
Als verteilte Suchmaschine ist ES in Bezug auf Erweiterungsmöglichkeiten und Suchfunktionen unübertroffen. Da es sich jedoch um ein nahezu echtzeitfähiges Speichersystem handelt, kann es aufgrund seiner Sharding- und Replikationsdesignprinzipien nicht mit OLTP konkurrieren (Online Transaction Processing)-Systeme hinsichtlich Datenlatenz und Konsistenz.
Aus diesem Grund werden die Daten in der Regel von anderen Speichersystemen zur sekundären Filterung und Analyse synchronisiert. Dies stellt einen Schlüsselknoten vor, nämlich die synchrone Schreibmethode von ES-Daten. In diesem Artikel wird die synchrone ES-Methode von MySQL vorgestellt.
Wenn Sie MySQL-Daten in ES schreiben, müssen Sie zunächst daran denken, Binlog zu verwenden und direkt in ES zu schreiben. Wenn Sie jedoch mehr Dimensionen berücksichtigen, werden Sie einige Nachteile dieser Methode feststellen. Daher gibt es einen anderen Weg, nämlich die integrierte Ökologie von
[RocketMQ
+ Flink Consumer + ES Bulk]. Wir werden diese beiden Zugriffsmethoden unter vier Gesichtspunkten bewerten: Synchronisationsverzögerung, Verbrauchseigenschaften, ES-Schreibleistung und Systemkatastrophentoleranz Geben Sie allen Inspiration und wählen Sie die Synchronisierungsmethode, die zu Ihrem Unternehmen passt.
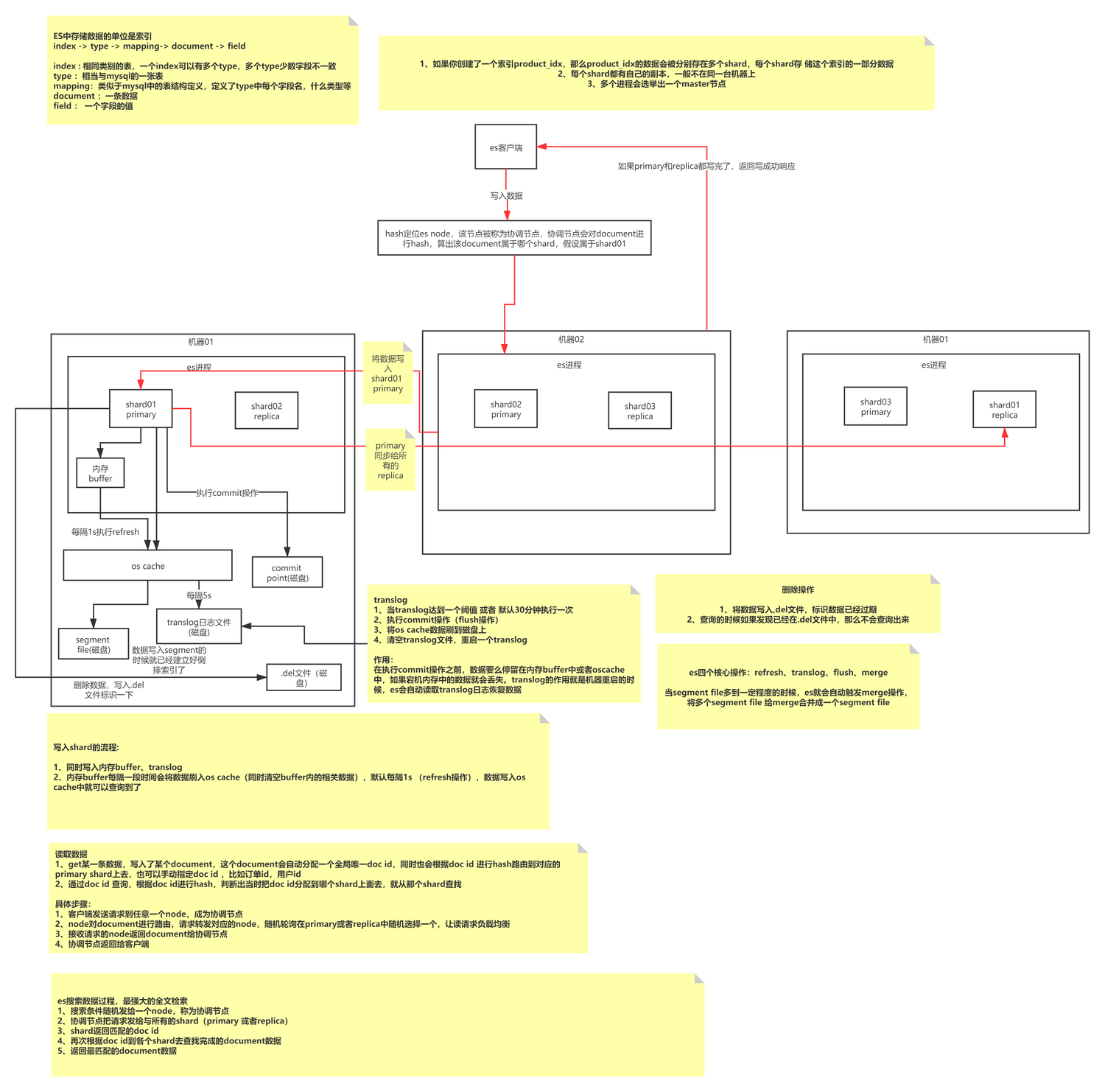
Grundlegende ES-Schreibprinzipien
Beim ES-Schreiben handelt es sich um einen Schreibprozess vom Typ Anhängen, der zunächst Segmente einer bestimmten Größe bildet und dann regelmäßig kleine Datensegmente zu großen Datensegmenten zusammenführt, um die Speicherfragmentierung zu reduzieren und die Abfrageeffizienz zu verbessern. Ein Index besteht aus N Shards und deren Kopien. Seine Indizierungsmethode wird durch Mapping definiert. Jeder Shard ist ein voll funktionsfähiger und vollständiger Lucene-Index Die Verarbeitungseinheit von ES; Segment ist die kleinste Datenverarbeitungseinheit von ES, und jedes Segment ist ein unabhängiger invertierter Index.
