In diesem Artikel wird übrigens hauptsächlich die InnoDB-Speicher-Engine erläutert.
- Indexklassifizierung
Die Indexklassifizierung kann aus verschiedenen Dimensionen klassifiziert werden
1. Geteilt durch die verwendete Datenstruktur
-
B+-Baumindex
-
Hash-Index
-
…
2. Entsprechend der tatsächlichen Aufteilung der physischen Speicherdatenstruktur
-
Clustered-Index
-
Nicht gruppierter Index (Sekundärindex)
Auf gruppierte Indizes und nicht gruppierte Indizes wird später eingegangen.
3. Geteilt durch Indexmerkmale
-
Primärschlüsselindex
-
eindeutiger Index
-
normaler Index
-
Volltextindex
-
…
4. Teilen Sie durch die Anzahl der Felder
-
Einzelspaltenindex
-
Gelenkindex
- Indexdatenstruktur
2.1 Vorbereitung
Um den nächsten Artikel besser zu erklären, habe ich hier eine userTabelle vorbereitet. Die Beispiele des gesamten Artikels werden mit dieser Tabelle erläutert
CREATE TABLE `user` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(10) DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.2 Hash-Index
Hash-Indizes sind nicht sehr praktisch, vor allem weil InnoDB, die am weitesten verbreitete Speicher-Engine, die explizite Erstellung von Hash-Indizes nicht unterstützt, sondern nur adaptive Hash-Indizes.
Obwohl Sie die SQL-Anweisung verwenden können, um den Hash-Index in InnoDB anzuzeigen und zu deklarieren, ist sie tatsächlich nicht wirksam

Erstellen Sie einen Hash-Index für das Namensfeld, aber Sie show index from 表名werden feststellen, dass es sich tatsächlich um einen B + -Baum handelt
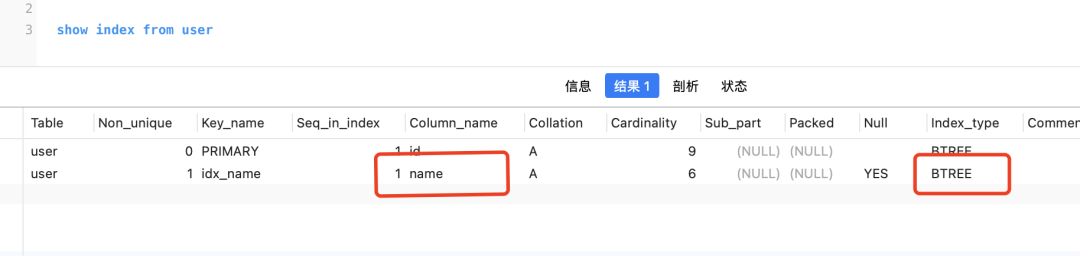
In der Speicher-Engine unterstützt die Speicher-Engine den Hash-Index
Der Hash-Index ähnelt eigentlich ein wenig der zugrunde liegenden Datenstruktur von HashMap in Java. Er verfügt außerdem über viele Slots, in denen auch Schlüssel-Wert-Paare gespeichert werden. Der Schlüsselwert ist die Indexspalte und der Wert ist der Zeilenzeiger der Daten . Sie können es über die Zeilenzeigerdaten finden
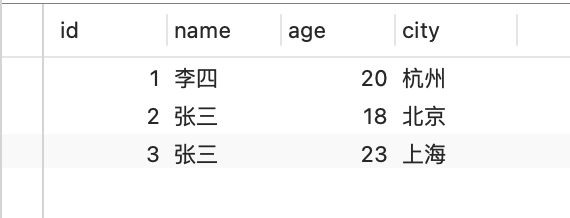
Unter der Annahme, dass die Tabelle nun userdie Memory-Speicher-Engine verwendet, wird ein Hash-Index für das Namensfeld erstellt und drei Datenelemente in die Tabelle eingefügt
Der Hash-Index führt eine Hash-Berechnung für den Wert des Indexspaltennamens durch und findet dann den entsprechenden Slot, wie in der folgenden Abbildung dargestellt
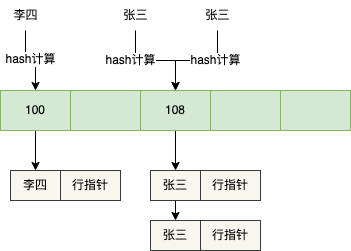
Wenn der Hash-Wert des Namensfelds gleich ist, dh ein Hash-Konflikt vorliegt, wird eine verknüpfte Liste erstellt. Wenn beispielsweise zwei Daten mit dem Namen = Zhang San vorhanden sind, wird eine verknüpfte Liste erstellt.
