
Dieses Zitat von Charity Majors fasst den aktuellen Stand der Beobachtbarkeit in der Technologiebranche wahrscheinlich am besten zusammen – völliges, massives Chaos. Alle sind verwirrt. Was ist Spur? Was ist Spanne? Ist eine Protokollzeile eine Spanne? Wenn ich Protokolle habe, muss ich dann trotzdem nachverfolgen? Wenn ich gute Messwerte habe, warum benötige ich dann einen Trace? Die Liste geht weiter und weiter. Charity hat zusammen mit anderen großartigen Köpfen in den beobachtbaren Systemen von Honeycomb hart daran gearbeitet, diese Probleme zu lösen. Aufgrund meiner eigenen Erfahrung ist es jedoch immer noch schwer zu erklären, was Charity meint, wenn sie sagt: „Protokolle sind Müll“, ganz zu schweigen davon, dass Protokollierung und Rückverfolgung im Wesentlichen dasselbe sind. Warum sind alle so verwirrt?
Bei einem leichten Risiko gebe ich Open Telemetry die Schuld. Ja, es ist das Kraftpaket des modernen Observability-Stacks, aber ich gebe ihm die Schuld für das Durcheinander. Das liegt nicht daran, dass es eine schlechte Lösung wäre – es ist brillant! Allerdings lässt die Einführung und Erläuterung der Konzepte und Funktionen der Open Telemetry die Beobachtbarkeit schwierig und kompliziert erscheinen.
Erstens unterscheidet Open Telemetry von Anfang an klar zwischen Traces, Metriken und Protokollen:
OpenTelemetry ist eine Sammlung von APIs, SDKs und Tools. Verwenden Sie es zum Instrumentieren, Generieren, Sammeln und Exportieren von Telemetriedaten (Metriken, Protokolle und Traces), um Sie bei der Analyse der Leistung und Verhaltenserfassung Ihrer Software zu unterstützen.
Erklären Sie dann jede dieser drei Fragen ausführlicher.
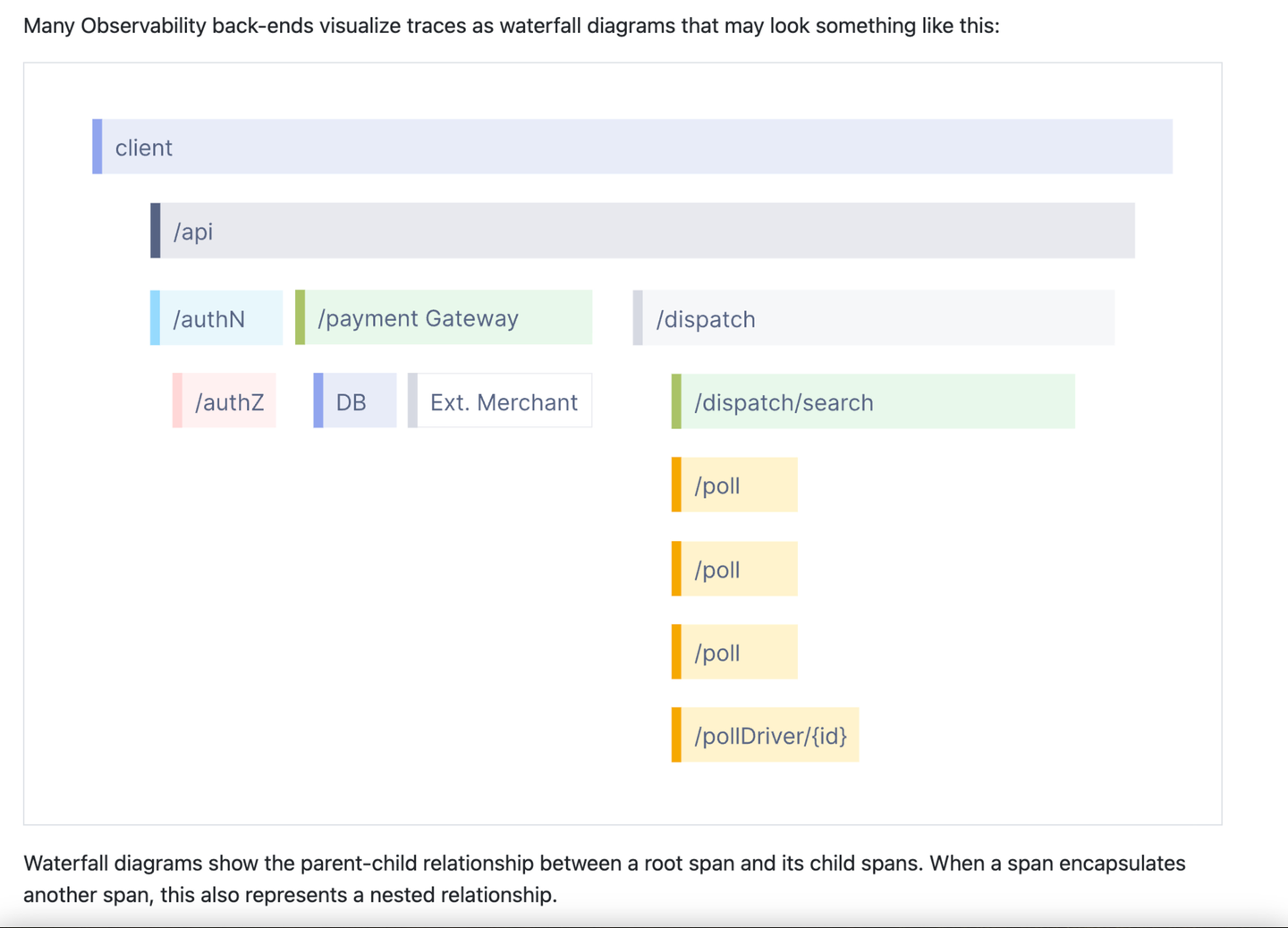
Dies ist ein teilweiser Screenshot der Trace-Einführung auf der OpenTelemetry-Website. Nach meiner Erfahrung im Gespräch mit OpenTelemetry-Mitarbeitern ist diese Präsentation wirklich zu einem der Hauptbilder im Zusammenhang mit der Beobachtbarkeit geworden. Für manche ist das Beobachtbarkeit. Es unterscheidet Trace auch von allem anderen. Das ist offensichtlich kein Protokoll, oder? Das sieht auch nicht nach einem Indikator aus, oder? Das ist etwas Besonderes, vielleicht ein bisschen Großartig und erfordert Hingabe zum Lernen. Meiner Erfahrung nach denken Menschen, sobald sie Spuren verstehen, nur noch im Kontext dieses Bildes und verwandter Begriffe wie „Span“, „Root Span“, „Nested Span“ usw. an sie. Die OpenTelemetry-Website verfügt über eine Glossarseite mit über 60 Begriffen ! Es ist alles extrem kompliziert!
