Brief introduction
This is used to record for me, "Informatics Olympiad a pass-rise piece" Brush title records exercises in the book and study notes.
General sub-themes to write (all together and may have to write for a long time ...), for example, this chapter is used to record greedy of.
Then plug one: Loj really a good OJ, if Luo Valley is the best OIer community, it is best to brush Loj problem area.
PS: Here's "best" simply refers to the practice gives me the best feeling, such as style goodies, and represents only a personal opinion.
Presentations : greedy, for the optimal solution to address topics like weapon, but often it is difficult to imagine that the code is simple and proven. (Detailed in this chapter will generally prove)
first question
# 10000 "1.1 cases through a 1" activity schedule
Is actually very simple greed, then greed routine is obvious.
A right end point is sorted in ascending order, when the right end of the left end point> = last selected ans++.
Certify as follows:
First, we assume that \ (N \) article about the segment endpoint were \ (a_i, b_i \) .
Assumed to have been sorted, namely \ (B_1 <B_2 <... <B_n \) , then it is assumed \ ((b_j <b_i) \) , and \ ((a_j, b_j) \ ) and \ ((a_i, b_i ) \) and before the event do not conflict.
Also assume that the current has been selected \ ((a_j, b_j) \) .
- If \ ((a_j, b_j) \ ) and \ ((a_i, b_i) \ ) and do not conflict: namely \ (b_j \ Leq a_i \) , you can select \ ((a_i, b_i) \ ) .
- If \ ((a_j, b_j) \) and \ ((a_i, b_i) \ ) conflict: namely \ (b_j> a_i \) , then because \ (b_j <b_i \) , so I chose \ ((a_j, b_j) \) on the back of less impact.
Thus, when (b_1 <b_2 <... <b_n \) \ , select \ (last \ _b_j \ leq a_i \) line segment is optimal.
QED.
code:
#include<cstdio>
#include<algorithm>
#include<cmath>
#include<iostream>
#include<cstring>
#define N 1010
using namespace std;
int n;
struct node{
int s,f;
}a[N];
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
bool cmp(node a,node b){
return a.f<b.f;//按照结束时间升序排序。
}
int main(){
n=read();
for(int i=1;i<=n;i++){
a[i].s=read();a[i].f=read();
}
sort(a+1,a+n+1,cmp);//排序。
int ans=1,jl=a[1].f;//jl 用来记录上一次的右端点。
for(int i=2;i<=n;i++){
if(a[i].s>=jl){//贪心策略。
ans++;jl=a[i].f;
}
}
printf("%d\n",ans);
return 0;
}
The second question
# 10001 "1.1 cases through a 2" trees
Range choice of site coverage issues, obviously picked by point the better. Practices are as follows:
- Each interval in ascending order according to the end point.
- Sequentially processed for each segment:
- And earn points throughout the interval.
- If the interval points> required points
continue. - Otherwise, add a forward position in the required number of points on the tree is not from - the interval points points.