Wenn Sie danach die Daten von name = Li Si überprüfen möchten, müssen Sie nur noch eine Hash-Berechnung für Li Si durchführen, den entsprechenden Slot finden, die verknüpfte Liste durchlaufen, den Zeilenzeiger entsprechend name = Li Si herausnehmen und Suchen Sie dann entsprechend dem Zeilenzeiger nach den entsprechenden Daten.
Vor- und Nachteile des Hash-Index
-
Der Hash-Index kann nur zum Gleichheitsvergleich verwendet werden, daher ist die Abfrageeffizienz sehr hoch
-
Bereichsabfragen werden nicht unterstützt und das Sortieren wird nicht unterstützt, da die Verteilung indizierter Spalten ungeordnet ist
2.3 B+-Baum
B + Baum ist die am häufigsten verwendete Datenstruktur im MySQL-Index, die hier nicht vorgestellt wird, aber im nächsten Abschnitt vorgestellt wird.
Neben Hash und B + Tree gibt es noch andere Indizes wie den Volltextindex, auf die hier nicht eingegangen wird
- Clustered-Index
3.1 Datenspeicherung der Datenseite
Wir wissen, dass die Daten, die wir in die Tabelle einfügen, letztendlich auf der Festplatte gespeichert werden. InnoDB schlägt das Konzept von Seiten vor, um die Verwaltung dieser Daten zu erleichtern . Es unterteilt die Daten in mehrere Seiten. Die Standardgröße jeder Seite beträgt 16 KB Wir können diese Seite als Datenseite bezeichnen .
Wenn wir ein Datenelement einfügen, werden die Daten auf der Datenseite gespeichert, wie in der folgenden Abbildung dargestellt
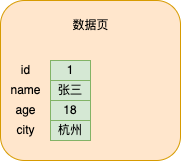
Wenn Daten kontinuierlich in die Datenseite eingefügt werden, werden die Daten nach der Größe des Primärschlüssels sortiert (andernfalls wird er automatisch generiert), um eine einseitig verknüpfte Liste zu bilden
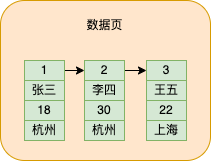
Zusätzlich zum Speichern der von uns eingefügten Daten bietet die Datenseite auch einen Teil des Speicherplatzes zum Speichern zusätzlicher Informationen. Es gibt viele Arten zusätzlicher Informationen. Ich werde eine später treffen und eine sagen
3.2 Datensuche für eine einzelne Datenseite
Da die Daten auf der Datenseite gespeichert werden, wie können die Daten auf der Datenseite überprüft werden?
Angenommen, Sie müssen jetzt die Daten dieses Datensatzes mit der ID = 2 auf der Datenseite finden. Wie können Sie sie schnell finden?
Es gibt eine dumme Möglichkeit, die verknüpfte Liste von Anfang an zu durchlaufen, zu beurteilen, ob die ID gleich 2 ist, und wenn sie gleich 2 ist, einfach die Daten herauszunehmen.