Aber was noch wichtiger ist: Stellt dieser Fokus auf „Protokolle, Metriken und Link-Traces“ die wahre Kraft der Beobachtbarkeit dar? Sicher, es deckt einige Szenarien ab, aber wenn es um große verteilte Systeme geht, ist es wichtiger, tief in die Daten einzudringen – sie „in Scheiben zu schneiden“, verschiedene Ansichten zu erstellen und zu analysieren, Korrelationen herzustellen. Sexuelle Analyse, Auf der Suche nach Anomalien ... und es gibt Systeme, die all diese Funktionen bieten.
Scuba: Observability Paradise
Als ich bei Meta arbeitete, war mir nicht bewusst, dass ich das Glück hatte, mit dem besten Observability-System zu arbeiten, das jemals geschaffen wurde. Dieses System heißt Scuba und ist das, was die Leute am meisten vermissen, nachdem sie die Meta Corporation verlassen haben.
Die Grundidee des Tauchens ist so einfach, dass man nicht seitenlang Fachbegriffe lesen muss, um sie zu verstehen. Es verwendet Wide Events. Ein generalisiertes Ereignis ist einfach eine Sammlung von Feldern mit Namen und Werten, genau wie ein JSON-Dokument. Wenn Sie einige Informationen protokollieren müssen – sei es der aktuelle Status des Systems oder verursacht durch einen API-Aufruf, einen Hintergrundjob oder ein anderes Ereignis – schreiben Sie einfach einige allgemeine Ereignisse in Scuba. Wenn ein System beispielsweise Werbung ausliefert, möchte es natürlich Ad Impressions erfassen – also die Tatsache, dass eine Anzeige von einem Nutzer gesehen wurde. Das entsprechende verallgemeinerte Ereignis könnte so aussehen:
{
"Timestamp": "1707951423",
"AdId": "542508c92f6f47c2916691d6e8551279”,
"UserCountry": "US",
"Placement": "mobile_feed",
"CampaingType": "direct_ads",
"UserOS": "Android",
"OSVersion": "14",
"AppVersion": "798de3c28b074df9a24a479ce98302b6",
"...": ""
}Solche Ereignisse werden als generalisierte Ereignisse bezeichnet, da alle erdenklichen Informationen in ihnen gespeichert werden sollen. Alles, was im Kontext dieser bestimmten Daten relevant sein könnte – stellen Sie es einfach zur Verfügung und es könnte später nützlich sein. Dieser Ansatz legt den Grundstein für den Umgang mit unbekannten Unbekannten – Dingen, an die man jetzt noch nicht denken kann und die bei einer Unfalluntersuchung ans Licht kommen könnten.
