Der Inhalt dieses Artikels bezieht sich auf die Entwicklung sowie den Betrieb und die Wartung von Redis.
1、String
Der String-Typ ist die grundlegendste Datenstruktur von Redis. Erstens handelt es sich bei allen Schlüsseln um Zeichenfolgentypen, und auf der Grundlage dieser Zeichenfolgentypen werden mehrere andere Datenstrukturen erstellt, sodass die Zeichenfolgentypen die Grundlage für das Lernen der anderen vier Datenstrukturen bilden können.
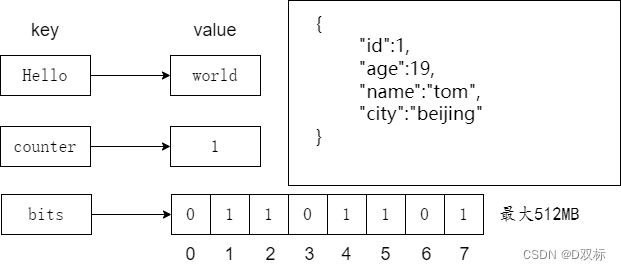
Wie in der Abbildung oben gezeigt, kann der Wert des Zeichenfolgentyps tatsächlich eine Zeichenfolge (einfache Zeichenfolge, komplexe Zeichenfolge (z. B. JSON, XML)), eine Zahl (Ganzzahl, Gleitkommazahl) oder sogar eine Binärzahl (Bild, Audio, video ), aber der Maximalwert darf 512 MB nicht überschreiten.
Befehl
Es gibt viele Befehle vom Typ Zeichenfolge. In diesem Artikel werden sie in zwei Dimensionen erläutert: häufig verwendet und ungewöhnlich. Allerdings sind häufig verwendete und ungewöhnliche Befehle hier relativ, sodass dies nicht bedeutet, dass sie nicht verstanden werden müssen, wenn sie nicht häufig verwendet werden .
Eine Zusammenfassung verwandter Befehle kann in der Verwendung von Redis eingesehen werden .
Allgemeine Befehle
(1) Einstellwert
set key value [ex seconds] [px milliseconds] [nx|xx]Die folgende Operation wird auf „Hallo“ gesetzt und der Wert ist das Schlüssel-Wert-Paar von „world“. Das Rückgabeergebnis ist „OK“, was bedeutet, dass die Einstellung erfolgreich ist.
![]()
Der Set-Befehl bietet mehrere Optionen:
- ex Sekunden: Legen Sie die Ablaufzeit der zweiten Ebene für den Schlüssel fest.
- px Millisekunden: Legen Sie die Ablaufzeit in Millisekunden für den Schlüssel fest.
- nx: Der Schlüssel darf nicht vorhanden sein, bevor er erfolgreich festgelegt und zum Hinzufügen verwendet werden kann.
- xx: Im Gegensatz zu nx muss der Schlüssel existieren, bevor er erfolgreich gesetzt und für Updates verwendet werden kann.
- Zusätzlich zur Set-Option bietet Redis auch zwei Befehle: setex und setnx:
setex key seconds value setnx key valueIhre Funktionen sind die gleichen wie die der Optionen ex und nx. Das folgende Beispiel veranschaulicht den Unterschied zwischen set, setnx und set xx.
Zuerst das Beispiel von setnx:

Wenn der Schlüssel, den wir erstellen möchten, nicht vorhanden ist, können wir feststellen, dass wir ihn mit dem Befehl setnx erfolgreich erstellen können. Wenn der Schlüssel, den wir erstellen möchten, jedoch bereits vorhanden ist, können wir ihn mit dem Befehl setnx nicht erstellen.
Satz:

Im Vergleich zu setnx können wir feststellen, dass der Unterschied zwischen set und setnx darin besteht, dass setnx nicht erfolgreich erstellt werden kann, wenn der Schlüssel, den wir erstellen möchten, bereits vorhanden ist, set aber dennoch erfolgreich erstellt werden kann.
Satz xx:

Aus der Abbildung können wir ersehen, dass bei Verwendung von Set xx nur vorhandene Schlüssel erfolgreich erstellt werden können. Wenn der Schlüssel, den wir erstellen möchten, nicht vorhanden ist, schlägt die Erstellung fehl.
Was sind also die tatsächlichen Anwendungsszenarien von setnx und set xx? manche.
Aufgrund des Single-Thread-Befehlsverarbeitungsmechanismus von Redis kann, wenn mehrere Clients den Setnx-Schlüsselwert gleichzeitig ausführen, gemäß den Eigenschaften von Setnx nur ein Client ihn erfolgreich festlegen. Setnx kann als Implementierungslösung für verteilte Sperren verwendet werden . Redis bietet offiziell die Möglichkeit, verteilte Sperren mit setnx zu implementieren: http://redis.io/topics/distlock
In manchen Fällen möchten Sie möglicherweise nur dann einen Schlüssel aktualisieren, wenn er bereits vorhanden ist, um sicherzustellen, dass kein neuer Schlüssel erstellt wird, wenn er ungültig ist. SET key value XXDer Befehl stellt sicher, dass der Wert nur aktualisiert wird, wenn der Schlüssel vorhanden ist.
(2) Wert erhalten
get key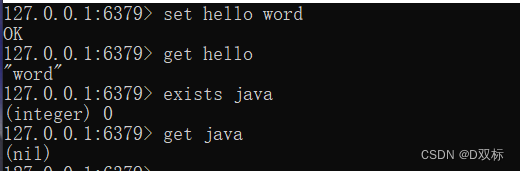
Aus der Abbildung können wir ersehen, dass wir den Wert des Schlüssels erhalten können, wenn der Schlüssel vorhanden ist. Wenn der erhaltene Schlüssel nicht vorhanden ist, wird Null (leer) zurückgegeben.
