

Der Extended Berkeley Packet Filter ( eBPF ) kann schnell und kontinuierlich aktualisiert werden und eignet sich daher ideal für die Bewältigung häufiger Änderungen der Sicherheitskonfiguration.
Übersetzt aus „ How to Manage XDP/eBPF Effectively for Better DDoS Protection“ , Autor Ivan Koveshnikov.
Die Extended Berkeley Packet Filter ( eBPF )-Karte dient als High-Level-Schnittstelle für atomare Aktualisierungen der gemeinsam genutzten Speichersegmente, die als gemeinsam genutzter Speicher verwendet werden, und bietet eine leistungsstarke Konfigurationsschnittstelle für eBPF-Programme. Der Lese-, Kopier- und Aktualisierungsmechanismus minimiert den Leistungsaufwand im Hot Path. Darüber hinaus ermöglicht die eBPF-Zuordnung den exklusiven Zugriff auf gemeinsam genutzte Speichersegmente. Sie können gemischte Kartentypen (Arrays, Hash-Tabellen, Bloom-Filter, Warteschlangen und Ringpuffer) verarbeiten, was sie ideal für komplexe Konfigurationen wie Sicherheit macht .
Mit zunehmender Konfigurationskomplexität steigt auch der Bedarf an Verbindungen zwischen verschiedenen Mapping-Einträgen. Wenn zu viele Verbindungen zwischen Karteneinträgen bestehen, verschlechtert sich die Fähigkeit, atomare Konfigurationsaktualisierungen vorzunehmen. Das Aktualisieren nur eines Karteneintrags kann dazu führen, dass andere Einträge gleichzeitig aktualisiert werden müssen, was zu Inkonsistenzen bei Aktualisierungen führen kann.
Wenden Sie XDP für erweitertes Verkehrsmanagement an
Stellen Sie sich ein einfaches eXpress Data Path (XDP) -Programm vor, das den Datenverkehr basierend auf einem Fünf-Tupel-Prioritätsregelsatz klassifiziert und filtert. Das Programm verarbeitet das nächste Paket basierend auf der Priorität der Regel und einer Kombination aus Quell-IP-Adresse, Ziel-IP-Adresse, Protokoll sowie Quell- und Ziel-Ports des Pakets.

Flussdiagramm der Klassifizierung, die zur Verarbeitung führt.
Das Folgende ist ein Beispiel für eine Netzwerkkonfigurationsregel:
- Jeglicher Datenverkehr von Subnetz A ist immer zulässig.
- Verhindern Sie, dass Clients in Subnetz C auf den Webserver in Subnetz B zugreifen.
- Beschränken Sie den Zugriff auf den Webserver in Subnetz B.
- Alle anderen Zugriffe werden verweigert.
Diese Regeln erfordern die Speicherung von Verkehrsklassifizierungsregeln und -beschränkungen in der Konfiguration, was durch die Verwendung von eBPF-Zuordnungen erreicht werden kann.
Verstehen Sie die eBPF-Programmkonfiguration als Baumstruktur
Sie können die Konfiguration als hierarchischen Baum mit einem „Konfigurationsstamm“ als Basis visualisieren. Dieser Stamm (möglicherweise virtuell) organisiert die verschiedenen Konfigurationseinheiten, um die aktive Konfiguration zu bilden. Entitäten sind entweder direkt mit dem Stamm verbunden, um sofortigen globalen Zugriff zu ermöglichen, oder für eine strukturierte Organisation in anderen Entitäten verschachtelt.
Der Zugriff auf eine bestimmte Entität beginnt im Stammverzeichnis und erfolgt sequentiell („Dereferenzierung“ jeder Ebene), bis die gewünschte Entität erreicht ist. Um beispielsweise ein boolesches Flag aus einer „Options“-Struktur in einer Sammlung abzurufen, würden Sie zur Sammlung navigieren, die Struktur suchen und dann die Flags abrufen.
Gcores Ansatz zur Bewältigung der Komplexitätsherausforderungen von eBPF
Diese Baumstruktur bietet Flexibilität bei der Konfigurationsverwaltung, einschließlich des atomaren Austauschs jedes Teilbaums, und sorgt so für reibungslose Übergänge ohne Unterbrechung. Die zunehmende Komplexität bringt jedoch Herausforderungen mit sich. Je komplexer die Konfigurationen werden, desto stärker sind die Einträge miteinander verbunden. Es kommt häufig vor, dass mehrere übergeordnete Einträge auf einen einzelnen untergeordneten Eintrag verweisen oder dass ein Eintrag eine doppelte Rolle spielt, sowohl als Eigenschaft einer Entität als auch als Teil einer Sammlung.
