NoSQL-bezogene Kenntnisse
- 1. Die Entwicklung von eigenständigem MySQL
- 2. Überblick über NoSQL
- Drei, 3V + 3 hoch
- 4. Technischer Überblick
- 5. Vier Kategorien von NoSQL
1. Die Entwicklung von eigenständigem MySQL
1. Eigenständiges MySQL (Evolution 1)
1.1 Benutzerzugriffsprozess
APP——>DAL——>Mysql

1.2 Hintergrund
Der Traffic einer einfachen Website ist in der Regel nicht allzu groß und eine einzelne Datenbank reicht völlig aus.
2. Cache (Evolution 2)
2.1 Struktur
Memcached (Caching) + MySQL + vertikale Aufteilung
2.2 Einführung
Da 80 % der Website gelesen werden, ist jede Abfrage sehr mühsam. Um den Datendruck zu verringern, können Sie den Cache verwenden, um die Effizienz sicherzustellen.
2.3 Entwicklungsprozess
Datenstruktur und Index optimieren -> Dateicache (IO) -> Memcached (das heißeste Jahr)
2.4 Funktionen
Realisieren Sie die Lese-/Schreibtrennung und das Caching
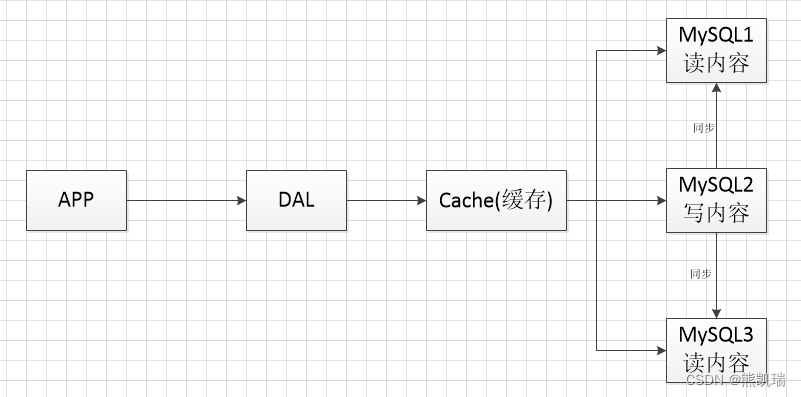
3. Cluster (Evolution 3)
3.1 Struktur
Unterdatenbank und Tabelle + horizontale Aufteilung + MySQL-Cluster + Cache
3.2 Einführung
MyISAM: Tabellensperren wirken sich stark auf die Effizienz aus und bei hoher Parallelität treten schwerwiegende Sperrprobleme auf.
Innodb: Zeilensperren
3.3 Prozess
Verwenden Sie Unterdatenbanken und Untertabellen, um den Schreibdruck zu lösen, und MySQL führt auch das Konzept der Tabellenpartition ein
3.4 Funktion
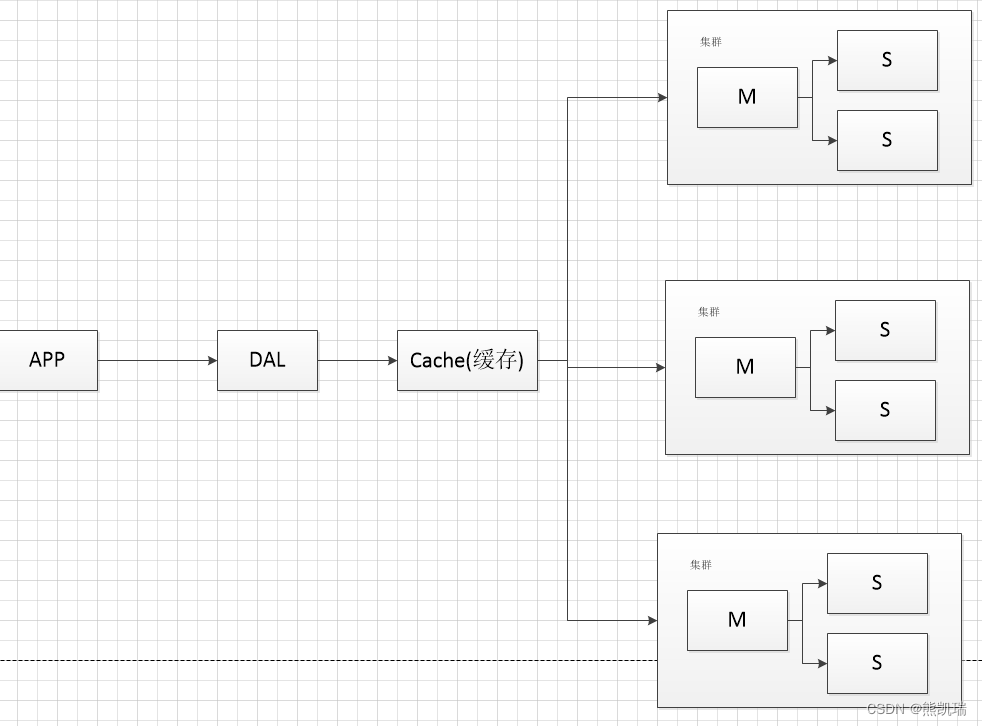
4. jetzt
4.1 Struktur
Lastausgleich + Unterdatenbank und Untertabelle + horizontale Aufteilung + MySQL-Cluster + Cache + verschiedene Server
4.2 Hintergrund
Die Datenmenge ist groß und ändert sich schnell, und relationale Datenbanken wie MySQL reichen nicht aus.
