
Hintergrundeinführung
In einem neueren Geschäftssystem befand sich die Slave-Datenbank in einem verzögerten Zustand und konnte nicht mit der Master-Datenbank mithalten, was zu größeren Geschäftsrisiken führte. Aus Ressourcensicht sind die CPU-, E/A- und Netzwerkauslastung der Slave-Bibliothek gering und es gibt keine Situation, in der die Wiedergabe durch übermäßigen Serverdruck verlangsamt wird. Auf der Slave-Bibliothek wird die parallele Wiedergabe aktiviert Die Bibliothek zeigt an, dass keine Wiedergabethreads vorhanden sind. Beim Parsen der Relay-Log-Protokolldatei wird festgestellt, dass keine große Transaktionswiedergabe erfolgt.
Prozessanalyse
Bestätigung des Phänomens
Ich habe von meinen Betriebs- und Wartungskollegen die Rückmeldung erhalten, dass es bei einem Satz Slave-Bibliotheken zu erheblichen Verzögerungen kam. Ich habe show slave statusScreenshots mit Informationen zur Verzögerung bereitgestellt.
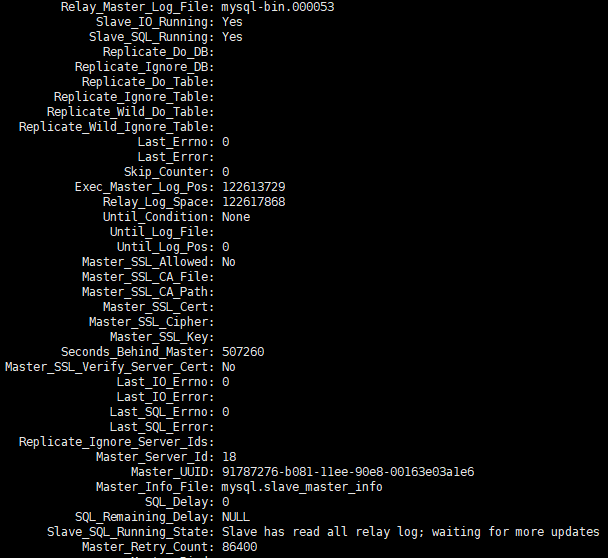
Nachdem ich die Änderungen eine Weile beobachtet hatte show slave status, stellte ich fest, dass sich die POS-Punktinformationen ständig änderten, Seconds_Behind_master sich ebenfalls ständig änderte und der Gesamttrend weiter zunahm.
Ressourcennutzung
Nachdem wir die Ressourcennutzung des Servers beobachtet haben, können wir feststellen, dass die Nutzung sehr gering ist.

Wenn Sie den Slave-Prozess beobachten, können Sie im Grunde nur einen Thread sehen, der die Arbeit wiedergibt.
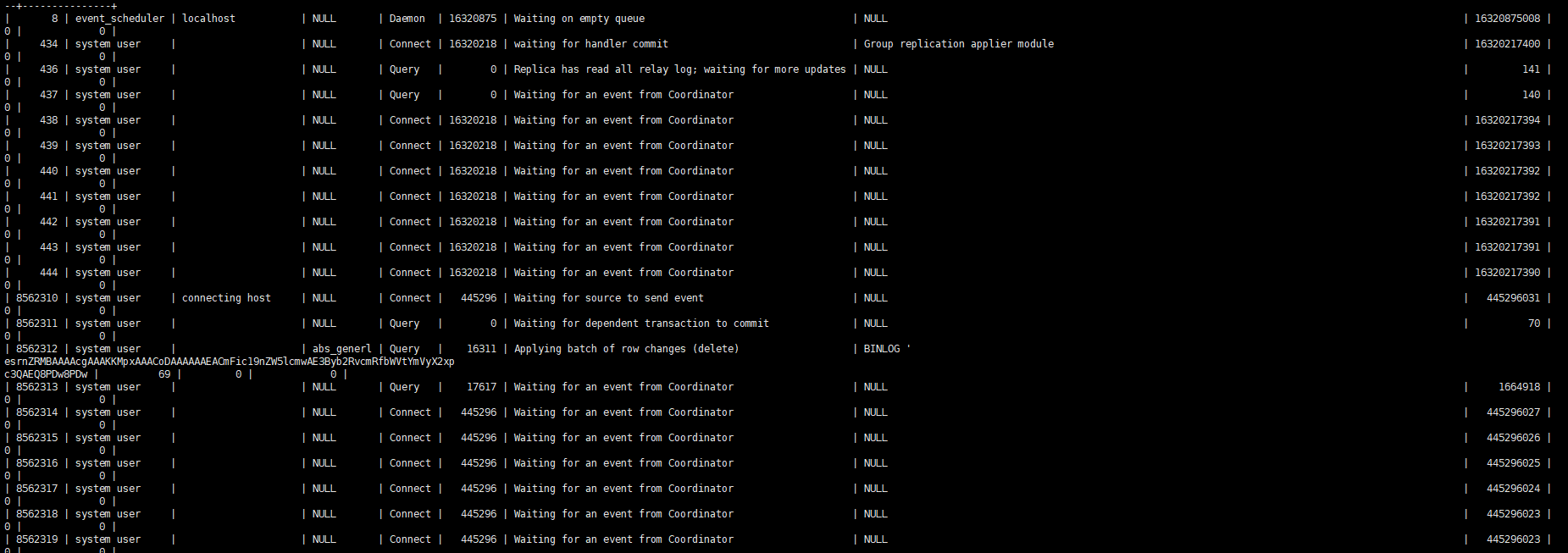
Beschreibung der Parameter für die parallele Wiedergabe
In der Hauptbibliothek eingestelltbinlog_transaction_dependency_tracking=WRITESET
In der Sklavenbibliothek sind slave_parallel_type=LOGICAL_CLOCKdie undslave_parallel_workers=64
Fehlerprotokollvergleich
Rufen Sie zur Analyse das parallele Wiedergabeprotokoll aus dem Fehlerprotokoll ab