Beim ES-Schreiben werden Daten tatsächlich kontinuierlich in dasselbe Segment (Speicher) geschrieben und dann die Aktualisierung ausgelöst, um das Segment im Betriebssystem-Cache zu aktualisieren (Standard: 1 s). Zu diesem Zeitpunkt können die Daten abgefragt werden, und der Betriebssystem-Cache löst das Flush durch das Betriebssystem aus . Vorgänge werden auf der Festplatte gespeichert.
Lässt Sie nachdenken: Wie stellt ES sicher, dass keine Daten verloren gehen? Welche Vor- und Nachteile hat das Schreiben von Anhängen? Wie geht das Schreiben von Anhängen mit Problemen bei der Datenaktualisierung um? Zu welcher Schreibmethode gehört MySQL? Der Schwerpunkt dieses Artikels liegt nicht hier, Sie können den Artikel separat lesen.

ES-Grundkonzepte
ES direktes Schreiben

Der Vorteil der Verwendung von ES-Direktverbindungsschreiben besteht darin, dass der Pfad kurz ist und nur wenige abhängige Komponenten vorhanden sind. Darüber hinaus bietet Dsyncer (heterogenes Speicherkonvertierungssystem) normalerweise einen vollständigen strombegrenzenden Wiederholungsmechanismus, sodass Verbrauchsverzögerung und Verbrauchsdatenintegrität beides sind Garantiert.
Mangel:
-
Es ist nicht einfach, auf die Disaster-Recovery-Bereitstellung in mehreren Computerräumen zuzugreifen. Derzeit werden alle ES-Disaster-Recovery-Computerräume unabhängig voneinander und im unabhängigen Lese- und Schreibmodus bereitgestellt mehrere Computerräume gleichzeitig, und der Disaster-Recovery-Effekt wird nicht erreicht. Binlog-->Dsyncer Normalerweise entspricht eine MySQL-Tabelle einer Konvertierungsaufgabe. Wenn Sie mehrere wiederholte Konvertierungsaufgaben starten, um mehrere Computerräume zu schreiben, erscheint es etwas dumm.