Certify as follows:
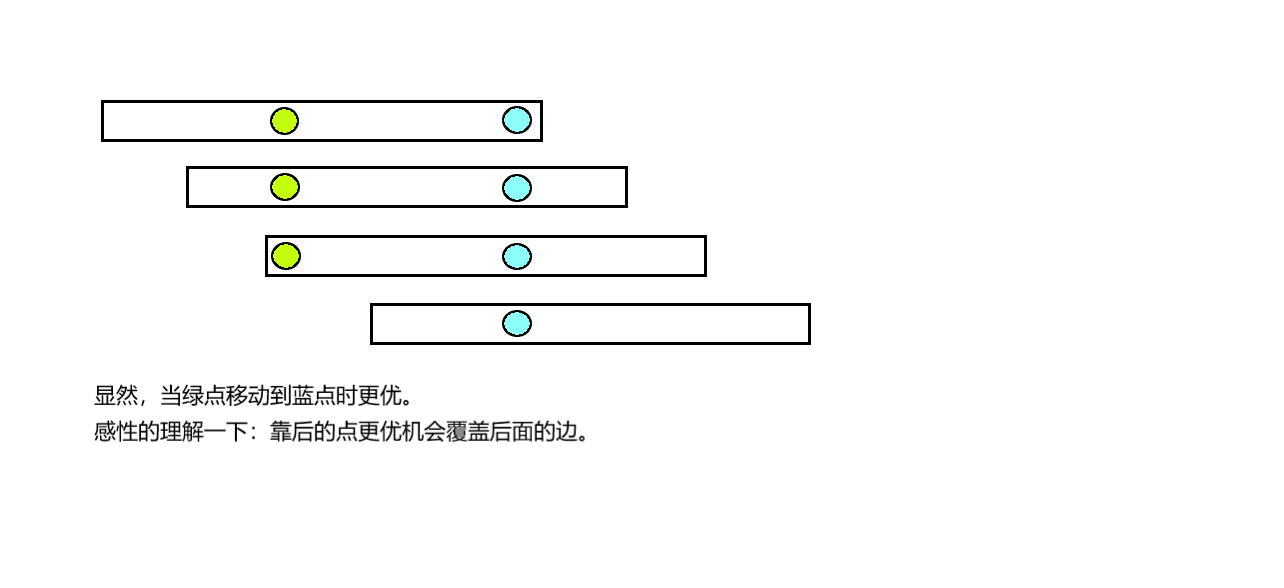
So ... it is Jiang Zi friends.
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<iostream>
#define N 30010
#define M 5010
using namespace std;
int n,m;
bool flag[N];
struct node{
int l,r,s;
}a[M];
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
bool cmp(node a,node b){
return a.r<b.r;
}
int main(){
memset(flag,false,sizeof(flag));
n=read();m=read();
for(int i=1;i<=m;i++)
a[i].l=read(),a[i].r=read(),a[i].s=read();
sort(a+1,a+m+1,cmp);
int ans=0;
for(int i=1;i<=m;i++){
int l=a[i].l,r=a[i].r,sum=0;
for(int j=l;j<=r;j++) if(flag[j]) sum++;
if(sum>=a[i].s) continue;
sum=a[i].s-sum;
ans+=sum;
for(int j=r;j>=l;j--){
if(!sum) break;
if(!flag[j]){flag[j]=true;sum--;}
}
}
printf("%d\n",ans);
return 0;
}
The third question
# 10002 "through a 3 1.1 cases" Sprinklers
Very good topic.
First excluded (r \ leq W \) \ point (because it is not even own range just below are not covered), calculated as far as coverage of each head:
Why is this so? Look:
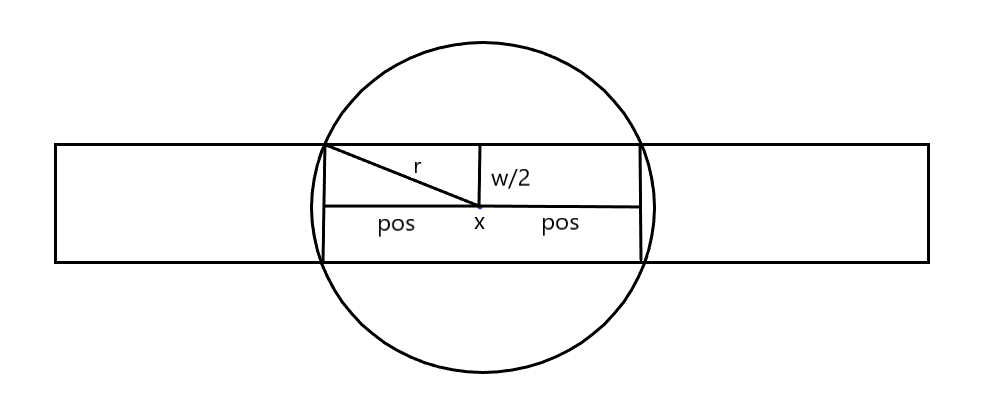
FIG fancy, because the boundary circle is not easy to calculate, it is possible to approximate circle coverage seen above a rectangular shape.