Obwohl diese Methode machbar ist, ist es nicht allzu mühsam, jedes Mal auf diese Weise zu durchlaufen, wenn auf einer Datenseite viele Daten, Dutzende oder Hunderte von Daten gespeichert sind
Daher hat sich MySQL eine gute Möglichkeit ausgedacht, diese Daten zu gruppieren
Unter der Annahme, dass 12 Daten auf der Datenseite gespeichert sind, entspricht die gesamte Gruppierung ungefähr der folgenden Abbildung
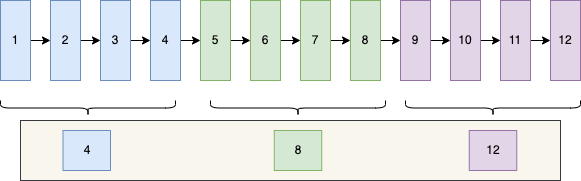
Der Einfachheit halber habe ich hier nur den ID-Wert markiert und die Werte anderer Felder weggelassen
Hier gehe ich davon aus, dass alle 4 Daten als Gruppe gelten und es 3 Gruppen im Bild gibt. Nachdem die Gruppe abgeschlossen ist, ermittelt MySQL den größten ID- Wert in jeder Gruppe, nämlich 4, 8 und 12 Zoll Das Bild. Suchen Sie einen Speicherort auf der Datenseite. Dies ist eine der zusätzlichen Informationen, die auf der oben erwähnten Datenseite gespeichert sind, die als Seitenverzeichnis bezeichnet wird
Angenommen, Sie müssen nach der Abfrage der Daten mit der ID = 6 zu diesem Zeitpunkt nur das Seitenverzeichnis gemäß der binären Suche durchsuchen und feststellen, dass es zwischen 4 und 8 liegt. Da 4 und 8 die größten IDs ihrer Gruppen sind, dann muss id=6 sein In der Gruppe von 8, gehen Sie dann zur Gruppe mit id=8, durchlaufen Sie alle Daten und beurteilen Sie, ob die ID gleich 6 ist oder nicht.
Da MySQL vorschreibt, dass die Anzahl der Datenelemente in jeder Gruppe etwa 4 bis 8 beträgt, muss dies viel schneller sein als das Durchlaufen der Daten der gesamten Datenseite
Tatsächlich habe ich die obige Gruppierungssituation ein wenig vereinfacht, aber das verzögert das Verständnis nicht
3.3 Datensuche auf mehreren Datenseiten
Wenn wir kontinuierlich Daten in die Tabelle einfügen, nimmt der von den Daten belegte Platz weiter zu, die Größe einer Datenseite ist jedoch festgelegt. Wenn eine Datenseite keine Daten speichern kann, wird eine Datenseite zum Speichern von Daten neu erstellt

Um jede Seite zu unterscheiden, weist MySQL jeder Datenseite eine Seitennummer zu, die im Speicherplatz für zusätzliche Informationen gespeichert wird. Gleichzeitig werden in den zusätzlichen Informationen auch die Positionen der vorherigen und nächsten Datenseite gespeichert der aktuellen Datenseite und bildet so eine doppelt verknüpfte Liste zwischen Datenseiten
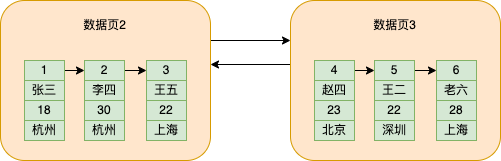
Die Seitennummer der Datenseite 2 beträgt 2 und die Seitennummer der Datenseite 3 beträgt 3. Zum besseren Verständnis schreibe ich hier direkt die Anzahl der Datenseiten.
Und MySQL legt fest, dass der Maximalwert der gespeicherten Daten-ID der vorherigen Datenseite kleiner ist als der Minimalwert der gespeicherten Daten-ID der nächsten Datenseite, sodass die Daten in allen Daten nach der Größe der ID sortiert werden Seiten .
Wenn es nun mehrere Datenseiten gibt, was sollen wir dann tun, wenn wir die Daten mit der ID=5 finden müssen?
Natürlich kann die obige dumme Methode immer noch verwendet werden, das heißt, von der ersten Datenseite aus zu durchlaufen, dann die Daten auf jeder Datenseite zu durchlaufen und schließlich die Daten mit der ID = 5 zu finden.