(3) Batch-Einstellungswerte und Batch-Erhaltwerte
mset key value [key value ...]
mget key1 key2 ....
Es kann festgestellt werden, dass, wenn einige Schlüssel nicht vorhanden sind, Null (leer) zurückgegeben wird und das Ergebnis in der Reihenfolge der übergebenen Schlüssel zurückgegeben wird.
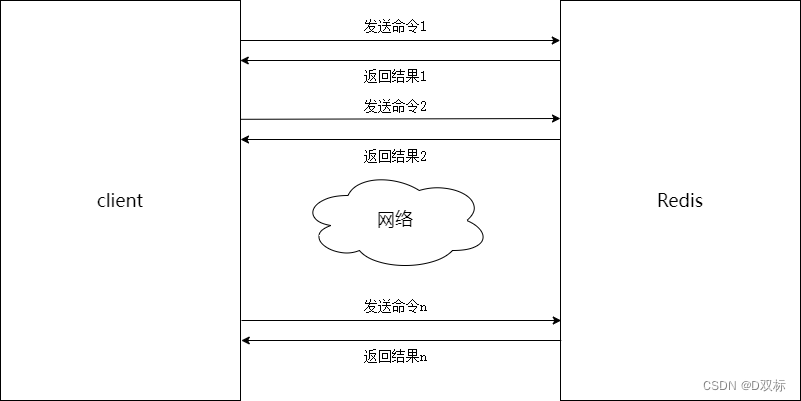
Batch-Operationsbefehle können die Effizienz der Entwicklung effektiv verbessern. Wenn es keinen Befehl wie mget gibt, muss der Get-Befehl zum n-maligen Ausführen wie in der folgenden Abbildung ausgeführt werden. Der spezifische Zeitverbrauch ist wie folgt:
n-mal Get-Zeit = n-mal Netzwerkzeit + n-mal Befehlszeit
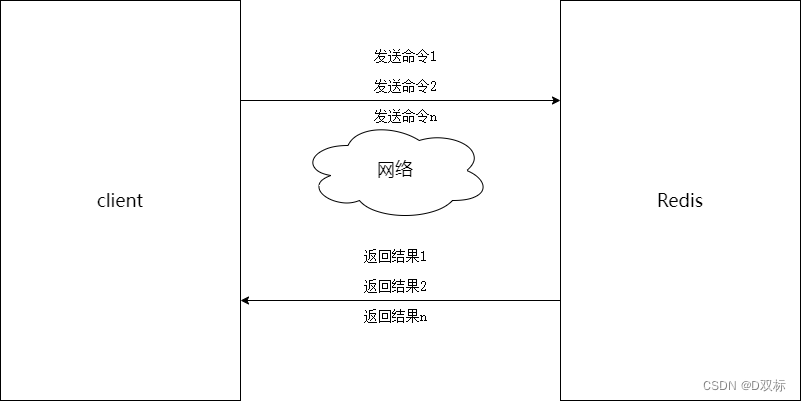
Nachdem Sie den Befehl mget verwendet haben, müssen Sie ihn nur wie unten gezeigt ausführen, um ihn n-mal auszuführen. Die spezifischen Vorteile sind wie folgt:
n Get-Zeiten = 1 Netzwerkzeit + n Befehlszeiten
Redis kann Zehntausende Lese- und Schreibvorgänge pro Sekunde ausführen, dies bezieht sich jedoch auf die Verarbeitungskapazität des Redis-Servers. Für den Client verfügt ein Befehl zusätzlich zur Befehlszeit auch über Netzwerkzeit. Nehmen wir an, dass die Netzwerkzeit beträgt 1 ms beträgt und die Befehlszeit 0,1 ms beträgt (berechnet basierend auf der Verarbeitung von 1 W Befehlen pro Sekunde), dann ist der Unterschied zwischen der Ausführung von 1000 get-Befehlen und einem mget-Befehl wie folgt:
| arbeiten | Zeit |
| 1000 mal bekommen | 1000 × 1 + 1000 × 0,1 = 1100 ms = 1,1 s |
| 1 mget (zusammengestellt aus 1000 Schlüssel-Wert-Paaren) | 1 × 1 + 1000 × 0,1 = 101 ms = 0,101 s |
Da die Verarbeitungsleistung von Redis hoch genug ist, kann das Netzwerk für Entwickler zu einem Leistungsengpass werden. Das Erlernen der Verwendung von Batch-Vorgängen trägt zur Verbesserung der Geschäftsverarbeitungseffizienz bei, es sollte jedoch darauf geachtet werden, welche Befehle für jeden Batch-Vorgang gesendet werden Die Anzahl ist nicht unbegrenzt. Wenn die Anzahl zu groß ist, kann es zu einer Redis-Überlastung oder einer Netzwerküberlastung kommen.
(4) Zählen
incr keyDer Befehl incr wird verwendet, um Inkrementierungsoperationen für Werte durchzuführen. Die zurückgegebenen Ergebnisse sind in drei Situationen unterteilt:
- Der Wert ist keine Ganzzahl, es wird ein Fehler zurückgegeben.
- Es ist nur eine Ganzzahl und gibt das Ergebnis nach der Inkrementierung zurück.
- Wenn der Schlüssel nicht vorhanden ist, wird er entsprechend dem Wert 0 erhöht und das zurückgegebene Ergebnis ist 1.