4.3 Funktion
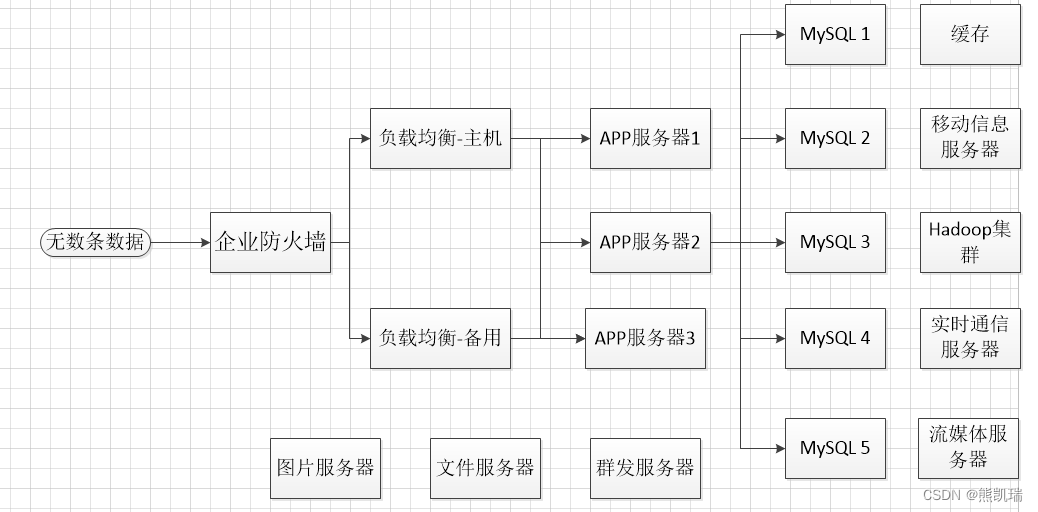
2. Überblick über NoSQL
1. Einleitung
NoSQL bezieht sich im Allgemeinen auf nicht relationale Datenbanken. Mit der Geburt des Web 2.0-Internets ist es für herkömmliche relationale Datenbanken schwierig, große Communities mit hoher Parallelität zu verwalten. Daher entwickelt sich NoSQL in der aktuellen Big-Data-Umgebung rasant weiter. (Viele Datentypen sind persönliche Informationen des Benutzers, soziale Netzwerke und geografische Standorte. Für die Speicherung dieser Datentypen ist kein festes Format erforderlich.)
2. Funktionen
(1) Einfach zu erweitern (keine Beziehung zwischen Daten, einfach zu erweitern)
(2) Großes Datenvolumen und hohe Leistung (Redis schreibt 80.000 Mal pro Sekunde, liest 110.000 und die Cache-Datensatzebene von NoSQL ist ein feinkörniger Cache, die Leistung wird relativ hoch sein)
(3) Der Datentyp ist vielfältig (keine Notwendigkeit, die Datenbank im Voraus zu entwerfen, nehmen Sie sie einfach und verwenden Sie sie)
3. Der Unterschied zwischen RDBMS und NoSQL
3.1 RDBMS (Relationale Datenbank)
Strukturierte Organisation, SQL, Daten und Beziehungen werden in separaten Tabellen gespeichert, befolgen ACID-Regeln usw.
3.2 NoSQL (nicht relationale Datenbank)
Bei der Speicherung handelt es sich nicht nur um Daten, es gibt keine feste Abfragesprache, keinen Schlüssel-Wert-Paar-Speicher, keinen Spaltenspeicher, keinen Dokumentenspeicher, keine
eventuelle Konsistenz der Diagrammdatenbank, kein CAP-Theorem und keine BASE, keine hohe Leistung, keine hohe Verfügbarkeit und keine hohe Skalierbarkeit.