Der Umgang mit unbekannten unbekannten Situationen lässt sich anhand eines Beispiels besser veranschaulichen. Scuba verfügt über eine intuitive und benutzerfreundliche Oberfläche, die das Erkunden und Bedienen erleichtert. Es gibt einen Abschnitt zum Auswählen der anzuzeigenden Metriken und Abschnitte zum Filtern und Gruppieren – Scuba zeichnet ein schönes Zeitreihendiagramm auf. Ein erster Blick auf den Datensatz zu den Anzeigenimpressionen zeigt lediglich ein Diagramm mit der Anzahl der Impressionen:
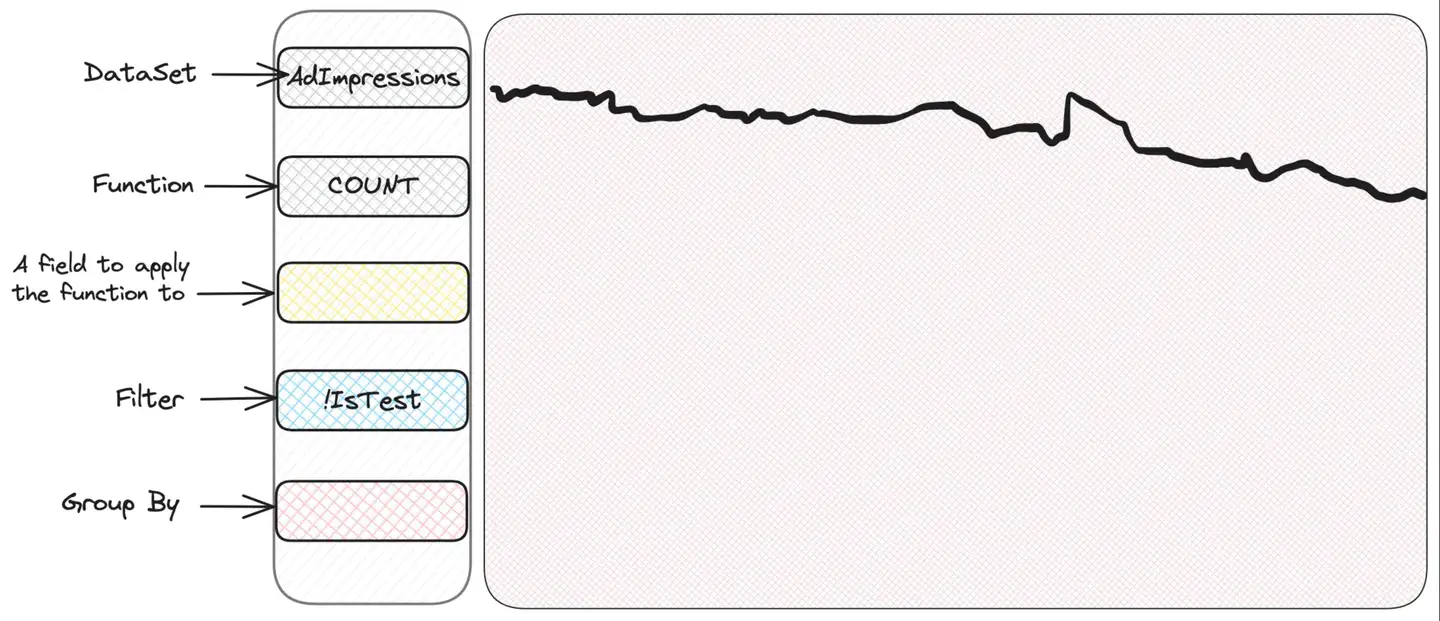
Würden wir in SQL ausdrücken, was hier genau ausgewählt wird, dann sähe das so aus:
SELECT COUNT(*) FROM AdImpressions
WHERE IsTest = FalseDies ist nicht ganz der Fall. Scuba bietet auch das Konzept der einheimischen Probenahme. Wenn ein Ereignis in Scuba geschrieben wird, muss auch ein Feld namens geschrieben werden, das die Abtastrate dieses bestimmten Ereignisses darstellt. Scuba verwendet diese Informationen, um die auf der Karte angezeigten Ergebnisse korrekt zu „vergrößern“, sodass Sie diese Vergrößerung nicht im Kopf vornehmen müssen. Dies ist ein großartiges Konzept, da es ein dynamisches Sampling ermöglicht. So kann beispielsweise eine bestimmte Art von Präsentation häufiger abgetastet werden als eine andere Art von Präsentation, während die „echten“ Werte in der Benutzeroberfläche erhalten bleiben. Die eigentliche Abfrage darunter lautet also: samplingRate