Then according to the Pythagorean theorem, it is easy to derive the formula, the circle coverage is: \ ([X-POS, POS X +] \) .
You may be wondering if this will lead to error out accuracy, the answer is no, and is the only correct way.
Because \ (x-pos \) before (or \ (x + pos \) part is not completely covered later), and if this distance is also added to the list will obviously result in an error.
And then it became a topic the same problem, but the approach is different:
- All sections in accordance with the left end point (i.e. \ (x-pos \) sorting).
- From left to right treatment for each interval. (See specific processing method code)
#include<cstdio>
#include<algorithm>
#include<cmath>
#include<iostream>
#include<cstring>
#define N 15010
using namespace std;
int T,n,L,W,cnt=0;
struct node{
double l,r;
}a[N];
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
void init(){
cnt=0;
n=read();L=read();W=read();
int x,r;
for(int i=1;i<=n;i++){
x=read();r=read();
if(r<=W/2) continue;
a[++cnt].l=(double)x-(double)sqrt(r*r-W*W/4.0);
a[cnt].r=(double)x+(double)sqrt(r*r-W*W/4.0);
}
return;
}
bool cmp(node a,node b){
return a.l<b.l;
}
void work(){
double t=0.0;
int ans=0,i=1;
while(t<L){
ans++;
double s=t;
for(;a[i].l<=s && i<=cnt;i++)
//核心代码:这个区间的左端点在上一次的右端点之前,并且没有超过区间总数时,进行叠加。
if(t<a[i].r) t=a[i].r;
//当这个区间的右端点在上一次选择的右端点之后时,可以抛弃上个区间而选择这个。(证明见例题一)
if(t==s && s<L){
//判断是否不可能,当并没有符合条件的区间,并且上一次的左端点<区间总长度,显然这是凉了。
printf("-1\n");return;
}
}
printf("%d\n",ans);
return;
}
int main(){
T=read();
while(T--){
init();
sort(a+1,a+cnt+1,cmp);
work();
}
}
Fourth Question
# 10003 "1.1 cases through a 4" processing and production scheduling
Classic question it, using a standard Johnsonalgorithm can be.
Given first practice, then give proof of it. (Readers can try to prove that he, in fact, is not difficult to difficult)
- Set \ (N_l \) of \ (a <b \) a set of operations, \ (N_2 \) of \ (a \ geq b \) of a set of jobs.
- The \ (N_l \) set in accordance with the \ (A \) nondecreasing sorting, \ (N_2 \) set in accordance with the \ (B \) non-increasing order.
- The answer is \ (N_1 + N_2 \) collection.
Time complexity is \ (O (N \ log \ N) \) , demonstrated as follows:
Set \ (S = \ {J_1, J_2, ..., J_N \} \) , order of jobs to be processed, if \ (A \) machine begins processing \ (S \) when, \ (B \) further in other parts of the processing, and the processing time \ (T \) .
