Regular expression
Regular expressions define the pattern of strings.
Regular expressions can be used to search, edit, or process text.
Regular expressions are not limited to a certain language, but there are subtle differences in each language.
For the regular expression abc, it can only match the string "abc" exactly, not any other string such as "ab", "Abc", "abcd".
If the regular expression has special characters, it needs to be escaped with \. For example, the regular expression a & c, where & is used to match the special character &, can accurately match the string "a & c", but cannot match "ac", "ac", "a && c", etc.
It should be noted that the regular expression is also a string in the Java code, so for regular expression a & c, the corresponding Java string is "a \ & c", because \ is also an escape character of the Java string, two \ It actually represents a \:
public class Main {
public static void main(String[] args) {
String re1 = "abc";
System.out.println("abc".matches(re1));
System.out.println("Abc".matches(re1));
System.out.println("abcd".matches(re1));
String re2 = "a\\&c"; // 对应的正则是a\&c
System.out.println("a&c".matches(re2));
System.out.println("a-c".matches(re2));
System.out.println("a&&c".matches(re2));
}
}
If you want to match non-ASCII characters, such as Chinese, then use the hexadecimal representation of \ u ####, for example: a \ u548cc matches the string "a and c", the Chinese character and the Unicode encoding is 548c.
Match any character
Exact matching is actually not very useful, because you can use String.equals () directly. In most cases, the desired matching rule is more fuzzy matching. You can use. To match an arbitrary character.
For example, the. In the middle of the regular expression ac can match an arbitrary character, for example, the following strings can be matched:
- "Abc" because. Can match the character b;
- "A & c" because. Can match the character &;
- "Acc" because. Can match the character c.
But it cannot match "ac", "a && c", because. Matches one character and only one character.
Match number
You can match any character with. This opening is a bit big. If you only want to match numbers like 0 ~ 9, you can use \ d to match. For example, the regular expression 00 \ d can match:
- "007" because \ d can match the character 7;
- "008" because \ d can match the character 8.
It cannot match "00A", "0077" because \ d is limited to a single numeric character.
Match common characters
Use \ w to match a letter, number or underscore, w means word. For example, java \ w can match:
- "Javac" because \ w can match the English character c;
- "Java9" because \ w can match the numeric character 9;
- "Java_" because \ w can match the underscore _.
It cannot match "java #", "java" because \ w cannot match characters such as #, space, etc.
Match space characters
Use \ s to match a space character. Note that the space character includes not only spaces but also tab characters (in Java, it is represented by \ t). For example, a \ sc can match:
- "Ac" because \ s can match space characters;
- "Ac" because \ s can match the tab character \ t.
It cannot match "ac", "abc", etc.
Match non-numeric
Use \ d to match a number, and \ D to match a non-number. For example, 00 \ D can match:
- "00A" because \ D can match the non-numeric character A;
- "00 #" because \ D can match the non-numeric character #.
The strings "007", "008", etc. that can be matched by 00 \ d, cannot be matched by 00 \ D.
Similarly, \ W can match characters that \ w cannot match, \ S can match characters that \ s cannot match, these are just the reverse.
public class Main {
public static void main(String[] args) {
String re1 = "java\\d"; // 对应的正则是java\d
System.out.println("java9".matches(re1));
System.out.println("java10".matches(re1));
System.out.println("javac".matches(re1));
String re2 = "java\\D";
System.out.println("javax".matches(re2));
System.out.println("java#".matches(re2));
System.out.println("java5".matches(re2));
}
}
Repeat matching
Use \ d to match a number, for example, A \ d can match "A0", "A1", what if you want to match multiple numbers, such as "A380"?
The modifier can match any number of characters, including 0 characters. Use A \ d to match:
- A: Because \ d * can match 0 digits;
- A0: Because \ d * can match 1 digit 0;
- A380: Because \ d * can match multiple numbers 380.
The modifier + can match at least one character. Use A \ d + to match: - A0: Because \ d + can match 1 digit 0;
- A380: Because \ d + can match multiple numbers 380.
But it cannot match "A" because the modifier + requires at least one character.
The modifier? Can match 0 or one character. Use A \ d? To match: - A: Because \ d? Can match 0 digits;
- A0: Because \ d + can match 1 digit 0.
But it cannot match "A33" because the modifier? More than 1 character cannot match.
What if you want to specify exactly n characters? Use the modifier {n}. A \ d {3} can match exactly: - A380: Because \ d {3} can match 3 digits 380.