Wenn beispielsweise der Incr-Befehl auf einem nicht vorhandenen Schlüssel ausgeführt wird, ist das Rückgabeergebnis 1. Wenn der Incr-Befehl erneut auf dem Schlüssel ausgeführt wird, ist das Rückgabeergebnis 2. Wenn der Wert keine Ganzzahl ist, wird ein Fehler angezeigt ist zurückgekommen. Wie im Bild gezeigt:
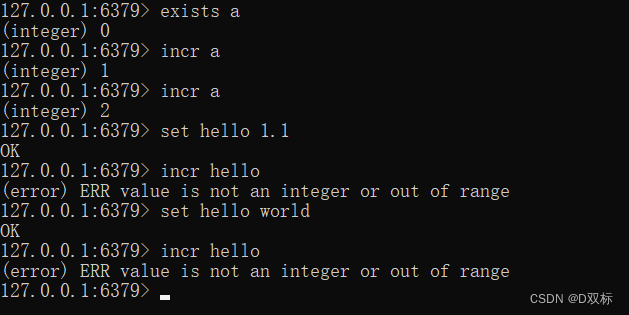
Zusätzlich zum Befehl incr bietet Redis decr (automatische Dekrementierung), incrby (automatische Inkrementierung auf eine angegebene Zahl), decrby (automatische Dekrementierung auf eine angegebene Zahl) und incrbyfloat (automatische Inkrementierung einer Gleitkommazahl). :
decr key
incrby key increment
decrby key increment
incrbyfloat key incrementViele Speichersysteme und Programmiersprachen verwenden den CAS-Mechanismus intern, um Zählfunktionen zu implementieren, was einen gewissen CPU-Overhead verursacht. Dieses Problem besteht jedoch bei Redis nicht, da Redis eine Single-Thread-Architektur ist und jeder Befehl erforderlich ist sequentiell ausgeführt werden, wenn es den Redis-Server erreicht.
Ungewöhnlich verwendete Befehle
(1) Mehrwert
append key valueappend kann einen Wert an das Ende einer Zeichenfolge anhängen, zum Beispiel:
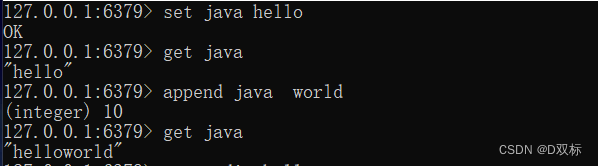
(2) Stringlänge
strlen key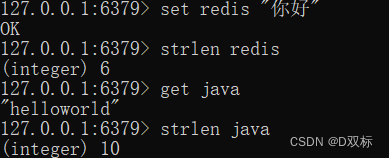
Aus dem Bild können wir ersehen, dass der Schlüssel Redis 6 Bytes belegt, da ein chinesisches Zeichen in Redis drei Bytes belegt.
(3) Stellen Sie den ursprünglichen Wert ein und geben Sie ihn zurück
getset key valuegetset setzt den Wert wie set, der Unterschied besteht jedoch darin, dass es auch den ursprünglichen Wert des Schlüssels zurückgibt, zum Beispiel:

(4) Setzen Sie das Zeichen an die angegebene Position
setrange key offset valueDie folgende Operation ändert den Wert von hello in fallo
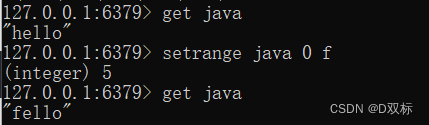
(5) Holen Sie sich einen Teil der Zeichenfolge
getrange key start end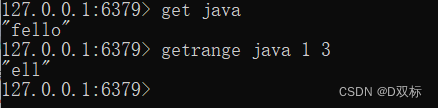
Start und Ende sind die Offsets von Start bzw. Ende. Der Offset wird von 0 aus berechnet. Beispielsweise erhält die Operation in der obigen Abbildung die Elle in der Mitte des Werts Fello.
Zeitkomplexität des Befehls vom Typ String
| Befehl | Zeitkomplexität |
| Schlüsselwert festlegen | O(1) |
| Schlüssel holen | O(1) |
| Entf-Taste [Taste ...] | O(k), k ist die Anzahl der Schlüssel |
| mset-Schlüsselwert [Schlüsselwert ...] | O(k), k ist die Anzahl der Schlüssel |
| mget-Schlüssel [Schlüssel ...] | O(k), k ist die Anzahl der Schlüssel |
| Incr-Taste | O(1) |
| Decr-Taste | O(1) |
| incrby Schlüsselinkrement | O(1) |
| Decrby-Schlüsselinkrement | O(1) |
| incrbyfloat-Schlüsselinkrement | O(1) |
| Schlüsselwert anhängen | O(1) |
| Strlen-Taste | O(1) |
| Setrange-Tasten-Offset-Wert | O(1) |
| Getrange-Taste Start Ende | O (n), n ist die Länge der Zeichenfolge. Da die Zeichenfolge sehr schnell erhalten wird, kann sie als O (1) betrachtet werden, wenn die Zeichenfolge nicht sehr lang ist. |
interne Kodierung
Es gibt drei interne Codierungen für String-Typen:
- int: 8 Byte lange Ganzzahl.
- embstr: Eine Zeichenfolge von weniger als oder gleich 39 Byte.
- raw: Eine Zeichenfolge, die größer als 39 Byte ist.
Redis entscheidet anhand des Typs und der Länge des aktuellen Werts, welche interne Codierungsimplementierung verwendet werden soll.
Beispiele sind wie folgt:
# 整数类型示例
127.0.0.1:6379> set key 8653
OK
127.0.0.1:6379> object encoding key
"int"
# 短字符串示例
# 小于等于39个字节的字符串:embstr
127.0.0.1:6379> set key "hello world"
OK
127.0.0.1:6379> object encoding key
"embstr"
# 长字符串示例
# 大于39个字节的字符串:raw
127.0.0.1:6379> set key "one string greater than 39 byte .................................."
