Inhaltsverzeichnis
2. Entwurfsmuster in Containern
1. Trennung von Lesen und Schreiben
2. So funktioniert die Reißverschlussmethode
4. Bestimmen Sie den Bucket-Index
5. Kapazitätserweiterung – Grundprinzipien
7. Objekte werden als Schlüssel gespeichert
Java-Container sind eine Reihe von Tools zum Speichern von Daten und Objekten. Es kann mit der STL von C++ verglichen werden. Java-Container werden auch Java Collection Framework (JCF) genannt. Zusätzlich zu Containern, in denen Objekte gespeichert werden, wird eine Reihe von Dienstprogrammklassen zum Verarbeiten und Bearbeiten von Objekten in den Containern bereitgestellt. Im Allgemeinen handelt es sich hierbei um ein Framework, das Java-Objektcontainer und Dienstprogrammklassen enthält.
1. Übersicht
Zu den Containern gehören hauptsächlich Collection und Map . Collection speichert eine Sammlung von Objekten, während Map eine Zuordnungstabelle von Schlüssel-Wert-Paaren (zwei Objekte) speichert.
1.1 Sammlung
1. Einstellen
- TreeSet : Basierend auf der Rot-Schwarz-Baum-Implementierung, unterstützt geordnete Vorgänge, wie z. B. die Suche nach Elementen basierend auf einem Bereich. Die Sucheffizienz ist jedoch nicht so gut wie die von HashSet. Die zeitliche Komplexität der HashSet-Suche beträgt O(1), während die von TreeSet O(logN) beträgt.
- HashSet : Basierend auf der Hash-Tabellenimplementierung, unterstützt die schnelle Suche, unterstützt jedoch keine geordneten Operationen. Und die Informationen zur Einfügereihenfolge der Elemente gehen verloren, was bedeutet, dass das Ergebnis, das durch die Verwendung von Iterator zum Durchlaufen des HashSet erhalten wird, ungewiss ist.
- LinkedHashSet : Es verfügt über die Sucheffizienz von HashSet und verwendet intern eine doppelt verknüpfte Liste, um die Einfügereihenfolge von Elementen beizubehalten.
2. Liste
- ArrayList : Basierend auf einer dynamischen Array-Implementierung, unterstützt Direktzugriff.
- Vektor : Ähnlich wie ArrayList, aber threadsicher.
- LinkedList : Basierend auf einer doppelt verknüpften Liste kann nur sequentiell darauf zugegriffen werden, es können jedoch schnell Elemente in der Mitte der verknüpften Liste eingefügt und gelöscht werden. Darüber hinaus kann LinkedList auch als Stack, Queue und Deque verwendet werden.
3. Warteschlange
- LinkedList : Sie können damit eine bidirektionale Warteschlange implementieren.
- PriorityQueue : Basierend auf der Heap-Struktur können Sie damit Prioritätswarteschlangen implementieren.
1.2 Karte
- TreeMap : basierend auf rot-schwarzen Bäumen implementiert.
- HashMap : Basierend auf der Hash-Tabellen-Implementierung.
- HashTable : Ähnlich wie HashMap, aber threadsicher, was bedeutet, dass mehrere Threads, die gleichzeitig in HashTable schreiben, keine Dateninkonsistenz verursachen. Es handelt sich um eine Legacy-Klasse und sollte nicht verwendet werden. Verwenden Sie stattdessen ConcurrentHashMap, um die Thread-Sicherheit zu unterstützen. ConcurrentHashMap ist effizienter, da ConcurrentHashMap Segmentierungssperren einführt.
- LinkedHashMap : Verwenden Sie eine doppelt verknüpfte Liste, um die Reihenfolge der Elemente in der Einfügereihenfolge oder in der LRU-Reihenfolge (Least Latest Used) beizubehalten.
2. Entwurfsmuster in Containern
Iteratormuster
Collection erbt die Iterable-Schnittstelle, in der die iterator()-Methode ein Iterator-Objekt generieren kann, über das die Elemente in der Collection iteriert werden können.
Ab JDK 1.5 können Sie die foreach-Methode verwenden, um Aggregatobjekte zu durchlaufen, die die Iterable-Schnittstelle implementieren.
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {
System.out.println(item);
}Adaptermodus
java.util.Arrays#asList() kann den Array-Typ in den Listentyp konvertieren.