SELECT SUM(samplingRate) FROM AdImpressions
WHERE IsTest = False Beachten Sie, dass das gesamte „Heranzoomen“ transparent von der Benutzeroberfläche durchgeführt wird und der Benutzer während der Abfrage nicht darüber nachdenken muss. Nehmen wir also an, dass eine Warnung auftritt und unser wertvolles Anzeigenimpressionsdiagramm seltsam aussieht:
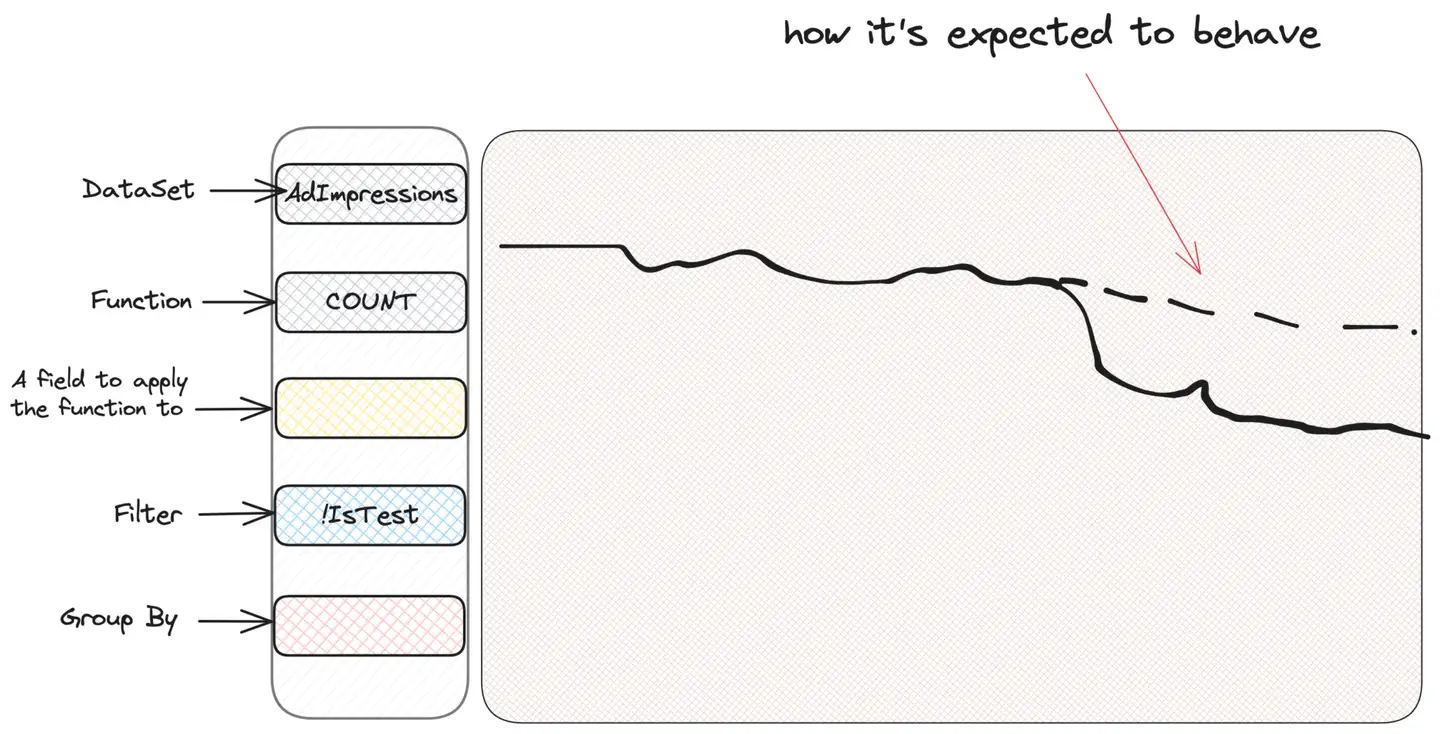
Der erste Instinkt eines jeden, der Scuba für Nachforschungen nutzt, ist das „Schneiden und Würfeln“, d. h. das Filtern oder Gruppieren nach Kriterien, um zu sehen, ob er Informationen erhalten kann. Wir wissen nicht, wonach wir suchen, aber wir glauben, dass wir es finden werden. Daher gruppieren wir nach Impressionstyp, Nutzerland oder Anzeigenstandort, bis wir etwas Verdächtiges finden. Nehmen wir eine Gruppierung nach Kampagnentyp (CampaignType) an:
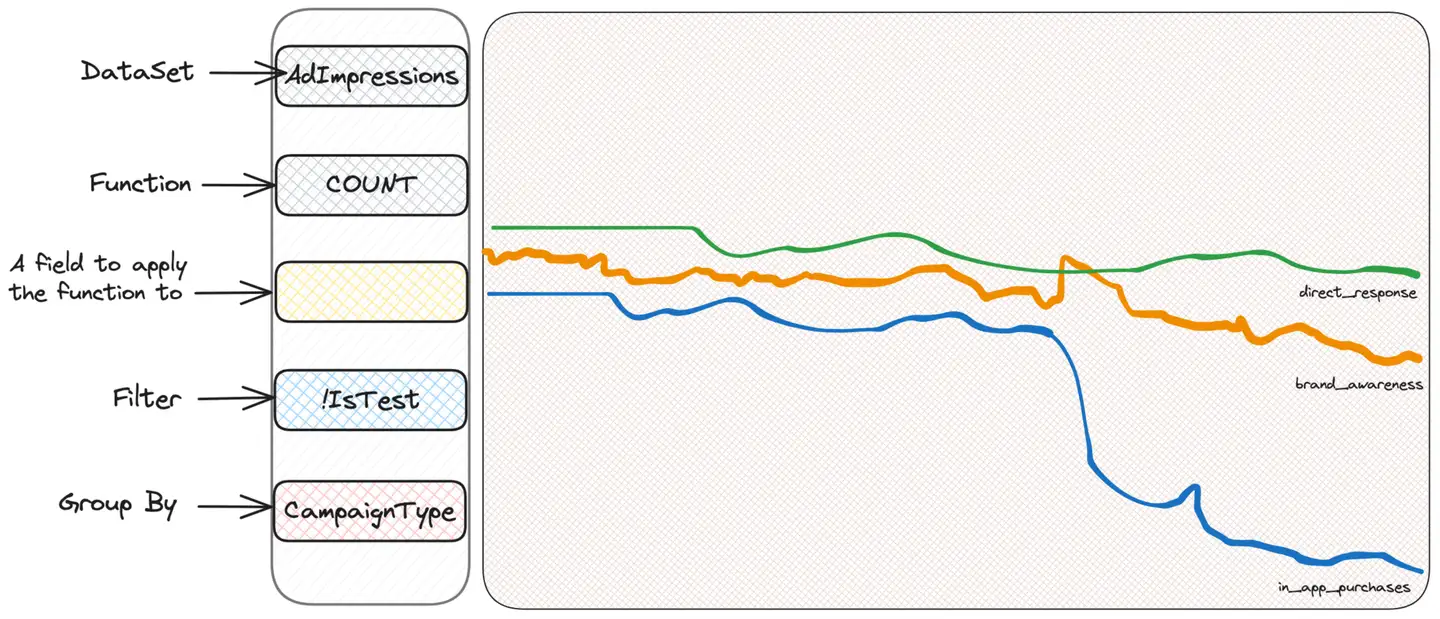
Wir haben festgestellt, dass sich ein Kampagnentyp namens in_app_purchases (bitte beachten Sie, dass ich ihn erfunden habe) von den anderen Typen zu unterscheiden scheint. Wir wissen nicht wirklich, was es bedeutet – und wir müssen es auch nicht wissen! - Wir müssen einfach weiter graben. Okay, jetzt können wir nur diese Kampagnen filtern und mit der Gruppierung nach anderen Kriterien fortfahren, die uns einfallen. Beispielsweise ist das Betriebssystem des Benutzers sinnvoll.
