
Faltungs-Neuronales Netzwerk
Jeder Faltungskern extrahiert unterschiedliche Merkmale . Jeder Faltungskern faltet die Eingabe, um eine Feature-Map zu generieren. Diese Feature-Map spiegelt die vom Faltungskern aus der Eingabe extrahierten Features wider.
- Extraktion des flachen Faltungskerns: zugrunde liegende Pixelmerkmale wie Kanten, Farben und Flecken;
- Faltungskernextraktion mittlerer Ebene: Texturmerkmale mittlerer Ebene wie Streifen, Linien, Formen usw.;
- Extraktion des Faltungskerns auf hoher Ebene: semantische Merkmale auf hoher Ebene wie Augen, Reifen, Text usw.
Schließlich gibt die Klassifizierungsausgabeschicht das abstrakteste Klassifizierungsergebnis aus.
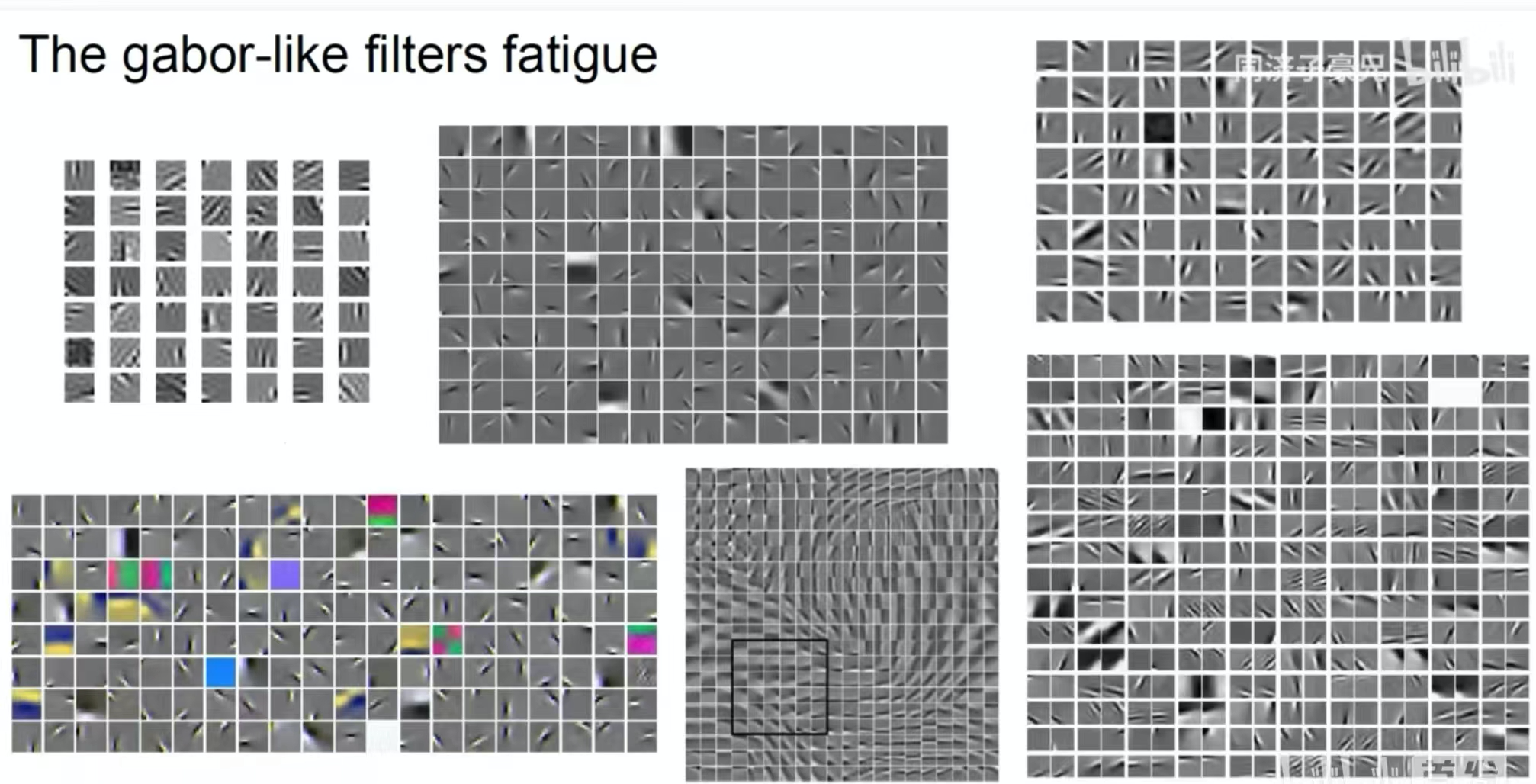
Das Bild oben zeigt die von einem flachen Faltungskern extrahierten Merkmale. Wir können sehen, dass einige Faltungskerne Formen und andere Farben extrahieren. Es handelt sich um eine Faltungsfunktion ähnlich dem Gabor-Filter.