@SafeVarargs
public static <T> List<T> asList(T... a)Es ist zu beachten, dass die Parameter von asList () generische Parameter variabler Länge sind und Basistyp-Arrays nicht als Parameter verwendet werden können, sondern nur entsprechende Pakettyp-Arrays.
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);asList() kann auch aufgerufen werden mit:
List list = Arrays.asList(1, 2, 3);3. Quellcode-Analyse
Sofern nicht anders angegeben, basiert die folgende Quellcode-Analyse auf JDK 1.8.
Rufen Sie in IDEA Search EveryWhere mit der doppelten Umschalttaste auf, suchen Sie nach Quellcodedateien und lesen Sie dann den Quellcode.
Anordnungsliste
1. Übersicht
Da ArrayList auf Array-Basis implementiert ist, unterstützt es schnellen Direktzugriff. Die RandomAccess-Schnittstelle gibt an, dass die Klasse schnellen Direktzugriff unterstützt.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable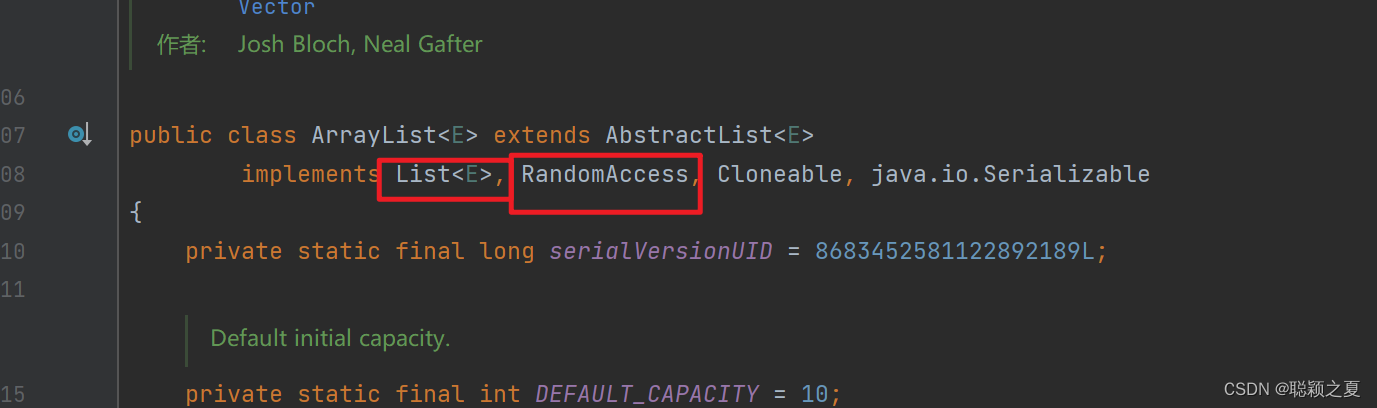
Die Standardgröße des Arrays beträgt 10.
private static final int DEFAULT_CAPACITY = 10;2. Erweiterung
Verwenden Sie beim Hinzufügen von Elementen die Methode „sichsureCapacityInternal()“, um sicherzustellen, dass die Kapazität ausreichend ist. Wenn dies nicht ausreicht, müssen Sie die Methode „grow()“ verwenden, um die Kapazität zu erweitern. Die Größe der neuen Kapazität beträgt oldCapacity + oldCapacity
oldCapacity + (oldCapacity >> 1)/ 2 . Unter diesen muss oldCapacity >> 1 gerundet werden, sodass die neue Kapazität etwa das 1,5-fache der alten Kapazität beträgt. (Wenn oldCapacity eine gerade Zahl ist, beträgt sie das 1,5-fache, und wenn es eine ungerade Zahl ist, beträgt sie das 1,5-fache von 0,5.)Der Erweiterungsvorgang erfordert den Aufruf, das gesamte ursprüngliche Array in das neue Array zu kopieren. Dieser Vorgang ist sehr teuer, daher ist es am besten, beim Erstellen des ArrayList-Objekts die ungefähre Kapazität anzugeben, um die Anzahl der Erweiterungsvorgänge zu reduzieren.
Arrays.copyOf()
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}3. Elemente löschen
Sie müssen System.arraycopy() aufrufen, um alle Elemente nach Index+1 an die Indexposition zu kopieren. Die zeitliche Komplexität dieser Operation beträgt O(N) . Sie können sehen, dass die Kosten für das Löschen von Elementen in ArrayList sehr hoch sind.