Processability \ (S \) minimum time \ (T (S, t) = min_ {1 \ leq i \ leq N} \ {a_i + T (S - \ {J_i \}), b_i + max \ {t -a_i, 0 \} \} \) . (Self-understanding)
Assuming that the optimum processing program for the first processing \ (J_i \) reprocessing \ (J_j \) , then:
\(T(s,t)=a_i+T(S-\{J_i\},b_i+max\{t-a_i,0\})\)
\(=a_i+a_j+T(S-\{J_i,J_j\},b_j+max\{b_i+max\{t-a_i,0\}-a_j,0\})\)
\(=a_i+a_j+T(S(j_i,J_j),T_{ij})\)
\(T_{ij}=b_j+max\{b_i+max\{t-a_i,0\}-a_j,0\}\)
\(=b_i+b_j-a_j+max\{max\{t-a_i,0\}),a_j-b_i\}\)
\(=b_i+b_j-a_j+max\{t-a_i,a_j-b_i,0\}\)
\(=b_i+b_j-a_i-a_j+max\{t,a_i,a_i+a_j-b_i\}\)
\(case\ 1:=t+b_i+b_j-a_i-a_j(max\{t,a_i,a_i+a_j-b_i\}=t)\)
\(case\ 2:=b_i+b_j-a_i(max\{t,a_i,a_i+a_j-b_i\}=a_i)\)
\(case\ 3:=b_j(max\{t,a_i,a_i+a_j-b_i\}=a_i+a_j-b_i)\)
If the job in accordance with \ (j - i \) and job \ (J_j \) of the exchange processing sequence, there are:
\ (T '(S, t) == a_i + a_j + T (S (J_i, J_j), T_ {ji}) \) ,其中
\(T_{ji}=b_i+b_j-a_i-a_j+max\{t,a_i,a_i+a_j-b_i\}\)
By hypothesis, \ (T \ T Leq '\) , it is:
\[max\{t,a_i+a_j-b_i,a_i\}\leq max\{t,a_i+a_j-b_j,a_j\} \]Then there are:
\[a_i+a_j+max\{-b_i,-a_i\}\leq a_i+a_j+max\{-b_j,-a_i\} \]which is:
\ [Min \ {b_j, a_i \} \ Leq min \ {b_i, a_j \} \]This is the form of the mathematical expression of the above algorithm.
QED.
Reading is not dazzling? The few times to see Jiuhaola.
#include<cstdio>
#include<algorithm>
#include<cmath>
#include<cstring>
#include<iostream>
#define N 1010
using namespace std;
int n,a[N],b[N],ans[N];
struct node{
int sum,num;
}c[N];
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
bool cmp(node a,node b){
return a.sum<=b.sum;
}
int main(){
n=read();
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<=n;i++) b[i]=read();
for(int i=1;i<=n;i++){
c[i].sum=min(a[i],b[i]);
c[i].num=i;
}
sort(c+1,c+n+1,cmp);
int l=0,r=n+1;
for(int i=1;i<=n;i++){
if(a[c[i].num]==c[i].sum) ans[++l]=c[i].num;
else ans[--r]=c[i].num;
}
int ans_a=0,ans_b=0;
for(int i=1;i<=n;i++){
ans_a+=a[ans[i]];
if(ans_b<ans_a) ans_b=ans_a;
ans_b+=b[ans[i]];
}//注意一下统计答案的方法,很简单的啦。
printf("%d\n",ans_b);
for(int i=1;i<n;i++) printf("%d ",ans[i]);
printf("%d\n",ans[n]);
return 0;
}
The fifth question
# 10004 "1.1 cases through a 5" Big Surf intelligence
City elementary school when the last question of the game (at that time what I did), greedy + disjoint-set to address, specifically to see this article .
#include<cstdio>
#include<algorithm>
#include<cmath>
#include<cstring>
#include<iostream>
#define N 510
using namespace std;
int M,n,fa[N];
struct node{
int t,c;
}a[N];
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
bool cmp(node a,node b){
if(a.c!=b.c) return a.c>b.c;
return a.t>b.t;
}
int find(int x){
if(fa[x]==x) return x;
return fa[x]=find(fa[x]);
}
int main(){
M=read();n=read();
for(int i=1;i<=n;i++) a[i].t=read();
for(int i=1;i<=n;i++) a[i].c=read();
for(int i=1;i<=n;i++) fa[i]=i;
sort(a+1,a+n+1,cmp);
int ans=0;
for(int i=1;i<=n;i++){
int f=find(a[i].t);
if(f<1) ans+=a[i].c;
else fa[f]=find(f-1);
}
printf("%d\n",max(0,M-ans));
return 0;
}
Question 6
# 10005 "through a 1.1 Exercise 1" number of columns poor
Simple greed.
