出处 :IEEE on Transactions on Information Forensics and Security 2018
Abstract: Keypoint-based Detection Methods used in the copy and paste tamper detection, for large-scale geometric transformations robustness. But tampered area is small or smooth regions, the very limited number of keypoint.
Paste proposed tampering detection algorithm based on hierarchical feature point matching the feature point matching the hierarchical replication.
- By reducing the contrast threshold, and scaling the input image, can produce a number of key points in small or smooth region
- It proposed a novel hierarchical matching strategy to resolve key issues match
- Further proposed a new iterative positioning techniques iterative localization technique, using the robust features (including the main direction of dominant orientation and scale information scale information) and color information in each key zone to pinpoint tampering.
(code)[https://github.com/YuanmanLi/FE-CMFD-HFPM.]
Dataset FAU [6], GRIP [12 ], MICC-F220 [3], MICC-F600 [16], CMH [15] and COVERAGE [34]
实验环境 desktop equipped with Core-i7 and 8-GB RAM, operating in single-thread modality.
metrics TPR, the FPR, Score-F., the evaluation image, the pixel angle. computational complexity
Related work
In recent years, copy and paste can be roughly divided into two groups detected
dense-field (or block-based) method, an input image is divided into overlapped and regular blocks, and then positioned by block matching.
To enhance the robustness of the geometric transformation, there Discrete Cosine Transform (DCT) Discrete Cosine Transform, Discrete Wavelet Transform (DWT) wavelet transform, a main component of Principal Component Analysis (PCA) Analysis, Singular Value Decomposition (SVD) singular value decomposition the method, block-based method is more accurate than the method based on the critical points, but the higher the complexity.
However, the current method of dense-field at the zoom, rotate, add noise situation is not good
sparse-field (or key-based) method
SIFT Algorithm: based on a scale-space, image scaling, rotation, affine transformation and even local image features good robustness