$ grep 010559 100werror3306.log | tail -n 3
2024-01-31T14:07:50.172007+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3318582273; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348754579743300 waited (count) when Workers occupied = 34529247 waited when Workers occupied = 76847369713200
2024-01-31T14:09:50.078829+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319256065; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348851330164000 waited (count) when Workers occupied = 34535857 waited when Workers occupied = 76866419841900
2024-01-31T14:11:50.060510+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319894017; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348943740455400 waited (count) when Workers occupied = 34542790 waited when Workers occupied = 76890229805500
Eine ausführliche Erläuterung der oben genannten Informationen finden Sie unter MTS Performance Monitoring How Much Do You Know?
Die Statistiken, die seltener auftraten, wurden entfernt und der Vergleich einiger Schlüsseldaten angezeigt.
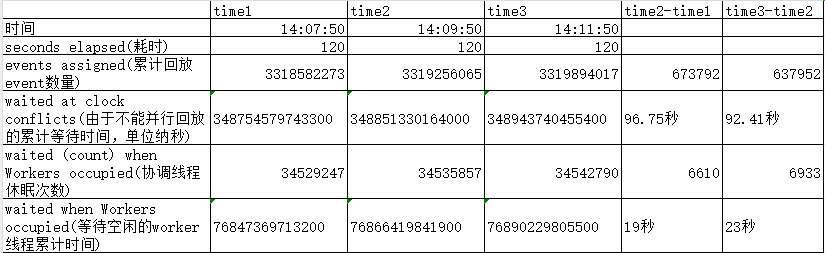
Es kann festgestellt werden, dass der Wiedergabekoordinationsthread bei der natürlichen Zeit von 120 mehr als 90 Sekunden wartet, weil er nicht parallel abspielen kann, und fast 20 Sekunden, weil keine inaktiven Arbeitsthreads warten müssen. Dies entspricht nur etwa 10 Sekunden damit der Koordinationsthread funktioniert.
Parallelitätsstatistik
Wie wir alle wissen, basiert die parallele Wiedergabe von MySQL hauptsächlich auf last_committed im Binlog. Wenn last_committed der Transaktion gleich ist, kann grundsätzlich davon ausgegangen werden, dass diese Transaktionen parallel wiedergegeben werden können die ungefähre Statistik zum Erhalten eines Relay-Protokolls aus der Umgebung für die parallele Wiedergabe.
