table of Contents
8.1.2 Further improve recognition accuracy
8.2 A small history of deep learning
8.3.4 Reduction of digits of operation precision
8.4 Application cases of deep learning
8.4.3 Generation of image title
8.5.4 Deep Q-Network (Reinforcement Learning)
Deep learning
On the basis of CNN, you can create a deep network just by overlaying layers
8.1 Deepen the network

This network uses the initial value of He as the initial value of the weight , and uses Adam to update the weight parameters .
To sum up the above content, this network has the following characteristics
- Convolutional layer based on 3×3 small filters.
- The activation function is ReLU.
- The Dropout layer is used behind the fully connected layer .
- Based on Adam optimal technology.
- Use the initial value of He as the initial value of the weight .
The recognition progress is as high as 99.38%
The wrong picture :
8.1.2 Further improve recognition accuracy
We can use integrated learning, learning rate decay, Data Augmentation, etc. to help improve recognition accuracy.
Data Augmentation "artificially" augments the input image (training image) based on an algorithm . Specifically
Data Augmentation can also expand the image through various other methods, such as "crop processing" to crop the image, "fl ip processing" A to flip the image left and right, etc.

8.1.3 Deepened motivation
The deeper the layer, the higher the recognition performance

Next, let's think about the situation where the 3 × 3 convolution operation is repeated twice in Figure 8-6 .
The area of a 5 × 5 convolution operation can be offset by two 3 × 3 convolution operations.
By superimposing convolutional layers , the number of parameters is reduced. Moreover, the difference in the number of parameters will increase as the layer deepens
Specifically:
When the 3 × 3 convolution operation is repeated three times, the total number of parameters is 27. In order to "observe" the same area with a convolution operation, a 7 × 7 filter is required, and the number of parameters at this time is 49.
The advantage of superimposing a small filter to deepen the network is that it can reduce the number of parameters, expand the receptive field, and apply changes to a certain local spatial area of the neuron) and, through the superimposed layer, sandwich activation functions such as ReLU in the volume The middle of the stack further improves the expressiveness of the network . This is because the "non-linear" expressive power based on the activation function is added to the network, and more complicated things can be expressed through the superposition of non-linear functions.
8.2 A small history of deep learning
8.2.1 ImageNet
ImageNet is a data set with more than 1 million images.
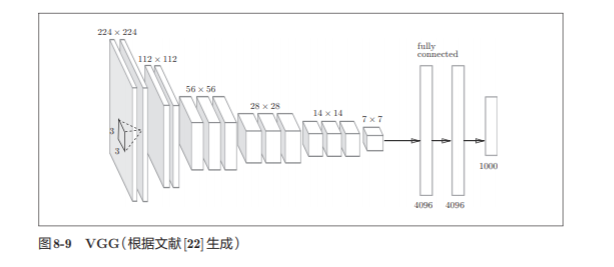
8.2.2 VGG
VGG is a basic CNN composed of a convolutional layer and a pooling layer
It is characterized by superimposing the weighted layer (convolutional layer or fully connected layer) to 16 layers (or 19 layers), with depth (according to the depth of the layer, sometimes called "VGG16" or "VGG19").
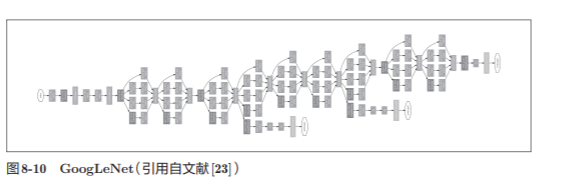
8.2.3 GoogLeNet
The network structure of GoogLeNet is shown in Figure 8-10. The rectangles in the figure represent convolutional layers, pooling layers, etc.

8.2.4 ResNet
It is characterized by a deeper structure than the previous network .

In practice, the weight data learned using ImageNet, a huge data set , is often used flexibly . This is called transfer learning . Copy (part of) the learned weights to other neural networks for fine tuning .
For example, prepare a network with the same structure as VGG, take the learned weight as the initial value, and use the new data set as the object for relearning.
Transfer learning is very effective when there are fewer data sets at hand .
8.3 Speeding up deep learning
Most deep learning frameworks support GPU (Graphics Processing Unit)
8.3.1 Problems to be solved
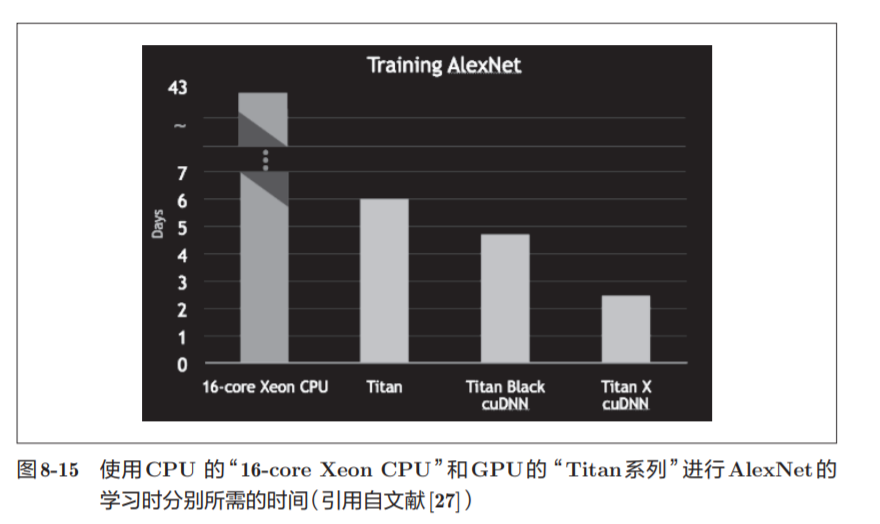
In AlexNex, most of the time is spent on the convolutional layer
The processing time of the convolutional layer adds up to 95% of the overall GPU and 89% of the overall CPU