First, we understand how the emotional, maximum and minimum values must be in accordance with the order to get some kind of extreme, so think big to small and from small to large .
Then hand the sample was found to play a maximum of small to large, from large to small minimum value . Thus the following methods:
- The data is sorted in descending order, sequentially extracts two numbers before \ (a \ times b + 1 \) operation, and the result is pushed back queue.
- Establishing rootlets stack successively extracted twice top of the stack (the proviso that at least two numbers), for \ (a \ times b + 1 \) operation, and the result is pushed back to the heap.
Finally, a number remain in the queue or heap is the answer.
But why only needs a queue, it takes a little heap root of it?
Since the maximum number of two for \ (a \ times b + 1 \) a certain operation or the maximum number, but the minimum number of two for \ (a \ times b + 1 \) operation might not be.
For chestnut: 10,9,8the 9*8+1=73>10while 10*9+1一定>8.
So far this problem has been done, but greed alone feeling this thing ... is very easy to roll, so to prove. Certify as follows:
The use of reductio ad absurdum, where only a maximum of small to large has proved that empathy to another. Assuming that \ (A_1 <A_2 <... <A_N \) .
The answer according to ascending order of operation is \ (ANS1 \) , press \ (a_1, a_2, ..., a_ {i + 1}, a_i, ..., a_n \) answers the operation of \ (ANS2 \) .
Suppose \ (ANS1 <ANS2 \) .
There are:
\(((a_1\times a_2+1)\times...+1)\times a_n+1<((((a_1\times a_2+1)\times...+1)\times a_{i+1}+1)\times a_i+1)\times ...\times a_n+1\)
设:\(x=(a_{i-1}\times a_i+1)\times a_{i+1}+1,y=(a_{i-1}\times a_i+1)\times a_{i+1}+1\),将 \(x,y\) 带入两式。
Find the rest are the same, get \ (the X-<the y-\) , namely :( lazy here, should be able to read it)
\((a_{i-1}\times a_i+1)\times a_{i+1}+1<(a_{i-1}\times a_i+1)\times a_{i+1}+1\)
Simplification was:
\(a_{i+1}<a_i\)
And suppose \ (a_1 <a_2 <... < a_n \) in contradiction, so the assumption does not hold, so the \ (ANS1 \ geq ANS2 \) .
And can be extended to universal law, was \ (ans1 \) is the best answer.
QED.
Code:
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<cmath>
#include<iostream>
#include<queue>
using namespace std;
int n,a[50010],mx,mn,jl=0;
priority_queue<int,vector<int>,greater<int> >q;
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
bool cmp(int a,int b){
return a>b;
}
int main(){
n=read();
for(int i=1;i<=n;i++){
a[i]=read();
q.push(a[i]);
}
a[0]=read();
sort(a+1,a+n+1,cmp);
mn=a[1];
for(int i=2;i<=n;i++) mn=mn*a[i]+1;
while(!q.empty()){
mx=q.top();q.pop();
if(!q.empty()) mx=mx*q.top()+1;q.pop();//if 判断不可少
if(!q.empty())q.push(mx);//if 判断不可少
}
printf("%d\n",mx-mn);
return 0;
}
The seventh question
# 10006 "through a 1.1 Exercise 2" series segments
Start wrong question, I thought what binary answers + greedy.
Requirements of the subject is a number of consecutive segments, so that the digital image is not loaded backpack backpack to switch as many articles, for example:
4 6
2 3 6 1
The answer to this set of data is 3 instead of 2. (Even if you read the title I thought it very funny, do not spray)
Then is a routine operation, so that each section of greedy enough as long as possible.
