This series of related blog, Mu class reference column Java source code and system manufacturers interviewer succinctly Zhenti
below this column is GitHub address:
Source resolved: https://github.com/luanqiu/java8
article Demo: HTTPS: // GitHub. com / luanqiu / java8_demo
classmates can look at it if necessary)
Java source code analysis and interview questions-overall design: queue design ideas, work scenarios
In
this chapter, we have studied four types of queues: LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue, and DelayQueue. The underlying data structures of the four types of queues are different, and the usage scenarios are also different. In this chapter, we will make some comparisons between the design ideas and the usage scenarios. to sum up.
1 Design ideas
First of all, we draw the overall design of the queue:
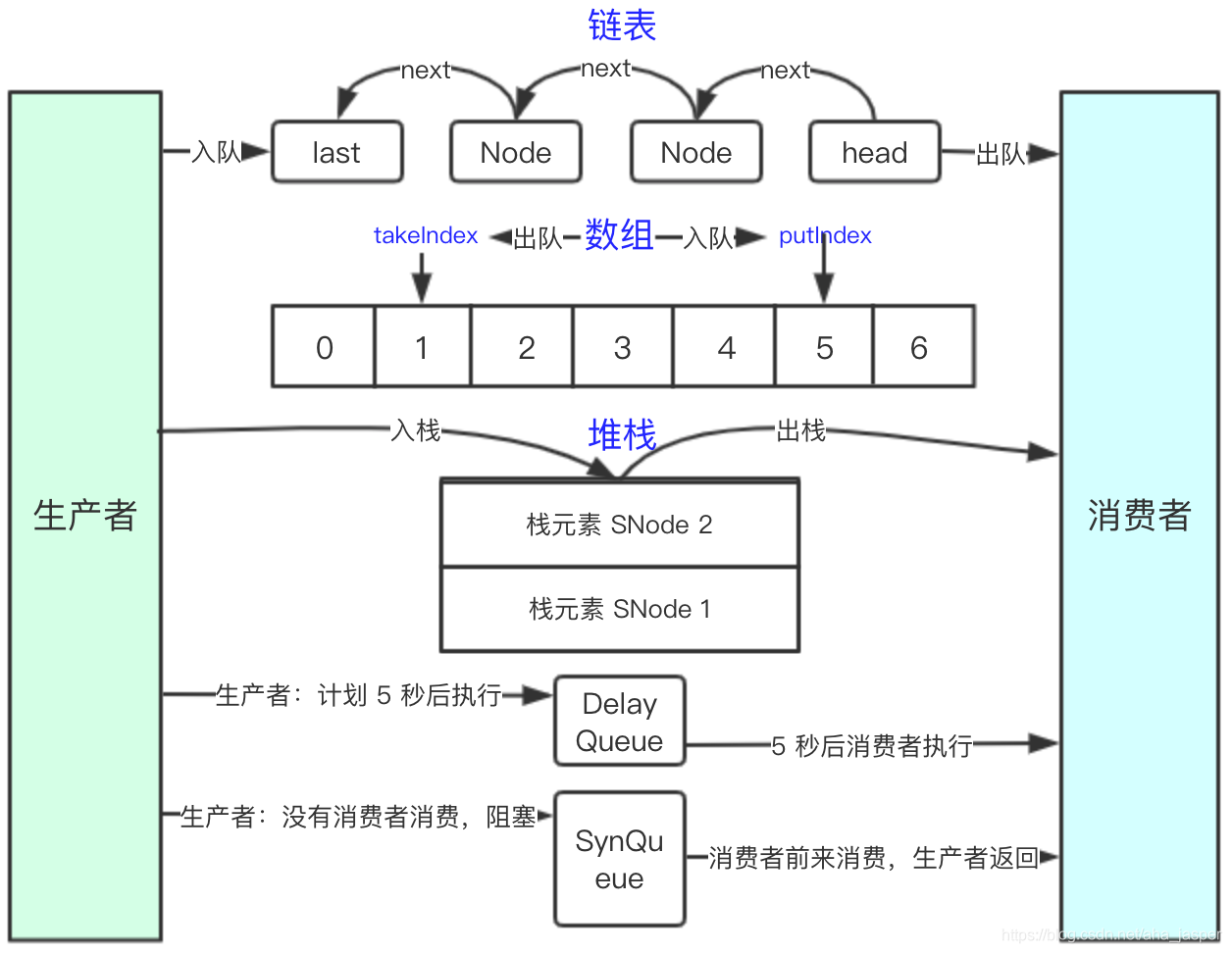
from the figure we can see several points:
- Queue decouples producers and consumers, and provides multiple forms of the relationship between producers and consumers. For example, LinkedBlockingQueue and ArrayBlockingQueue decouple producers and consumers. For example, SynchronousQueue, the producer Correspondence with consumers (producers can only return after the consumer's message has been consumed by the consumer. For convenience of understanding, use the term mutual correspondence);
- Different queues have different data structures, including linked lists (LinkedBlockingQueue), arrays (ArrayBlockingQueue), stacks (SynchronousQueue), etc .;
- Different data structures determine that the posture for entering and leaving the team is different.