SIFT implemented steps: 1. extracting key Key 2. Description keypoint matches 3. 4. Elimination point mismatch
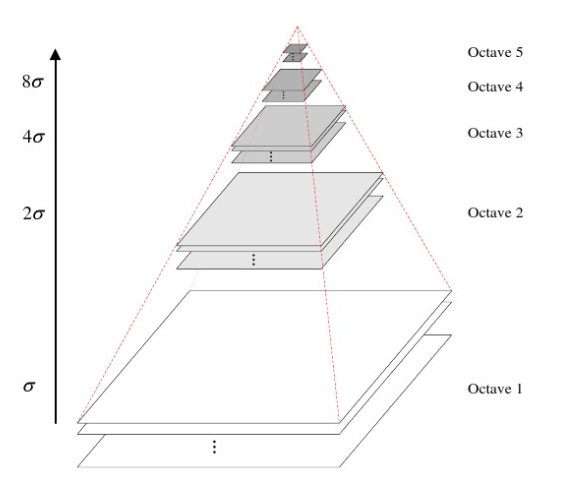
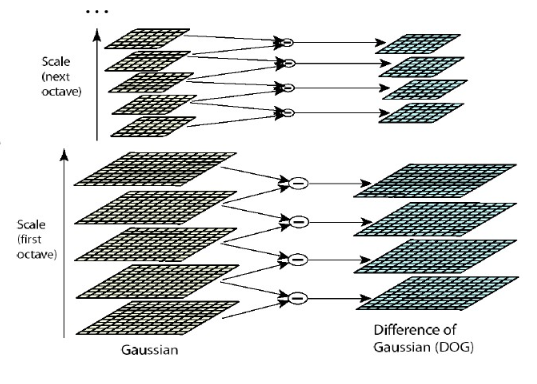
key point is to find a stable, such as the highlight corner, edge point, dark spots and dark areas of the bright regions, has three characteristics: size scale directionKey Detection: an image convolved with a Gaussian kernel, resulting in multi-scale space
Constructor DoG function, simplified calculation
Looking for local extreme points of DOG
-> key pinpoint: extremum point of the further test to find, at some point rounding, including low contrast value removal point
-> key direction assignment
-> The key point description
-> key match
-> eliminate mismatch point
Algorithm structure described herein feature extraction -> Match -> tamper localization
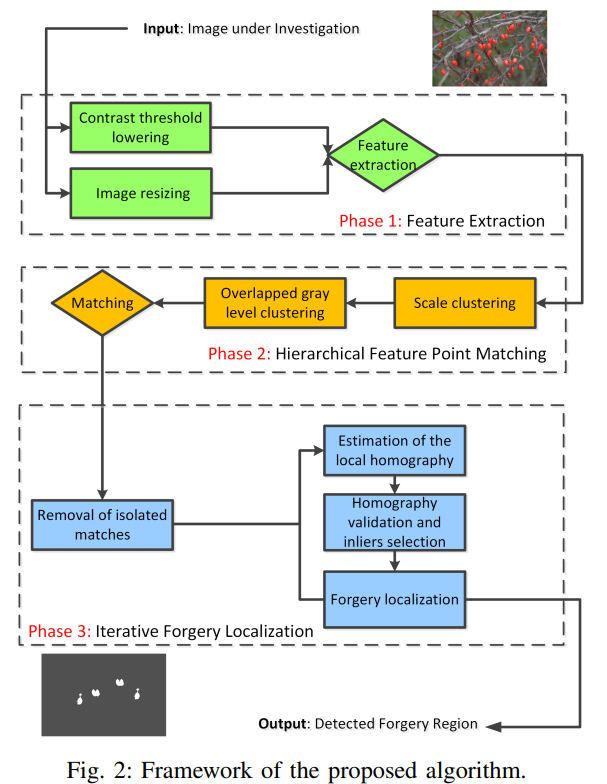
Feature extraction Ⅲ
SIFT feature extraction algorithm employed, however, does not produce a lot of SIFT key points in a small and smooth areas, which would impair the detection performance. Therefore, the authors propose two strategies to improve SIFT, so that it can produce a number of key points in a small area and smooth
Reducing the contrast threshold
SIFT algorithm, the extreme point is detected by i) differential Gaussian pyramid, to ii) positioning the key points and filtering, i.e., using known discrete scale space extrema DoG function of the interpolated curve continuous space extremum point
For that, the contrast value
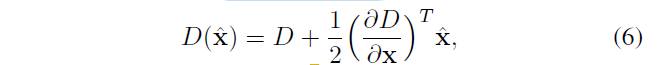
D is a Difference of Gaussian functions, x ^ is offset relative to the center of the interpolation
To remove the contrast and extreme points is less than the threshold c, usually c = 4. However, the small smooth extremal point is below a threshold contrast area, will be omitted, FIG. 4 (b), is less critical points is generated, can not provide sufficient evidence of tampering detection
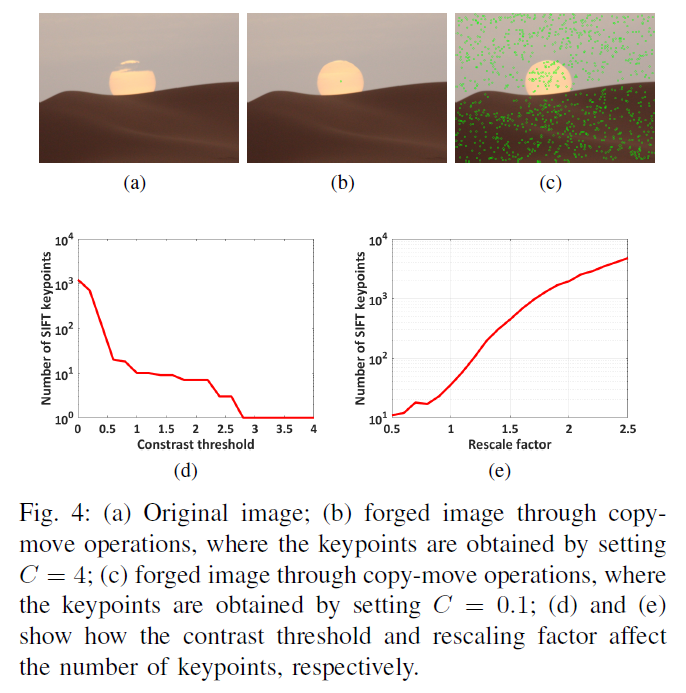
Therefore, to produce in order to ensure the smooth small number of key points of the region, one should lower the threshold c, c but can not be too low, too low will produce a lot of key points of instability, causing the key point matching problem.