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null;
return oldValue;
}4. Serialisierung
ArrayList wird basierend auf Arrays implementiert und verfügt über dynamische Erweiterungseigenschaften. Daher werden möglicherweise nicht alle Arrays, in denen Elemente gespeichert sind, verwendet, sodass keine Notwendigkeit besteht, sie alle zu serialisieren.
Das Array elementData, das die Elemente enthält, wird mit transient geändert. Dieses Schlüsselwort deklariert, dass das Array standardmäßig nicht serialisiert wird.
transient Object[] elementData;ArrayList implementiert writeObject() und readObject(), um die Serialisierung nur des mit Elementen gefüllten Teils des Arrays zu steuern.
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
s.defaultReadObject();
s.readInt();
if (size > 0) {
ensureCapacityInternal(size);
Object[] a = elementData;
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
int expectedModCount = modCount;
s.defaultWriteObject();
s.writeInt(size);
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}Beim Serialisieren müssen Sie writeObject () von ObjectOutputStream verwenden, um das Objekt in einen Bytestream umzuwandeln und auszugeben. Die Methode writeObject() reflektiert und ruft writeObject() des Objekts auf, wenn das eingehende Objekt in writeObject() vorhanden ist, um eine Serialisierung zu erreichen. Die Deserialisierung verwendet die readObject()-Methode von ObjectInputStream und das Prinzip ist ähnlich.
ArrayList list = new ArrayList();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(list);5. Fail-Fast
Vektor
1. Synchronisierung
Die Implementierung ähnelt ArrayList, verwendet jedoch synchronisiert zur Synchronisierung.
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}2. Erweiterung
Der Konstruktor von Vector kann den Parameter „capacityIncrement“ übergeben, der verwendet wird, um die Kapazität während der Erweiterung um „capacityIncrement“ zu erhöhen. Wenn der Wert dieses Parameters kleiner oder gleich 0 ist, wird die Kapazität bei jeder Erweiterung verdoppelt.
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
//调用没有 capacityIncrement 的构造函数时,
capacityIncrement 值被设置为 0,也就是说默认情况下 Vector 每次扩容时容量都会翻倍。
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector() {
this(10);
}
3. Vergleich mit ArrayList
- Vector ist synchronisiert, daher ist der Overhead größer als bei ArrayList und die Zugriffsgeschwindigkeit langsamer. Es ist besser, ArrayList anstelle von Vector zu verwenden, da die Synchronisierungsvorgänge vollständig vom Programmierer selbst gesteuert werden können.
- Vector benötigt bei jeder Erweiterung das Zweifache seiner Größe (die wachsende Kapazität kann auch über den Konstruktor festgelegt werden), während ArrayList das 1,5-fache benötigt.
4. Alternativen
Sie können verwenden Collections.synchronizedList();, um eine threadsichere ArrayList zu erhalten.
List<String> list = new ArrayList<>();
List<String> synList = Collections.synchronizedList(list);Sie können auch die CopyOnWriteArrayList- Klasse im Concurrent-Paket verwenden .
List<String> list = new CopyOnWriteArrayList<>();CopyOnWriteArrayList
1. Trennung von Lesen und Schreiben
Der Schreibvorgang wird für ein kopiertes Array ausgeführt, der Lesevorgang wird weiterhin für das ursprüngliche Array ausgeführt. Lesen und Schreiben sind getrennt und beeinflussen sich nicht gegenseitig.
Schreibvorgänge müssen gesperrt werden, um den Verlust geschriebener Daten aufgrund gleichzeitiger Schreibvorgänge zu verhindern.
Nachdem der Schreibvorgang abgeschlossen ist, muss das ursprüngliche Array auf das neue kopierte Array verweisen.
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}2. Anwendbare Szenarien
CopyOnWriteArrayList ermöglicht Lesevorgänge gleichzeitig mit Schreibvorgängen, was die Leistung von Lesevorgängen erheblich verbessert und sich daher sehr gut für Anwendungsszenarien mit mehr Lesevorgängen und weniger Schreibvorgängen eignet.
Aber CopyOnWriteArrayList hat seine Mängel:
- Speicherverbrauch: Beim Schreiben muss ein neues Array kopiert werden, wodurch der Speicherverbrauch etwa doppelt so hoch ist wie die ursprüngliche Größe.
- Dateninkonsistenz: Der Lesevorgang kann keine Echtzeitdaten lesen, da einige der Schreibvorgangsdaten noch nicht mit der Lesegruppe synchronisiert wurden.