Wenn Sie jedoch genau darüber nachdenken, entspricht diese dumme Methode einem vollständigen Tabellenscan, der definitiv nicht funktionieren wird.
Wie kann man es also optimieren?
Die Idee der MySQL-Optimierung ähnelt tatsächlich der vorherigen Optimierungsidee, bei der auf einer einzelnen Datenseite nach Daten gesucht wird
Es wird die kleinste ID aus jeder Datenseite herausgenommen und separat auf einer anderen Datenseite abgelegt. Diese Datenseite speichert nicht die Daten, die wir tatsächlich einfügen, sondern nur die kleinste ID und die Seitennummer der Datenseite, auf der sich die ID befindet befindet, wie in der Abbildung gezeigt
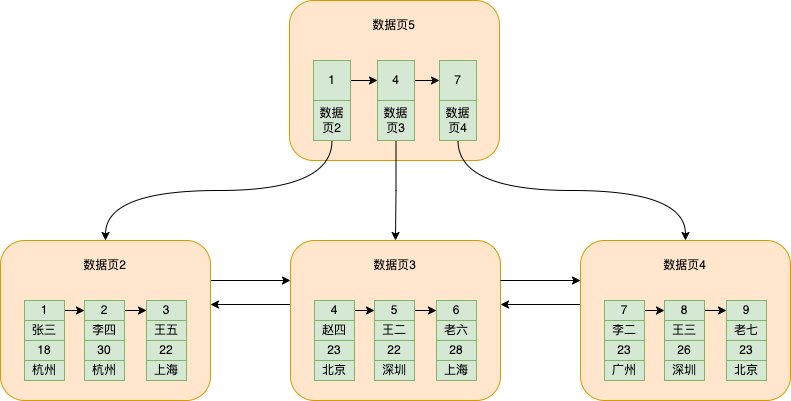
Um das Bild vollständiger zu machen, habe ich eine Datenseite zum Speichern von Daten 4 hinzugefügt
Zu diesem Zeitpunkt wird Datenseite 5 extrahiert, auf der die Mindest-ID und die entsprechende Datenseitennummer der folgenden drei Datenseiten gespeichert sind, auf denen Daten gespeichert sind
Zu diesem Zeitpunkt ist es sehr praktisch, die Daten mit der ID = 5 zu finden, grob unterteilt in die folgenden Schritte:
-
Von Datenseite 5 direkt basierend auf der binären Suche, gefunden zwischen 4 und 7
-
Da 4 und 7 die kleinsten IDs der Datenseiten sind, müssen sich die Daten mit ID=5 auf der Datenseite mit ID=4 befinden (da die kleinste ID der Datenseite mit ID=7 7 ist).
-
Gehen Sie als Nächstes zur Seitennummer der Datenseite 2, die der ID = 4 entspricht, um die Datenseite 2 zu finden
-
Suchen Sie dann nach Daten gemäß dem Suchvorgang auf einer einzelnen Datenseite basierend auf der Primärschlüssel-ID der oben genannten Daten
Auf diese Weise ist es möglich, Daten zwischen mehreren Datenseiten anhand der Primärschlüssel-ID zu finden
3.4 Clustered-Index
Da die Datenmenge weiter zunimmt, nimmt die Anzahl der Datenseiten, auf denen Daten gespeichert werden, weiter zu, und Datenseite 5 enthält immer mehr Daten, aber jede Datenseite ist standardmäßig 16 KB groß, sodass Datenseite 5 auch in mehrere Daten aufgeteilt wird Seitensituation, wie unten gezeigt
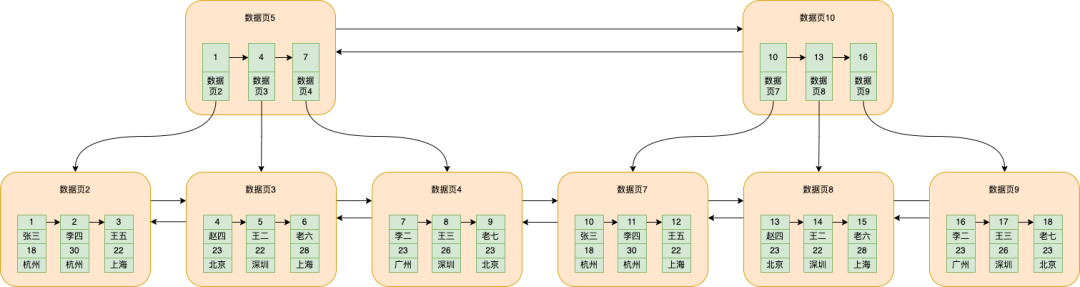
Datenseite 10 verhält sich genauso wie Datenseite 5
Wenn Sie zu diesem Zeitpunkt nach Daten mit der ID=5 suchen möchten, sollten Sie dann zur binären Suche auf Datenseite 5 oder zur binären Suche auf Datenseite 10 gehen?