-
Wenn Ihr eigenes Geschäftsszenario das gleichzeitige Schreiben desselben Datensatzes umfasst, die Schreibvorgänge jedoch möglicherweise nicht alle von Binlog stammen, ist es wahrscheinlicher, dass es zu Schreibkonflikten kommt, wenn Sie globales direktes Schreiben in ES in Betracht ziehen, da es keine Garantie für eine geordnete Warteschlange gibt.
Erstellen Sie ein integriertes ES-System über Flink

Flink baut ein ES-integriertes System auf, was bedeutet, dass alle ES-Schreibvorgänge durch Flink-Überwachung der RocketMQ-Echtzeitdatenströme erfolgen, was nicht nur die Ordnungsmäßigkeit der Datenpartitionen gewährleistet, sondern auch die Batch-Schreibfunktionen von ES voll ausnutzt Die Batch-Schreibleistung ist um ein Vielfaches höher als die Einzelschreibleistung. Gleichzeitig kann aufgrund der Fehlertoleranz von Flink selbst die ultimative Datenkonsistenz auch in anormalen Szenarien gewährleistet werden.
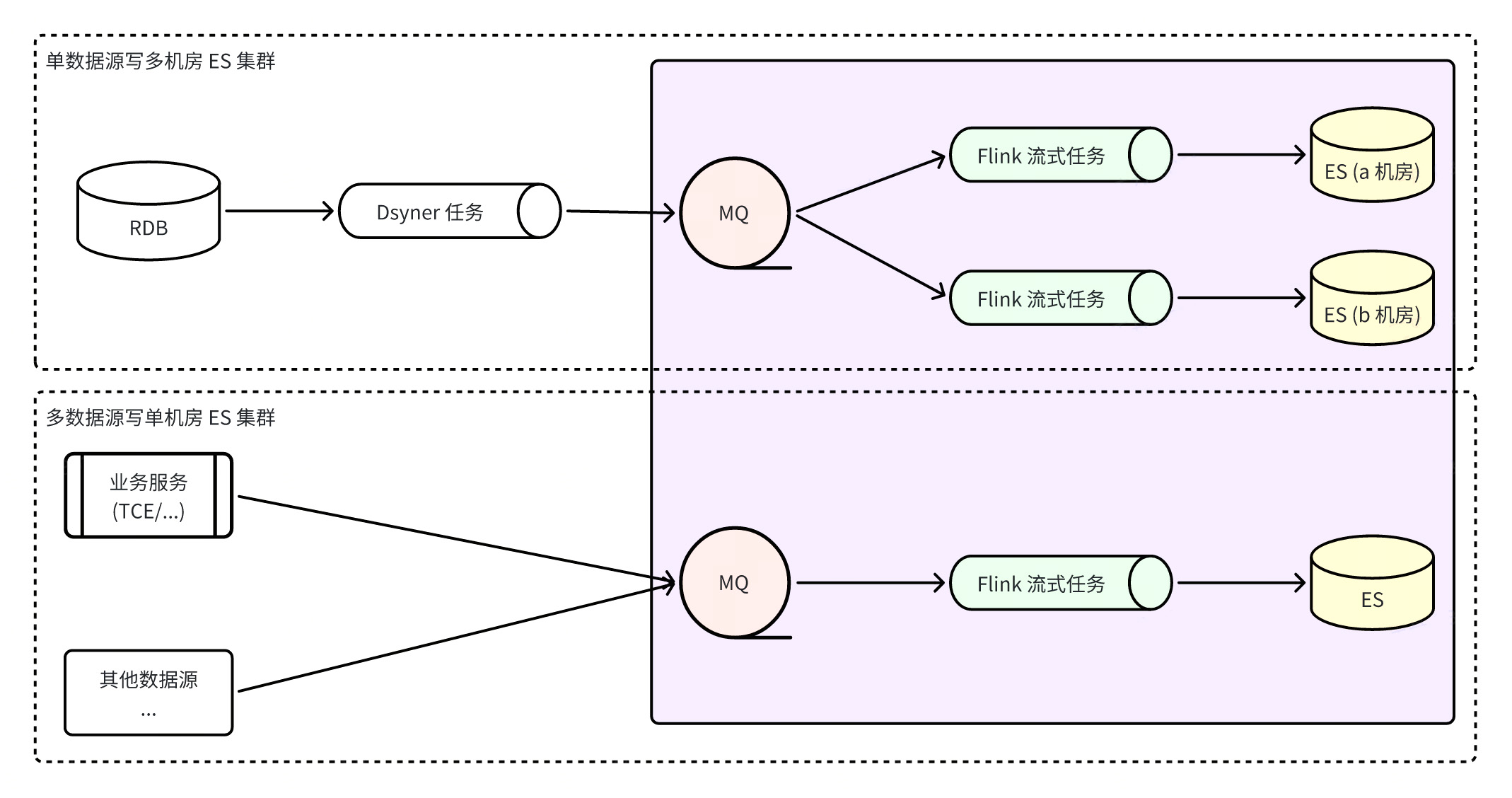
Vorteil
:
-
MQ kann verwendet werden, um schneller auf ES-Cluster mit mehreren Maschinenräumen zuzugreifen, und die Verbraucher in den drei Computerräumen schreiben Daten unabhängig voneinander . Wenn ein einzelner Computerraum ausfällt, solange ein Computerraum verfügbar ist. Der Leseverkehr wird direkt unterbrochen. Ja, der Notfallwiederherstellungsplan ist einfach und klar .
-
Wenn Probleme wie Netzwerk-Jitter dazu führen, dass ES vorübergehend nicht schreiben kann, speichert RocketMQ die Nachricht vorübergehend, ohne das Schreiben anderer Cluster zu beeinträchtigen, und Flink speichert den Verbrauchs-Snapshot und versucht es bis zum Erfolg erneut, wodurch die endgültige Konsistenz der Daten besser gewährleistet wird . Geschlecht ;
-
Durch das Schreiben aus mehreren Datenquellen kann die globale Partitionskonsistenz sichergestellt werden.