Daher ist CopyOnWriteArrayList nicht für speicherempfindliche und Echtzeit-Anforderungsszenarien geeignet.
LinkedList
1. Übersicht
Basierend auf der Implementierung einer doppelt verknüpften Liste wird Node zum Speichern von Knoteninformationen verknüpfter Listen verwendet.
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}
每个链表存储了 first 和 last 指针:
transient Node<E> first;
transient Node<E> last;2. Vergleich mit ArrayList
ArrayList wird basierend auf dynamischen Arrays implementiert, und LinkedList wird basierend auf doppelt verknüpften Listen implementiert. Der Unterschied zwischen ArrayList und LinkedList kann auf den Unterschied zwischen Arrays und verknüpften Listen zurückgeführt werden:
- Arrays unterstützen den wahlfreien Zugriff, das Einfügen und Löschen ist jedoch teuer und erfordert das Verschieben einer großen Anzahl von Elementen.
- Verknüpfte Listen unterstützen keinen wahlfreien Zugriff, das Einfügen und Löschen erfordert jedoch nur eine Änderung des Zeigers.
HashMap
Um das Verständnis zu erleichtern, basiert die folgende Quellcode-Analyse hauptsächlich auf JDK 1.7.
1. Speicherstruktur
Es enthält intern eine Array-Tabelle vom Typ Eintrag. Der Eintrag speichert Schlüssel-Wert-Paare. Es enthält vier Felder. Aus dem nächsten Feld können wir erkennen, dass Eintrag eine verknüpfte Liste ist. Das heißt, jede Position im Array wird als Bucket betrachtet und jeder Bucket speichert eine verknüpfte Liste. HashMap verwendet die Zipper-Methode, um Konflikte zu lösen. Einträge mit demselben Hash-Wert und demselben Hash-Bucket-Modulo-Operationsergebnis werden in derselben verknüpften Liste gespeichert.
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}2. So funktioniert die Reißverschlussmethode
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");- Erstellen Sie eine neue HashMap. Die Standardgröße beträgt 16.
- Fügen Sie das Schlüssel-Wert-Paar <K1, V1> ein, berechnen Sie zunächst den HashCode von K1 bis 115 und verwenden Sie die Division-Leaving-Remainder-Methode, um den Bucket-Index 115%16=3 zu erhalten.
- Fügen Sie das Schlüssel-Wert-Paar <K2, V2> ein, berechnen Sie zunächst den HashCode von K2 auf 118 und verwenden Sie die Division-Leaving-Remainder-Methode, um den Bucket-Index 118%16=6 zu erhalten.
- Fügen Sie das Schlüssel-Wert-Paar <K3,V3> ein, berechnen Sie zunächst den HashCode von K3 bis 118, verwenden Sie die Divisions- und Restmethode, um den Bucket-Index 118%16=6 zu erhalten, und fügen Sie ihn vor <K2,V2> ein.
Es ist zu beachten, dass das Einfügen der verknüpften Liste durch Kopfeinfügung erfolgt. Beispielsweise wird das obige <K3, V3> nicht nach <K2, V2> eingefügt, sondern am Kopf der verknüpften Liste.
Die Suche muss in zwei Schritte unterteilt werden:
- Berechnen Sie den Bucket, in dem sich das Schlüssel-Wert-Paar befindet.
- Bei der sequentiellen Suche in einer verknüpften Liste ist die zeitliche Komplexität offensichtlich proportional zur Länge der verknüpften Liste.
3. Operation durchführen
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 键为 null 单独处理
if (key == null)
return putForNullKey(value);
int hash = hash(key);
// 确定桶下标
int i = indexFor(hash, table.length);
// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 插入新键值对
addEntry(hash, key, value, i);
return null;
}
HashMap ermöglicht das Einfügen von Schlüssel-Wert-Paaren mit Nullschlüsseln. Da jedoch die hashCode()-Methode von null nicht aufgerufen werden kann, kann der Bucket-Index des Schlüssel-Wert-Paares nicht bestimmt werden und kann nur durch erzwungene Angabe eines Bucket-Index gespeichert werden. HashMap verwendet den 0. Bucket zum Speichern von Schlüssel-Wert-Paaren mit Nullschlüsseln.