Der dumme Weg ist das Durchlaufen, aber es ist wirklich unnötig. MySQL extrahiert die ID der kleinsten Daten, die auf Datenseite 5 und Datenseite 10 gespeichert sind, und die entsprechende Datenseitennummer und fügt sie separat in eine Datenseite ein, wie in gezeigt die Abbildung unten
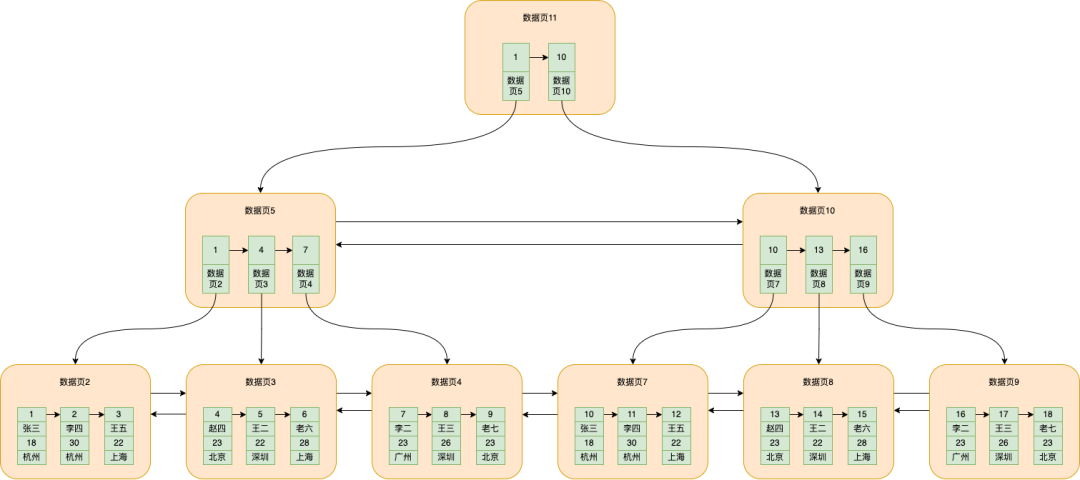
Datenseite 11 ist die neu extrahierte Datenseite, auf der die Seitennummer von ID = 1 und die entsprechende Datenseite 5 sowie die Nummer ID = 10 und die entsprechende Seitennummer von Datenseite 10 gespeichert sind
Und das ist der B+-Baum .
Im Allgemeinen kann der B + -Baum der MySQL-Datenbank zig Millionen Daten in drei Schichten enthalten.
Zu diesem Zeitpunkt ist die Suche nach Daten mit der ID = 5 grob in die folgenden Schritte unterteilt:
-
Suchen Sie von der Datenseite 11 gemäß der binären Suche nach id=5, entsprechend der Datenseite 5
-
Gehen Sie dann zu Datenseite 5 und suchen Sie Datenseite 3 gemäß der binären Suche id=5
-
Gehen Sie dann zu Datenseite 3, um Daten gemäß ID = 5 zu finden. Die spezifische Logik wurde bereits oft erwähnt.
Auf diese Weise können die Daten erfolgreich gefunden werden.