8.3.2 GPU-based high speed
The goal of GPU computing is to use this overwhelming computing power for various purposes.
Deep learning requires a lot of multiplication and accumulation operations (or product operations of large matrices). This large number of parallel operations is what GPUs are good at (in turn, CPUs are better at continuous and complex calculations).
GPUs are mainly provided by NVIDIA and AMD. Although both GPUs can be used for general-purpose numerical calculations, NVIDIA's GPUs are "closer" to deep learning.
Based on im2col, the calculation is summarized by the product of large matrices, which makes it easier to use the GPU's capabilities.
8.3.3 Distributed learning

8.3.4 Reduction of digits of operation precision
8.4 Application cases of deep learning
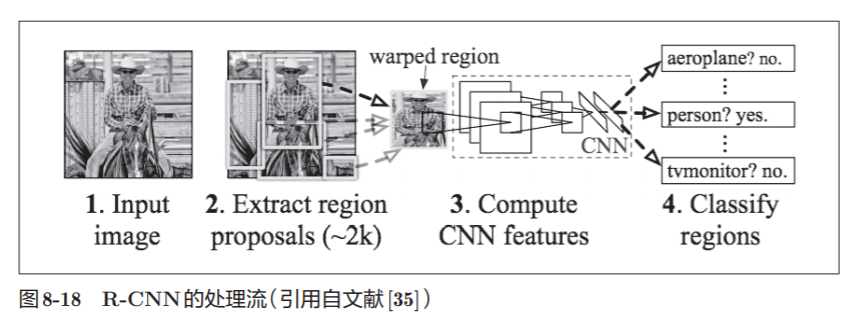
8.4.1 Object detection

Among the methods of object detection using CNN, there is a well-known method called R-CNN .
8.4.2 Image segmentation
As shown in Figure 8-19, use the supervised data to color each object in pixel as a unit for learning

In the convolution operation, meaningless calculations that repeatedly calculate many areas will occur)
It was suggested that a group called FCN (Fully Convolutional Network) FCN literally means " all network consisting of convolution layer network"

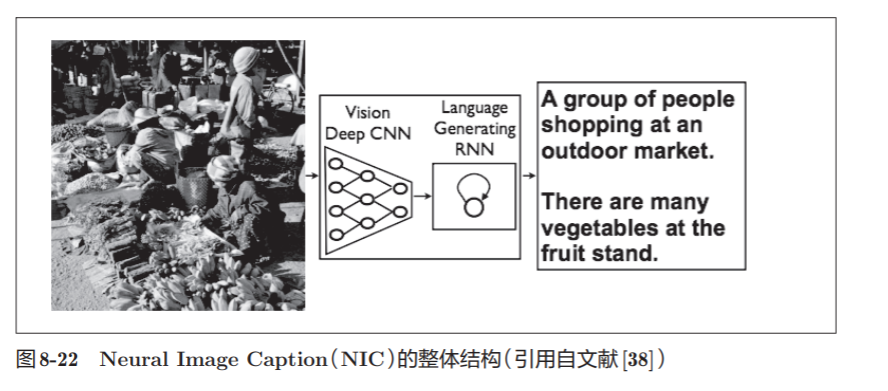
8.4.3 Generation of image title
There is an interesting blend of research in computer vision and natural language, the study shown in Figure 8-21, after a given image, self-will automatically generate text describes this image (title of the image).
A representative method of generating image captions based on deep learning is a model called NIC (Neural Image Caption) . We call the processing of combining multiple information such as images and natural language as multi-modal processing. Multimodal processing is an area that has attracted much attention in recent years.
8.5.1 Image style change
One study uses deep learning to "draw" artistic paintings. As shown in Figure 8-23, after inputting two images, a new image will be generated. Of the two input images, one is called "content image" and the other is called "style image".

8.5.2 Image generation
Now generate "bedroom" images from scratch

The image generated by DCGAN is an image that no one has seen before (an image that is not in the learning data), a new image generated from zero
8.5.3 Autonomous driving
8.5.4 Deep Q-Network (Reinforcement Learning)
Just like humans learn through groping and experimentation (such as riding a bicycle), let the computer learn independently in the process of groping and experimentation. This is called reinforcement learning (reinforcement learning).
The basic framework of reinforcement learning is that the agent chooses actions according to the environment, and then changes the environment through this action. According to changes in the environment, the agent gets some kind of remuneration.
Among the reinforcement learning methods that use deep learning, there is a method called Deep Q-Network (commonly known as DQN).

Application in the game:

8.6 Summary
- The main point of this chapter is to open the eyes
- For most of the questions, we can look forward pass through deeper network to improve performance .
- In the recent image recognition competition ILSVRC, deep learning-based methods have come out on top , and the network used is also deepening.
- VGG, GoogLeNet, ResNet, etc. are several well-known networks .
- Based GPU, distributed learning, the median reduction in accuracy, can be achieved now speed the depth of learning .
- Deep learning (neural network) can be used not only for object recognition , but also for object detection and image segmentation.
- Deep learning applications include image title generation, image generation, and reinforcement learning .
- Recently, the application of deep learning in autonomous driving is also highly anticipated.