Das Bild oben zeigt die vom mittleren und tiefen Faltungskern extrahierten Merkmale. Der mittlere Faltungskern extrahiert größere Farb- und Texturblöcke. Die vom tiefen Faltungskern extrahierten Merkmale können Menschen oder einige konkrete Dinge umfassen.
CAM-Interpretierbarkeit
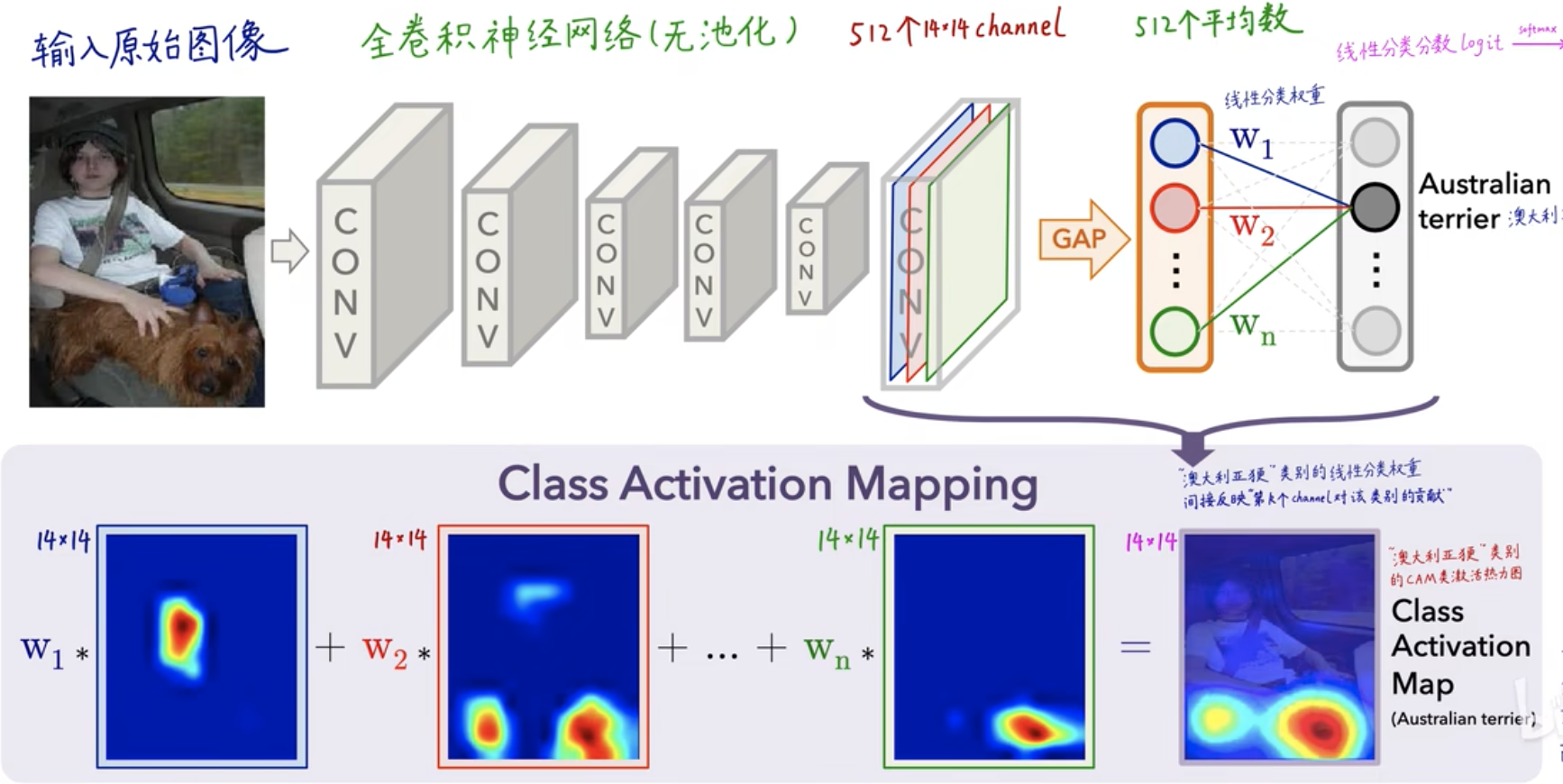
In der obigen Abbildung wurde das eingegebene Originalbild Schicht für Schicht gefaltet. Auf der letzten Schicht gibt es 512 Faltungskerne und 512 Kanäle, d. h. nach GAP (Global Average Pooling) wurden 512 tiefe Merkmale extrahiert Für jedes Kanalmerkmal wird ein Durchschnitt berechnet, und dann wird das Gewicht (Koeffizient) jedes Merkmalswerts über die FC-Schicht (vollständig verbundene