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}Verwenden Sie die Kopfeinfügungsmethode der verknüpften Liste, dh das neue Schlüssel-Wert-Paar wird am Kopf der verknüpften Liste und nicht am Ende der verknüpften Liste eingefügt.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 头插法,链表头部指向新的键值对
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}4. Bestimmen Sie den Bucket-Index
Bei vielen Vorgängen muss zunächst der Bucket-Index ermittelt werden, in dem sich ein Schlüssel-Wert-Paar befindet.
int hash = hash(key);
int i = indexFor(hash, table.length);4.1 Hash-Wert berechnen
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}4.2 Modellierung
Sei x = 1<<4, das heißt, x ist die 4. Potenz von 2, die die folgenden Eigenschaften hat:
x : 00010000
x-1 : 00001111
令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
y : 10110010
x-1 : 00001111
y&(x-1) : 00000010
这个性质和 y 对 x 取模效果是一样的:
y : 10110010
x : 00010000
y%x : 00000010
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运
static int indexFor(int h, int length) {
return h & (length-1);
}5. Kapazitätserweiterung – Grundprinzipien
Angenommen, die Tabellenlänge von HashMap beträgt M und die Anzahl der zu speichernden Schlüssel-Wert-Paare beträgt N. Wenn die Hash-Funktion die Einheitlichkeitsanforderungen erfüllt, beträgt die Länge jeder verknüpften Liste ungefähr N/M, also die Suche Komplexität ist O(N/ M).
Um die Suchkosten zu reduzieren, sollte N/M so klein wie möglich gemacht werden, also muss M so groß wie möglich sein, das heißt, die Tabelle sollte so groß wie möglich sein. HashMap verwendet eine dynamische Erweiterung, um den M-Wert entsprechend dem aktuellen N-Wert anzupassen, sodass sowohl Platzeffizienz als auch Zeiteffizienz gewährleistet werden können.
Zu den mit der Erweiterung verbundenen Parametern gehören hauptsächlich: Kapazität, Größe, Schwellenwert und Lastfaktor.
| Parameter | Bedeutung |
|---|---|
| Kapazität | Die Kapazität der Tabelle beträgt standardmäßig 16. Es ist zu beachten, dass die Kapazität garantiert 2 hoch n-tel sein muss. |
| Größe | Anzahl der Schlüssel-Wert-Paare. |
| Schwelle | Der kritische Wert der Größe. Wenn die Größe größer oder gleich dem Schwellenwert ist, muss der Erweiterungsvorgang durchgeführt werden. |
| Ladefaktor | Lastfaktor, der Anteil, den die Tabelle verwenden kann, Schwellenwert = (int)(Kapazität* Lastfaktor). |
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;Wie aus dem Code zum Hinzufügen von Elementen unten hervorgeht, wird die Kapazität verdoppelt, wenn eine Erweiterung erforderlich ist.
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}Die Erweiterung wird mit resize() implementiert. Es ist zu beachten, dass der Erweiterungsvorgang auch das erneute Einfügen aller Schlüssel-Wert-Paare der alten Tabelle in die neue Tabelle erfordert, sodass dieser Schritt sehr zeitaufwändig ist.
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}6. Vergleich mit Hashtable
- Hashtable verwendet synchronisiert für die Synchronisierung.
- HashMap kann Einträge mit Nullschlüsseln einfügen.
- Der Iterator von HashMap ist ein ausfallsicherer Iterator.
- HashMap kann nicht garantieren, dass die Reihenfolge der Elemente in der Karte im Laufe der Zeit unverändert bleibt.
7. Objekte werden als Schlüssel gespeichert
- Überschreiben Sie die Methoden hashCode() und equal(), um sicherzustellen, dass die Karte korrekt funktionieren und Objekte abrufen kann.
- Stellen Sie die Unveränderlichkeit des Objekts sicher, um eine Änderung des Objektstatus zu vermeiden, nachdem es als Schlüssel verwendet wurde.
- Implementiert optional die Comparable-Schnittstelle, um das Sortieren von Schlüsseln zu unterstützen.
- Gut gestaltete hashCode()-Methode, um die Möglichkeit von Hash-Kollisionen zu reduzieren.
- Vermeiden Sie die Verwendung veränderlicher Objekte als Schlüssel und aktualisieren Sie die Schlüssel in der Map bei Bedarf umgehend.