Next, we will summarize and analyze according to these aspects.
1.1 Data structure of the queue
The queue of the linked list structure is LinkedBlockingQueue, and its characteristics are as follows:
- The initial size is the maximum value of Integer by default, and the initial size can also be set;
- Linked list elements are associated with the next element through the next attribute;
- The new addition is from the tail of the linked list, and the start is from the head of the linked list.
The queue of the array structure is ArrayBlockingQueue, which has the following characteristics:
- The capacity is fixed and cannot be expanded dynamically;
- There are two indexes, takeIndex and putIndex, to record the next position to take and add;
- When takeIndex and putIndex reach the last position of the array, the loop will start from 0 next time.
SynchronousQueue has two data structures, queue and stack, which are characterized as follows:
- The queue guarantees a first-in first-out data structure, which reflects fairness;
- The stack is a first-in, first-out data structure, which is unfair, but the performance is higher than the first-in, first-out.
1.2 Ways to join and leave the team
Different queues have different data structures, leading to different ways of entering and leaving the queue:
- The linked list is directly added to the end of the team when entering the team, and the data is taken from the head of the list when leaving the team;
- The array has two index positions, takeIndex and putIndex, to record the next pick and take position, such as the overall design, the enqueue directly points to putIndex, and the outgoing team points to takeIndex;
- The stack is mainly carried on and off the stack head.
1.3 Communication mechanism between producers and consumers
From the four queues, we can see that there are two communication mechanisms between producers and consumers, one is strong association and the other is non-association.
- Strong correlation mainly refers to the SynchronousQueue queue. The producer puts data into the queue. If there is no consumer consumption at this time, the producer will always block and cannot return; the consumer comes to the queue to fetch data. If the queue is at this time There is no data in it, consumers will always block, so in the SynchronousQueue queue model, producers and consumers are strongly associated. If only one of them exists, it will only block and cannot transfer data.
- Non-association mainly refers to queues with data storage functions, such as LinkedBlockingQueue and ArrayBlockingQueue. As long as the queue container is not full, the producer can be successful and the producer can return directly. There is no relationship with consumers. The producer and Consumers are completely decoupled, decoupling through the storage function of the queue container.
2 Use scenarios in work
In our daily work, we need to match business scenarios according to the characteristics of the queues to decide which queues to use. We summarize the suitable scenarios for each queue:
2.1 LinkedBlockingQueue
It is suitable for scenarios where the size of the production data is uncertain (time is high and time is low) and the amount of data is large. For example, when we buy something on Taobao and click the order button, the system corresponding to the background is called the order system. The order system will Put all the order requests into a thread pool. At this time, when we initialize the thread pool, we generally choose LinkedBlockingQueue and set a suitable size. At this time, the main reason for choosing LinkedBlockingQueue is: within the threshold we set. The size of the queue can be large or small, without any performance loss, just in line with the characteristics of the order flow, when the time is large and small.
In general work, most of us will choose the LinkedBlockingQueue queue, but will set the maximum capacity of LinkedBlockingQueue. If the default maximum value of Integer is used directly during initialization, when the traffic is large and the consumer processing capacity is poor, a large number of requests will be in The accumulation in the queue will consume a lot of memory of the machine, which will reduce the overall performance of the machine and even cause downtime. Once the machine is down, the data in the queue will disappear, because the data in the queue is stored in memory. The data in the memory will disappear, so when using the LinkedBlockingQueue queue, it is recommended to set the appropriate queue size according to daily traffic.
2.2 ArrayBlockingQueue
It is generally used in scenarios where the production data is fixed. For example, the system will perform reconciliation every day. After the reconciliation is completed, 100 reconciliation results will be fixed. Because the reconciliation results are fixed, we can use the ArrayBlockingQueue queue. The size can be set to 100.
2.3 DelayQueue
Delay queue, often encountered in work, is mainly used when the task does not want to be executed immediately, but wants to wait for a period of time to execute.