Mangel
:
-
Wenn Sie sich auf mehr Komponenten verlassen, erhöht sich die Datensynchronisationsverzögerung der gesamten Verbindung, und die Standardaktualisierungsfrequenz von ES beträgt einmal pro Sekunde. Nach dem Test liegt die Datenverzögerung der Verbindung unter normalen Umständen auf der zweiten Ebene, was nicht völlig inakzeptabel ist.
-
Es ist auf mehr Komponenten angewiesen und stellt höhere Anforderungen an die Stabilität grundlegender Komponenten. RocketMQ-Ausnahmen oder Flink-Aufgabenausnahmen führen zu Synchronisierungsverbindungsproblemen und erhöhen das Risiko von Geschäftsausnahmen.
Ein Problem, das hier beachtet werden muss, ist, dass einige Leute möglicherweise eine Verbindung zu einem ES-Cluster mit mehreren Maschinenräumen in Betracht ziehen. Wie kann sichergestellt werden, dass mehrere Computerräume gleichzeitig erfolgreich sind, und wie kann sichergestellt werden, dass die Daten nach erfolgreichem Schreiben abgefragt werden können? Derzeit können diese beiden Punkte nicht erreicht werden, da mehrere Computerräume unabhängig schreiben, ohne sich gegenseitig zu beeinflussen, und der ES-Cluster ein Cluster mit schwacher Datenkonsistenz ist, sodass keine Garantie dafür besteht, dass erfolgreiche Schreibvorgänge sofort gefunden werden können.
Voraussetzungen für die Erstellung und Ausführung eines ES Flink- Verbraucherprogramms :
-
Flink- Laufumgebung : Zunächst benötigen Sie eine Laufumgebung für Flink-Aufgaben. Normalerweise werden Flink-Aufgaben auf Unternehmensebene als YARN-Job im verteilten System geplant und Ressourcen für die Ausführung zugewiesen, aber gleichzeitig wird Flink ausgeführt kann auch als eigenständiger Prozess oder zum Aufbau eines unabhängigen Cluster-Vorgangs verwendet werden.