ConcurrentHashMap
1. Speicherstruktur
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}ConcurrentHashMap und HashMap sind in der Implementierung ähnlich. Der Hauptunterschied besteht darin, dass ConcurrentHashMap Segmentsperren (Segment) verwendet. Jede Segmentsperre verwaltet mehrere Buckets (HashEntry). Mehrere Threads können gleichzeitig auf Buckets in verschiedenen Segmentsperren zugreifen. Dadurch wird die Parallelität höher (Die Parallelität ist die Anzahl der Segmente).
Segment erbt von ReentrantLock.
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
final Segment<K,V>[] segments;
默认的并发级别为 16,也就是说默认创建 16 个 Segment。
static final int DEFAULT_CONCURRENCY_LEVEL = 16;2. Größenbetrieb
Jedes Segment verwaltet eine Zählvariable, um die Anzahl der Schlüssel-Wert-Paare im Segment zu zählen.
transient int count;
Bei der Größenoperation ist es notwendig, alle Segmente zu durchlaufen und dann die Zählung zu akkumulieren.
ConcurrentHashMap versucht zunächst, die Größenoperation nicht zu sperren. Wenn die Ergebnisse zweier aufeinanderfolgender nicht sperrender Operationen konsistent sind, kann das Ergebnis als korrekt angesehen werden.
Die Anzahl der Versuche wird mit RETRIES_BEFORE_LOCK definiert, das den Wert 2 hat. Der Anfangswert der Wiederholungen ist -1, also beträgt die Anzahl der Versuche 3.
Wenn die Anzahl der Versuche 3 überschreitet, muss jedes Segment gesperrt werden.
static final int RETRIES_BEFORE_LOCK = 2;
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow;
long sum;
long last = 0L;
int retries = -1;
try {
for (;;) {
// 超过尝试次数,则对每个 Segment 加锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock();
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 连续两次得到的结果一致,则认为这个结果是正确的
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}3. Änderungen in JDK 1.8
JDK 1.7 verwendet den Segmentsperrmechanismus, um gleichzeitige Aktualisierungsvorgänge zu implementieren. Die Kernklasse ist Segment, die von der Wiedereintrittssperre ReentrantLock erbt. Der Grad der Parallelität entspricht der Anzahl der Segmente.
JDK 1.8 verwendet CAS-Operationen, um eine höhere Parallelität zu unterstützen, und verwendet eine integrierte Sperre, die synchronisiert wird, wenn CAS-Operationen fehlschlagen.
Und wenn die verknüpfte Liste zu lang ist, wird die Implementierung von JDK 1.8 auch in einen Rot-Schwarz-Baum umgewandelt.
LinkedHashMap
Speicherstruktur
Es wurde von HashMap geerbt und verfügt über die gleichen schnellen Sucheigenschaften wie HashMap.
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>Eine doppelt verknüpfte Liste wird intern verwaltet, um die Einfügungsreihenfolge oder LRU-Reihenfolge aufrechtzuerhalten.
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;accessOrder bestimmt die Reihenfolge und der Standardwert ist false. Zu diesem Zeitpunkt wird die Einfügungsreihenfolge beibehalten.
final boolean accessOrder;Das Wichtigste an LinkedHashMap sind die folgenden Funktionen zur Aufrechterhaltung der Reihenfolge, die in put, get und anderen Methoden aufgerufen werden.
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }afterNodeAccess()
Wenn auf einen Knoten zugegriffen wird und accessOrder wahr ist, wird der Knoten an das Ende der verknüpften Liste verschoben. Das heißt, nach Angabe der LRU-Reihenfolge wird der Knoten bei jedem Zugriff auf einen Knoten an das Ende der verknüpften Liste verschoben, um sicherzustellen, dass das Ende der verknüpften Liste der zuletzt besuchte Knoten und der Kopf von ist Die verknüpfte Liste ist der jüngste und am längsten nicht verwendete Knoten.
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}afterNodeInsertion()
Es wird nach Operationen wie „Put“ ausgeführt. Wenn die Methode „removeEldestEntry()“ „true“ zurückgibt, wird der neueste Knoten, der der erste Knoten der verknüpften Liste ist, entfernt.
evict ist nur beim Erstellen der Karte falsch, hier ist es wahr.
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
removeEldestEntry() 默认为 false,如果需要让它为 true,需要继承 LinkedHashMap 并且覆盖这个方法的实现,这在实现 LRU 的缓存中特别有用,通过移除最近最久未使用的节点,从而保证缓存空间足够,并且缓存的数据都是热点数据。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}