Therefore, we do experiments to select the appropriate point c. Select a smooth image region 100 (including the moon, desert, sky, etc.), each of the first image is divided into overlapping blocks of the same size, and select the block having the smallest variance in size as the patch, a total of 100 × 100 to 500 × 500 5 sizes with patches finally obtained 500
According to Equation 7 to give appropriate values of c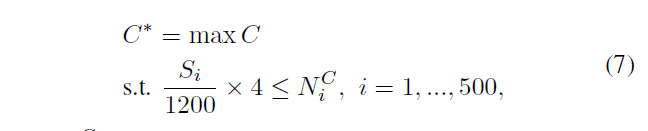
C is the contrast threshold, from 4 transferred 0, step = 0.01, constraints are \ (N ^ {C} _ {I} \) , the key number of points i-th patch is guaranteed at least \ (S ^ {i} \) there are 1200 pixels per key points on the size of the patch. FIG 4 d c is the relationship between the number of key value and, when c = 0.01 is the optimal solution, only a little better than c = 0.1, considering the mismatches, provided c = 0.1. Figure 4c is a result of c = 0.1
Scaling the input image
Scaling the input image can greatly enhance the number of critical points, as 4e, although s bigger, more critical point, but s too much time, resulting in tightly gathered critical point, the key point matching problem will worsen, so the trade-off s = 2
The above two methods can be a substantial increase in the number of critical points, but the key point will cause difficulties in matching and mismatched, so proposed above matching strategy and positioning technology to improve the problem below
Hierarchical feature matching Ⅳ
A key point matching problem
Figure 5a is tampered image
5b: 5 direct matching, key 2990, c = 4, s = 1
5c: 1 direct matching, key 35601, c = 0.1, s = 2
5d: 54 th scale clustering matching key 35601, c = 0.1, s = 2

After using the above method, the number of key points doubled 10 times, but never hits 5 down to 1, because the same position or adjacent positions different scales generate more critical points is very similar to the corresponding descriptors, contrary to the matching condition equation 5, referred to keypoint matching problem-I
Keypoint matches for tampered image create key subset described, matching is completed by two arbitrary similarity measure keypoints descriptors, using Euclidean distance
Between two points, the shortest straight line. Straight-line distance between two points Euclidean distance described
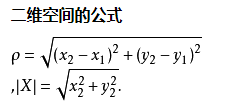
Equation 5, the key points to be paired ( \ (R_ {I}, \) \ (R_ {I} \) ) to satisfy
\ [\ frac {R_ {i } nearest point R_ {j} distance} { R_ {i} times near point distance S_ {j}} <threshold \]
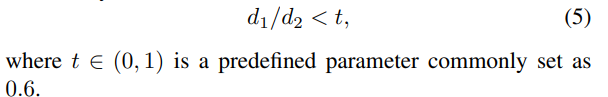
Matching algorithm computational complexity is greatly increased, referred keypoint matching problem-II
To solve the above two problems, the hierarchical feature matching algorithm, the algorithm structure shown in Figure 6,
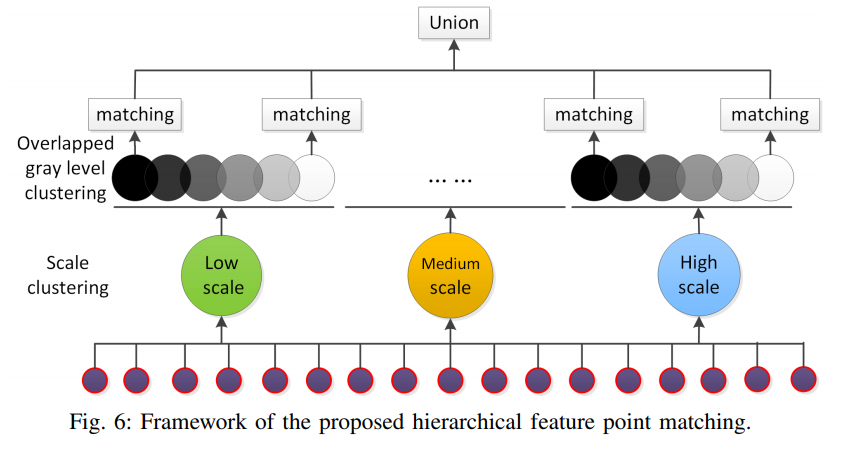
Consists of two parts, 1) is set by matching the scale clustering 2) is set by matching the overlapping clusters gradation
Group B is matched by the clustering scale
As shown in FIG 3, SIFT algorithm, the Gaussian images as octave group, the scale space keypoints detected. After using a method Ⅲ, tightly gathered key points of different scales, since the number of key points 1. octaves higher scale of relatively low-scale small-scale joint 2. High-matching key point for massive scaling robust, so this the solution is to be matched within a single octave, respectively, each a lower scale, and match together in multiple scales higher octave.
According to Equation 8, the key points are divided into 3 groups, octave1, octave2, octave3 above is a group
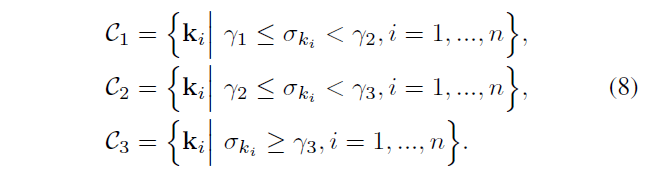
\ (\ gamma_ {i} \ ) is the first scale value DoG image in the i-th octave. \ (\ sigma_ {k} \ ) is the scale value of the key point k, the larger the smoother the image
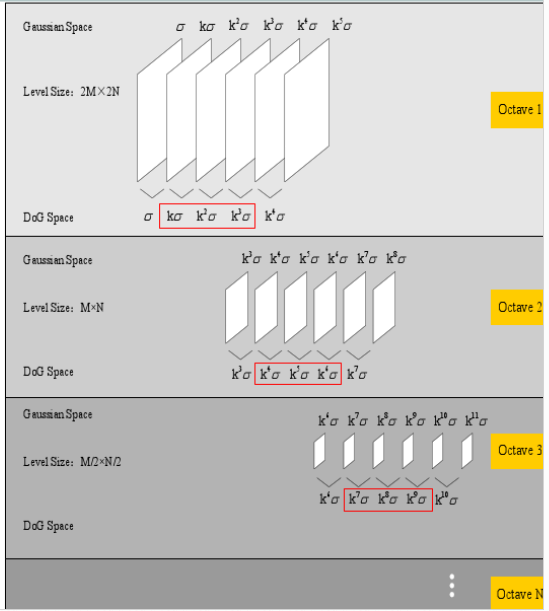
Thus, reducing the keypoint matching problem-I problem, as shown in FIG 5d.
