The biggest problem of the AB experiment in the recommendation-flow bias and solution: overlapping experiment architecture
The flow is unbiased. This is the biggest and the most difficult problem of traffic distribution. When only one experiment is done at the same time, the problem is not obvious, but if you want to do multiple experiments at the same time, how to avoid the impact of the previous experiment on the latter experiment, this effect is the flow bias, which means that in the flow distribution of the previous experiment There is a potential factor that affects the flow distribution. This potential factor is not easy to be noticed. If the potential factor affects the experimental results, it is difficult to get an objective conclusion in the experiment that obtains traffic behind this experiment. This no-offset requirement is also called "orthogonal".
Overlapping experimental architecture
The so-called overlap experiment is a flow from entering the product service, and finally returning the result to the user. There are several checkpoints in the middle, each checkpoint is testing something, so doing multiple sets of experiments at the same time is an overlap experiment.
As mentioned earlier, the biggest problem with overlapping experiments is how to avoid flow bias. To this end, three concepts need to be introduced.
- Domain: It is a large division of traffic. When the top-level traffic comes in, the domain is divided first.
- Layer: is a subset of system parameters, and layer experiment is a test of a subset of parameters.
- Barrels: The experimental and control groups are in these barrels.
Layers and domains can be nested in each other. The main meaning is to divide the traffic, for example, divide 50%, and 50% of the traffic is a domain. There are multiple experimental layers in this domain. In each experimental layer, you can continue to nest domains, that is, you can improve the division of 50 % Of traffic. The following two figures illustrate two cases with and without domain division.

The left side of the figure is a three-layer experiment, but there is no domain division. The first layer of experiments should test the UI, the second layer should test the recommendation results, and the third layer should test the results of inserting ads in the recommendation results.
The three layers do not affect each other.
On the right side of the figure, domain division is added, that is, not all traffic is involved in the experiment, but a part is divided into the left domain. The remaining flow is the same as the experiment on the left.