Drei, 3V + 3 hoch
1. 3V im Zeitalter von Big Data
(1) Riesiges Volumen
(2) Vielfalt
(3) Echtzeitgeschwindigkeit
2. Drei Höhepunkte im Zeitalter von Big Data
(1) Hohe Parallelität
(2) Hohe Skalierbarkeit
(3) Hohe Leistung
4. Technischer Überblick
1. Grundlegende Produktinformationen
1.1 Szenarien
Name, Preis, Geschäftsinformationen
1.2 Technologie
Relationale Datenbank (MySQL/Oracle)
2. Produktbeschreibung und Kommentare
2.1 Szenarien
mehr Text
2.2 Technologie
Dokumentendatenbank (MongoDB)
3. Bilder
3.1 Szenarien
Bild speichern
3.2 Technologie
Verteiltes Dateisystem FastDFS
Taobao-Dateisystem TFS
Google-Dateisystem GFS
Hadoop-Dateisystem HDFS
Alibaba Cloud-Dateisystem OSS
4. Die Schlüsselwörter des Produkts
4.1 Szenarien
suchen
4.2 Technologie
Suchmaschinen Solr, Elasticsearch, ISerach
5. Bandinformationen beliebter Produkte
5.1 Szenarien
Produktverkäufe
5.2 Technologie
Speicherdatenbank Redis, Tair, Memache...
6. Warentransaktionen, externe Zahlungsschnittstelle
Drei-Parteien-Antrag
5. Vier Kategorien von NoSQL
1. KV-Schlüssel-Wert-Paar
1.1 Beispiel
Sina: Redis
Meituan: Redis + Tair
Ali, Baidu: Redis + Memecache
1.2 Anwendungsszenarien
Inhaltscaching wird hauptsächlich zur Bewältigung hoher Zugriffslasten großer Datenmengen verwendet und wird auch in einigen Protokollsystemen usw. verwendet.
1.3 Datenmodell
Der Schlüssel weist auf das Schlüssel-Wert-Paar Wert hin, das normalerweise durch eine Hash-Tabelle implementiert wird.
1.4 Vorteile
schnelle Suche
1.5 Nachteile
Die Daten sind unstrukturiert und werden normalerweise nur als Zeichenfolgen- oder Binärdaten behandelt
2. Dokumentendatenbank (BSON-Format ist dasselbe wie JSON)
1.1 MongoDB、CouchDB
MongoDB ist eine Datenbank, die auf verteilter Dateispeicherung basiert. Sie ist in C++ geschrieben und wird hauptsächlich zur Verarbeitung einer großen Anzahl von Dokumenten verwendet.
MongoDB ist ein Zwischenprodukt zwischen relationalen Datenbanken und nicht relationalen Datenbanken. Wie eine relationale Datenbank.
1.2 Anwendungsszenarien
Webanwendung (ähnlich wie Schlüsselwert, Wert ist strukturiert, der Unterschied besteht darin, dass die Datenbank den Inhalt von Wert verstehen kann)
1.3 Datenmodell
Das Schlüssel-Wert-Paar, das Schlüsselwert und Wert entspricht, sind strukturierte Daten.
1.4 Vorteile
Die Anforderungen an die Datenstruktur sind nicht streng, die Tabellenstruktur ist variabel und es besteht keine Notwendigkeit, die Tabellenstruktur wie bei einer relationalen Datenbank vorab zu definieren.
1.5 Nachteile
Die Abfrageleistung ist nicht hoch und es fehlt eine einheitliche Abfragesyntax.
3. Spaltenspeicherdatenbank
3.1 Beispiel
HBase (Big Data)
3.2 Anwendungsszenarien
verteiltes Dateisystem
3.3 Datenmodell
In Spaltenclustern speichern, Daten zusammen in derselben Spalte speichern
3.4 Vorteile
Die Suchgeschwindigkeit ist hoch, die Skalierbarkeit ist hoch und die verteilte Erweiterung ist einfacher durchzuführen.
3.5 Nachteile
Relativ eingeschränkte Funktionen
4. Relationale Datenbank grafisch darstellen
Es handelt sich nicht um eine Datenbank, die Bilder speichert, sondern Beziehungen
4.1 Beispiel
Neo4J, InfoGrid, Infinite Graph
4.2 Anwendungsszenarien
Soziale Netzwerke, Empfehlungssysteme usw. mit Schwerpunkt auf dem Aufbau von Beziehungsdiagrammen
4.3 Datenmodell
Diagrammstruktur
4.4 Vorteile
Verwenden Sie Algorithmen, die sich auf die Graphstruktur beziehen, z. B. die Adressierung des kürzesten Pfads, die Suche nach N-Grad-Beziehungen usw.
4.5 Nachteile
In vielen Fällen ist es notwendig, das gesamte Diagramm zu berechnen, um die erforderlichen Informationen zu erhalten, und diese Struktur ist nicht einfach zu verteilen.