Reprinted Source: https://blog.csdn.net/weixin_42462804/article/details/99821091
Article Directory glance
-
- What is the uneven distribution of sample categories?
- Sample categories uneven distribution harm caused?
- Solution:
- Other evaluation
- how to choose
- references
Today learned a bit about the process of uneven distribution of sample categories, here and share with everyone.
What is the uneven distribution of sample categories?
Way of illustration, a set of samples in the sample size is very large differences in different categories, such as having 1000 data sample data set, a class classification only ten samples, sample data at this time is a serious uneven distribution.
Sample imbalance means that a given data set and some categories of data, less some categories of data, and data categories accounting for more data samples and accounted for a larger proportion reached between the two smaller categories of data samples.
Sample categories uneven distribution harm caused?
Sample type feature classification imbalance will cause a small amount of sample contained too little, and it is difficult to extract the law; even with the classification model, and also prone to over-reliance on a limited data sample overfitting result, when the model application when the new data, the accuracy of the model will be poor.
Solution:
- Level data: sampling, data enhancement, data synthesis;
- Algorithmic level: Modify the loss function value, difficult cases of mining.
- Classification levels:
1. by over-sampling and under sampling solve unbalanced sample
Sampling
random oversampling: a random sample set from minority repeated samples drawn (with replacement) to give a larger sample;
random sub-sampling: concentrated randomly selected samples from the majority class fewer samples (with replacement / without replacement) ;
random sampling of the disadvantages
Oversampling of minority samples were multiple copies, while expanding the size of the data, but also easily lead to over-fitting;
lost part of the sample due to sampling, the possible loss of useful information, resulting in less of certain features of the model fit
(1) through the sample (over-sampling): Sample equilibrium is achieved by increasing the number of classified samples minority, there is a better way SMOTE algorithm.
1. oversampled basic version: random oversampled training samples relatively small number of transactions; disadvantages, is easy to overfitting;
2. oversampling improved version: the SMOTE, neighbor data points added by interpolation manner;
3. Based oversampling clustering: clustering the data first, then data clustering oversampled respectively. This method can reduce the imbalance between the classes and class.
4. The neural network oversampling: When SGD training, to ensure that each batch of samples internal equilibrium.
SMOTE algorithm: it simply thought smote algorithm is the synthesis of new minority sample, the synthetic strategy is for each minority sample a, from its nearest neighbor in a randomly selected sample of b, then between a, b of a connection point on randomly selected samples minority newly synthesized. Specific process you can own google.
Attach sample code :( first show sample data, this article will use this data)
import pandas as pd
from imblearn.over_sampling import SMOTE #过度抽样处理库SMOTE
df=pd.read_table('data2.txt',sep=' ',names=['col1','col2','col3','col4','col5','label'])
x=df.iloc[:,:-1]
y=df.iloc[:,-1]
groupby_data_orginal=df.groupby('label').count() #根据标签label分类汇总
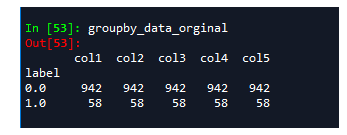
With groupby can see the data label = 0 of 942 samples, label = 1 only 58, there is a serious imbalance, where we use SMOTE algorithms to solve it.
model_smote=SMOTE() #建立smote模型对象
x_smote_resampled,y_smote_resampled=model_smote.fit_sample(x,y)
x_smote_resampled=pd.DataFrame(x_smote_resampled,columns=['col1','col2','col3','col4','col5'])
y_smote_resampled=pd.DataFrame(y_smote_resampled,columns=['label'])
smote_resampled=pd.concat([x_smote_resampled,y_smote_resampled],axis=1)
groupby_data_smote=smote_resampled.groupby('label').count()

(2) subsampling (under-sampling): Sample equilibrium is achieved by reducing the number of samples majority class classification
Oversampling method is opposed to the sub-sampling method, the main part of the data is removed large amount of data categories. The problem with this approach is that data loss caused by missing information. To overcome this shortcoming, you can lose some data categories boundary portion.