Note that the number be increased to match the above, but at the expense of robustness to scale the image to a certain extent. Considering the high-scale C3 contains all the key points, to some extent, to retain the robustness of the picture for zooming. C1 C2 match for small scale robust
C Group matching via overlapped gray level clustering
Group by matching the overlapping clusters gradation
The SIFT Equation 5, all key points required distance calculation within the same group, so as to match. But with the increase in the number of critical points, the calculation burden. Thus, in the structures herein, an efficient matching algorithm is important, a matching strategy proposed - overlapping clusters matching the gradation
In the detection of copy and paste, a priori knowledge is, for a correct match is should have similar pixel values in two similar local area. Therefore, the gray scale value to the classification proposed critical point, then apply each gradation value in Equation 5 based matching.
Only the separation of all keys into several gray value classes, may be lost between the different gray values match the correct class, and therefore, the 0-255 into L overlapping subsets, step = c1, overlapped step = c2, as shown in equation 9
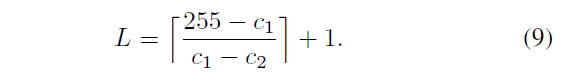

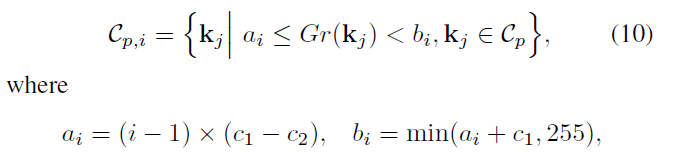
\ (C_ {p, i} \) represents a scale clustering of the i-th overlpped gray level clustering in the critical point, \ (A_ {i} \) \ (B_ {J} \) representative of the set of gray values the start and end points
P represents an image of all the matching pairs, \ (of P_ {P,} i \) represents a scale clustering in an i-th overlpped gray level clustering in matching pairs, having the formula 11
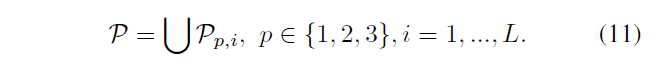
To eliminate matching errors, use
Ⅴ iterative forgery location
Iteration tamper location
Copy and paste detection algorithm based on key points, there is a problem in positioning
When there are a plurality tampered areas, homograohy not unique, and the number of the tampered unknown
All matching, and thus tampering point corresponding original point matching process, no separation of no matching sequence
RANSAC algorithm is to estimate a single homography, and should be matched to the matching order.
Previous solutions:
1) as described in [3], [15], proposed first keyword matches a keyword-based clustering algorithm for clustering by location, the original forged keywords and keywords separated into different clustering; then, connecting the two clusters are assigned a match identically matching sequence (from one cluster to another cluster) [3];
2) segmentation algorithm based on key points of [5], the entire image is first divided into small non-overlapped area, then a match between each of the divided regions. If the region contains a sufficient number of matching points, the area is considered to copy - corresponding to the movement.
Problems
1) a plurality of regions tampering, real cluster is unknown or tamper localization region close to endure, and the region easy to tamper with a cluster area into real
2) large-size image segmentation computationally intensive, difficult to find a universal algorithm parameters
Our approach
1) without any segmentation or clustering process
Robust Features (main direction and scale information) 2) critical points and take advantage of the color information
3) tamper with very accurate positioning
Specific steps
Step 1): Delete match isolated on;
Step 2): the local homography estimation;
Step 3): the use of a single dominant direction shall inliers selection and verification;
Step 4): scale and color information using tamper localization.