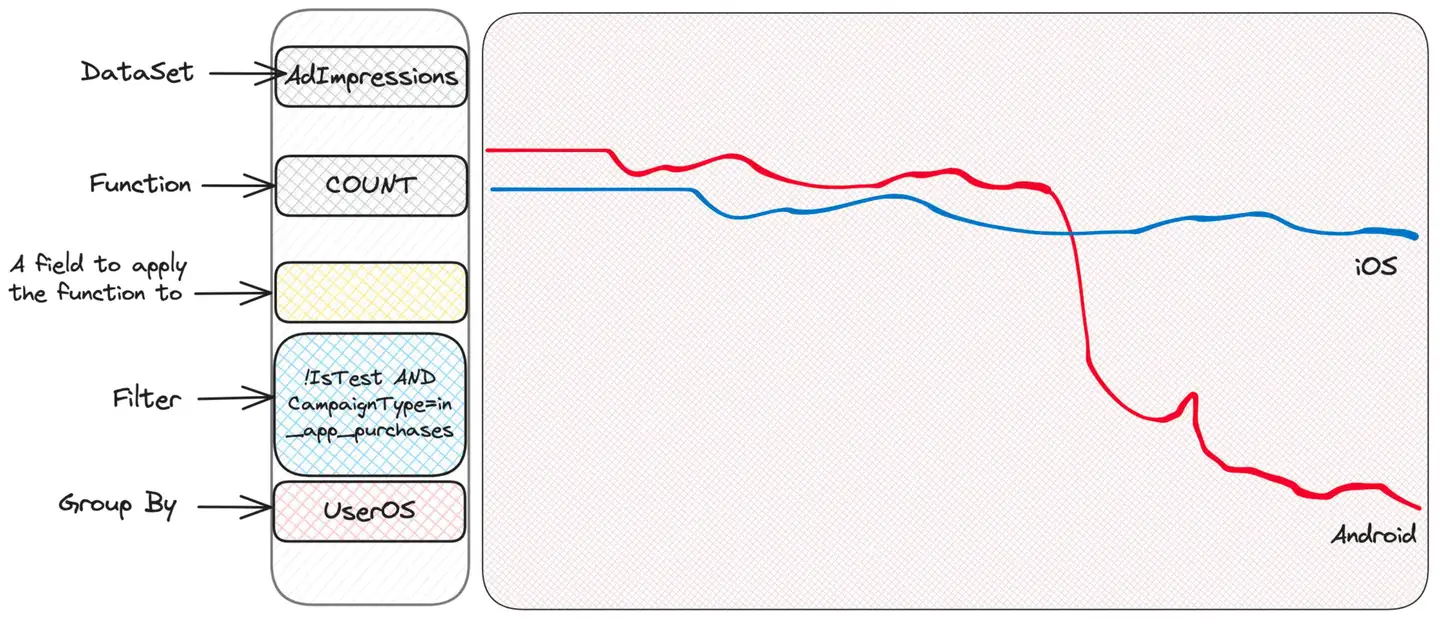
Nun, es scheint ein Problem mit Android zu geben. iOS ist in Ordnung, was darauf hindeutet, dass das Problem möglicherweise auf der Clientseite liegt – vielleicht eine fehlerhafte Version der App?
