1. What is data mining
Data mining is the process of automatically discovering useful information in a large data repository .
Data mining techniques are used to explore large databases and find useful patterns that were previously unknown. Data mining can also predict future observations.
Not all information discovery tasks are considered data mining. For example, searching for individual records using a database management system, or searching for specific Web pages through Internet search engines, is a task in the field of information retrieval. Although these tasks are very important and may involve the use of complex algorithms and data structures, they mainly rely on traditional computer science techniques and the obvious characteristics of data to create an index structure to effectively organize and retrieve information. Nevertheless, people are also using data mining technology to enhance the capabilities of information retrieval systems.
Data mining and knowledge discovery
Data mining is an indispensable part of knowledge discovery in database (KDD) , and KDD is the entire process of converting raw data into useful information, as shown in Figure 1. The process includes a series of transition steps, from data preprocessing to post-processing of data mining results.

Input data can be stored in various forms (flat files, spreadsheets, or relational tables), and can reside in a centralized data repository or distributed across multiple sites. The purpose of data preprocessing is to convert raw input data into a form suitable for analysis. The steps involved in data preprocessing include fusing data from multiple data sources, cleaning the data to eliminate noise and repeated observations, and selecting records and features related to the current data mining task. Due to the various ways of collecting and storing data, data preprocessing may be the most laborious and time-consuming step in the entire knowledge discovery process.
"Closing the loop" usually refers to the process of integrating data mining results into a decision support system. For example, in commercial applications, the laws revealed by the results of data mining can be combined with commercial activity management tools to carry out or test effective product promotion activities. Such binding require post-treatment (Postprocessing Use) steps to ensure that effective and useful results will only be integrated into the decision support system spring. An example of post-processing is visualization , which allows data analysts to explore data and data mining results from various perspectives. In the post-processing stage, statistical measures or hypothesis testing can also be used to remove false data mining results.
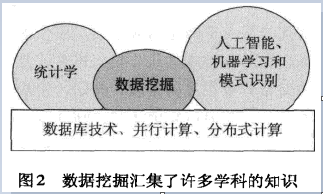
Figure 2 shows the connection between data mining and other fields .
2. Problems to be solved by data mining
(1) Scalable . Due to advances in data generation and collection technology, data sets of gigabytes, terabytes, and even petabytes are becoming more and more common. If the data mining algorithm is to process these massive data sets , the algorithm must be scalable. Many data mining algorithms use special search strategies to deal with exponential search problems. In order to achieve scalability may also need to implement a new data structure in order to access each record in an efficient manner. For example, when the data to be processed cannot be put into memory, non-memory algorithms may be required. The use of sampling techniques or the development of parallel and distributed algorithms can also increase scalability.
(2) High dimensionality . Nowadays, we often encounter datasets with hundreds or thousands of attributes , instead of datasets with only a few attributes that were common decades ago. In the field of bioinformatics, advances in microarray technology have produced gene expression data involving thousands of features. Data sets that have time or space components also often have very high dimensions. For example, consider a data set containing temperature measurement results in different regions. If the measurement is repeated over a long period of time, the increase in the dimension (number of features) is proportional to the number of measurements. Traditional data analysis techniques developed for low-dimensional data usually cannot handle such high-dimensional data well. In addition, for some data analysis algorithms, as the dimension (number of features) increases, the computational complexity increases rapidly.
(3) Heterogeneous data and complex data . Usually, traditional data analysis methods only deal with data sets containing the same type of attributes, either continuous or classified. With the increasing role of data mining in business, science, medicine, and other fields, there is an increasing need for technologies that can handle heterogeneous attributes (including different types of attributes, discontinuous, unclassified, etc.) . In recent years, more complex data objects have emerged. Examples of these non-traditional data types are: web page collections containing semi-structured text and hyperlinks, DNA data with sequence and three-dimensional structure, and time series measurements (temperature, air pressure, etc.) at different locations on the earth’s surface Meteorological data. The technology developed for mining such complex objects should consider the connections in the data, such as the autocorrelation of time and space, the connectivity of graphs, semi-structured text, and the parent-child connection between elements in XML documents.
(4) Ownership and distribution of data . Sometimes, the data that needs to be analyzed is not stored in one site or belongs to one organization, but is geographically distributed among resources belonging to multiple organizations . This requires the development of distributed data mining technology. The main challenges faced by distributed data mining algorithms include: (1) How to reduce the amount of communication required to perform distributed computing? (2) How to effectively unify the data mining results obtained from multiple sources? (3) How to deal with data security issues?
(5) Non-traditional analysis . Traditional statistical methods are based on a hypothesis-testing model, that is, proposing a hypothesis, designing experiments to collect data, and then analyzing the data against the hypothesis. However, this process is laborious. Current data analysis tasks often need to generate and evaluate thousands of hypotheses, so hypotheses need to be generated and evaluated automatically , which has prompted people to develop some data mining techniques. In addition, the data sets analyzed by data mining are usually not the results of well-designed experiments, and they usually represent an opportunistic sample of data, rather than a random sample. Moreover, these data sets often involve non-traditional data types and data distributions.
3. Data mining tasks
Generally, data mining tasks are divided into the following two categories .
- Forecast tasks . The goal of these tasks is to predict the value of a particular attribute based on the value of other attributes. The predicted attribute is generally called target variable or dependent variable, and the attribute used for prediction is called explanatory variable or independent variable
- Describe the task . The goal is to derive patterns (correlations, trends, clusters, trajectories, and anomalies) that summarize potential connections in the data.
In essence, descriptive data mining tasks are usually exploratory and often require post-processing techniques to verify and interpret the results.
Figure 3 shows the four main data mining tasks .

(1) Predictive modeling involves establishing a model for the target variable in a way that describes the function of the variable. There are two types of predictive modeling tasks:
- Classification , used to predict discrete target variables;
- Regression is used to predict continuous target variables.
For example, predicting whether a web user will buy a book in an online bookstore is a classification task because the target variable is binary, while predicting the future price of a stock is a regression task because the price has a continuous value attribute. The goal of both tasks is to train a model to minimize the error between the predicted value of the target variable and the actual value. Predictive modeling can be used to determine the customer's response to product promotions, predict the disturbance of the earth's ecosystem, or determine whether the patient has a certain disease based on the results of the examination.
(2) Association analysis is used to discover patterns that describe strong association features in data. The patterns found are usually expressed in the form of implication rules or feature subsets. Since the search space is exponential, the goal of association analysis is to extract the most interesting patterns in an efficient way.
The application of association analysis : find out the genomes with related functions, identify the Web pages that users visit together, understand the connections between different elements of the earth's climate system, etc.
(3) Cluster analysis (cluster-analysis) and discover closely related groups of observations, so that compared with observations belonging to different clusters, observations belonging to the same family are as similar as possible to each other.
Application of cluster analysis : group related customers, find out ocean areas that significantly affect the earth's climate, and compress data.
(4) The task of anomaly detection (anomaly.detection) is to identify observations whose features are significantly different from other data. Such observations are called anomaly or outlier. The goal of the anomaly detection algorithm is to find the true reward points, and avoid incorrectly marking normal objects as abnormal points. In other words, a good anomaly detector must have a high detection rate and a low false alarm rate.
The application of anomaly detection : detection of fraud, network attacks, unusual patterns of diseases, ecosystem disturbances, etc.
Reference material: << Introduction to Data Mining >> written Pang-Ning Tan, Michael Steinbach, Vipin Kumar, etc.