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11){sum+=$2}} END {print sum}'
235703
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>10){sum+=$2}} END {print sum}'
314694
Der erste Befehl oben zählt die Anzahl der Transaktionen mit demselben last_committed zwischen 1 und 10, dh der Grad der parallelen Wiedergabe ist gering oder kann nicht parallel wiedergegeben werden. Die Gesamtzahl dieser Transaktionen beträgt 235703, was 43 % entspricht. Detaillierte Analyse der Transaktionen mit einem relativ geringen Grad an paralleler Wiedergabe. Aus der Transaktionsverteilung ist ersichtlich, dass es sich bei diesem Teil von last_committed im Grunde um eine einzelne Transaktion handelt. Sie müssen auf den Abschluss der Wiedergabe der Vorbestellungstransaktion warten Dies führt dazu, dass der im vorherigen Protokoll beobachtete Koordinationsthread nicht parallel abgespielt werden kann und in den Wartezustand wechselt
$ mysqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11) {print $2}}' | sort | uniq -c
200863 1
17236 2
98 3
13 4
3 5
1 7
Der zweite Befehl zählt die Gesamtzahl der Transaktionen mit mehr als 10 gleichen last_committed-Transaktionen, was 57 % entspricht. Es ist ersichtlich, dass diese Transaktionen im Detail analysiert werden zwischen 6500 und 9000. Anzahl der Transaktionen
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>11){print $0}}' | column -t
last_commited group_count Percentage
1 7340 1.33%
11938 7226 1.31%
23558 7249 1.32%
35248 6848 1.24%
46421 7720 1.40%
59128 7481 1.36%
70789 7598 1.38%
82474 6538 1.19%
93366 6988 1.27%
104628 7968 1.45%
116890 7190 1.31%
128034 6750 1.23%
138849 7513 1.37%
150522 6966 1.27%
161989 7972 1.45%
175599 8315 1.51%
189320 8235 1.50%
202845 8415 1.53%
218077 8690 1.58%
234248 8623 1.57%
249647 8551 1.55%
264860 8958 1.63%
280962 8900 1.62%
297724 8768 1.59%
313092 8620 1.57%
327972 9179 1.67%
344435 8416 1.53%
359580 8924 1.62%
375314 8160 1.48%
390564 9333 1.70%
407106 8637 1.57%
422777 8493 1.54%
438500 8046 1.46%
453607 8948 1.63%
470939 8553 1.55%
486706 8339 1.52%
503562 8385 1.52%
520179 8313 1.51%
535929 7546 1.37%
Einführung in den last_committed-Mechanismus
Die Parameter der Hauptbibliothek binlog_transaction_dependency_trackingwerden verwendet, um anzugeben, wie die in das Binärprotokoll geschriebenen Abhängigkeitsinformationen generiert werden, um der Slave-Bibliothek zu helfen, zu bestimmen, welche Transaktionen parallel ausgeführt werden können. Das heißt, dieser Parameter wird verwendet, um den Generierungsmechanismus von last_committed zu steuern. Die optionalen Werte des Parameters sind COMMIT_ORDER, WRITESET und SESSION_WRITESET. Aus dem folgenden Code sind die drei Parameterbeziehungen leicht zu erkennen:
- Der grundlegende Algorithmus ist COMMIT_ORDER
- Der WRITESET-Algorithmus wird basierend auf COMMIT_ORDER erneut berechnet
- Der SESSION_WRITESET-Algorithmus wird basierend auf WRITESET erneut berechnet
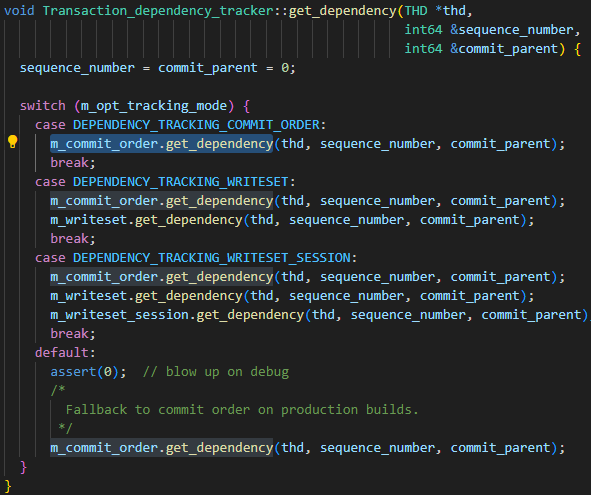
Da meine Instanz auf WRITESET eingestellt ist, konzentrieren Sie sich einfach auf den COMMIT_ORDER-Algorithmus und den WRITESET-Algorithmus.
