Hallo zusammen, mein Name ist Mu Chuan
Die Schlüsselkomponente der Parallelitätsleistung der Go-Sprache liegt in ihrem Planungsprinzip. Go verwendet ein Modell namens M:N-Planung, wobei M den Kernel-Status-Thread des Betriebssystems und N den Benutzer-Status-Thread darstellt. Goroutinen (die leichte Ebene der Go-Sprache). Faden)
Im Wesentlichen handelt es sich bei der Goroutine-Planung um den Prozess, bei dem Goroutine (G) zur Ausführung gemäß einem bestimmten Algorithmus an die CPU gesendet wird. Da die CPU keine Goroutinen, sondern nur Kernel-Threads erkennen kann, muss der Go-Scheduler die Goroutinen für den Kernel-Thread M planen, und dann stellt der Betriebssystem-Scheduler den Kernel-Thread M zur Ausführung auf die CPU. M ist eigentlich eine Kapselung von Threads auf Kernel-Ebene, daher besteht die Kernaufgabe des Go-Schedulers darin, M Goroutinen zuzuweisen
Die Implementierung des Go-Schedulers hat mehrere Entwicklungen durchlaufen, unter anderem vom ursprünglichen GM-Modell zum GMP-Modell, von der Nichtunterstützung von Preemption über die Unterstützung von kooperativer Preemption bis hin zur Unterstützung von signalbasierter asynchroner Preemption. Dieser Evolutionsprozess wurde kontinuierlich optimiert und verfeinert, um die Parallelitätsleistung der Go-Sprache zu verbessern.
1. GMP-Modellkonzept
In der Go-Sprache sind Goroutinen die Grundeinheit der gleichzeitigen Verarbeitung. Dabei handelt es sich um leichtgewichtige Threads, die von der Go-Laufzeit geplant und verwaltet werden. Das Herzstück dieses Planungssystems ist das GMP-Modell, das aus drei Hauptkomponenten besteht:
G (Goroutinen): Benutzerthread, erstellt über das Schlüsselwort go
M (Maschine): Betriebssystem-Thread
P (Prozessor): Planungskontext, der eine Reihe von Goroutine-Warteschlangen verwaltet
Goroutinen belegen weniger Speicher als herkömmliche Threads und ihre Erstellungs- und Zerstörungskosten sind sehr gering, sodass Tausende von Goroutinen problemlos erstellt werden können, ohne dass ein großer Ressourcenverbrauch entsteht. Diese Funktion ist in Anwendungen mit hoher Parallelität sehr nützlich. Beispielsweise müssen wir einen Netzwerkserver schreiben und jede Clientverbindung erfordert eine separate Goroutine, um die Anfrage zu verarbeiten. Beim traditionellen Threading-Modell kann das Erstellen von Threads für jede Verbindung zu einer Ressourcenerschöpfung führen, aber in Go können problemlos Tausende von Goroutinen erstellt werden, um Client-Anfragen gleichzeitig ohne nennenswerte Leistungsprobleme zu bearbeiten.
2. GMP-Modelldesign-Ideen
Nutzen Sie die Parallelität
Mehrere Coroutinen sind an verschiedene Betriebssystem-Threads gebunden und können die Vorteile von Multi-Core-CPUs nutzen
Thread-Wiederverwendung
Work-Stealing-Mechanismus: Wenn Thread M kein ausführbares G hat, versucht er, G von P zu stehlen, die an andere M gebunden sind, um den Leerlauf zu reduzieren. Übergabemechanismus: Wenn Thread M aufgrund eines G-Systemaufrufs blockiert ist, überträgt er P an andere inaktive M für Ausführung. , M führt das verbleibende G von P aus
Präventive Planung
Vermeiden Sie, dass bestimmte Goroutinen Threads für längere Zeit belegen, was dazu führt, dass andere Goroutinen verhungern, und lösen Sie Fairnessprobleme.
3. Prinzip des GMP-Modells
Wer wird das arrangieren?
Der Go-Scheduler ist für die Planung von G bis M verantwortlich. Der Go-Scheduler ist Teil der Go-Laufzeit. Die Go-Laufzeit ist für die Implementierung wichtiger Funktionen wie gleichzeitige Planung, Speicherbereinigung und Speicherstapelverwaltung von Go verantwortlich.