Moderne Programmiersprachen haben Mechanismen zur Verwaltung komplexer Konfigurationen entwickelt. Entwickler verwenden Referenzzähler, veränderliche und unveränderliche Referenzen sowie Garbage Collectors, um sichere Updates zu gewährleisten. Die Verwaltung der Sicherheit dieser Konfigurationen garantiert jedoch keine Atomizität beim Wechsel zwischen Konfigurationsversionen.
Die sich ständig verändernde Landschaft des Online-Verkehrs bedeutet, dass Sicherheitsteams häufig Änderungen an den Sicherheitsrichtlinien vornehmen müssen. Daher hat Gcore den Gcore-DDoS-Schutz schnell und regelmäßig aktualisiert und wichtige Funktionen wie eine Engine für reguläre Ausdrücke integriert. Wir sind über die standardmäßigen ein oder zwei Updates pro Tag für selbst gehostete Lösungen hinaus auf nahezu konstante Updates übergegangen, die von Dienstanbietern gefordert werden. Diese Anforderung, die in Linux-Anwendungen oft übersehen wird, hat zur Einführung der eBPF-Technologie geführt, die schnelle, unterbrechungsfreie Updates ermöglicht.
Bei der Erkundung von eBPF-Lösungen müssen wir gründlich Strategien erkunden, um sicherzustellen, dass unsere eBPF-Konfiguration bestmöglich gehandhabt wird. Insbesondere die Einschränkungen der eBPF-Zuordnung veranlassten unser Team, unsere Konfigurationsspeicherstrategie zu überdenken.
Aufgrund der Kernel-Sicherheitsvalidierung können eBPF-Map-Einträge keine direkten Zeiger auf beliebige Speichersegmente speichern, was einen Suchschlüssel erfordert, um auf den Map-Eintrag zuzugreifen, was den Suchvorgang verlangsamt. Dieser Mangel bietet jedoch einen Vorteil: Er ermöglicht es uns, komplexe Konfigurationsbäume in kleinere, besser verwaltbare Segmente zu unterteilen, die direkt mit dem Konfigurationsstamm verknüpft sind. Was ist das Ergebnis? Konsistenz, auch bei nicht-atomaren Updates.
Unsere Ergebnisse und Strategien unterstreichen die Bedeutung einer sorgfältigen Planung und Durchführung von eBPF-Programmen zur Optimierung der Effizienz. Wenden wir uns nun den spezifischen Konfigurationsaktualisierungsstrategien für eBPF-Umgebungen und ihrer Anwendbarkeit auf die besonderen Anforderungen und Einschränkungen des Systems zu.
Richtlinie zur Aktualisierung der Sicherheitskonfiguration
Wir haben festgestellt, dass drei Update-Strategien besonders effektiv sind, um Programmaktualisierungen zu verbessern und gleichzeitig eine hohe Leistung und Flexibilität sicherzustellen.
Update-Strategie 1: Allmählicher Übergang
Eine schrittweise Aktualisierungsstrategie bedeutet inkrementelle Konfigurationsaktualisierungen über mehrere Zuordnungen hinweg. Dies ist eine nützliche Option, wenn Daten in einer Karte verarbeitet werden, um einen Suchschlüssel für eine andere Karte bereitzustellen. In diesem Fall müssen mehrere Karteneinträge aktualisiert werden und eine atomare Konvertierung ist nicht möglich. Aber präzise und sequentielle Aktualisierungsvorgänge ermöglichen methodische Aktualisierungen der Konfiguration. Einige Vorgänge an referenzierten Konfigurationsteilbäumen werden sicher, wenn sie in der richtigen Reihenfolge ausgeführt werden.
Im Kontext der Klassifizierung und Verarbeitung stellt die Klassifizierungsschicht beispielsweise Suchschlüssel für übereinstimmende Sicherheitsrichtlinien bereit, was bedeutet, dass Aktualisierungsvorgänge einer bestimmten Reihenfolge folgen sollten:
- Das Einfügen einer neuen Sicherheitsrichtlinie ist sicher , da auf die neue Richtlinie noch nicht verwiesen wurde.
- Es ist auch sicher , bestehende Sicherheitsrichtlinien zu aktualisieren, da die Aktualisierung einzelner Sicherheitsrichtlinien normalerweise keine Probleme verursacht. Obwohl atomare Updates wünschenswert sind, bieten sie keine wesentlichen Vorteile.
- Es ist sicher , die Klassifizierungsebenenzuordnung zu aktualisieren , um auf die neue Sicherheitsrichtlinie zu verweisen und Verweise auf die veraltete Richtlinie zu entfernen.