OK
127.0.0.1:6379> object encoding key
"raw"
127.0.0.1:6379> strlen key
(integer) 66Typische Nutzungsszenarien
1. Caching-Funktion
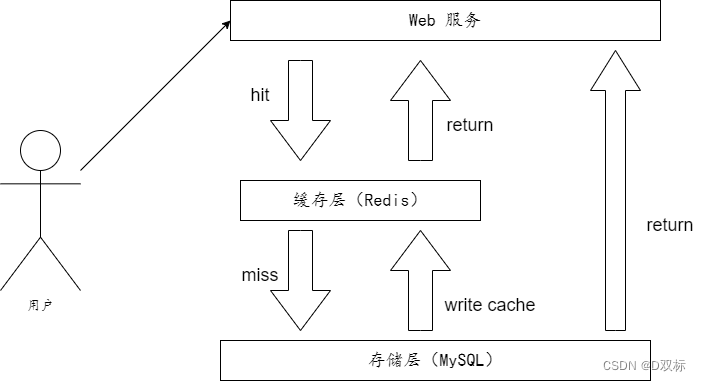
Wie oben gezeigt, handelt es sich um ein typisches Cache-Nutzungsszenario, bei dem Redis als Cache-Schicht und MySQL als Speicherschicht dient. Die meisten angeforderten Daten werden von Redis bezogen. Da Redis über die Eigenschaften verfügt, eine hohe Parallelität zu unterstützen, kann Caching normalerweise dazu beitragen, das Lesen und Schreiben zu beschleunigen und den Back-End-Druck zu verringern.
Der folgende Pseudocode simuliert den Zugriffsvorgang in der obigen Abbildung:
// 假设有一个函数getUserInfo,通过传入的id,获取用户信息
UserInfo getUserInfo(Long id){
// 首先从Redis中获取用户信息:
// 定义键
userRedisKey = "user:info:" + id;
// 从Redis中获取值
value = redis.get(userRedisKey);
// 如果没有从Redis中获取到用户信息,需要从MySQL中进行获取,并将结果回写到Redis,添加1小时(3600)过期时间;
UserInfo userInfo;
if (value != null) {
userInfo = deserialize(value);
} else{
// 从MySQL中获取用户信息
userInfo = mysql.get(id);
if(userInfo != null)
// 将userInfo序列化,并存入Redis中
redis.setex(userRedisKey, 3600, serialize(userInfo));
}
// 返回结果
return userInfo;
}2. Zählen
Viele Anwendungen verwenden Redis als grundlegendes Tool zum Zählen. Es kann schnelle Zähl- und Abfrage-Caching-Funktionen implementieren und Daten können asynchron in andere Datenquellen eingespeist werden. Es kann beispielsweise in einem System zur Anzahl der Videowiedergaben verwendet werden. Sie können Redis als Basiskomponente zum Zählen der Anzahl der Videowiedergaben verwenden. Jedes Mal, wenn ein Benutzer ein Video abspielt, erhöht sich die entsprechende Anzahl der Videowiedergaben um 1.
3. Geschwindigkeitsbegrenzung
Aus Sicherheitsgründen werden Benutzer häufig aus Sicherheitsgründen bei jeder Anmeldung aufgefordert, einen Mobiltelefon-Bestätigungscode einzugeben, um festzustellen, ob sie selbst der Benutzer sind. Um jedoch zu verhindern, dass häufig auf die SMS-Schnittstelle zugegriffen wird, wird die Häufigkeit, mit der Benutzer pro Minute Verifizierungscodes erhalten, begrenzt, beispielsweise nicht mehr als fünf Mal pro Minute. Wie im Bild gezeigt:
![]()
Diese Funktion kann mit Redis implementiert werden. Der folgende Pseudocode gibt die grundlegende Implementierungsidee wieder:
String phoneNum = "188xxxxxxxx"
String key = "shortMsg:limit:" + phoneNum
// SET Key EX 60 NX
isExists = redis.set(key, 1 "EX 60", "NX")
if (isExists != null || redis.incr(key)<=5){
// 通过
}else{
// 限速
}Das Obige stellt die Verwendung von Redis zum Implementieren der Geschwindigkeitsbegrenzungsfunktion dar. Wenn beispielsweise eine Website den Zugriff auf eine IP-Adresse mehr als n-mal pro Sekunde einschränkt, kann eine ähnliche Idee verwendet werden.
Zusätzlich zu den oben vorgestellten zentralisierten Anwendungsszenarien gibt es für Strings viele anwendbare Szenarien. Entwickler können ihrer Fantasie freien Lauf lassen, indem sie die relevanten Befehle kombinieren, die von Strings bereitgestellt werden.
2、Hash
Fast alle Programmiersprachen bieten Hash-Typen, die als Hashes, Wörterbücher und assoziative Arrays bezeichnet werden können. In Redis bezieht sich der Hash-Typ auf den Schlüsselwert selbst, der eine Schlüssel-Wert-Paarstruktur in der Form value={ { field1:value},....,{fieldn, valuen}}, Redis-Schlüsselwert ist Paar und Hash Die Beziehung zwischen den beiden Typen kann durch die folgende Abbildung dargestellt werden.

Befehl
Eine Zusammenfassung verwandter Befehle kann in der Verwendung von Redis eingesehen werden .
(1) Einstellwert
hset key field value(2) Wert erhalten
hget key field(3) Feld löschen
hdel key field [field ...](4) Berechnen Sie die Anzahl der Felder
hlen key(5) Feldwerte stapelweise festlegen oder abrufen
hmget key field [field ...]
hmset key field value [field value ...]