Proved a little ... (it is too simple)
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<cmath>
#include<iostream>
using namespace std;
int n,m,a[100010],ans=0,sum=0;
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
int main(){
n=read();m=read();
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<=n;i++){
if(sum+a[i]<=m) sum+=a[i];
else{ans++;sum=a[i];}
}
if(sum) ans++;
printf("%d\n",ans);
return 0;
}
Q8
# 10007 "through a 1.1 Exercise 3" line
And code the first question of exactly the same, but you want to adjust the range of the array bigger. Could not help but say: one through exercises such water it
#include<cstdio>
#include<algorithm>
#include<cmath>
#include<iostream>
#include<cstring>
#define N 1000010
using namespace std;
int n;
struct node{
int s,f;
}a[N];
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
bool cmp(node a,node b){
return a.f<b.f;
}
int main(){
n=read();
for(int i=1;i<=n;i++){
a[i].s=read();a[i].f=read();
}
sort(a+1,a+n+1,cmp);
int ans=1,jl=a[1].f;
for(int i=2;i<=n;i++){
if(a[i].s>=jl){
ans++;jl=a[i].f;
}
}
printf("%d\n",ans);
return 0;
}
Ninth title
# 10008 "through a 1.1 Exercise 4" Homework
And fifth questions the same? This book ... [silent .jpg]
#include<cstdio>
#include<algorithm>
#include<cmath>
#include<cstring>
#include<iostream>
#define N 1000010
using namespace std;
int M,n,fa[N];
struct node{
int t,c;
}a[N];
int read(){
int x=0,f=1;char c=getchar();
while(c<'0' || c>'9') f=(c=='-')?-1:1,c=getchar();
while(c>='0' && c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
bool cmp(node a,node b){
if(a.c!=b.c) return a.c>b.c;
return a.t<b.t;
}
int find(int x){
if(fa[x]==x) return x;
return fa[x]=find(fa[x]);
}
int main(){
n=read();
for(int i=1;i<=n;i++){
a[i].t=read();a[i].c=read();
}
for(int i=1;i<=n;i++) fa[i]=i;
sort(a+1,a+n+1,cmp);
int ans=0;
for(int i=1;i<=n;i++){
int f=find(a[i].t);
if(f<1) continue;
ans+=a[i].c;
fa[f]=find(f-1);
}
printf("%d\n",ans);
return 0;
}
Question 10
# 10009 "through a 1.1 Exercise 5" Fishing
It is really a good question, beginning with the DP wants to do is go over after Kang Kang dalao a solution to a problem only to find a clever greedy approach.
First DP bars, with \ (f [i, j] \) represents \ (I \) ponds, the common \ (J \) time fishing. (Note that only the fishing time)
There is a state transition equation: \ (F [I, J] = max_ {0 \ Leq K \ Leq J} \ {F [I-. 1, JK] + \ sum_ {L = 0} ^ {K-. 1} a_i - (b_i \ times l) \ } \)
The time complexity is: \ (O (nh ^ 3) \) .
Code:
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <iostream>
#include <cstring>
#define N 2010
using namespace std;
int n, h, a[N], b[N], t[N], tt, f[N][N], ans = 0;
int read() {
int x = 0, f = 1;
char c = getchar();
while (c < '0' || c > '9') f = (c == '-') ? -1 : 1, c = getchar();
while (c >= '0' && c <= '9') x = x * 10 + c - 48, c = getchar();
return x * f;
}
int main() {
n = read();
h = read();
h *= 12;
for (int i = 1; i <= n; i++) a[i] = read();
for (int i = 1; i <= n; i++) b[i] = read();
for (int i = 2; i <= n; i++) {
tt = read();
t[i] = t[i - 1] + tt;
}
memset(f, 0, sizeof(f));
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= h - t[i]; j++) {
f[i][j] = f[i][j - 1];
for (int k = 0; k <= j; k++) {
if (a[i] < (k - 1) * b[i])
break;
int s = 0;
for (int l = 0; l < k; l++) s += a[i] - (b[i] * l);
f[i][j] = max(f[i][j], f[i - 1][j - k] + s);
}
ans = max(ans, f[i][j]);
}
}
printf("%d\n", ans);
return 0;
}
Then the greedy.