Schicht) erhalten – \(W_1, W_2, W_3,..., W_n\) für jeden Kategorie Sie können einen Bewertungswert (Score) erhalten, der durch erhalten wird
\(score=W_1*blauer Eigenwert+W_2*roter Eigenwert+...+W_n*grüner Eigenwert\)
Erhalten und berechnen Sie schließlich einen Wahrscheinlichkeitswert durch Softmax, einen Prozess der CNN-Wärmekarte, der sich hauptsächlich im \(W_1, W_2, W_3,..., W_n\)Merkmalswertgewicht widerspiegelt gibt den Grad der Aufmerksamkeit an, den das endgültige Klassifizierungsergebnis verschiedenen Merkmalen schenkt .
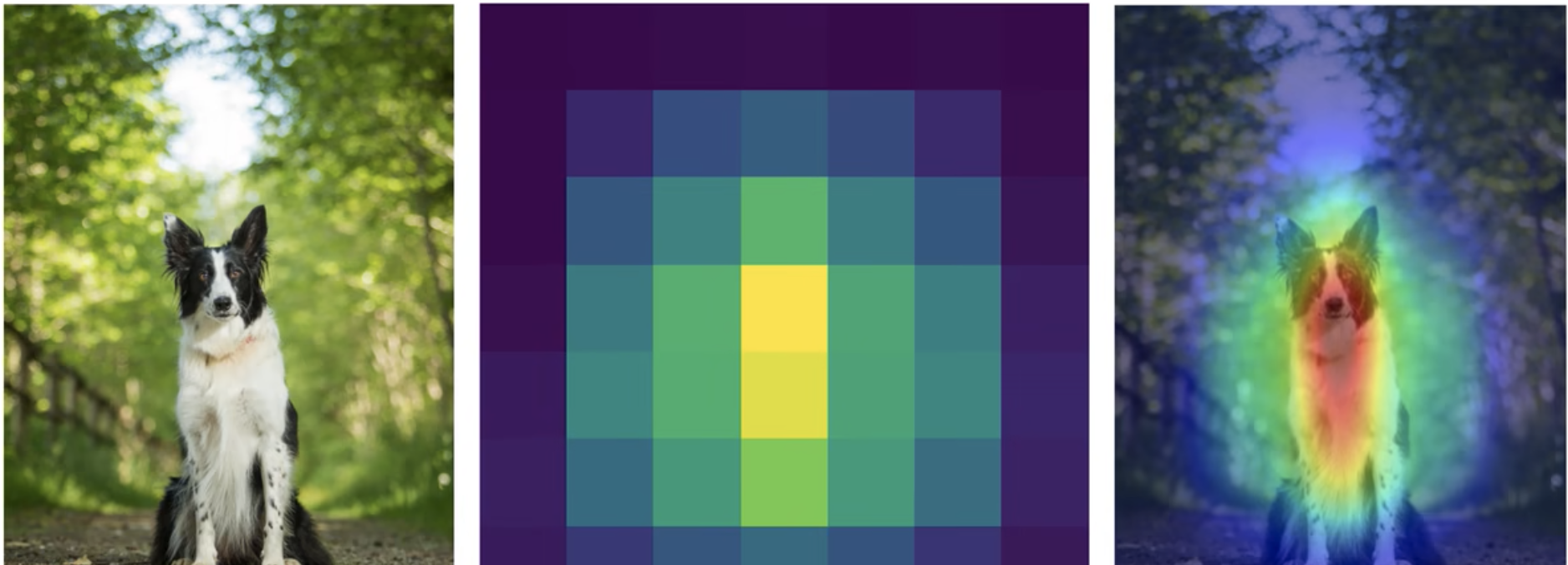
- Nachteile von CAM
- Es muss eine GAP-Schicht vorhanden sein, andernfalls muss die Modellstruktur geändert und neu trainiert werden.