(6) Bestimmen Sie, ob das Feld vorhanden ist
hexists key field(7) Holen Sie sich alle Felder
hkeys key(8) Holen Sie sich alle Werte
hvals key(9) Alle Feldwerte abrufen
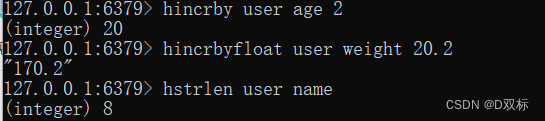
hgetall key(10)hincrby bincrbyfloat
hincrby key field increment
hincrbyfloadt key field increment(11) Berechnen Sie die Zeichenfolgenlänge des Werts (erfordert Redis3.2 oder höher).
hstrlen key field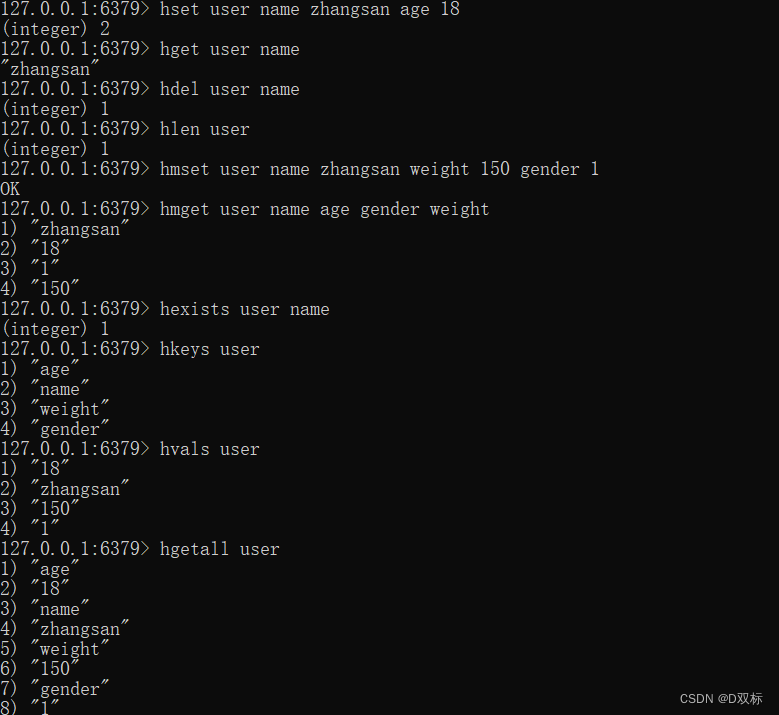
Die folgende Tabelle beschreibt die zeitliche Komplexität von Befehlen vom Typ Hash
| Befehl | Zeitkomplexität |
| hset-Schlüsselfeldwert | O(1) |
| hget-Schlüsselfeld | O(1) |
| HDEL-Schlüsselfeld [Feld ...] | O(k), k ist die Anzahl der Felder |
| hlen Schlüssel | O(1) |
| hgetall-Schlüssel | O(n), n ist die Gesamtzahl der Felder |
| hmget-Feld [Feld ...] | O(k), k ist die Anzahl der Felder |
| hmset-Feldwert [Feldwert ...] | O(k), k ist die Anzahl der Felder |
| Hexists-Schlüsselfeld | O(1) |
| hkeys-Schlüssel | O(n), n ist die Gesamtzahl der Felder |
| hvals-Schlüssel | O(n), n ist die Gesamtzahl der Felder |
| hsetnx-Schlüsselfeldwert | O(1) |
| Hincrby-Schlüsselfeldwert | O(1) |
| Hincrbyfloat-Schlüsselfeldinkrement | O(1) |
| hstrlen-Schlüsselfeld | O(1) |
interne Kodierung
Es gibt zwei interne Kodierungen für Hash-Typen:
- ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
- hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
1、当field个数比较少且没有大的value时,内部编码为ziplist。
2、当有value大于64字节,内部编码会有ziplist变为hashtable。
3、当field个数超过512,内部编码也会有ziplist变为hashtable。
但是在实际操作中我们会发现哈希内部的编码是listpack,既不是ziplist,也不是hashtable,如图:
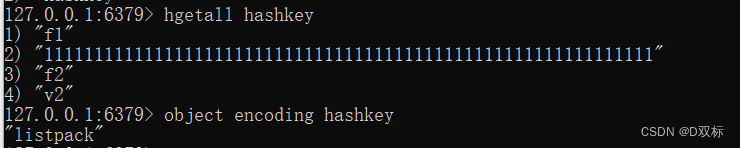
这是因为Redis 在内部自动进行了编码转换,将哈希键的编码方式从哈希表(hashtable)转换为 Listpack。这是 Redis 为了优化内存使用和性能而采取的一种策略。
当哈希键的大小和字段的大小满足一定条件时,Redis 会自动选择将其编码方式从哈希表转换为 Listpack。Listpack 是一种紧凑的二进制格式,用于存储键值对,类似于 Redis 中的列表(List)数据结构。这种转换可以减少内存占用并提高一些操作的性能。
虽然哈希键的内部编码方式显示为 "listpack",但用户仍然可以使用通常的哈希操作命令来访问和操作哈希键的数据,就像它们仍然是哈希表一样。这种编码方式的转换是 Redis 内部的优化策略,对于用户来说,不需要直接操作 Listpack。
那什么情况下会发生这样的事情呢?