-
ES- Nachrichtenformat : Es ist notwendig, sich auf ein ES-Nachrichtenübertragungsformat und eine Serialisierungsmethode zu einigen. Die derzeit gängige Serialisierungsmethode ist das PB-Format oder das JSON-Format . Datenformat Schemadefinition:
|
Feldname
|
Werttyp
|
Erforderlich/Optional
|
beschreiben
|
|
_Index
|
Zeichenfolge
|
erforderlich
|
Der Name oder Alias des zu indizierenden Dokuments
|
|
_Typ
|
Zeichenfolge
|
Erforderlich/Optional
|
Art des Dokuments
|
|
_on_type
|
Zeichenfolge
|
erforderlich
|
Typ des Dokumentschreibvorgangs
, Wertebereich:
Index, Erstellen, Aktualisieren,
Upsert
, Löschen
|
|
_Ausweis
|
Zeichenfolge
|
Optional
|
Wenn keine Dokument-ID
angegeben wird, wird sie beim Schreiben in ES
automatisch generiert
. Wenn jedoch dieselben Daten wiederholt verbraucht und in ES geschrieben werden, werden mehrere Dokumente generiert.
|
|
_Routing
|
Zeichenfolge
|
Optional
|
Wenn nicht angegeben
, wird standardmäßig das _id-Feldwert-Routing verwendet .
|
|
_Ausführung
|
int64
|
Optional
|
Wenn die Dokumentversion
angegeben ist, ist sie größer als 0
und gilt nur für Index-/Löschvorgänge
. Standardmäßig wird der Versionstyp
external_gte verwendet.
|
|
_Quelle
|
Objekt
|
Erforderlich/Optional
|
Der Inhalt des Dokuments
muss nicht angegeben werden, wenn der Vorgangstyp „Löschen“ ist.
|
|
_Skript
|
Objekt
|
Optional
|
Dokumentskript
, gültig, wenn der Vorgangstyp „Update/Upsert“ ist, aber nicht gleichzeitig mit _source vorhanden sein kann
|
syntax = "proto3";
message ESIndexInfo {
string Name = 1; // 文档要写入索引的名称或别名
}
enum ESOPType { // 文档写入操作类型
DELETE = 0; // 删除文档
INDEX = 1; // 创建新文档或更新老文档,只能全量更新 (替换老文档)
UPDATE = 2; // 更新老文档,支持部分更新 (合并老文档)
UPSERT = 3; // 创建新文档或更新老文档,支持部分更新 (合并老文档)
CREATE = 4; // 创建新文档,存在时报错丢弃
}
message ESDocAction {
ESIndexInfo IndexInfo = 1; // 索引信息 (必需)
ESOPType OPType = 2; // 操作类型 (必需)
string ID = 3; // 文档 ID (可选)
string Doc = 4; // 文档内容 (JSON 格式, 删除操作时不需要)
int64 Version = 5; // 文档版本 (可选, 大于 0 且操作为 index/create/delete 有效)
string Routing = 6; // 文档路由 (可选, 非空有效)
string Script = 7; // 文档脚本 (JSON 格式, 操作类型为 update/upsert 有效,但和 Doc 不能同时存在)
}-
Notwendige Konfiguration für Flink- Aufgaben : Überwachte RocketMQ-Themeninformationen, Schreiben von ES-Clusterinformationen;
-
Flink -Ausführungsfunktion : Flink verarbeitet Streaming-Nachrichten auf zwei Arten: Streaming-SQL und benutzerdefinierte Anwendungen. Streaming-SQL unterliegt einigen eigenen Einschränkungen, z. B. der Nichtunterstützung mehrerer Indexnachrichten im selben MQ, während benutzerdefinierte Programmierung flexibler ist Da verschiedene Verwaltungsfunktionen, Protokolle, Fehlercodeverarbeitung usw. hinzugefügt werden, wird diese Methode empfohlen.