- Es ist sicher , nicht verwendete Sicherheitsrichtlinien aus der Konfiguration zu entfernen, sobald sie nicht mehr referenziert werden.
Auch ohne atomare Updates können sichere Updates durchgeführt werden, indem der Update-Prozess richtig sequenziert wird. Diese Methode eignet sich am besten für eigenständige Zuordnungen, die nicht eng mit anderen Zuordnungen verknüpft sind.
Wir empfehlen, inkrementelle Aktualisierungen durchzuführen, anstatt die gesamte Karte auf einmal zu aktualisieren. Beispielsweise sind inkrementelle Aktualisierungen von Hash-Maps und Arrays völlig sicher. Dies ist jedoch bei inkrementellen Aktualisierungen einer LPM-Karte (Longest Prefix Match) nicht der Fall, da die Suche von Elementen abhängt, die bereits in der Karte vorhanden sind. Das gleiche Problem tritt auf, wenn Sie zum Erstellen eines Suchschlüssels für eine andere Tabelle Elemente aus mehreren Karten bearbeiten müssen.
Klassifizierungsebenen werden häufig mithilfe mehrerer LPMs und Hash-Tabellen implementiert, was ein Beispiel für diese Komplexität darstellt:
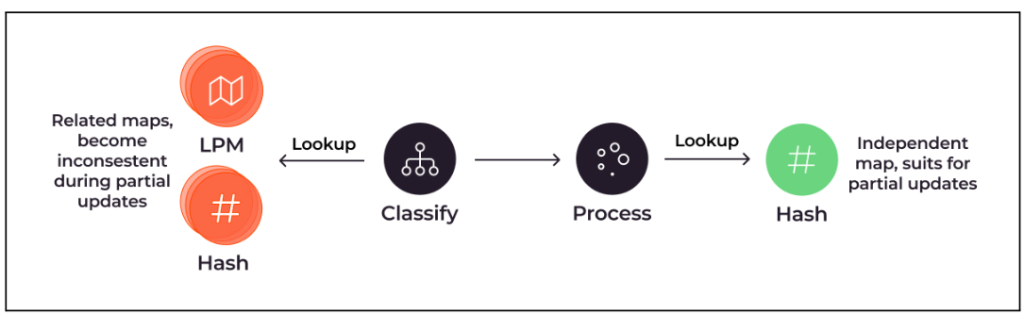
Suchabläufe von der Klassifizierung über LPM und Hashing und von der Klassifizierung über die Verarbeitung bis hin zum Hashing, mit Beschreibung des Zuordnungsaktualisierungsproblems.
Update-Strategie 2: Mapping-Ersatz
Für Zuordnungen, die nicht ohne Inkonsistenz inkrementell aktualisiert werden können (z. B. LPM-Zuordnungen), ist der Austausch der gesamten Zuordnung die beste Lösung. Um das Mapping des eBPF-Programms zu ersetzen, benötigen Sie ein Mapping des Mappings. Eine Userspace-Anwendung kann eine neue Karte erstellen, sie mit den erforderlichen Einträgen füllen und dann die alte Karte atomar ersetzen.

Die zugeordnete Zuordnung führt zu zwei Knoten mit Ressourcenisolations- und Ersetzungsfunktionen.
Die Partitionierung der Konfiguration in separate Karten, die jeweils die Einstellungen einer einzelnen Entität beschreiben, bietet den zusätzlichen Vorteil der Ressourcenisolation und macht es überflüssig, die vollständige Konfiguration bei kleineren Aktualisierungen neu zu erstellen. Die Konfiguration jeder Mehrfachentität kann in einer austauschbaren Karte gespeichert werden.
Diese Methode hat einige Nachteile. Der Benutzerbereich muss die vorherige Zuordnung aufheben, um den vorherigen festen Pfad beizubehalten, da die Ersatzzuordnung nicht an derselben Position wie die vorherige Zuordnung angeheftet werden kann. Dies ist besonders wichtig für Langzeitprogramme, die ihre Konfiguration häufig aktualisieren und für Stabilität auf Map Pinning angewiesen sind.
Update-Strategie 3: Programmaustausch
Die Kartenersetzungsmethode schlägt möglicherweise fehl, wenn mehrere Karten miteinander verknüpft werden. Das alleinige Aktualisieren der Zuordnung kann zu einem inkonsistenten oder ungültigen Zustand führen, der weder die alte Konfiguration noch die erwartete neue Konfiguration widerspiegelt.