Redis 会自动选择将哈希键(Hash Key)的编码方式从哈希表(hashtable)转换为 Listpack 编码方式的情况通常涉及以下条件:
-
哈希键的大小:当哈希键包含的字段数量相对较少,并且字段的大小适中时,Redis 可能会考虑将其编码方式转换为 Listpack。具体的阈值可能因 Redis 的版本和配置而有所不同。
-
字段的大小:如果哈希键的字段的键和值的大小都比较小,那么 Redis 更有可能选择 Listpack 编码方式。
-
哈希键的使用模式:哈希键的使用模式也会影响 Redis 的编码选择。如果哈希键主要用于插入、删除或迭代操作,并且不需要频繁的哈希键查找操作,那么 Listpack 编码方式可能更合适。
-
内存优化策略:Redis 会考虑系统的内存状况和性能,以决定是否切换编码方式。它的目标是提高内存使用效率和执行操作的速度。
需要注意的是,Redis 的编码方式转换是自动进行的,用户无需干预。Redis 会根据上述条件自动选择合适的编码方式以提高性能和内存利用率。这个转换是 Redis 的内部优化机制,它使 Redis 能够在不同情况下充分利用内存,并提供高性能。
如果您想了解特定版本的 Redis 在何时选择转换编码方式以及如何调整这些条件,请参考该版本的 Redis 文档或源代码。不同版本的 Redis 可能会在这方面有些许不同。
使用场景
相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对field-value对应每个用户的属性。
但是需要注意的是哈希类型和关系数据库有两点不同之处:
- 哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的field,二关系型数据库一旦添加新的列,所有行都要为其设置值(即使为NULL)。
- 关系型数据库可以做复杂的关系查询,去模拟关系型复杂查询开发困难,维护成本高。
到目前为止,我们已经给出三种方法缓存用户信息,如下:
1、原生字符串类型:每个属性一个键
set user:1:name tom
set user:1:age 23
set user:1:city beijing优点:简单直观,每个属性都支持更新操作。
缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以这种方式一般不会在生产环境中使用。
2、序列化字符串类型:将用户信息序列化后用一个键保存。
set user:1 serialize(userInfo)优点:简化编程,如果合理的使用序列化可以提高内存的使用率。
缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出来进行反序列化,更新后再序列化到Redis中。
3、哈希类型:每个用户属性使用一对field-value,但是只用一个键保存。
hmset user:1 name tom age 23 city beijing优点:简单直观,如果使用合理可以减少内存空间的使用。
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
3、List
列表(list)类型是用来存储多个有序的字符串的,可以理解为是一个双向链表。

如上图中第一个列表所示,a、b、c、d、e五个元素从左到右组成了一个有序的列表,列表中的每个字符串被称为元素,一个列表最多可以存储2^32-1个元素。在Redis中,可以对列表两端插入和弹出,还可以获取指定范围内的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,他可以充当栈和队列的角色,在实际开发上有很多应用场景。
列表类型有两个特点:第一、列表中的元素是有序的,这就意味着可以通过索引下标来获取某个元素或者某个范围内的元素列表如上图的第二个列表所示。第二,列表中的元素可以是重复的。
命令
相关命令的汇总可以前往Redis的使用进行查看
基本命令
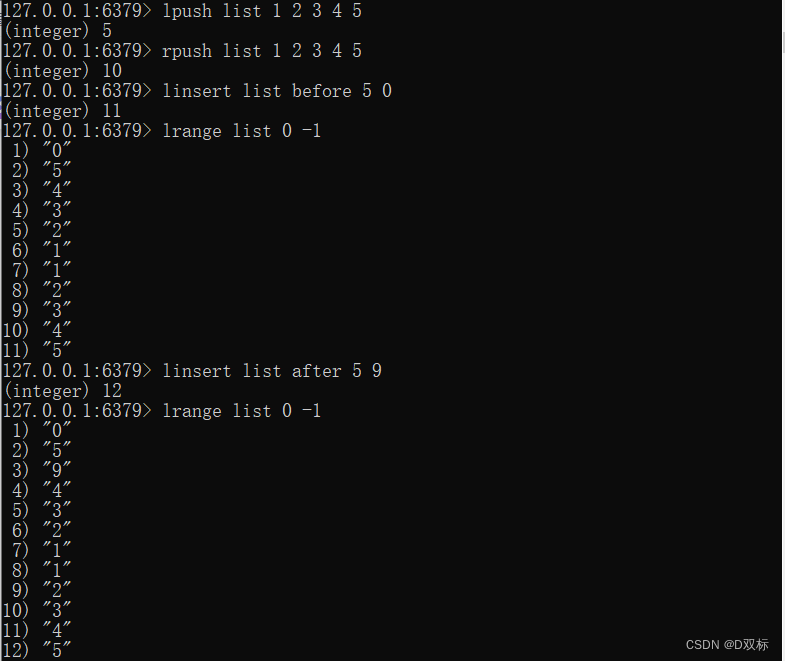
# 从左/右边插入元素
lpush/rpush key value [value ...]