-
Flink -Ressourcenkonfiguration : JobManager-Ressourcenkonfiguration, TaskManager-Ressourcenkonfiguration usw.;
-
Benutzerdefinierte Flink- Parameterkonfiguration : Sie können einige dynamische Konfigurationen anpassen, die eng mit der Anwendung verbunden sind, um die dynamische Anpassung der Flink-Verbrauchsfunktionen zu erleichtern, wie zum Beispiel:
|
Parametername
|
verwenden
|
Standardwert
|
|
job.writer.connector.bulk-flush.max-actions
|
Die maximale Anzahl von Dokumenten in einem einzelnen Bulk. Wenn sie diese Anzahl überschreitet, wird ein Flush durchgeführt (d. h. eine Massenanforderung von ES wird ausgeführt).
|
Standard 300
|
|
job.writer.connector.bulk-flush.max-size
|
Die maximale Anzahl von Bytes in einem einzelnen Bulk. Wenn sie den Grenzwert überschreitet, wird ein Flush durchgeführt (d. h. eine Massenanforderung von ES wird ausgeführt).
|
Standard 10 MB
|
|
job.writer.connector.bulk-flush.interval
|
Das maximale Intervall zwischen zwei Bulks, wenn mehr als ein Flush (d. h. eine ES-Bulk-Anfrage ausgeführt wird)
|
Standard 1000 ms
|
|
job.writer.connector.global-rate-limit
|
Globaler Grenzwert für die Schreibgeschwindigkeit
|
Standard -1, keine Geschwindigkeitsbegrenzung
|
|
job.writer.connector.failure-handler
|
Geben Sie einen benutzerdefinierten Fehlerhandler an, z. B. die Behandlung von 4xx-Fehlern, 5xx-Fehlern auf unterschiedliche Weise, 429 immer endlose Wiederholungsversuche usw.;
|
|
|
global_parallelism_num
|
Globale Parallelität der Flink-Aufgabe
|
rmq ist queue/4, bmq/kafka ist partition/3
|
|
max_parallelism_num
|
Maximale Parallelität von Flink-Aufgaben
|
Die Anzahl der Warteschlangen/Partitionen von mq
|
|
checkpoint_interval
|
Das Intervall zum Erstellen eines Checkpoints, Einheit ms (5min=300000)
|
Standardmäßig 15 Min
|
|
checkpoint_timeout
|
Zeitüberschreitung beim Erstellen eines Checkpoints, Einheit ms (5 Min. = 300.000)
|
Standardmäßig 10 Min
|
|
rebalance_enable
|
Aktivieren Sie den Verbrauch außerhalb der Reihenfolge
|
Standardmäßig falsch
|
Vergleichsvorschläge
|
Schreibmethode
|
Synchronisierungsverzögerung
|
Schreiben Sie Eigenschaften
|
ES-Schreibleistung
|
Verbraucher
|
Katastrophentoleranz
|
|
direkte Verbindung
|
Weniger abhängige Komponenten und geringe Latenz
|
Binlog-Einzelschlüssel bestellt
|
Massenschreiben
|
FaaS
|
Arm
|
|
RocketMQ+Flink+ES
|
Es gibt viele abhängige Komponenten und die Verzögerung ist hoch/zweit
|
Globale Einzelschlüsselbestellung
|
Massenschreiben
|
Beträchtlich
|
Gut
|
Wenn das Unternehmen nach der obigen Einführung Verzögerungen auf zweiter Ebene akzeptieren kann, kann die Verwendung von RocketMQ + Flink eine bessere Ordnungs- und Notfallwiederherstellungsfunktion erreichen. Flink ist FaaS auch in Bezug auf die Verarbeitungsfunktionen für Streaming-Aufgaben weit überlegen, aber direkt Die Verbindungsmethode hat offensichtlich einfachere Verbindungen, leichtere Architektur und geringere Systemintegrations- und Wartungskosten. Daher ist es immer noch notwendig, die am besten geeignete Lösung basierend auf den Geschäftsmerkmalen auszuwählen.
Quellteam|ByteDance E-Commerce-Geschäftsplattform
{{o.name}}
{{m.name}}