- Nur die Ausgabe der letzten Faltungsschicht kann analysiert werden, die mittlere Schicht kann nicht analysiert werden.
- Nur Bildklassifizierungsaufgaben
GradCAM

In GradCAM können Sie anstelle der GAP-Ebene vollständig die FC-Ebene verwenden, um die Partitur über die vollständig verbundene Ebene auszugeben, dargestellt durch \(y^c\) .
- Ableitung einer Matrix
1. Die Ableitung einer Skalarfunktion nach einem Vektor:
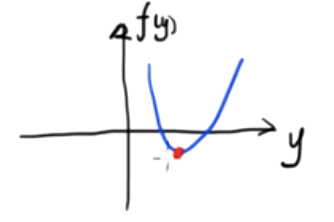
Dies ist eine zweidimensionale Skalarfunktion. Wir wissen, dass der Minimalwert dieser Funktion ist
\({df(y)\over dy}=0\)
Wenn es sich bei dieser Funktion um eine dreidimensionale Skalarfunktion handelt, die aus zwei unabhängigen Variablen besteht, sieht das Bild wie folgt aus
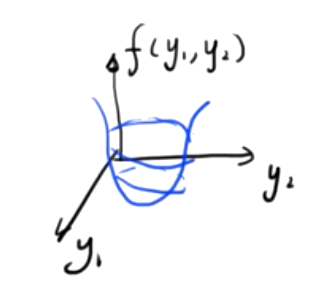
Finden Sie gleichzeitig den Minimalwert dieser Binärfunktion
- \({∂f(y_1,y_2)\über ∂y_1}=0\)
- \({∂f(y_1,y_2)\over ∂y_2}=0\)
Wenn eine Skalarfunktion n unabhängige Variablen \(f(y_1,y_2,y_3,...,y_n)\) hat , definieren wir einen Vektor
Y=[ ![]() ]
]
Dann kann die partielle Ableitung der Funktion nach dem Vektor Y definiert werden als
\({∂f(Y)\over ∂Y}=\) \([\) 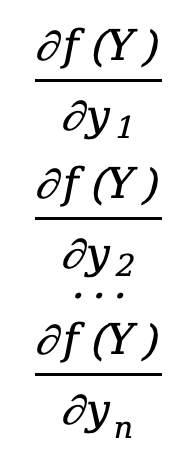 \(]\)
\(]\)
Dies ist ein n*1-Spaltenvektor, und wir stellen fest, dass seine Zeilenanzahl mit dem Nenner Y übereinstimmt. Dieses Layout wird als Nennerlayout bezeichnet .
Ebenso können wir auch die partielle Ableitung der Funktion nach dem Vektor Y definieren als
\({∂f(Y)\over ∂Y}=[{∂f(Y)\over ∂y_1}{∂f(Y)\over ∂y_2}...{∂f(Y)\over ∂y_n }]\)
Dies ist ein 1*n-Zeilenvektor, und wir stellen fest, dass seine Zeilenanzahl mit dem Zähler f(Y) (ein 1*1-Skalar) übereinstimmt. Ein solches Layout wird Zählerlayout genannt .
Das Nenner-Layout und das Zähler-Layout sind die Transponierten voneinander .