# 向某个元素前或者后插入元素
linsert key before/after pivot value
# 获取指定范围内的元素列表
lrange key start end
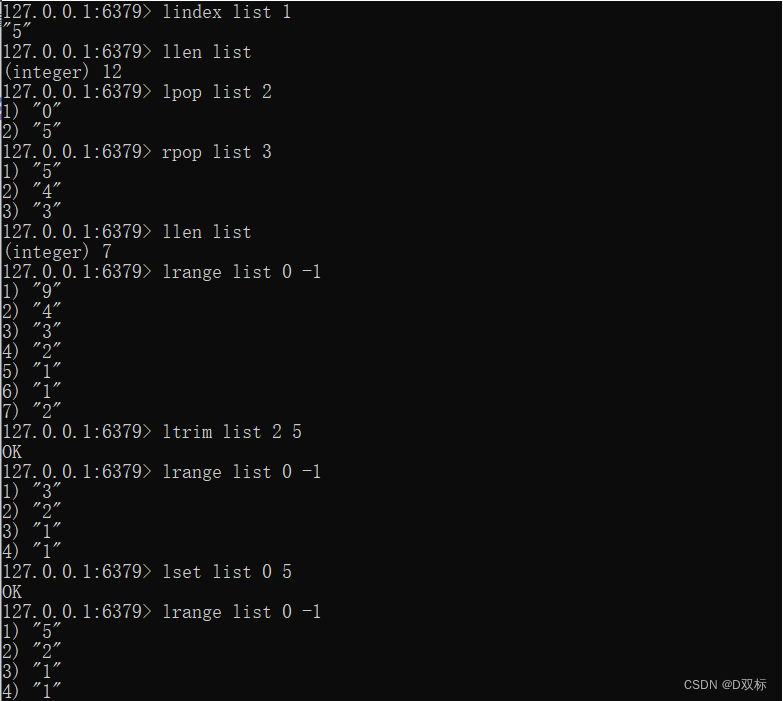
# 获取列表指定索引下标的元素
lindex key index
# 获取列表长度
llen key
# 从左/右侧弹出元素
lpop/rpop key
# 按照索引范围修剪列表
ltrim key start end
# 修改指定索引下标的元素
lset key index newValue
删除元素命令
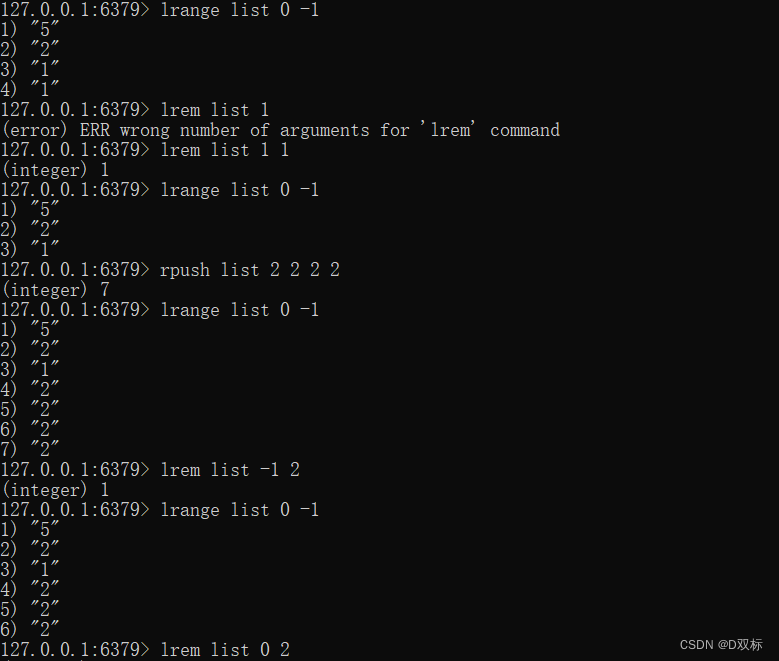
# 删除指定元素
lrem key count valuelrem命令会从列表中找到等于value的元素进行删除,根据count的不同分为如下情况:
- count>0,从左到右,删除最多count个元素。
- count<0,从右到左,删除最多count绝对值个元素。
- count=0,删除所有。

阻塞式弹出
# 阻塞式弹出
blpop key [key ...] timeout
brpop key [key ...] timeoutblpop与brpop是lpop和rpop的阻塞版本,它们除了弹出的方向不同,使用方法基本相同,所以下面以brpop命令进行说明,brpop命令包含2个参数:
- key [key ...]:多个列表的键。
- timeout:阻塞时间(单位:秒)。
- 列表为空:如果timeout=3,那么客户要等到3秒结束后返回,如果timeout=0,那么客户端一直阻塞下去。
client1:
此时如果另一个客户端在该列表里添加了数据则: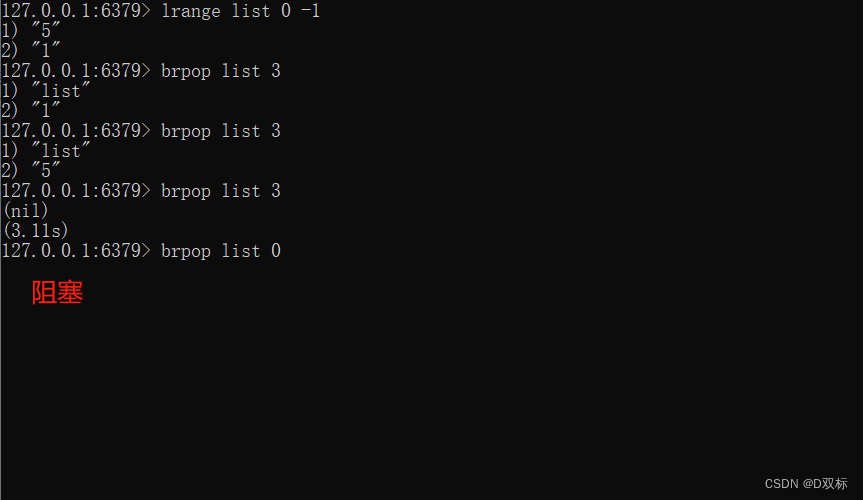
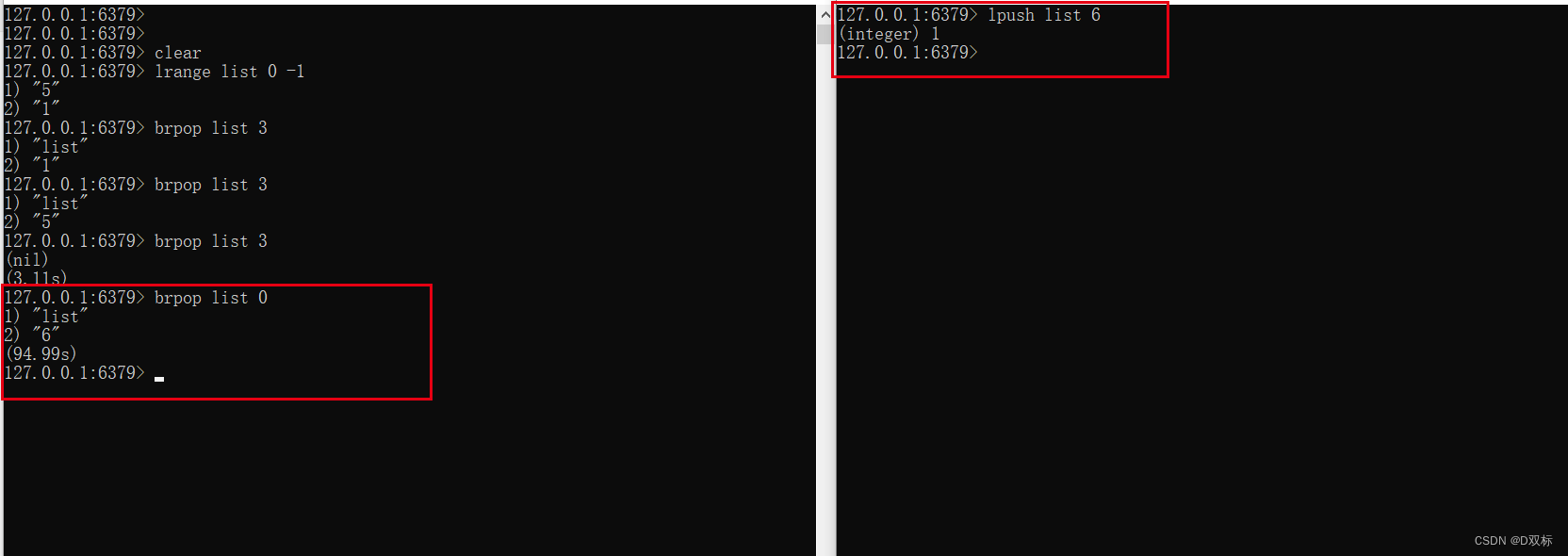
- 列表不为空:客户端会立即返回。

在使用brpop时需要注意两个点:
- 如果是多个键,那么brpop会从左至右遍历键,一旦有一个键能弹出元素,客户端会立即返回。

- 如果多个客户端对同一个键执行brpop,那么最先执行brpop命令的客户端可以获取到弹出的值。
下表描述的是列表类型命令的时间复杂度
| 操作类型 | 命 令 | 时间复杂度 |
|---|---|---|
| 添加 | rpush key value [value ....] | O(k),k是元素个数 |
| lpush key value [value ....] | O(k),k是元素个数 | |
| linsert key before | after pivot value | O(n),n是pivot距离列表头或尾的距离 | |
| 查找 | lrange key start end | O(s+n),s是start偏移量,n是start到end的范围 |
| lindex key index | O(n),n是索引的偏移量 | |
| llen key | O(1) | |