Um dieses Problem zu lösen, sollten atomare Updates auf einer höheren Ebene erfolgen. Obwohl eBPF über keinen Mechanismus zum atomaren Ersetzen einer Reihe von Zuordnungen verfügt, sind Zuordnungen normalerweise mit einem bestimmten eBPF-Programm verknüpft. Dieses Problem kann gelöst werden, indem die miteinander verbundenen Zuordnungen und der entsprechende Code in separate eBPF-Programme aufgeteilt werden, die durch Tail Calls verknüpft sind.
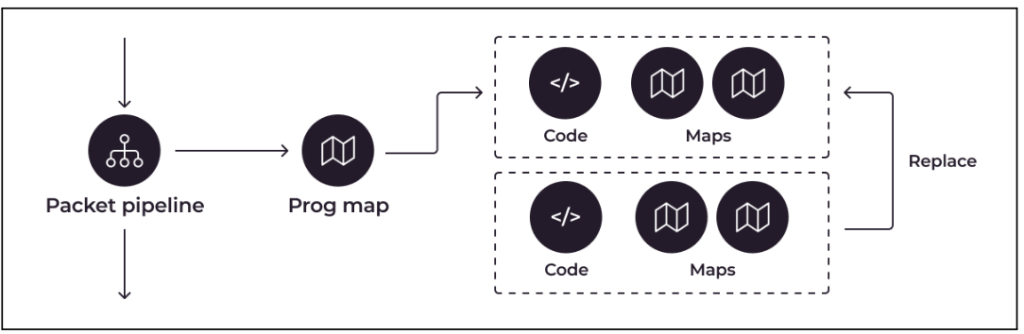
Paketpipeline-zu-Programm-Mapping-Flussdiagramm, das zu austauschbaren Code- und Mapping-Paketen für eBPF-Programme führt.
Um dies zu erreichen, müssen Sie ein neues eBPF-Programm laden, die Zuordnung dafür erstellen und füllen, beides anheften und dann die Programmzuordnung aus dem Benutzerbereich aktualisieren. Dieser Vorgang ist aufwändiger als ein einfacher Mapping-Ersatz, ermöglicht jedoch die gleichzeitige Aktualisierung des Mappings und des zugehörigen Codes und erleichtert so die Anpassung des Laufzeitcodes. Allerdings ist die Verwendung dieses Ansatzes nicht immer besonders effizient, insbesondere wenn mehrere Karten und Unterroutinen verwendet werden, um einen einzelnen Karteneintrag in einem komplexen Programm zu aktualisieren.
Fehlerbehandlung
Der Umgang mit Fehlern bei der Verwaltung von eBPF kann schwierig sein. Es ist wichtig, die Konfiguration zu aktualisieren, um Inkonsistenzen zu vermeiden. Wenn während eines Updates ein Fehler auftritt, kann dies zu Chaos führen. Automatisierte Backups können daher dazu beitragen, den Bedarf an manuellen Korrekturen zu reduzieren.
Sie können Fehler in zwei Kategorien einteilen: behebbare Fehler und nicht behebbare Fehler. Bei behebbaren Fehlern gilt: Wenn während eines Updates etwas schief geht, können Sie es einfach stoppen und es werden keine Änderungen vorgenommen. Sie können jeden Fehler ohne Risiko beheben.
Nicht behebbare Fehler sind etwas schwieriger. Sie müssen vorsichtig damit umgehen, da sie sich auf bestimmte Konfigurationseinheiten auswirken können, wodurch das gesamte System beschädigt werden kann.
Es ist besser, Aktualisierungen nach Konfigurationseinheit statt nach Aktualisierungstyp zu organisieren. Auf diese Weise betrifft ein Fehler nur eine bestimmte Konfigurationseinheit und nicht alles auf einmal. Wenn beispielsweise Klassifizierungsregeln und Sicherheitsrichtlinien für verschiedene Netzwerksegmente definiert sind, wäre es effizienter, sie in separaten Zyklen basierend auf dem Netzwerksegment statt nach Aktualisierungstyp zu aktualisieren. Dies erleichtert die Handhabung automatisierter Backups und wenn ein nicht behebbarer Fehler auftritt, wissen Sie genau, welche Auswirkungen dies hat. Nur ein Teil des Netzwerks ist inkonsistent konfiguriert, während der Rest davon nicht betroffen ist oder schnell auf eine neue Konfiguration umgestellt werden kann.