A Removal of isolated matched pairs
Detecting copy and paste a priori knowledge: tampering in a continuous shape, the correct matching key so should not isolated in a local area. According to Equation 12, abandoned the match against isolated

\ ({K} of N_ \) , \ (of N_ {K '} \) refers to the distance matching pair (k, k' distance) < \ (ISO T_ {100} = \) matches the number of
The remaining set of valid match is defined as M
B Estimation of the local homography
From M randomly selected (k, k '), Equation 14, \ (C_ {K} \) , \ (C_ {k'} \) represents \ (M_ {keys} \) key points where distances k and k 'near critical point
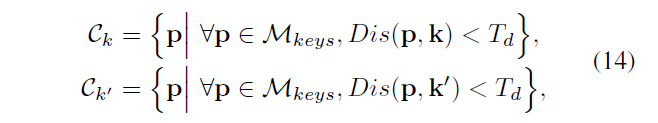
\ (M_ {keys} \) refers to the key points M, \ (T_ {D} \) = 100, the DIS (P, K) is calculated Euclidean distance of two key points
Generating \ (M_ {k} \) comprising distance (k, k ') near the critical point for all pairs (matching order from \ (C_ {K} \) to \ (C_ {K'} \) )
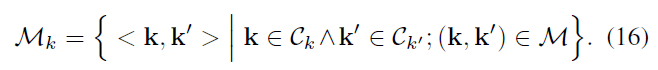
(https://blog.csdn.net/xuyangcao123/article/details/70916767)

\ (M_ {k} \) in their homograhy from two consecutive partial regions, assuming \ (H_k {} \) the same, thus solving the problem mentioned at the beginning Ⅴ.
[16] suggests a set of estimated affine matrix, each by a portion of an affine matrix also matched pair (three randomly selected adjacent pairs) is calculated. Their goal is to gather in a match of the concept of space right.
And we use all the matches from two adjacent local areas to estimate the affine matrix, and then use all inliers carried refine
C Homography validation and inliers selection using the dominant orientation
Homography verification and selected by the main direction inliers
RANSAC method is not completely accurate, especially when the number of inliers enough for a long time. We propose a novel single verification and input should point selection methods, the use associated with each key point leading direction.
In the SIFT algorithm, dominant orientation play an important role in the rotation invariance.
<k, k '> is correct matching, offset main direction keypoints \ (\ theta_ {k'} - \ theta_ {k} \) should be compatible with the estimated Affine Homography \ (H_k {} \) . Although some false matching may homography transformation obey the same, but their main direction is not compatible with BE \ (H_k {} \)
\ (H_k {} \) Writing
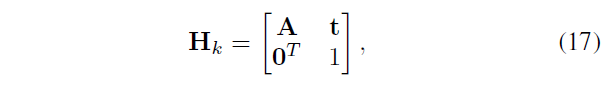
A non-singular matrix is a 2 × 2, \ (T = [T_ {X}, {Y} T_] T ^ {} \) is the transition vector transition matrix
Singular value decomposition formula
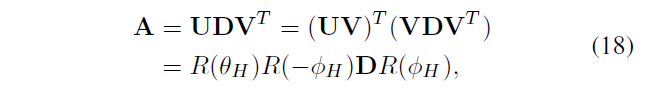
\ (R & lt (\ theta_ {H}) \) , \ (R & lt (\ phi_ {H}) \) representative of the rotational operation, the parameter is \ (\ theta_ {H} \) , \ (\ phi_ {H} \)
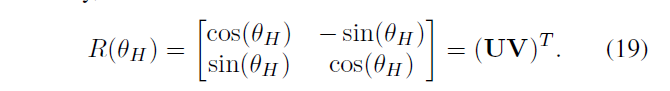
Copy and paste patch may be rotated clockwise or counterclockwise, so the \ (\ theta_ {h} \ ) maps to (0, \ (2 \ PI \) ] Space
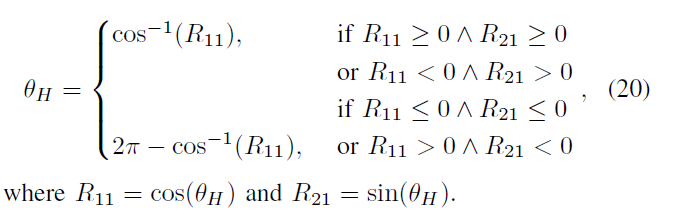
Defined function to verify \ (H_k {} \) correctly
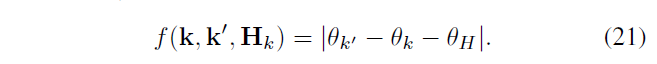
For estimating the correct \ (H_k \) and correct matching of <k, k '>, f should be close to zero.