COMMIT_ORDER
COMMIT_ORDER-Berechnungsregel: Wenn zwei Transaktionen gleichzeitig auf dem Master-Knoten eingereicht werden, bedeutet dies, dass es keinen Konflikt zwischen den Daten der beiden Transaktionen gibt, dann können sie auch parallel auf dem Slave-Knoten ausgeführt werden. Ein idealer typischer Fall ist wie folgt.
| Session 1 | Sitzung-2 |
|---|---|
| BEGINNEN | BEGINNEN |
| INSERT t1-Werte(1) | |
| t2-Werte einfügen(2) | |
| begehen (group_commit) | begehen (group_commit) |
Bei MySQL handelt es sich jedoch um ein internes Verhalten, solange Session-1 und Session-2 gleichzeitig Commit ausführen, unabhängig davon, ob sie intern in Group_Commit zusammengeführt werden Ein Schritt zurück: Solange Sitzung 1 Commit ausführt und keine neuen Daten in Sitzung 2 geschrieben werden, weisen die beiden Transaktionen immer noch keine Datenkonflikte auf und können weiterhin parallel repliziert werden.
| Session 1 | Sitzung-2 |
|---|---|
| BEGINNEN | BEGINNEN |
| INSERT t1-Werte(1) | |
| t2-Werte einfügen(2) | |
| begehen | |
| begehen |
In Szenarien mit mehr gleichzeitigen Threads können diese Threads möglicherweise nicht gleichzeitig parallel repliziert werden, einige Transaktionen jedoch schon. Nehmen wir als Beispiel die folgende Ausführungssequenz: Nachdem Sitzung 3 festgeschrieben wurde, hat Sitzung 2 keine neuen Schreibvorgänge, sodass die beiden Transaktionen parallel repliziert werden können. Nachdem Sitzung 3 festgeschrieben wurde, fügt Sitzung 1 neue Daten ein, was zu einem Datenkonflikt führt kann derzeit nicht bestimmt werden, daher können die Transaktionen von Sitzung 3 und Sitzung 1 nicht parallel repliziert werden, aber nach der Übermittlung von Sitzung 2 werden nach Sitzung 1, also Sitzung 2 und Sitzung 1, keine neuen Daten geschrieben sind wieder parallel replizierbar. Daher kann in diesem Szenario Sitzung 2 parallel zu Sitzung 1 bzw. Sitzung 3 repliziert werden, die drei Transaktionen können jedoch nicht gleichzeitig parallel repliziert werden.
| Session 1 | Sitzung-2 | Sitzung-3 |
|---|---|---|
| BEGINNEN | BEGINNEN | BEGINNEN |
| INSERT t1-Werte(1) | t2-Werte einfügen(1) | t3-Werte einfügen(1) |
| t1-Werte einfügen(2) | t2-Werte einfügen(2) | |
| begehen | ||
| t1-Werte einfügen(3) | ||
| begehen | ||
| begehen |
SCHREIBSET
Es handelt sich tatsächlich um eine Kombination aus commit_order+writeset. Es berechnet zunächst einen last_committed-Wert über commit_order, dann einen neuen Wert über writeset und verwendet schließlich den kleineren Wert zwischen den beiden als last_committed-Wert der endgültigen Transaktions-GTID.
In MySQL ist writeset im Wesentlichen ein Hash-Wert, der für Schemaname + Tabellenname + Primärschlüssel/eindeutiger_Schlüssel berechnet wird. Während der Ausführung der DML-Anweisung werden für alle Primärschlüssel/eindeutigen Schlüssel in der DML-Anweisung Hash-Werte berechnet, bevor row_event über binlog_log_row generiert wird separat und zur Writeset-Liste der Transaktion selbst hinzugefügt. Und wenn es eine Tabelle ohne Primärschlüssel/eindeutigen Index gibt, wird has_missing_keys=true auch für die Transaktion gesetzt.