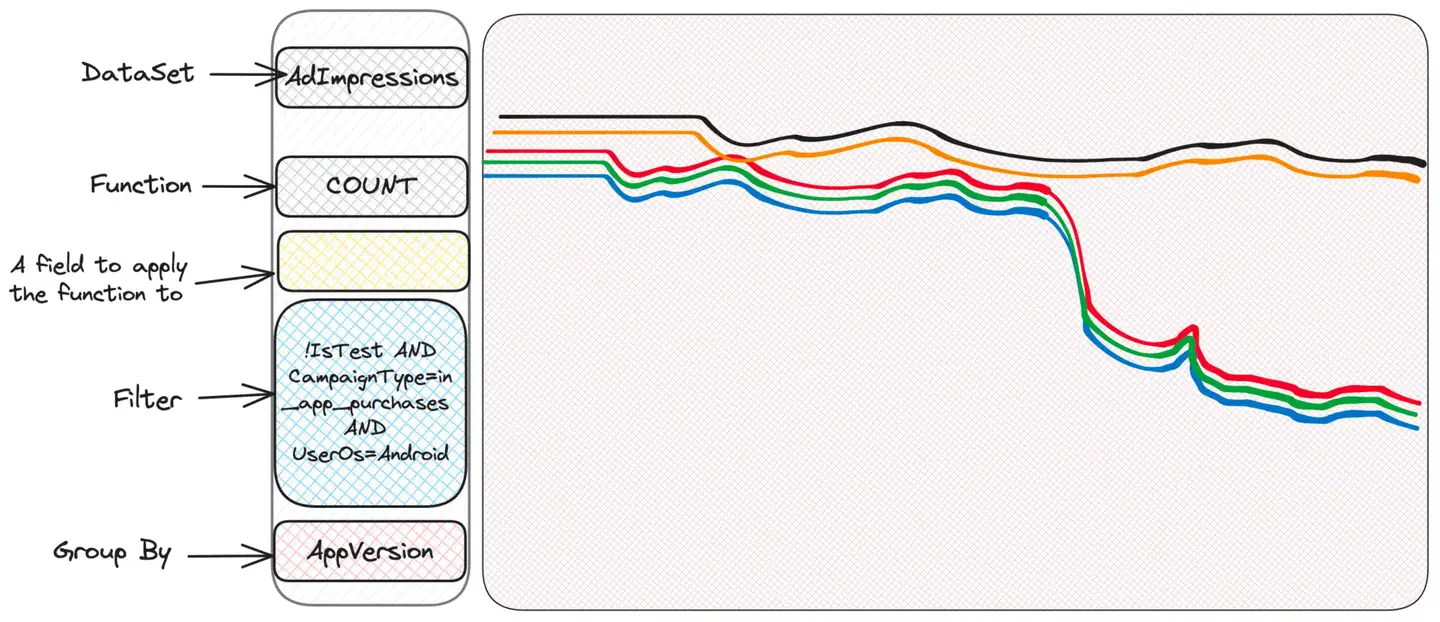
Fremdheit. Manche Menschen haben Probleme, andere nicht. Vielleicht die Betriebssystemversion überprüfen?
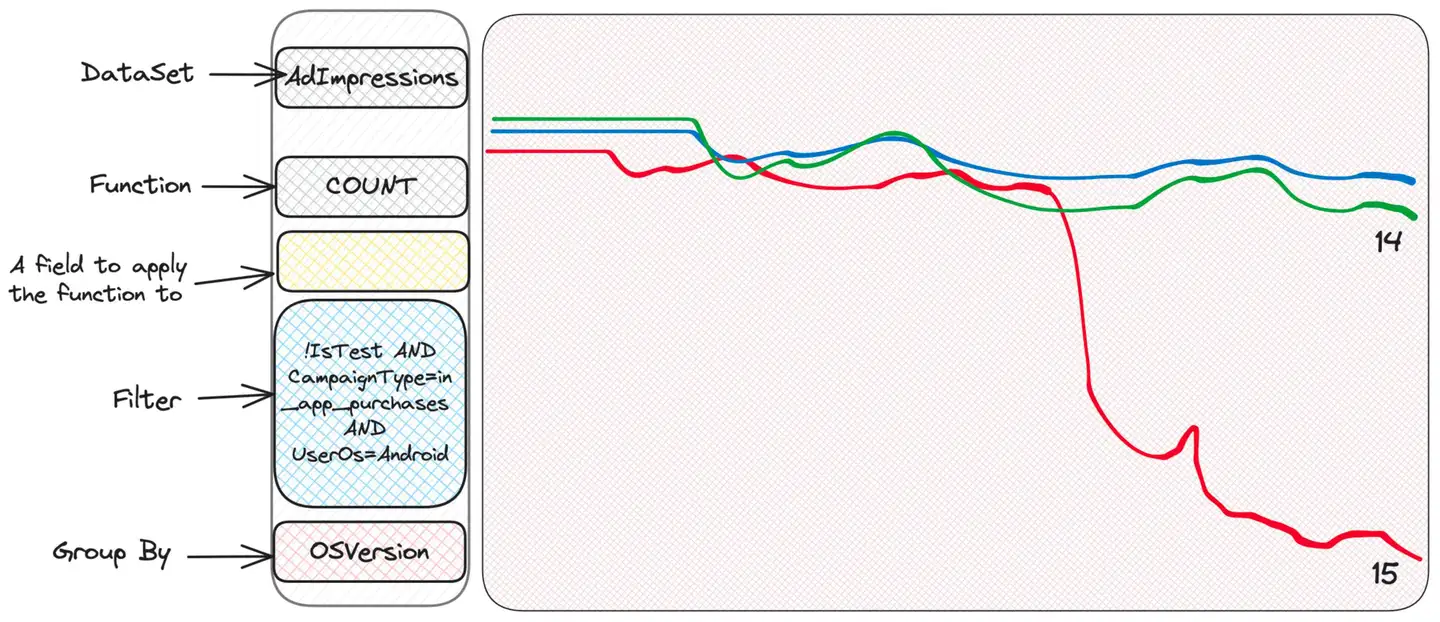
Ha! Dies ist die neueste Betriebssystemversion und es sieht so aus, als ob einige App-Versionen für diese Art von Kampagne auf dieser Betriebssystemversion nicht gut funktionieren. Anhand dieser Informationen kann das engagierte Team nun tiefer in die Materie eintauchen.
was ist passiert? Ohne Kenntnis des Systems haben wir das Problem eingegrenzt und das Team identifiziert, das für die weitere Untersuchung verantwortlich ist. Hätten wir im Voraus wissen können, dass diese seltsame Kombination aus Betriebssystem, Betriebssystemversion, Kampagnentyp und App-Version einige Probleme verursachen könnte, und hätten wir die Messwerte parat haben können? Natürlich ist es unmöglich. Dies ist ein Beispiel für den Umgang mit unbekannten Unbekannten. Wir speichern lediglich alle relevanten Kontextinformationen in verallgemeinerten Ereignissen und verwenden sie bei Bedarf. Scuba erleichtert die Erkundung, da es schnell ist und über eine sehr schöne und benutzerfreundliche Benutzeroberfläche verfügt. Beachten Sie auch, dass wir nie etwas über Kardinalität erwähnt haben. Weil es keine Rolle spielt – jedes Feld kann jede beliebige Kardinalität haben. Scuba arbeitet mit Rohereignissen und führt keine Vorabaggregation durch, sodass Kardinalität kein Problem darstellt.