\ (\ hat {M_ {k }} \) expressed \ (H_k \) returns after doing RANSAC algorithm results inliers set, known \ (\ hat {M_ {k }} \ subseteq {M_ {k}} \) , to eliminate false inliers, if and only if \ (\ hat {M_ {k }} \) more than 90% of the time satisfying the formula 22, to accept \ (H_k \) ( \ (T_ \ Theta = 15 \) )
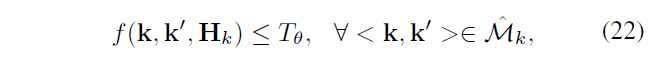
With (H_k \) \ later,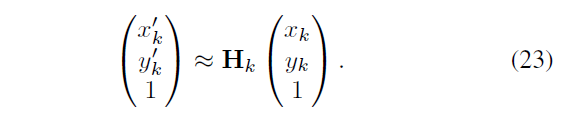
With \ (M_H \) represents liners selected, k is a key point
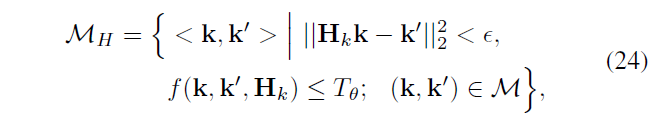
Refine and then get Linera \ (H_k \)
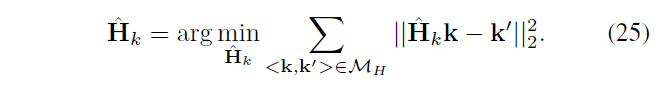
D Forgery localization in dense fields
In the proposed algorithm-intensive field positioning tampering
- The construction of each input point scale information suspect areas
- By verifying the consistency of color information to refine the suspicious area
Is \ (m_h \) each inlier point k a partial circular configuration suspected area
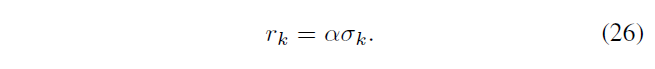
\ (\ sigma_k \) is a measure of the value of k, \ (\ Alpha = 16 \) is a hyper-parameters
\ (M_h \) of each point matching sequence, so to obtain two suspect areas S S '
Use color information to optimize the suspicious area
S k via the homography into k *
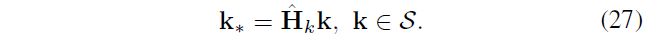
When the k and k * RGB information similar to the k and k * are a copy and paste considered point
Q1 represents all points based on the copy and paste S calculated,
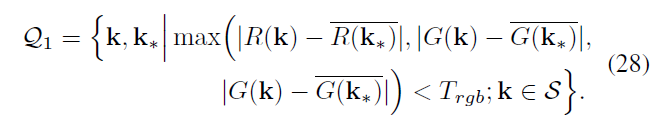
among them 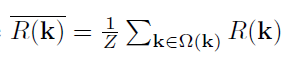
\ (\ Omega (k) \) is the k field of the 3 × 3, Z is a normalization factor, the threshold value \ (T_rgb = 10 \)
In S 'k' in the opposite way conversion
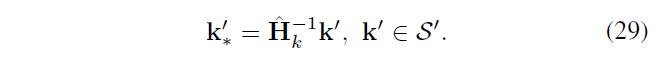
Q2 represents all points based on the copy and paste S 'calculated,
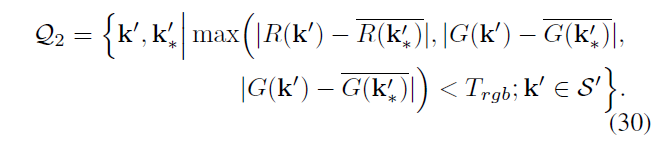
B represents a binary image tamper location, region 1 represents tampering, 0 represents the original image, B is first initialized to 0, then Q1 Q2 referred to as a point marked
Note that, by the above step 2) -4), we can obtain a copy up to meet the homographic transformations - the movement area. However, when a plurality of clones, a homography may not be unique. Our localization algorithm is iterative, as shown in FIG.
Specifically, in our approach, step 2) -4) is repeated K iterations (in our experiments K = 15). In each iteration, we use only part of the match to estimate a homography
After completion of all iterations, on B: Remove a small area, the morphological closing operation to fill the small gap,
Finally generated the detected region forgery
Ⅵ experiment
data set:
- FAU: containing 48 and 48 with the original image corresponding to a real copy - tampered image moving operation, an average resolution of approximately 3000 × 2300
- GRIP: 80 contains the original image 80 and moved tamper replication fidelity, it is the same size 768 × 1024. It is noteworthy that, GRIP some tampering with patches very smooth, which is based on sparse sampling replication (such as SIFT) - The mobile tamper detection is a challenge
- MICC-F220: a tampered image 110 and 110 are not tampered image composition, resolution from 722 × 480 to 800 × 600
- MICC-F600: a tampered image 160 and 440 composed of the original image, the image resolution from 800 × 533 to 3888 × 2592
- CMH: comprising 108 clones real image resolution from 845 × 634 to 1296 × 972
- (COVERAGE) [ https://github.com/wenbihan/coverage ]: The raw data set 100 - tampered images, the average resolution of 400 × 486. Each image contains similar but real objects. In our experiments, we used the original 91 - tampering subset of images for composition, excluding 9 released ground truth incorrect image pairs.