The title says some of the lake, we will enumerate each lake as an end point, then the total time - time = number of walk can fishing, denoted \ (SUM \) .
As examples:
第一个湖:4 3 2 1 0 0 0…
第二个湖:5 3 1 0 0 0…
第三个湖:6 5 4 3 2 1 0 0 0…
This question is to allow us to choose \ (sum \) largest number.
Our first \ (i \) lake has been selected. \ (X \) number, in \ (j \) lake has been selected. \ (Y \) number, the equivalent of our first \ (i \) a Lake fishing in the \ (x \) times the fish, caught in the j-th lake \ (y \) times fish.
Since \ (D [I] \ GEQ 0 \) , so that all columns were descending order, so if we want to select a number of columns of \ (I \) number, the former series of \ (i-1 \) one number have
After being elected (because of the ratio \ (i \) the number of large), it is consistent with the meaning of the questions.
Code below, with optimization priority queue, is the worst time \ (O (n-\ log (NH)) \) :( proved to be too simple, skip)
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <iostream>
#include <cstring>
#include <queue>
#define N 2010
using namespace std;
int n, h, a[N], b[N], t[N], ans = 0;
struct node {
int sum, cha;
bool operator<(const node &a) const { return a.sum > sum; }
};
priority_queue<node> q;
int read() {
int x = 0, f = 1;
char c = getchar();
while (c < '0' || c > '9') f = (c == '-') ? -1 : 1, c = getchar();
while (c >= '0' && c <= '9') x = x * 10 + c - 48, c = getchar();
return x * f;
}
int main() {
n = read();
h = read();
h *= 12;
for (int i = 1; i <= n; i++) a[i] = read();
for (int i = 1; i <= n; i++) b[i] = read();
for (int i = 1; i < n; i++) t[i] = read();
int Sum = 0, sum = 0, m;
for (int i = 1; i <= n; i++) {
sum = 0;
Sum += t[i - 1];
m = h - Sum;
node p;
for (int j = 1; j <= i; j++) {
p.sum = a[j];
p.cha = b[j];
q.push(p);
}
while (m > 0 && !q.empty() && q.top().sum > 0) {
sum += q.top().sum;
p.sum = q.top().sum - q.top().cha;
p.cha = q.top().cha;
q.pop();
q.push(p);
m--;
}
ans = max(ans, sum);
}
printf("%d\n", ans);
return 0;
}
XI title
Solitaire ring sharing problem.
The general problem is equivalent to the card sharing disconnect between the second ring and the first individual personal N, N personal station which at this time in a row, the number of cards held by the prefix and are:
A[1] S[1]
A[2] S[2]
…
A[N] S[N]
If after the broken ring of K individual standing in line, the N number of cards held by individuals, and the prefix are:
A[k+1] S[k+1]-S[k]
A[k+1] S[k+2]-S[k]
…
A[N] S[N]-S[k]
A[1] S[1]+S[N]-S[k]
…
A[k] S[k]+S[N]-S[k]
Therefore, the required minimum cost is: \ (\ sum_. 1 = {I} ^ {N} | S [I] -S [K] | \) .
When the value of the equation where K is the minimum? This is the "warehouse site selection" problem.
So we \ (S \) array from small to large order, taking the median as \ (S [k] \) is the optimal solution.
#include<cstdio>
#include<algorithm>
#include<iostream>
#define N 1000010
using namespace std;
typedef long long ll;
ll n,a[N],sum[N],ave=0,ans=0;
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%lld",&a[i]);ave+=a[i];
}
ave/=n;
for(int i=1;i<=n;i++) a[i]-=ave;
for(int i=1;i<=n;i++) sum[i]=sum[i-1]+a[i];
sort(sum+1,sum+n+1);
ll mid=sum[(n+1)>>1];
for(int i=1;i<=n;i++) ans+=abs(mid-sum[i]);
printf("%lld\n",ans);
return 0;
}