What if you want to specify matching n ~ m characters? Use the modifier {n, m}. A \ d {3,5} can match exactly: - A380: Because \ d {3,5} can match 3 digits 380;
- A3800: Because \ d {3,5} can match 4 numbers 3800;
- A38000: Because \ d {3,5} can match 5 digits 38000.
If there is no upper limit, the modifier {n,} can match at least n characters.
Match the beginning and end
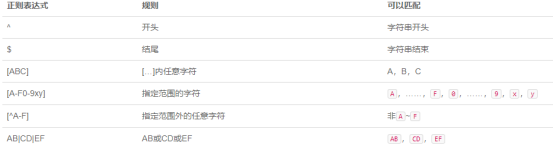
When using regular expressions to match multiple lines, use ^ to indicate the beginning, and KaTeX parse error: Undefined control sequence: \ d at position 11: to indicate the end. For example, ^ A \ ̲d̲ {3} can match "A001" and "A380".
Match the specified range
If it is specified that a 7-8 digit phone number cannot start with 0, how should the matching rule be written? \ d {7,8} will not work, because the first \ d can match 0.
Use […] to match the characters in the range, for example, [123456789] can match 1 ~ 9, so that the above telephone number rules can be written: [123456789] \ d {6,7}.
It's too much trouble to list all the characters, […] there is another way to write, just write [1-9].
To match a hexadecimal number with no upper or lower case, such as 1A2b3c, we can write: [0-9a-fA-F], which means that it can match any of the following characters in total:
- 0-9: characters 0 ~ 9;
- af: characters a ~ f;
- AF: Characters A ~ F.
If you want to match 6 hexadecimal numbers, the {n} mentioned above can still be used together: [0-9a-fA-F] {6}.
[…] There is also an exclusion method, which does not include the characters of the specified range. Suppose you want to match any character, but not numbers, you can write [^ 1-9] {3}: - Can match "ABC" because it does not contain characters 1 ~ 9;
- Can match "A00" because it does not contain characters 1 ~ 9;
- Cannot match "A01" because it contains the character 1;
- Cannot match "A05" because it contains the character 5.
Or rule matching
The two regular rules connected with | are OR rules. For example, AB | CD means that AB or CD can be matched.
public class Main {
public static void main(String[] args) {
String re = "java|php";
System.out.println("java".matches(re));
System.out.println("php".matches(re));
System.out.println("go".matches(re));
}
}
It can match "java" or "php", but not "go".
To add go to match, you can rewrite it as java | php | go.
Use parentheses
You can put the public part out, and then use (...) to enclose the sub-rules as learn \ s (java | php | go).
public class Main {
public static void main(String[] args) {
String re = "learn\\s(java|php|go)";
System.out.println("learn java".matches(re));
System.out.println("learn Java".matches(re));
System.out.println("learn php".matches(re));
System.out.println("learn Go".matches(re));
}
}
The above rules still cannot match strings such as learn Java and learn Go. Try to modify the rule so that it can match learn Java, learn Php, learn Go that start with a capital letter
Group matching
(…) Another important role is group matching.
import java.util.regex.*;
public class Main {
public static void main(String[] args) {
Pattern p = Pattern.compile("(\\d{3,4})\\-(\\d{7,8})");
Matcher m = p.matcher("010-12345678");
if (m.matches()) {
String g1 = m.group(1);
String g2 = m.group(2);
System.out.println(g1);
System.out.println(g2);
} else {
System.out.println("匹配失败!");
}
}
}
Running the above code, you will get two matching substrings 010 and 12345678.
Pay special attention to the parameters of the Matcher.group (index) method with 1 for the first substring and 2 for the second substring. Pass in 0 to get 010-12345678, that is, the entire regular matched string.
Multiple use of String.matches () to match the same regular expression multiple times is inefficient, because the same Pattern object is created every time. You can create a Pattern object first, and then use it repeatedly, you can compile once and match many times.
import java.util.regex.*;
public class Main {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("(\\d{3,4})\\-(\\d{7,8})");
pattern.matcher("010-12345678").matches(); // true
pattern.matcher("021-123456").matches(); // true
pattern.matcher("022#1234567").matches(); // false
// 获得Matcher对象:
Matcher matcher = pattern.matcher("010-12345678");
if (matcher.matches()) {
String whole = matcher.group(0); // "010-12345678", 0表示匹配的整个字符串
String area = matcher.group(1); // "010", 1表示匹配的第1个子串
String tel = matcher.group(2); // "12345678", 2表示匹配的第2个子串
System.out.println(area);
System.out.println(tel);
}
}
}
When using Matcher, you must first call matches () to determine whether the match is successful. After matching, you can call group () to extract the substring.
