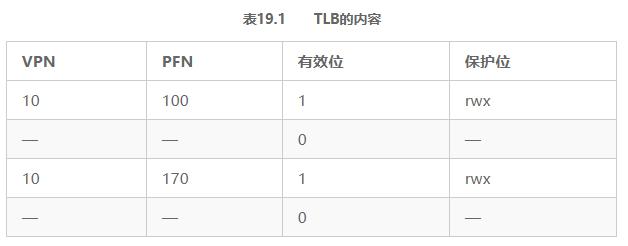
In the above TLB, there is obviously a problem: VPN 10 is converted to PFN 100 (P1) and PFN 170 (P2), but the hardware cannot tell which item belongs to which process. So we still need to do some work to make TLB correctly and efficiently support virtualization across multiple processes. Therefore, the key questions are:
The key question: how to manage the content of TLB during process switching
If an inter-process context switch occurs, the address mapping of the previous process in the TLB is meaningless for the process to be run. What should the hardware or operating system do to solve this problem?
There are some possible solutions to this problem. One method is to simply flush the TLB during context switching, so that the TLB becomes empty before the new process runs. If it is a software management TLB system, it can be done through an explicit (privileged) instruction when a context switch occurs. If it is a hardware management TLB, you can clear the TLB when the content of the page table base register changes (note that the operating system must change the value of the page table base register (PTBR) during context switching). In either case, the clearing operation sets all valid bits (valid) to 0, essentially clearing the TLB.
Clearing the TLB during context switching is a feasible solution, and the process will no longer read the wrong address mapping. However, there is a certain overhead: every time a process runs, when it accesses data and code pages, it triggers a TLB miss. If the operating system switches processes frequently, this overhead will be high.
In order to reduce this overhead, some systems have added hardware support to achieve cross-context switching TLB sharing. For example, some systems add an Address Space Identifier (ASID) to the TLB. You can think of ASID as a Process Identifier (PID), but it usually has fewer bits than PID (PID is generally 32 bits, and ASID is generally 8 bits).
If we still take the above TLB as an example and add the ASID, it is clear that different processes can share the TLB: as long as the ASID field is used to distinguish the indistinguishable address mapping. Table 19.2 shows the TLB after adding the ASID field.
Table 19.2 TLB after adding ASID field
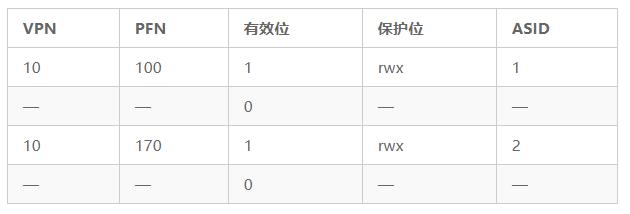
Therefore, with the address space identifier, the TLB can cache the address space mappings of different processes at the same time without any conflict. Of course, the hardware also needs to know which process is currently running in order to perform address translation. Therefore, the operating system must set a certain privileged register as the ASID of the current process during context switching.
In addition, you may have thought of another situation, two of the TLB are very similar. In Table 19.3, two items belonging to two different processes point two different VPNs to the same physical page.
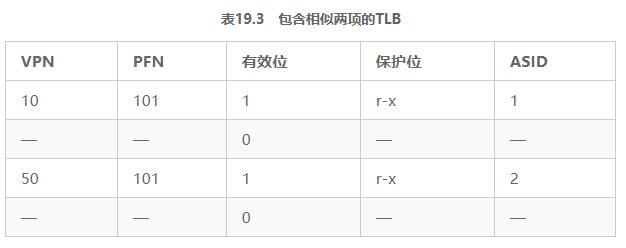
This can happen if two processes share the same physical page (for example, a page of a code segment). In the above example, process P1 and process P2 share physical page 101, but P1 maps its virtual page 10 to this physical page, and P2 maps its virtual page 50 to the physical page. Shared code pages (in binary or shared libraries) are useful because it reduces the use of physical pages, thereby reducing memory overhead.
19.6 TLB replacement strategy
TLB, like other caches, has another issue to consider, that is, cache replacement. Specifically, when a new item is inserted into the TLB, an old item is replaced (replace), so the question is: which one should be replaced?
Key question: how to design a TLB replacement strategy
When adding a new item to the TLB, which old item should be replaced? The goal is of course to reduce the TLB miss rate (or increase the hit rate), thereby improving performance.