Der Parameter ist auf WRITESET gesetzt, darf aber nicht verwendet werden. Die Einschränkungen sind wie folgt
- Nicht-DDL-Anweisungen oder -Tabellen mit Primärschlüsseln oder eindeutigen Schlüsseln oder leeren Transaktionen
- Der von der aktuellen Sitzung verwendete Hash-Algorithmus stimmt mit dem in der Hash-Map überein.
- Es werden keine Fremdschlüssel verwendet
- Die Kapazität der Hash-Map überschreitet nicht die Einstellung von binlog_transaction_dependency_history_size. Wenn die oben genannten vier Bedingungen erfüllt sind, kann der WRITESET-Algorithmus verwendet werden. Wenn eine der Bedingungen nicht erfüllt ist, wird er zur COMMIT_ORDER-Berechnungsmethode degeneriert.
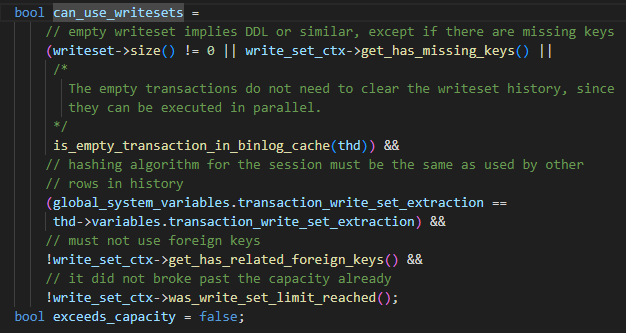
Der spezifische WRITESET-Algorithmus lautet wie folgt, wenn die Transaktion übermittelt wird:
-
last_committed ist auf m_writeset_history_start gesetzt, dieser Wert ist die kleinste sequence_number in der m_writeset_history-Liste
-
Durchlaufen Sie die Writeset-Liste der Transaktionen
a Wenn in der globalen m_writeset_history kein Writeset vorhanden ist, erstellen Sie ein Paar<writeset, sequence_number>-Objekt der aktuellen Transaktion und fügen Sie es in die globale m_writeset_history-Liste ein
b. Wenn es existiert, dann last_committed=max(last_committed, der Sequenznummerwert des historischen Schreibsatzes) und gleichzeitig die dem Schreibsatz entsprechende Sequenznummer in m_writeset_history auf den aktuellen Transaktionswert aktualisieren
-
Wenn has_missing_keys=false, d. h. alle Datentabellen der Transaktion Primärschlüssel oder eindeutige Indizes enthalten, wird der von commit_order und writeset berechnete Mindestwert als endgültiger last_committed-Wert verwendet.
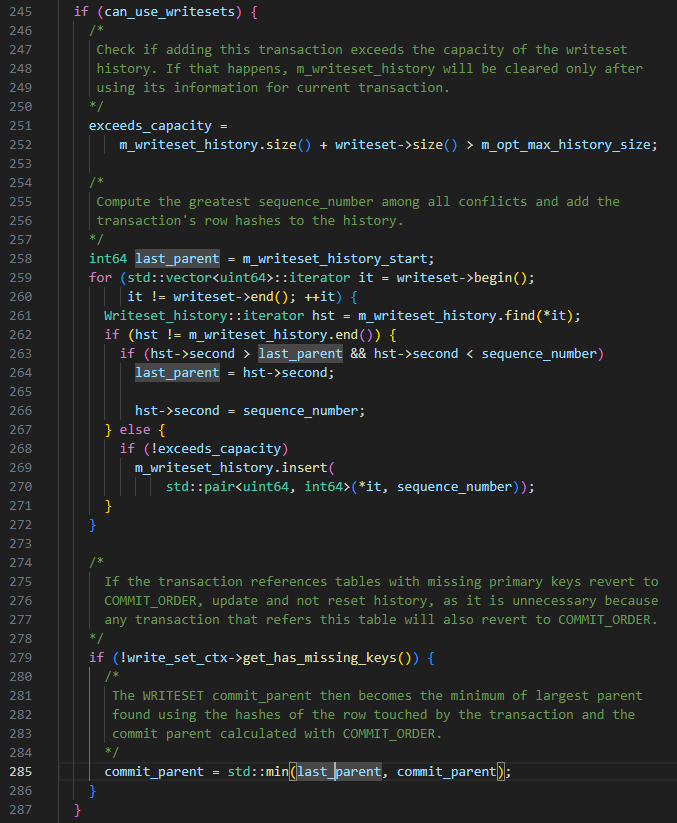
TIPPS: Basierend auf den oben genannten WRITESET-Regeln kann es vorkommen, dass der last_committed der später übermittelten Transaktion kleiner ist als der der zuerst übermittelten Transaktion.