Verwalten Sie den Lebenszyklus des eBPF-Programms für Updates
Die Verfolgung des Lebenszyklus eines eBPF-Programms ist von entscheidender Bedeutung für Programme, die Persistenz, häufige Aktualisierungen und Statusbeibehaltung über verschiedene Codeinstanzen hinweg erfordern. Wenn Ihr XDP-Programm beispielsweise häufige Codeaktualisierungen erfordert und gleichzeitig bestehende Clientsitzungen aufrechterhält, ist eine effektive Verwaltung seines Lebenszyklus von entscheidender Bedeutung.
Für Entwickler, die die Flexibilität maximieren und Einschränkungen vermeiden möchten, sollte das Ziel darin bestehen, nur wichtige Informationen zwischen den Neuladevorgängen beizubehalten – Daten, die nicht aus dem nichtflüchtigen Speicher abgerufen werden können. Auf diese Weise können Sie eBPF-Mappings für dynamische Konfigurationsanpassungen verwenden.
Um den Hot-Code-Neuladevorgang einfacher zu gestalten, müssen Sie in der Lage sein, zwischen Zustands- und Konfigurationszuordnungen zu unterscheiden, die Zustandszuordnung beim Neuladen wiederzuverwenden und die Konfigurationszuordnung aus dem nichtflüchtigen Speicher neu zu füllen. Die Umstellung der Verarbeitung vom alten Programm auf das neue Programm und die Benachrichtigung aller eBPF-Mapping-Benutzer über die Änderungen kann etwas umständlich sein.
Es gibt zwei gängige Methoden zur Implementierung von Übergängen:
- Atomarer Programmaustausch : Bei dieser Methode wird ein XDP-Programm direkt an eine Netzwerkschnittstelle angehängt und während eines Updates atomar ausgetauscht. Für große, komplexe eBPF-Programme, die mit einer großen Anzahl von User-Space-Programmen und -Maps interagieren, ist dies möglicherweise nicht die beste Lösung.
- Ein libxdp-ähnlicher Ansatz : Das Scheduler-Programm stellt eine Verbindung zur Netzwerkschnittstelle her und verwendet Tail Calls, um die Verarbeitung im nächsten Programm in der Programmzuordnung durchzuführen, in dem die eigentliche Verarbeitung erfolgt. Neben der Verwaltung der Kartennutzung und dem Anheften koordiniert es mehrere Handler und ermöglicht so schnelle Übergänge zwischen ihnen.

Die Netzwerkschnittstellenkarte (NIC) stellt eine Verbindung zum Scheduler, zur Programmzuordnung und zur Zustandszuordnung her, was zur eigentlichen Programmkonfiguration führt.
Der Hot-Reload-Prozess erkennt und behebt schnell Konfigurationsprobleme und stellt bei Bedarf schnell eine frühere stabile Version wieder her. Für komplexe Szenarien wie A/B-Tests kann der Planer Klassifizierungstabellen verwenden, um bestimmten Datenverkehr an neue Versionen des XDP-Programms weiterzuleiten.
abschließend
Durch die eBPF/XDP-Programmierung hat Gcore die Grenzen der Netzwerksicherheit und Leistungsoptimierung erweitert. Unsere Reise zeigt unser Engagement für die Bekämpfung neuer Bedrohungen durch fortschrittliche eBPF/XDP-Funktionen. Während wir unseren Paketverarbeitungskern weiter verbessern, sind wir bestrebt, modernste Lösungen bereitzustellen, die dazu beitragen, die Netzwerke unserer Kunden robust und flexibel zu halten.
Ich habe beschlossen, Open-Source-Hongmeng aufzugeben . Wang Chenglu, der Vater von Open-Source-Hongmeng: Open-Source-Hongmeng ist die einzige Architekturinnovations- Industriesoftwareveranstaltung im Bereich Basissoftware in China – OGG 1.0 wird veröffentlicht, Huawei steuert den gesamten Quellcode bei Google Reader wird vom „Code-Scheißberg“ getötet Ubuntu 24.04 LTS wird offiziell veröffentlicht Vor der offiziellen Veröffentlichung von Fedora Linux 40 Microsoft-Entwickler: Die Leistung von Windows 11 ist „lächerlich schlecht“, Ma Huateng und Zhou Hongyi geben sich die Hand, „beseitigen den Groll“ Namhafte Spielefirmen haben neue Vorschriften erlassen: Hochzeitsgeschenke an Mitarbeiter dürfen 100.000 Yuan nicht überschreiten. Pinduoduo wurde wegen unlauteren Wettbewerbs zu einer Entschädigung von 5 Millionen Yuan verurteiltDieser Artikel wurde zuerst auf Yunyunzhongsheng ( https://yylives.cc/ ) veröffentlicht, jeder ist herzlich willkommen.