Manchmal wird dem Schnittstellen-/Visualisierungsaspekt nicht genügend Aufmerksamkeit geschenkt, und das Überwachungssystem stellt eine Abfragesprache bereit – möglicherweise proprietär (eine besonders schlechte Erfahrung) oder SQL (etwas besser, aber immer noch nicht gut). Eine solche Schnittstelle würde die Durchführung einer ähnlichen Umfrage nahezu unmöglich machen. Ein wichtiger Aspekt von Scuba ist, dass alle Felder (Funktionen, Filter, Gruppierungen usw.) erkundebar sind. Allerdings gibt es eine einfache Möglichkeit, die auswählbaren Wertetypen anzuzeigen. Wenn die für ein bestimmtes Datenfeld zuständige Person zusätzliche Anstrengungen unternimmt, um die Daten, für die sie verantwortlich ist, zu verbessern, geht sie über das bloße Sammeln der Daten hinaus. Sie stellt sogar eine detaillierte Beschreibung für das jeweilige Feld bereit, einschließlich zugehöriger Links. Dies ist sehr wichtig. Ich habe die Fehlerbehebung viele Male erfolgreich durchgeführt, ohne das System als Ganzes oder die in diesem Datensatz verfügbaren Daten vollständig zu verstehen. Und während dieser Fehlerbehebungsprozesse habe ich allein durch die Interaktion mit Scuba viel über das System gelernt! Das ist großartig. Das ist der Himmel der Beobachtbarkeit.
Der Schmerz nach dem Verlassen von Meta
Stellen Sie sich nun meine Verwirrung und meinen Unglauben vor, als ich Meta verließ und etwas über den Zustand des externen Observability-Systems erfuhr.

Protokoll? Schiene? Index? Was ist das genau? Kennt jemand allgemeine Ereignisse? Kann ich nicht das Glossar mit 60 Begriffen lernen und einfach... Dinge erkunden?
Ich habe einige Zeit damit verbracht, das Scuba-basierte mentale Modell dem mentalen Modell der offenen Telemetrie zuzuordnen. Mir wurde klar, dass es sich bei Open Telemetry's Span eigentlich um ein verallgemeinertes Ereignis handelt. Eigentlich bin ich mir immer noch nicht ganz sicher, ob ich es richtig verstehe:

Wenn wir das Beispiel einer Werbeanzeige nehmen, handelt es sich bei dieser Anzeige nicht um einen eigentlichen Vorgang, sondern nur um einige Fakten, die wir aufzeichnen möchten ... Fairerweise muss man sagen, dass das Konzept von Ereignissen in Open Telemetry existiert:

Aber wenn wir dem Link folgen und tiefer graben, stellen wir erneut fest, dass es sich bei dem Ereignis tatsächlich um einen der Traces, Metriken oder Protokolle handelt

Aber auf jeden Fall ist Span das Konzept, das einem verallgemeinerten Ereignis am nächsten kommt. Das Problem ist, dass es schwierig ist, das von Open Telemetry vorgeschlagene mentale Modell zu verteidigen, wenn man daran gewöhnt ist. Das ist wirklich frustrierend, weil Traces, Metriken und Protokolle eigentlich nur Sonderfälle verallgemeinerter Ereignisse sind:
- Traces und Spans (Spans): Es handelt sich lediglich um verallgemeinerte Ereignisse mit den Feldern SpanId, TraceId und ParentSpanId. So können wir alle Spans mit einer bestimmten TraceId filtern, sie topologisch basierend auf der Beziehung SpanId → ParentSpanId sortieren und die von allen bevorzugte verteilte Trace-Ansicht zeichnen.
- Protokolle: Um ehrlich zu sein, bin ich wirklich verwirrt darüber, was Open Telemetry als Protokolle bezeichnet. Es sieht so aus, als ob es viele Dinge enthält, darunter die strukturierte Protokollierung, bei der es sich im Grunde um umfassende Ereignisse handelt. Sehr gut! Das Problem besteht jedoch darin, dass „Protokoll“ ein ziemlich genau definiertes Konzept ist und die Leute normalerweise meinen, was diese Aufrufe erzeugen. Was auch immer das bedeutet, Protokolle können problemlos großen Ereignissen zugeordnet werden. Im einfachsten Fall nehmen wir einfach die Protokollnachricht, fügen sie in das Feld „log_message“ ein, fügen eine Reihe von Metadaten hinzu und sind zufrieden. In einem komplexeren Fall könnten wir versuchen, automatisch eine Vorlage aus der Protokollnachricht zu extrahieren, indem wir das Token entfernen, das wie eine ID aussieht, und den Hash dieser Vorlage abrufen. Dadurch können wir schnell die häufigsten Fehler ermitteln, indem wir beispielsweise nach diesem Hash gruppieren. Meta hat ein solches System und es ist ziemlich cool.
logger.info(…) - Metriken: Auch Metriken können einfach abgebildet werden. Wir müssen lediglich innerhalb eines bestimmten Intervalls ein umfassendes Ereignis ausgeben, das den Systemstatus enthält (z. B. CPU-Systemindikatoren, verschiedene Zähler usw.). Übrigens macht Prometheus genau das durch die Scraping-Methode – indem es gelegentlich einen Snapshot des Systems erstellt. Im Gegensatz zu Prometheus müssen wir uns bei Verwendung des Wide-Event-Ansatzes jedoch nicht um Kardinalitätsprobleme kümmern.