Fazitanalyse
Abschlussbeschreibung
Gemäß den Nutzungsbeschränkungen von WRITESET verglichen wir Relay-Log und die an der Transaktion beteiligten Tabellenstrukturen, analysierten die Transaktionszusammensetzung eines einzelnen last_committed und stellten die folgenden zwei Situationen fest:
- Es besteht ein Datenkonflikt zwischen den an der einzelnen last_committed-Transaktion beteiligten Daten und sequence_number.
- Die an einer einzelnen last_committed-Transaktion beteiligte Tabelle hat keinen Primärschlüssel und es gibt viele solcher Transaktionen.
Aus der obigen Analyse kann geschlossen werden, dass die Tabelle zu viele Transaktionen ohne Primärschlüssel enthält, was dazu führt, dass WRITESET zu COMMIT_ORDER degeneriert. Da es sich bei der Datenbank um eine TP-Anwendung handelt, werden Transaktionen schnell übermittelt und es kann nicht garantiert werden, dass mehrere Transaktionen übermittelt werden innerhalb eines Commit-Zyklus liegen, was zu COMMIT_ORDER führt. Die vom Mechanismus generierten last_committed-Wiederholungsvorgänge sind sehr gering. Die Slave-Bibliothek kann diese Transaktionen nur seriell wiedergeben, was zu Verzögerungen bei der Wiedergabe führt.
Optimierungsmaßnahmen
- Ändern Sie die Tabellen von der Geschäftsseite aus und fügen Sie nach Möglichkeit Primärschlüssel zu verwandten Tabellen hinzu.
- Versuchen Sie, die Parameter binlog_group_commit_sync_delay und binlog_group_commit_sync_no_delay_count von 0 auf 10000 zu erhöhen. Aufgrund besonderer Umgebungseinschränkungen wird diese Anpassung möglicherweise nicht wirksam.
Viel Spaß mit GreatSQL :)
Über GreatSQL
GreatSQL ist eine inländische unabhängige Open-Source-Datenbank, die für Anwendungen auf Finanzebene geeignet ist. Sie verfügt über viele Kernfunktionen wie hohe Leistung, hohe Zuverlässigkeit, hohe Benutzerfreundlichkeit und hohe Sicherheit. Sie kann als optionaler Ersatz für MySQL oder Percona Server verwendet werden und wird in Online-Produktionsumgebungen verwendet, völlig kostenlos und kompatibel mit MySQL oder Percona Server.
Verwandte Links: GreatSQL Community Gitee GitHub Bilibili
GreatSQL-Community:

Vorschläge und Feedback zu Community-Belohnungen: https://greatsql.cn/thread-54-1-1.html
Details zur preisgekrönten Einreichung des Community-Blogs: https://greatsql.cn/thread-100-1-1.html
(Wenn Sie Fragen zu dem Artikel haben oder einzigartige Erkenntnisse gewinnen möchten, können Sie diese auf der offiziellen Community-Website stellen oder teilen~)
Technische Austauschgruppe:
WeChat- und QQ-Gruppe:
QQ-Gruppe: 533341697
WeChat-Gruppe: Fügen Sie GreatSQL Community Assistant (WeChat-ID wanlidbc:) als Freund hinzu und warten Sie, bis der Community-Assistent Sie der Gruppe hinzufügt.