For example, delayed reconciliation, we have encountered such a scene in our work: we buy things on Taobao, pop up Alipay payment page, at the moment we enter the fingerprint, the process is mainly front-end-"transaction back-end-" after payment At the end, the transaction backend calls the payment backend mainly to transfer our Alipay money to the merchant, and there is a small probability in the process of transaction call payment, because the network jitter will time out, this time you need to pass timely Reconciliation to solve this matter (reconciliation is only one of the means to solve this problem), we simply draw a flow chart:
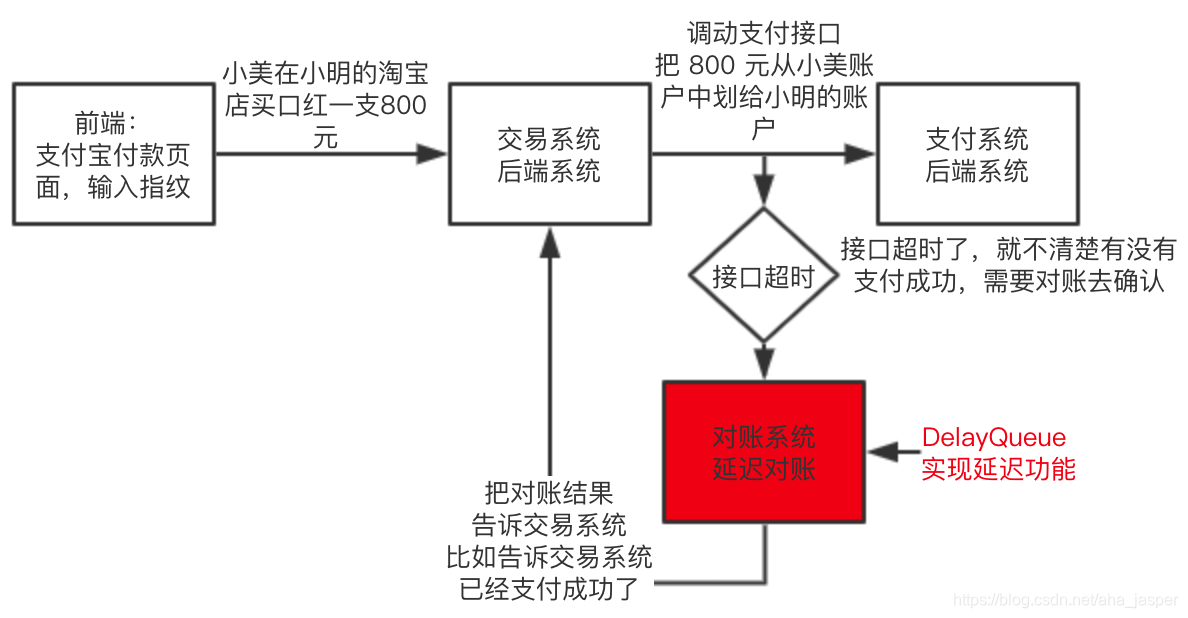
This is a real scene, for the convenience of description, has been greatly simplified, and explain a few points:
- The transaction calls the payment interface. The purpose of this interface is to transfer Xiaomei's 800 yuan to the merchant Xiaoming;
- The interface call timed out. At this time, the trading system does not know whether 800 was successfully transferred to Xiaoming. Of course, there are many ways to know. We chose the method of reconciliation. The purpose of reconciliation is to know whether the current 800 yuan is successfully transferred. Xiao Ming
- The purpose of delaying reconciliation is that it takes time for the payment system to transfer 800 yuan to the merchant Xiaoming. If the reconciliation is performed immediately after the timeout, the transfer may still be in progress, resulting in an inaccurate reconciliation result, so a delay of several seconds Then go to reconciliation;
- There are several results after the reconciliation. For example, the 800 yuan has been successfully transferred to Xiaoming. At this time, the reconciliation result needs to be communicated to the trading system. The transaction system updates the data, and the front end can show that the transfer was successful.
In this case, the core technology of delayed reconciliation is DelayQueue, we probably do this: create a new reconciliation task, set it to execute after 3 seconds, put the task in DelayQueue, after 3 seconds, it will automatically execute the Account task.
The DelayQueue delay execution function is applied in this scenario.
3 Summary
We will not read the source code in order to read the source code. The original purpose of reading the source code is to improve our technical depth. The final purpose is to select the appropriate technology for landing in different scenarios. Some queues explained in this chapter Scenes, we will actually encounter in our work, especially when using the thread pool, which queue to use is a problem we must think about, so this chapter first compares the suitable usage scenarios of each queue, and then gives a few cases to carry out Specific analysis, I hope everyone can also put the technology into practical work, so that technology can promote and assist business.