Beispiel 1: \(f(y_1,y_2)=y_1^2+y_2^2\)
Nenner-Layout:
Sei Y=[ ![]() ]
]
Aber
\({∂f(Y)\over ∂Y}=\) [ ![]() ]=[
]=[ ![]() ]
]
Molekularer Aufbau:
令\(Y=[y_1 y_2]\)
Aber
\({∂f(Y)\over ∂Y}=[{∂f(Y)\over ∂y_1} {∂f(Y)\over ∂y_2}]=[2y_1 2y_2]\)
2. Ableitung der Vektorfunktion nach dem Vektor
Wenn unsere Funktion auch ein Vektor ist
F(Y)=[ 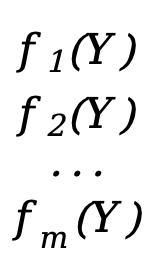 ]
]
Jedes \(f_x(Y)\) (x=1,2,3,...,m) entspricht hier einer Skalarfunktion f(Y) oben (die unabhängige Variable ist der Vektor Y), F(Y) ist eine Vektorfunktion von m*1.
Beispiel eins:
- Y=[
 ]
] - F(Y)=[
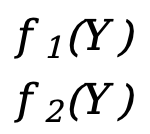 ]=[
]=[ 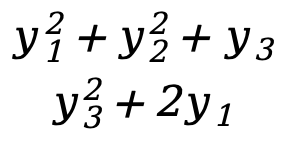 ]
]
Die partielle Ableitung einer Vektorfunktion nach einem Vektor ist das Nennerlayout
\({∂F(Y)\over ∂Y}=\) [ 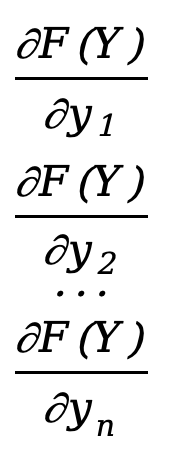 ]=[
]=[ 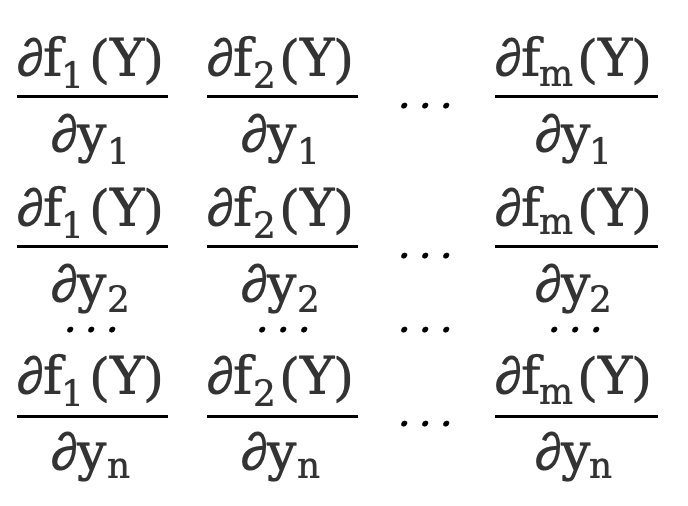 ]
]
Wie in Beispiel 1 gibt es
\({∂F(Y)\over ∂Y}=\) [ ![]() ]=[
]=[ 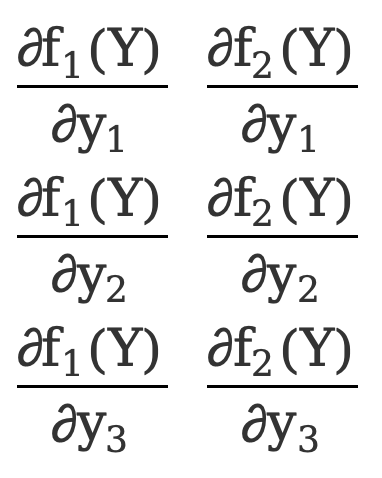 ]=[
]=[ 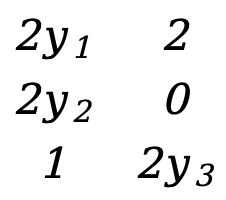 ]
]
Dies ist eine 3*2-Matrix.
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! Google bestätigte Entlassungen, die den „35-jährigen Fluch“ chinesischer Programmierer in den Flutter-, Dart- und Teams- Python mit sich brachten stark und wird von GPT-4.5 vermutet; Tongyi Qianwen Open Source 8 Modelle Arc Browser für Windows 1.0 in 3 Monaten offiziell GA Windows 10 Marktanteil erreicht 70 %, Windows 11 GitHub veröffentlicht weiterhin KI-natives Entwicklungstool GitHub Copilot Workspace JAVA ist die einzige starke Abfrage, die OLTP+OLAP verarbeiten kann. Dies ist das beste ORM. Wir treffen uns zu spät.