| 删除 | lpop key | O(1) |
| rpop key | O(1) | |
| lrem count value | O(n),n是列表长度 | |
| ltrim key start end | O(n),n是要裁剪的元素总数 | |
| 修改 | lset key index value | O(n),n是索引的偏移量 |
| 阻塞操作 | blpop brpop | O(1) |
内部编码
列表的类型的内部编码有两种:
- ziplist(压缩列表):列表内部的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时(默认64字节),Redis会选用ziplist来作为列表内部实现来减少内存的使用。
- linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
- quicklist(快速列表):考虑到链表的附加空间相对太高,prev 和 next 指针就要占去 16 个字节 (64bit 系统的指针是 8 个字节),另外每个节点的内存都是单独分配,会加剧内存的碎片化,影响内存管理效率。因此Redis3.2版本开始对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist
快速列表
quicklist 实际上是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。

详情介绍可以前往https://www.cnblogs.com/hunternet/p/12624691.html

使用场景
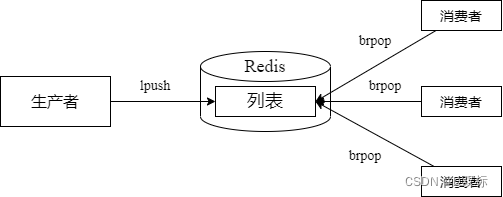
1)消息队列
Redis中的lpush+brpop命令组合可以实现阻塞队列,生产者客户端用lrpish从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
2)文章列表
每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
-
每篇文章使用户哈希结构存储,例如每篇文章有三个属性,title、timestamp、content。
-
向文章列表添加文章,user:{id}:articles作为用户文章列表的键。
-
分页获取用户文章列表。

# 伪代码
articles = lrange user:1:article 0 9
for article in {articles}:
hgetall {article}
lpush + lpop = Stack(栈)
lpush + rpop = Queue(队列)
lpush + ltrim = Capped Collection(集合)
lpush + brpop = Message Queue(消息队列)
4、Set
待更新
5、ZSet
待更新
6、BitMaps
待更新
7、HypeLogLog
ausstehendes Upgrade
8、GEO
ausstehendes Upgrade