from imblearn.under_sampling import RandomUnderSampler
model_RandomUnderSampler=RandomUnderSampler() #建立RandomUnderSample模型对象
x_RandomUnderSample_resampled,y_RandomUnderSample_resampled=model_RandomUnderSampler.fit_sample(x,y) #输入数据并进行欠抽样处理
x_RandomUnderSample_resampled=pd.DataFrame(x_RandomUnderSample_resampled,columns=['col1','col2','col3','col4','col5'])
y_RandomUnderSample_resampled=pd.DataFrame(y_RandomUnderSample_resampled,columns=['label'])
RandomUnderSampler_resampled=pd.concat([x_RandomUnderSample_resampled,y_RandomUnderSample_resampled],axis=1)
groupby_data_RandomUnderSampler=RandomUnderSampler_resampled.groupby('label').count()

2. The right to punish by positive and negative samples of heavy solve unbalanced sample
(1) with the weight loss function:
Simple and crude increased loss function of small sample labels weight, after weighting can be simply understood that: for a small sample of data using multiple top, where the weight is more than we want to set, somewhat similar to the small sample data oversampling operation is performed;
Example difficult Mining: refers to the mining results predict a poor model samples, i.e. the model prediction is less effective on large hard predicted loss function value of the sample, is difficult to dig out the training samples, and these samples for further re-training.
Think about why this may be part of the solution sample imbalance problem?
In fact, very simple can understand why this method can work, difficult cases of mining, for our small sample data, predictive models can imagine the effect is certainly not okay prediction, forecast is not good, it will not be excavated out as hard cases yet? Model for handling these samples again, small sample data will have a special treatment, a kind of feel bad grades students were brought to the office to learn the teacher, then the poor performance of students how to say it will improve a little, model it can not be a corresponding increase in performance!
focal loss comes from the paper Focal Loss for Dense Object Detection
specific explanation can see this article: https: //zhuanlan.zhihu.com/p/32423092
Here a brief introduction: focal loss has been improved on the basis of loss of the original function with weights on the direction of improvement is a function of weight loss.
Then take a look at a two-class cross entropy loss function expression: 
in accordance with the above example, if we find the right function for predicting the value of financial loss in value compared to the sample weights correctly predicted much larger, both the original ratio is 1: 1, the ratio now is 1:64, equivalent to the prediction error samples, we deal with them is the weight increased 63-fold.
This method of modifying the weight loss function, is based on probability and modified, not directly modify the weight loss function, to directly modify a bit stiff.
Remember here we dig out of the prediction is wrong, but there is no data for unbalanced operation (of course, can lead to an imbalance prediction error data), we continue to add weight loss function at this time is to weight category unbalanced treatment, expressed as follows:
def focal_loss(labels, logits, gamma, alpha):
labels = tf.cast(labels, tf.float32)
probs = tf.sigmoid(logits)
ce_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=logits)
alpha_t = tf.ones_like(logits) * alpha
alpha_t = tf.where(labels > 0, alpha_t, 1.0 - alpha_t)
probs_t = tf.where(labels > 0, probs, 1.0 - probs)
focal_matrix = alpha_t * tf.pow((1.0 - probs_t), gamma)
loss = focal_matrix * ce_loss
loss = tf.reduce_mean(loss)
return loss
**
algorithm idea: For a number of samples of different classification categories were given different weights, usually small sample size category weight is high, a large sample size category weight low. **
SVM here for an example:
from sklearn.svm import SVC
model_svm=SVC(class_weight='balanced')
model_svm.fit(x,y)
Here class_weight options in its default method 'balanced', i.e. SVM will the weight to weight was inversely proportional to the number of different types of samples for automatic re-equalization process.
3. Category balanced sampling
The samples grouped by category, generating a sample list of each category, the training process to one or several randomly selected category, and then select a random sample from the sample list in corresponding to the respective category. This ensures that each class the opportunity to participate in training is relatively equal.
These require more job categories for samples with an equal number of first define the category list, the category for tasks such massive data sets, etc. This ImageNet extremely cumbersome. Category balanced approach proposed reorganization of the Institute of Hikvision.