To understand here, why can multi-layer experiments overlap without causing flow bias?
This requires the concept of barrels. Still the left picture in the above schematic diagram, if each layer of this experimental platform is evenly and randomly divided into 5 barrels, on the actual experimental platform, there may be thousands of barrels, here only for example.
The schematic diagram is as follows:
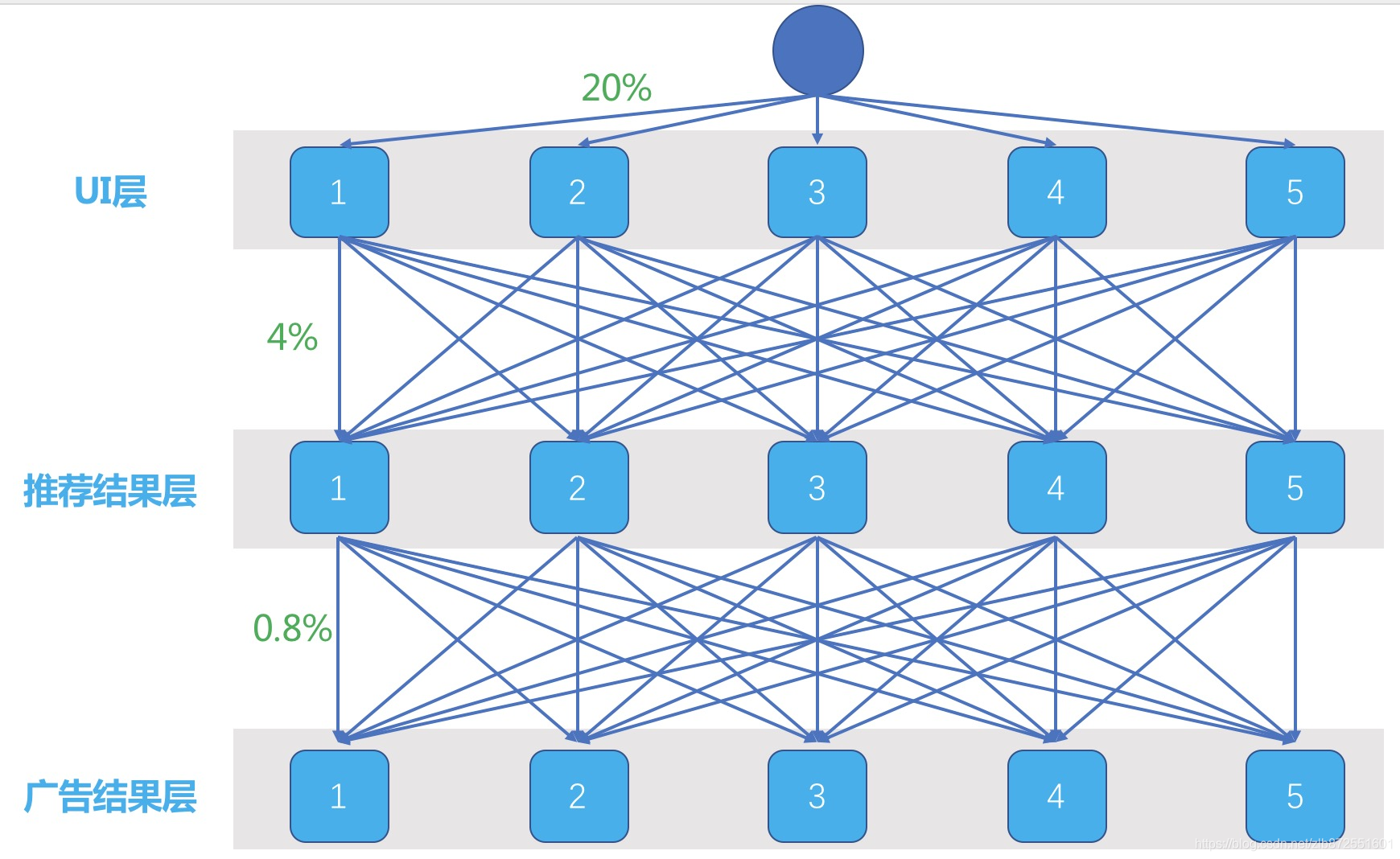
This is a three-layer experiment divided into domains.
Each layer is divided into 5 buckets, and a flow comes. At the first layer, there is a unified random distribution algorithm. Cookie or UUID is added to the first layer ID to hash into an integer, and then the integer is taken to 5 Mode, so a flow randomly enters one of the 5 buckets.
Each bucket gets 20% of the flow evenly. Each bucket has already decided what kind of UI to show you, and the traffic continues to go down. The flow of each bucket is still facing one of the 5 buckets that randomly enter the next layer of experiments. The original 20% of each bucket's flow is divided into 5 parts, and each bucket has 4% of the flow into the second Layer each bucket.
In this way, each bucket of the second layer actually obtains 20% of the total flow, and the impact of the previous layer of the experiment is evenly dispersed in each bucket of this layer, that is, it can be considered The previous layer of experiments has no effect on this layer . The same is true for the third layer of experiments.
This is the most basic principle of layered experiments. On this basis, the concept of domain is added, just to configure more experiments more flexibly.
There are a few points to note about layered experiments:
- 1. When bucketing each layer, it is not just modulo the Cookie or UUID hash, but the layer ID is added in order to make the buckets between the layers independent of each other;
- 2. When hashing cookies or UUIDs into integers, consider using a uniform hashing algorithm, such as MD5.
- 3. The modulo should be consistent. For user experience, although it is a bucket experiment, but the same user feels inconsistent each time in the same location, which will damage the user experience.
The traffic distribution method of hashing the user ID in the previous example is only one of them, and there are three types of traffic distribution methods, a total of four :
- Cookie + layer ID modulus ;
- Completely random
- Modulation of user ID + layer ID;
- Cookie + date modulo.