Geplantes Objekt
Quelle von G
P's runnext (nur 1 G, Lokalitätsprinzip, wird immer zuerst geplant)
Ps lokale Warteschlange (Array, bis zu 256 G)
Globale G-Warteschlange (verknüpfte Liste, unbegrenzt)
Network poller_network poller_ (speichert G dort, wo Netzwerkanrufe blockiert sind)
Quelle von P
globale P-Warteschlange (Array, GOMAXPROCS P)
Quelle von M
Schlafende Thread-Warteschlange (nicht an P gebunden, langes Schlafen wartet auf GC-Recycling und -Zerstörung)
Thread ausführen (P binden, auf G in P zeigen)
Spin-Thread (gebundenes P, zeigt auf G0 von M)
Zeitplanung
In den folgenden Situationen wird die ausführende Goroutine gewechselt
Präventive Planung
Sysmon erkennt, dass die Coroutine zu lange läuft (z. B. Ruhezustand oder Endlosschleife), wechselt zu g0 und tritt in die Planungsschleife ein.
proaktive Planung
Eine neue Coroutine wird gestartet und die Coroutine ausgeführt, wodurch eine Planungsschleife ausgelöst wird.
Rufen Sie runtime.Gosched() aktiv auf, wechseln Sie zu g0 und betreten Sie die Planungsschleife
Nach der Garbage Collection stw wird g erneut ausgewählt, um die Ausführung zu starten.
passive Planung
Das System ruft Blöcke (synchronisiert) auf, blockiert G und M, trennt P von M, übergibt P an ein anderes M zur Bindung und das andere M führt das verbleibende G von P aus
Der Netzwerk-E/A-Aufruf blockiert (asynchron), blockiert G, verschiebt G zu NetPoller und M führt das verbleibende G von P aus.
Atomic/Mutex/Channel usw. blockieren (asynchron), Block G, G bewegt sich in die Warteschlange des Kanals und M führt das verbleibende G von P aus.
Planungsprozess
Bei der Planung von Coroutinen wird das Producer-Consumer-Modell verwendet, das die Entkopplung von Benutzeraufgaben und Schedulern realisiert.
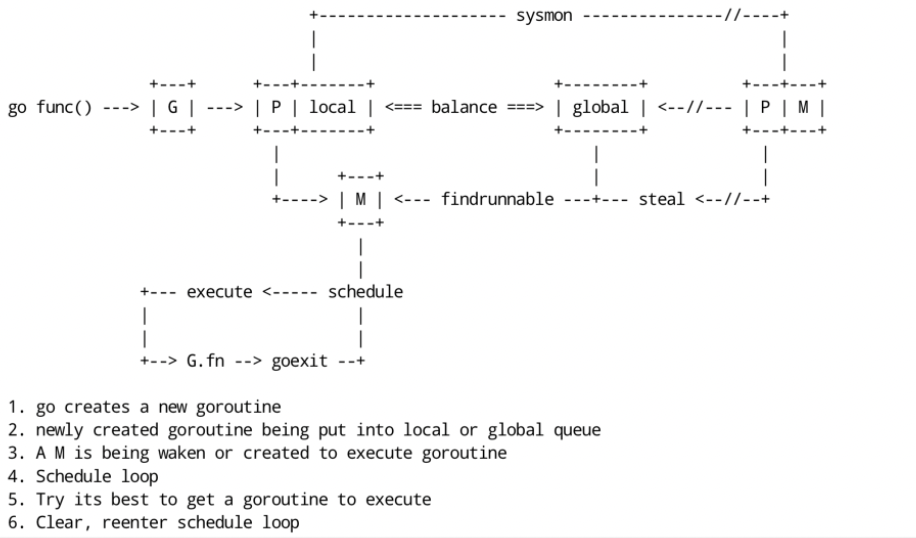
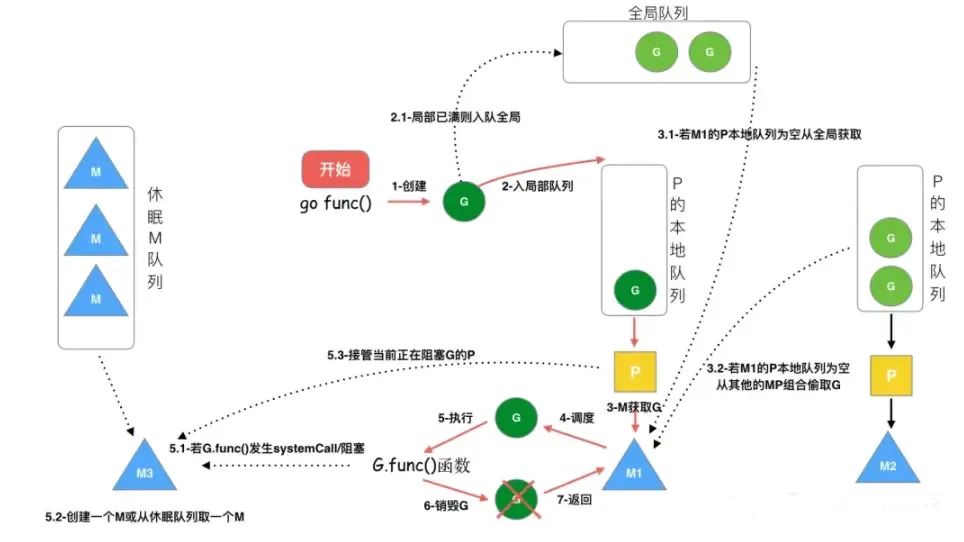
Jede Coroutine, die wir auf der Produktionsseite starten, ist eine Rechenaufgabe, und diese Aufgaben werden an die Laufzeit von go übermittelt. Wenn es sehr viele Rechenaufgaben gibt, Zehntausende davon, ist es unmöglich, dass diese Aufgaben sofort gleichzeitig ausgeführt werden, sodass die Rechenaufgabe zuerst zwischengespeichert wird. Der allgemeine Ansatz besteht darin, sie in die Warteschlange zu stellen des Speichers und warten auf die Ausführung. .