Test results
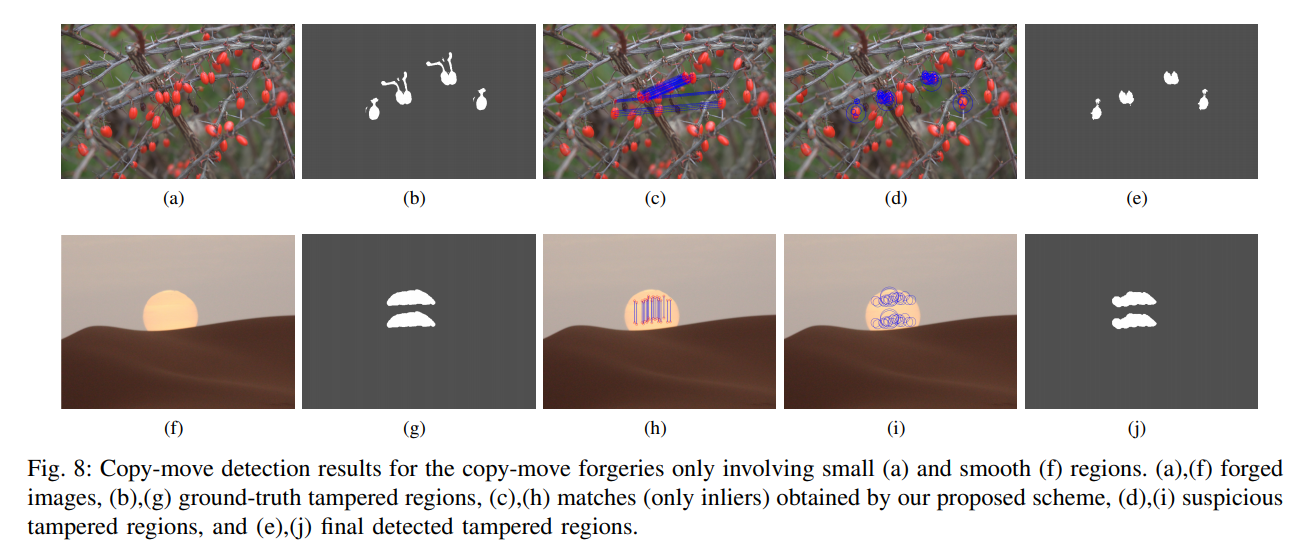
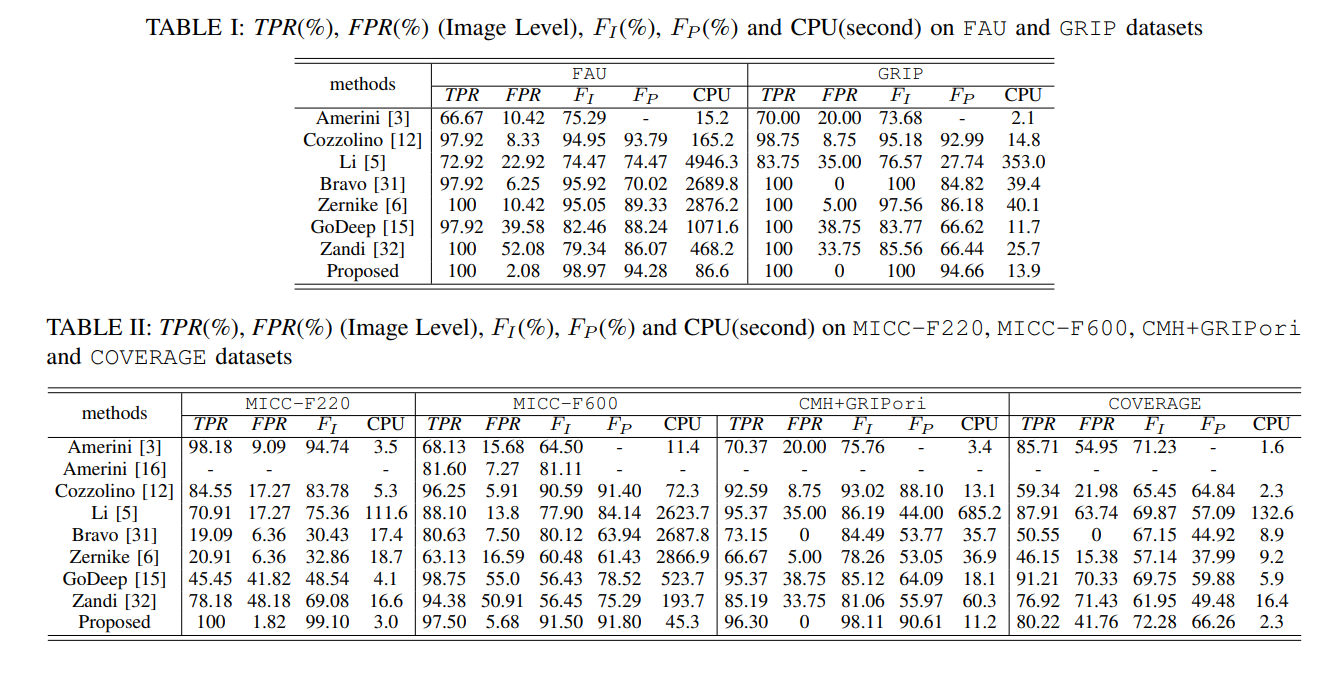
8, Table 12, are the results of the FAU GRIP
Robust Detection
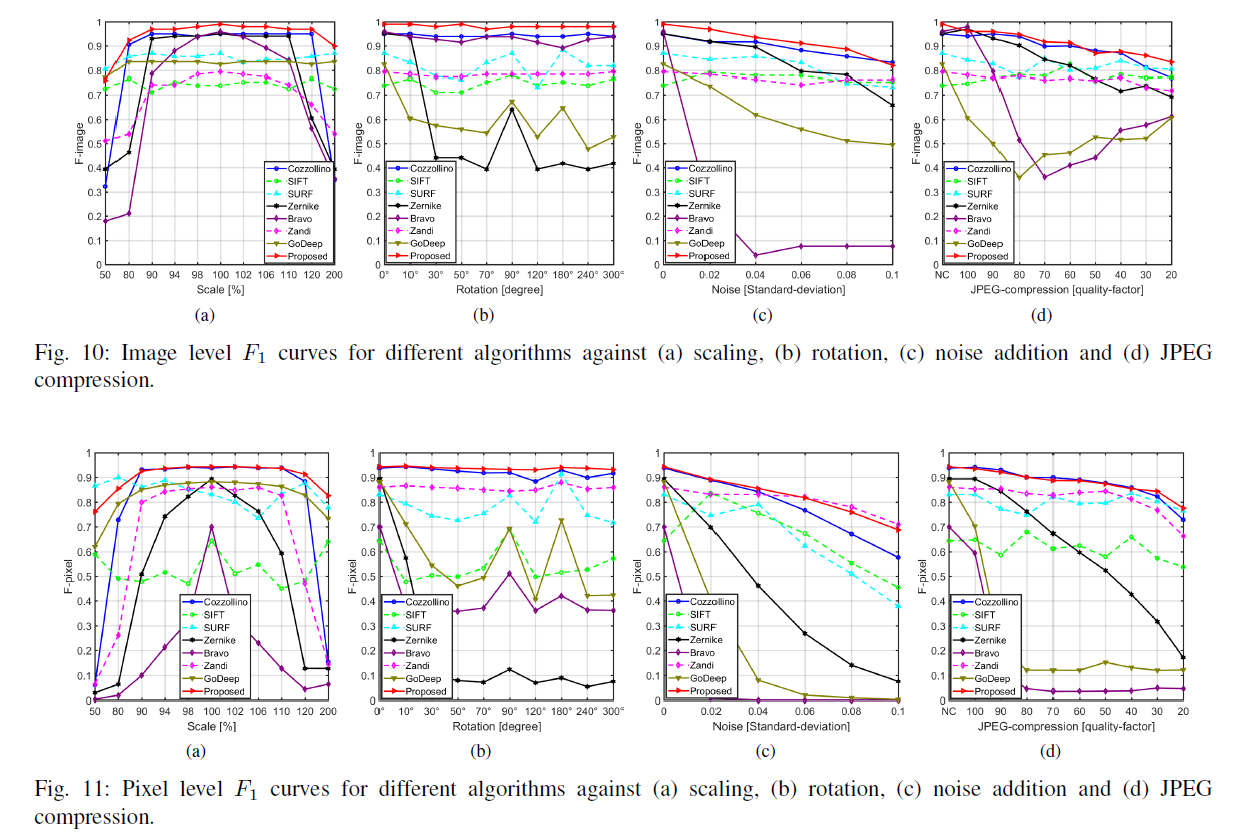
Table 3 is to show the impact of the different stages of the algorithm, the data set in the FAU
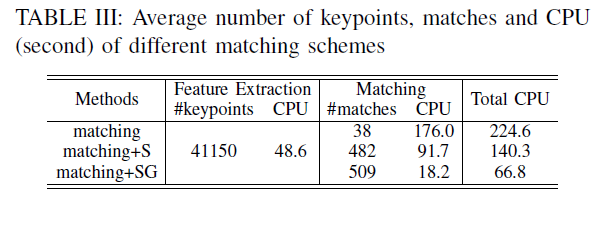
matching showing a conventional matching method
matching + S represents a set of matched only for clustering scale
matching + SG indicates a hierarchical matching the proposed method (including overlapping gray value scale clustering and cluster)
reference
https://wenku.baidu.com/view/87270d2c2af90242a895e52e.html?re=view