
This article is shared from Huawei Cloud Community " A brief analysis of the long-tail latency problem of KV storage, Huawei Cloud GeminiDB Redis explores better solutions in the industry!" ", author: Huawei Cloud Database GaussDB NoSQL Team.
At present, the widespread use of KV storage largely stems from the business requirements for fast access, and this kind of business is usually highly sensitive to latency. Under good average performance, performance jitter in specific scenarios also needs to be resolved. Open source Redis uses fork to create sub-threads for execution in order not to affect the main thread when operating AOF rewriting, RDB, master-slave synchronization, etc. However, since the main thread is still providing services, triggering Copy-On-Write will cause performance jitters. , resulting in long tail delay.
Huawei Cloud GeminiDB (formerly Huawei Cloud GaussDB NoSQL, later collectively referred to as GeminiDB) is a NoSQL multi-mode database that adopts a storage-computation separation architecture and is industry-leading in terms of performance and stability. On the KV interface, GeminiDB is 100% compatible with the Redis 5.0 protocol, and users can migrate to GeminiDB without modifying the code. Aiming at the pain points of Redis fork technology in the industry, GeminiDB provides the ultimate optimization solution.
Let’s first look at two common solutions in the industry:
Industry solution one: Implementation-level optimization fork problem
The conventional solution is to make magic changes at the fork implementation layer, that is, to find the code that causes the long tail delay of fork and then optimize it. Through many experiments, it was found that the execution time of fork increases sharply as the instance size increases. The most time-consuming one is the page table copy operation. As shown in (a) below, after the Invoke Fork operation, the main process needs to spend time. Page table copy and service glitches occur.
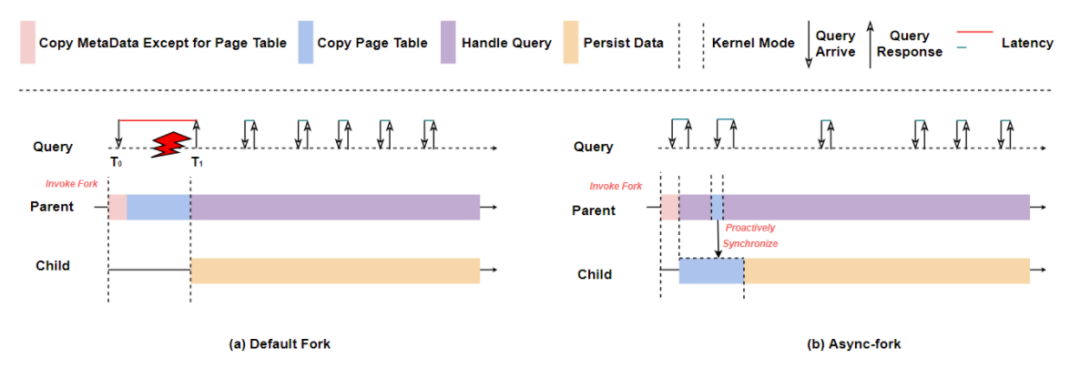
This leads to the core idea of fork rewriting: Since the parent process is not pure in the native internal implementation of fork, it still needs to fall into the kernel state when copying the page table, causing a temporary blocking phenomenon. By moving the most time-consuming page copy operation of the parent process to the child process for execution, it is enough to significantly weaken the blocking phenomenon of the parent process during the fork process, so that the problems caused by the native fork can be solved without any modification to the program. Long tail delay.
There is an algorithm in the industry, as shown in (b) above, which allows the child process to asynchronously complete the page table copy action (Copy Page Table) and the main process to actively synchronize the page table (Proactively Synchronize) to solve glitches and possible inconsistencies between the main and child processes. The problem is that the main process can be achieved with almost zero blocking. It is not difficult to see that modifying the fork algorithm has the following advantages:
1. The implementation level eliminates the long tail delay caused by fork scenarios.
2. Completely transparent to in-memory key-value storage services.
However, due to the fork implementation of the modified operating system, the maintenance and evolution costs are high and the forward compatibility is poor. In contrast, it may be simpler and more natural to solve this problem at the architectural level.
Industry Solution 2: Optimizing the fork problem at the architectural level
In addition to optimizing fork, directly eliminating fork may be a more urgent need in engineering.
Let's analyze it. The reason why fork is introduced is because Redis performs AOF rewriting, RDB, and master-slave synchronization operations. For in-memory KV storage like Redis, AOF operations can ensure that data is not lost, and RDB and master-slave synchronization are also required for persistence. But if it is non-volatile KV storage, the link from memory to persistent media does not exist, and RDB-like and master-slave synchronization operations can be handled independently by the storage layer, thus completely eliminating the long tail caused by fork. time delay.
Based on this, some databases in the industry directly write KV data into persistent media through their storage engines, and have highly optimized performance at the computing layer, achieving performance that is no worse than open source Redis:
Storage and computing separation architecture using PMem as storage base
The storage engine that uses PMem as its main persistent storage medium, to a certain extent, combines the performance and byte addressability of DRAM with the persistence characteristics of SSD. The following figure is a comparison of several storage media:

At the same time, by implementing the Cache module of the storage engine, the data pages storing hot business data during service operation will be loaded to PMem. During the processing of user requests, the data pages on the SSD are no longer directly operated, but the read and write delay is changed. Low PMem further improves the performance and throughput of the computing layer.