Aber Wide Events kann viel mehr bieten als diese „drei Säulen“ (Traces, Logs, Metrics). Die oben erwähnte Debugging-Sitzung ist bereits (zumindest nicht natürlich) ein Fall, der von Traces, Logs und Metrics abgedeckt wird. Es kann auch andere Anwendungsfälle geben – beispielsweise können kontinuierliche Profilierungsdaten einfach als Wide Event dargestellt und abgefragt werden, um ein Flame-Diagramm zu erstellen. Dafür ist kein separates System erforderlich – ein einziges System, das umfangreiche Ereignisse verarbeitet, kann alles erledigen. Stellen Sie sich die Möglichkeiten der Kreuzkorrelation und Ursachenanalyse vor, wenn alles zusammen an einem Ort gespeichert wird. Besonders im Zeitalter des Aufkommens von Tools der künstlichen Intelligenz, die hervorragend dazu geeignet sind, Zusammenhänge in Daten zu entdecken.
Also dann?
Ich weiß nicht ... Ich wollte nur meine Enttäuschung und Frustration darüber zum Ausdruck bringen, dass die Beobachtbarkeit so verwirrend und verwirrend ist und sich auf die „drei Säulen“ konzentriert …
Ich hoffe nur, dass Observability-Anbieter dem Chaos entgegentreten und eine einfache und natürliche Möglichkeit bieten, mit dem System zu interagieren. Honeycomb scheint dies zu tun, und einige andere Systeme wie Axiom tun dies ebenfalls. Es ist großartig! Hoffentlich werden andere Anbieter diesem Beispiel folgen.
beigefügt
Dieser Artikel ist eine Übersetzung, Originaltext: https://isburmistrov.substack.com/p/all-you-need-is-wide-events-not-metrics
Bitte erlauben Sie mir, am Ende des Artikels eine kleine Anzeige einzufügen. Ich gründe seit zwei Jahren ein Unternehmen und unser Unternehmen betreibt auch Observability, was der Idee dieses Artikels etwas ähnelt. Wenn Sie Bedarf in diesem Bereich haben, können Sie uns gerne für den Produkt- und technischen Austausch kontaktieren.
Über den Kuaimao-Nebel
Kuaimao Nebula ist ein Cloud-natives Unternehmen für intelligente Betriebs- und Wartungstechnologie. Es besteht aus dem Kernentwicklungsteam des bekannten Open-Source-Projekts „Nightingale“. Das Gründungsteam besteht aus Internetunternehmen wie Alibaba, Baidu und Didi. Nightingale ist ein cloudnatives Open-Source-Überwachungstool. Es ist das erste Open-Source-Projekt, das von der Computer Society of China gespendet und gehostet wird. Es hat mehr als 8.000 Sterne auf GitHub, hat mehr als 100 iterative Versionen veröffentlicht und verfügt über Hunderte von Communitys Mitwirkende Es ist die führende Open-Source-Observability-Lösung in China.
Die von Kuaimao Nebula mit der Open-Source-Lösung Nightingale als Kernstück entwickelte „Flashcat-Plattform“ ist die Produktimplementierung der Observability-Praktiken führender inländischer Internetunternehmen. Sie hat sich zum Ziel gesetzt, die Observability-Technologie besser für Unternehmen zu nutzen und die Servicestabilität sicherzustellen. Die Flashcat-Plattform verfügt über die folgenden Funktionen:
- Einheitliche Sammlung: Durch die Übernahme des Plug-In-Konzepts können Hunderte von integrierten Sammlungs-Plug-Ins integriert werden. Server, Netzwerkgeräte, Middleware, Datenbanken, Anwendungen und Unternehmen können sofort überwacht und verwendet werden.
- Einheitlicher Alarm: Unterstützt das Andocken von Dutzenden von Datenquellen, sammelt Alarmereignisse von verschiedenen Überwachungssystemen und führt eine einheitliche Alarmkonvergenz, Rauschunterdrückung, Planung, Inanspruchnahme, Aktualisierung und Zusammenarbeit durch, wodurch die Effizienz der Alarmverarbeitung erheblich verbessert wird.
- Einheitliche Beobachtung: Integrieren Sie verschiedene Observability-Daten wie Metriken, Protokolle, Traces, Ereignisse und Profiling sowie voreingestellte Best Practices der Branche. Es bietet nicht nur ein Cockpit aus globaler Geschäftsperspektive und einer technischen Perspektive, sondern auch Drilldown-Fehler. Positionierungsfähigkeit, wodurch die Fehlererkennungs- und Positionierungszeit effektiv verkürzt wird.
Der Kuaimao-Nebel macht Beobachtbarkeitsdaten wertvoller! https://flashcat.cloud/