WebMagic function
Achieve PageProcessor
- Extraction element Selectable
WebMagic was mainly used three extraction technologies: XPath, regular expressions and CSS selectors . Further, the content JSON format, can be used to parse JsonPath.
XPath
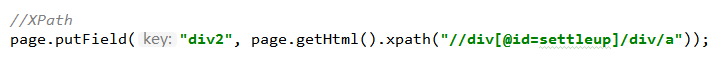
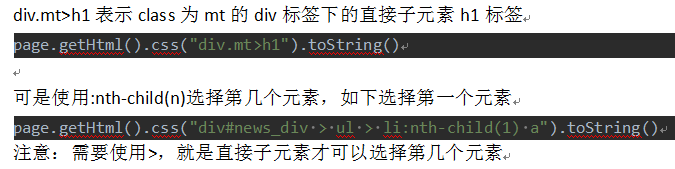
CSS selectors
CSS and XPath selectors are similar language. XPath than it is simpler to write, but if you write complex extraction rules a little, it is relatively little trouble.

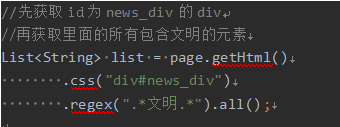
Regular Expressions
Regular expressions are a universal language text extraction. Here are generally used to obtain the url address.

Extraction API elements
Selectable related to the extraction element chain API is a core function of WebMagic. Selectable use interface, you can page elements to complete the direct chain of extraction, there is no need to care about the details extracted.
Can be seen in the earlier example, page.getHtml () returns a Html objects , which implements the Selectable interfaces . This interface contains methods fall into two categories: the extraction section and acquiring results section.



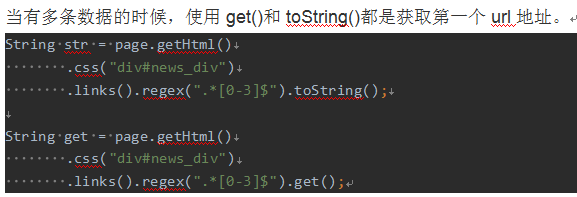
API Getting Results
When the chained calls, we generally want to get a result of type string . This time we need to use the API to get results.
An extraction rules, either XPath, CSS selector or a regular expression , it is always possible to extract multiple elements. WebMagic these were unified, you can get through to one or more elements of different API.



Get Link
With the processing logic of the page, our crawlers will be close to completion, but now there is a problem: a page of the site is a lot of from the beginning we can not all be listed, then follow the link to discover how, is not a reptile an integral part.

Use Pipeline Save Results
Components WebMagic to save the results called Pipeline . We are now the "console output" it is through a built-in Pipeline completed, it is called ConsolePipeline .
Well, I now want to use the results saved to a file , how to do it? Only to realize Pipeline replaced "FilePipeline" on it