In general, the advantages of using PMem storage base are:
1. There is no fork scenario, and there is no long tail delay caused by fork.
2. Provides greater capacity than open source Redis.
3. Data can be stored in hot and cold hierarchies.
However, strong dependence on PMem also brings some problems that are difficult to solve:
1. Non-volatile memory programming is difficult and has poor robustness. It requires frameworks and tools to reduce its development difficulty. In general, the development and maintenance costs are too high.
2. Due to complex programming, numerous Redis index structures, and more than 300 data model-related APIs, the reliability of the implementation of Redis command compatibility is greatly reduced, and the problem of how to reduce coding complexity is also faced.
3. PMem has an order of magnitude performance degradation compared to DRAM, with more than 3 times the performance degradation and more than 10 times bandwidth reduction in read performance. Performance issues cannot be ignored.
In terms of reliability and development and maintenance costs, the architecture using PMem as the storage base still has certain shortcomings.
Huawei Cloud's NoSQL database GeminiDB has a more powerful implementation solution in this regard. GeminiDB is compatible with the Redis interface (formerly GaussDB (for Redis), later collectively referred to as the GeminiDB compatible Redis interface). Based on RocksDB + distributed file system + high-performance storage pool, it implements a leading storage and computing separation architecture, with better overall performance.
GeminiDB storage and calculation separation architecture
Huawei Cloud GeminiDB is compatible with the Redis interface. The storage architecture adopts RocksDB + distributed file system + high-performance storage pool. As shown in the figure below, in addition to eliminating the impact of long-tail latency at the architectural level, it also provides highly reliable storage features through high-performance storage pools. The distributed file system encapsulates a high-performance storage pool and exposes standard file system interfaces to the outside, reducing development difficulty.
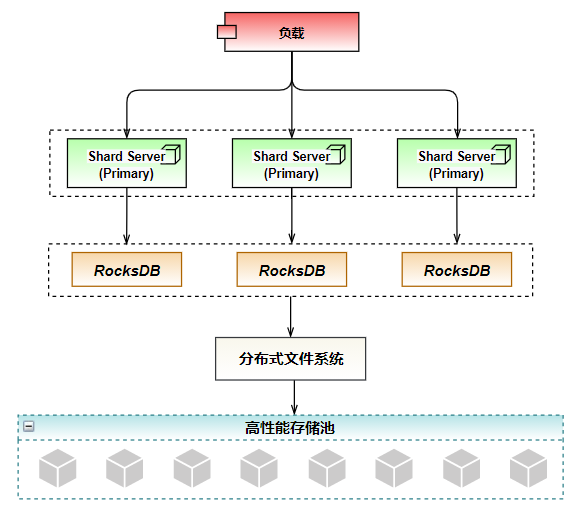
In terms of performance selection, RocksDB is selected as the storage engine. It is optimized for fast, low-latency storage with extremely high write throughput. At the same time, RocksDB supports write-ahead logs, range scans and prefix searches, which can provide consistency guarantees during high-concurrency reading and writing and large-capacity storage. The append write feature of RockDB just solves the most time-consuming disk seek time of disk I/O, achieving a performance close to that of random memory read and write.
For high-reliability implementation, choose the high-performance storage pool distributed storage developed by Huawei, which supports up to 128TB of massive storage, supports cross-AZ deployment, and second-level switchover after failure, ensuring data loss-free and rapid recovery in extremely severe situations. Supporting data automatic backup.
In addition, the distributed file system uses HDFS Snapshot to achieve second-level snapshots, generating a mirror of the entire file system or a certain directory at a certain moment, providing users with the capabilities of data recovery, data backup, and data testing.
In short, through the storage architecture of RocksDB + distributed file system + high-performance storage pool, we have achieved:
1. Low latency, based on high-performance storage architecture, access latency is highly guaranteed.
2. Large capacity, based on the separation of storage and computing, the storage layer can be freely expanded.
3. Low cost, based on hierarchical storage of hot and cold data, meeting customer demands.
4. High reliability, based on distributed file system + high-performance storage pool, supports excellent data backup and data synchronization features, and does not cause delay to the main process.
However, RocksDB's data storage model also brings some complications. Because RocksDB has problems with reading, writing and space amplification, and the three restrict each other. Although RocksDB provides a variety of compaction strategies and parameters to adapt to different application scenarios, the cost of selecting strategies and adjusting parameters will be relatively high due to too many influencing factors.
summary
Through the comparison between different solutions, in terms of solving the long-tail delay problem, the architectural solution is more in line with the needs of most customers. At the same time, in most scenarios, GeminiDB's Redis interface-compatible architecture provides higher reliability and better performance than industry solutions. It is expected to reach a performance level of one million QPS per chip by the end of the year.
appendix
For more product information, please visit the official blog: bbs.huaweicloud.com/blogs/248875
Click to follow and learn about Huawei Cloud’s new technologies as soon as possible~
Alibaba Cloud suffered a serious failure and all products were affected (restored). Tumblr cooled down the Russian operating system Aurora OS 5.0. New UI unveiled Delphi 12 & C++ Builder 12, RAD Studio 12. Many Internet companies urgently recruit Hongmeng programmers. UNIX time is about to enter the 1.7 billion era (already entered). Meituan recruits troops and plans to develop the Hongmeng system App. Amazon develops a Linux-based operating system to get rid of Android's dependence on .NET 8 on Linux. The independent size is reduced by 50%. FFmpeg 6.1 "Heaviside" is released