Der Lebenszyklus von G: G wird erstellt, gespeichert, erworben, geplant und ausgeführt, blockiert und zerstört. Die Schritte sind wie folgt:
Schritt 1: Erstellen Sie G
Beim Ausführen von go func ruft der Hauptthread M0 newproc() auf, um eine G-Struktur zu generieren
Schritt 2: Speichern Sie G
Das erstellte G wird zunächst in der lokalen Warteschlange P gespeichert. Wenn P voll ist, wird ein Teil von P an die globale Warteschlange verteilt.
Es wird versucht, jede Coroutine G zuerst in Runnext in P zu platzieren. Wenn Runnext leer ist, wird sie in Runnext platziert und die Produktion wird beendet.
Wenn der Runnext voll ist, werfen Sie das G im ursprünglichen Runnext in die lokale Warteschlange, stellen Sie das aktuelle G in den Runnext und die Produktion endet.
Wenn auch die lokale Warteschlange voll ist, wird die Hälfte des G in der lokalen Warteschlange entnommen und in die globale Warteschlange gestellt, und die Produktion wird beendet.
Schritt 3: Aufwachen oder ein neues M erstellen
Suchen Sie ein M und treten Sie in die Planungsschleife ein: Wiederholen Sie die Schritte 4, 5 und 6
Schritt 4: M bekommt G
Einzelheiten finden Sie in der Planungsstrategie unten.
Schritt 5: M plant und führt G aus
M ruft die Funktion G.func() auf, um G auszuführen
Wenn eine Systemaufrufblockierung (Synchronisation) auftritt, während M G ausführt , werden G und M blockiert (Betriebssystemeinschränkungen). Zu diesem Zeitpunkt wird P vom aktuellen M getrennt und sucht nach einem neuen M. Wenn kein freies vorhanden ist M, es wird ein neues M erstellt. Ein M übernimmt das P, das G blockiert, und führt dann weiterhin das verbleibende G in P aus. Diese Art der Freigabe von P nach der Blockierung wird als Übergabe bezeichnet. Wenn der Systemaufruf endet , versucht dieses G, ein inaktives P zur Ausführung zu erhalten, wobei dem Erhalten des zuvor gebundenen P Priorität eingeräumt und es in die lokale Warteschlange dieses P gestellt wird. Wenn es P nicht erhalten kann, wird dieser Thread M ruhend. Treten Sie dem inaktiven Thread bei, und dann wird dieses G in die globale Warteschlange gestellt.