Category recombination requires only a listing of the original image to the same uniform sampling task completed, the following steps:
- First, by category sorting order of the original sample, after calculating the number of samples in each category, and the number of samples Sample up to that class.
- Thereafter, the number of samples to produce a list of up to a random arrangement of each type of sample,
- Then a random number in this list the number of samples taken for the remainder of their category, to obtain a value corresponding to the index.
- Next, the image extracted from the image based on the index of this class, the class generates an image random list. After random list of all classes together randomly disarranged order, to obtain a final image list, the list can be found in the final equalization of the number of samples in each category.
- The training model list, the list traversal is completed during training, the weight of the head of the operation to do it again for a second round of training, and so forth.
- Category advantages Reorganization Act is that it requires only the original image list, and all operations are done online in memory, easy to implement.

Thresholding Method yet post scaling process, i.e., select the appropriate threshold determination categories based on the distribution of different types of sample test data may be re-adjusted probability value based classifier output Bayesian formula. General basis, the following: Suppose that for a category class accounted for in the training data x, the proportion of the test data is x '. Probability classifier output values need to do scaling, the probability of the conversion formula is:
fp=apap+b*1-p
a=x’x, b=1-x’1-x
Of course, this weighting may also be added in the way the model training process, i.e. the objective function for the binary classification can be converted to the following formula:
loss=aytruelogypred+b1-ytruelog1-ypred
Depending on the number of samples in the sample misclassification different categories, redefine the loss function. Threshold moving and post scaling is a common method of cost adjustments during the test. This method of calculating the loss function may also be added in the training process, see in particular the part. Another cost sensitive approach is to dynamically adjust the learning rate, easy to mistakenly believe that sub-sample weights when updating the model parameters of heavy larger.
As a category distinct from judgment, One-class classification only from the large number of samples can be detected in that category, for each category are an independent detect model. This method can be extremely uneven sample questions.
Mainly over a variety of methods. Boosting is an example, and the method SMOTEBoost SMOTE oversampling binding.
Other evaluation
In the case of accuracy does not work, use the recall or try to exact rate.
The accuracy of the evaluation does not work in the category unbalanced classification tasks. Several more effective than traditional accuracy of evaluation:
Confusion matrix (Confusion Matrix): Use a table of predicted classification category and its true statistical sample categories, namely: TP, FN, FP and TN.
Accuracy (Precision)
recall (the Recall)
Fl score (F1 Score): accuracy and a recall to find a weighted average.
In particular:
Kappa (Cohen Kappa)
ROC curve (ROC Curves): see Assessing and Comparing Classifier Performance with ROC Curves
how to choose
There are many, just above some of the most commonly used methods to solve the problem of data imbalance, and the most commonly used method has such a variety, how to choose the appropriate method based on the actual problem? Then we talk about some of my experiences.
1, in the positive and negative samples are very small, the synthesis of the data should be used;
2, sufficient sample in negative, positive and very little sample under widely varying conditions and the ratio should be considered a classification method;
3, the positive and negative samples are sufficient and at a ratio not particularly poor conditions, or weighted sampling method should be considered.
4, sampling and weighted mathematically equivalent, but there is a difference in practical application results. In particular, such as sampling, etc. and Random Forest method, the training process will carry out random sampling of the training set. In this case, if the computing resources to allow the sampling is often better than the weighting.
5, Further, although sampling and down-sampling may be set so that the data becomes balanced, and is equivalent in the case of enough data, but both are different. Practical application, my experience is that if calculated on the use of resource-sufficient and minority class sample a sufficient number of cases sampling, or sampling the next use, because the sampling will increase the size of the training set, thus increasing the training time, while a small training set very prone to over-fitting.
6, for downsampling, if relatively high computing resources and has good parallel environment, should be selected Method Ensemble.
references
How to solve the problem of uneven sample
Pytorch used in the right way to sample weights (sample_weight) of
SMOTE algorithm (synthetic data)
how to solve the imbalance problem in machine learning data