We will study this strategy in detail when discussing the issue of page swapping out to disk. Here we briefly point out a few typical strategies. A common strategy is to replace the least-recently-used (LRU) items. LRU attempts to take advantage of the locality in the memory reference stream, assuming that items that have not been used recently may be good swap-out candidates. Another typical strategy is random (random) strategy, that is, randomly select an item to exchange. This strategy is simple and can avoid an extreme situation. For example, a program accesses n +1 pages in a loop , but the TLB size can only store n pages. At this time, the seemingly "reasonable" LRU strategy will behave unreasonably, because every access to the memory will trigger a TLB miss, and the random strategy is much better in this case.
19.7 TLB entries of the actual system
Finally, we briefly look at the real TLB. This example comes from MIPS R4000 [H93], which is a modern system that uses software to manage TLB. Figure 19.4 shows a slightly simplified MIPS TLB term.

Figure 19.4 TLB items of MIPS
MIPS R4000 supports a 32-bit address space with a page size of 4KB. So in a typical virtual address, expect to see a 20-bit VPN and a 12-bit offset. However, as you can see in the TLB, there are only 19-bit VPNs. In fact, the user address only occupies half of the address space (the rest is reserved for the kernel), so only a 19-bit VPN is required. VPN is converted into a maximum 24-bit physical frame number (PFN), so it can support systems with up to 64GB of physical memory (224 4KB memory pages).
MIPS TLB also has some interesting markers. For example, the global bit (Global, G) is used to indicate whether this page is globally shared by all processes. Therefore, if the global position is 1, the ASID is ignored. We have also seen the 8-bit ASID, which is used by the operating system to distinguish process space (as described above). Here is a question: what if the number of running processes exceeds 256 (28)? Finally, we see 3 coherence bits (Coherence, C), which determine how the hardware caches the page (one of which is beyond the scope of this book); the dirty bit (dirty) indicates whether the page is written with new data ( The usage will be introduced later); the valid bit (valid) tells the hardware whether the address mapping of the item is valid. There is also a page mask field, not shown in Figure 19.4, to support different page sizes. Later, I will explain why a larger page might be useful. Finally, some of the 64 bits are unused (the gray part in Figure 19.4).
MIPS TLB usually has 32 items or 64 items, most of which are provided for user processes, and a small part is reserved for operating systems. The operating system can set a monitored register to tell the hardware how many TLB slots it needs to reserve for itself. These reserved conversion mappings are used by the operating system for the code and data that it uses at critical times. At these times, TLB misses may cause problems (for example, in TLB miss handlers).
Since the TLB of MIPS is managed by software, the system needs to provide some instructions to update the TLB. MIPS provides four such instructions: TLBP, used to find whether the specified conversion mapping is in the TLB; TLBR, used to read the contents of the TLB into the specified register; TLBWI, used to replace the specified TLB item; TLBWR , Used to randomly replace a TLB item. The operating system can use these instructions to manage the contents of the TLB. Of course these instructions are privileged instructions, which is critical. If the user program can modify the contents of the TLB arbitrarily, you can imagine what terrible things will happen.
Tip: RAM is not always RAM (Culler's Law)
Random-Access Memory (RAM) implies that you can access any part of RAM as fast. Although it is generally correct to think of RAM this way, because of hardware/operating system functions such as TLB, accessing some memory pages is expensive, especially pages that are not cached by TLB. Therefore, it is best to remember this implementation trick: RAM is not always RAM. Sometimes random access to the address space, especially pages that are not cached by the TLB, can cause severe performance losses. Because one of my mentors, David Culler, used to point out that TLB is the source of many performance problems, we named this law after him: Culler's Law.
This article is taken from "Introduction to Operating Systems"

This book focuses on the three main concepts of virtualization, concurrency, and persistence, and introduces the main components of all modern systems (including scheduling, virtual memory management, disk and I/O subsystems, and file systems). The book consists of 50 chapters, divided into 3 parts, which are about virtualization, concurrency and persistence. The author introduces the introduced thematic concepts in the form of dialogue, and the witty and humorous writing is also included, trying to help readers understand the principles of virtualization, concurrency and persistence in operating systems.
The content of this book is comprehensive, and it provides real and runnable code (not pseudo-code), and provides corresponding exercises, which is very suitable for teachers of related majors in colleges and universities to carry out teaching and college students to conduct self-study.
This book has the following characteristics:
● The theme is prominent, and it closely surrounds the three major thematic elements of the operating system-virtualization, concurrency, and persistence.
● Introduce the background in the way of dialogue, ask questions, explain the principles, and inspire hands-on practice.
● Contains many "supplements" and "hints" to expand readers' knowledge and increase interest.
● Use real code instead of pseudo code to allow readers to have a deeper and thorough understanding of the operating system.
● Provide many learning methods such as assignments, simulations and projects to encourage readers to practice.
● Provide teachers with auxiliary teaching resources.