Wenn M in Vorgängen wie Netzwerk-E/A blockiert ist, während G (asynchron) ausgeführt wird, wird G blockiert, M jedoch nicht . M sucht nach einer anderen ausführbaren Datei G in P, um die Ausführung fortzusetzen. G wird vom Netzwerk-Poller übernommen. Wenn das blockierte G wiederhergestellt wird, wird es vom Netzwerk-Poller zurück in die lokale Warteschlange von P verschoben und in die ausführbare Datei erneut eingegeben Zustand. In asynchronen Situationen wandelt der Go-Scheduler durch Planung erfolgreich E/A-Aufgaben in CPU-Aufgaben um oder wandelt Thread-Switching auf Kernel-Ebene in Goroutine-Switching auf Benutzerebene um, was die Effizienz erheblich verbessert.
Schritt 6: Bereinigen Sie die Szene
Nachdem M die Ausführung von G abgeschlossen hat, bereinigt es die Szene und tritt erneut in den Planungszyklus ein (schaltet die auf M laufende Goroutine auf G0 um, das für den Wechsel der Coroutinen während der Planung verantwortlich ist).
Planungsstrategie
Welche Strategie wird verwendet, um die nächste auszuführende Goroutine auszuwählen: Da die G in P in Runnext, lokaler Warteschlange, globaler Warteschlange und Netzwerk-Poller verteilt sind, muss nacheinander ermittelt werden, ob ausführbare Gs vorhanden sind. Die allgemeine Logik lautet wie folgt:
Jedes Mal, wenn 61 Planungsschleifen ausgeführt werden, wird G aus der globalen Warteschlange abgerufen und, falls vorhanden, direkt zurückgegeben (hauptsächlich, um ein Verhungern von G in der globalen Warteschlange zu vermeiden).
Verwenden Sie runnext auf P, um zu sehen, ob es G gibt, und wenn ja, kehren Sie direkt zurück.
Überprüfen Sie, ob G aus der lokalen Warteschlange auf P vorhanden ist, und kehren Sie in diesem Fall direkt zurück
Wenn keines der oben genannten gefunden wird, suchen Sie in der globalen Warteschlange, im Netzwerk-Poller oder stehlen Sie von anderen P und blockieren Sie , bis ein verfügbares G erhalten wird.
Der Quellcode ist wie folgt implementiert:
func schedule() {
_g_ := getg()
var gp *g
var inheritTime bool
...
if gp == nil {
// 每执行61次调度循环会看一下全局队列。为了保证公平,避免全局队列一直无法得到执行的情况,当全局运行队列中有待执行的G时,通过schedtick保证有一定几率会从全局的运行队列中查找对应的Goroutine;
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 先尝试从P的runnext和本地队列查找G
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
// 仍找不到,去全局队列中查找。还找不到,要去网络轮询器中查找是否有G等待运行;仍找不到,则尝试从其他P中窃取G来执行。
gp, inheritTime = findrunnable() // blocks until work is available
// 这个函数是阻塞的,执行到这里一定会获取到一个可执行的G
}
...
// 调用execute,继续调度循环
execute(gp, inheritTime)
}4. Zusammenfassung
In praktischen Anwendungen hat Go seine überlegene Leistung in Umgebungen mit hoher Parallelität unter Beweis gestellt. Beispielsweise profitieren hochgradig gleichzeitige Webserver, verteilte Systeme und paralleles Rechnen alle vom GMP-Modell. Wenn Sie das GMP-Modell verstehen und nutzen, wird Ihr Programm wettbewerbsfähiger und in der Lage, große Parallelität effektiv zu bewältigen.
Abschließend möchte ich für mein ursprüngliches Go-Interviewheft werben. Wenn Sie sich mit Go-bezogener Entwicklung befassen, können Sie gerne den Code scannen, um es zu kaufen. Der aktuelle Buyout beträgt 10 Yuan. Fügen Sie den Screenshot der WeChat-Zahlung unten hinzu, um ein zusätzliches Exemplar zu senden Ihres eigenen aufgezeichneten Go-Interview-Fragen-Erklärungsvideos.

Wenn es für Sie hilfreich ist, helfen Sie mir bitte, es anzusehen oder weiterzuleiten. Willkommen, wenn Sie meinem offiziellen Konto folgen