Der B+-Baum, in dem die Blattknoten die tatsächlich eingefügten Daten speichern, wird als Clustered-Index bezeichnet , und die Nicht-Blattknoten speichern die Datensatz-ID und die entsprechende Datenseitennummer.
Für die InnoDB-Speicher-Engine werden die Daten selbst also in einem B+-Baum gespeichert.
- Sekundärindex
Ein Sekundärindex wird auch als nicht gruppierter Index bezeichnet, der selbst ein B+-Baum ist. Ein Sekundärindex entspricht einem B+-Baum, aber die im Sekundärindex-B+-Baum gespeicherten Daten unterscheiden sich von denen des Clustered-Index.
Wie bereits im Clustered-Index erwähnt, speichern Blattknoten die Daten, die wir in die Datenbank einfügen, und Nicht-Blattknoten speichern die Primärschlüssel-ID der Daten und die entsprechende Datenseitennummer.
Die Blattknoten des Sekundärindex speichern die Daten der Indexspalte und die entsprechende Primärschlüssel-ID, und die Nicht-Blattknoten speichern zusätzlich zu den Daten und der ID der Indexspalte auch die Seitennummer der Datenseite.
Die oben erwähnte Datenseite wird eigentlich Indexseite genannt, da der Blattknoten die Daten der tatsächlichen Tabelle speichert, also nenne ich sie Datenseite. Als nächstes werde ich, weil ich wirklich über den Index sprechen möchte, den Sekundärindex verwenden Die Seite wird Indexseite genannt . Sie wissen, dass sie dieselbe ist, aber die gespeicherten Daten sind nicht dieselben.
4.1 Einspaltiger Index
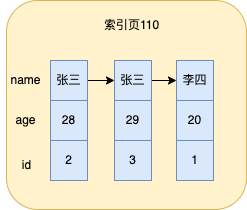
Angenommen, wir fügen dem Namensfeld nun einen gemeinsamen, nicht eindeutigen Index hinzu, dann ist der Name die Indexspalte und der Namensindex ist ebenfalls ein einspaltiger Index
Wenn zu diesem Zeitpunkt drei Daten in die Tabelle eingefügt werden, sind die im Blattknoten des Namensindex gespeicherten Daten wie in der folgenden Abbildung dargestellt

MySQL sortiert nach dem Wert des Namensfelds. Hier gehe ich davon aus, dass Zhang San vor Li Si steht. Wenn die Werte der Indexspalten gleich sind, werden sie nach der ID sortiert Der Index wurde tatsächlich nach dem Wert der Indexspalte sortiert.
Hier sind sicher ein paar Freunde, die Fragen haben. Kann man die im Namensfeld gespeicherten Chinesen sortieren?
Die Antwort lautet „Ja“, und MySQL unterstützt viele Arten von Sortierregeln. Wir können die Sortierregeln beim Erstellen von Datenbanken oder Tabellen angeben, und die Sortierung der in den folgenden Artikeln enthaltenen Zeichenfolgen wird von mir nach dem Zufallsprinzip durchgeführt. Die tatsächliche Situation ist möglicherweise nicht dieselbe . das gleiche .
Die Datensuche für eine einzelne Indexspalte ist dieselbe wie beim oben erwähnten Clustered-Index. Die Daten werden ebenfalls gruppiert, und dann können die Daten gemäß der binären Suche in einer einzelnen Indexspalte durchsucht werden.
Wenn die Daten weiter zunehmen und eine Indexseite die Daten nicht speichern kann, werden mehrere Indexseiten zum Speichern der Daten verwendet, und die Indexseiten bilden direkt eine doppelt verknüpfte Liste

Wenn die Anzahl der Indexseiten weiter zunimmt, wird auch eine Indexseite extrahiert, um die Suche nach Daten auf verschiedenen Indexseiten zu erleichtern. Zusätzlich zur Speicherung der ID auf der Seite wird auch der Wert des Index gespeichert Spalte, die der ID entspricht
Wenn die Datenmenge immer größer wird, werden sie extrahiert und ein dreischichtiger B + -Baum gebildet, daher werde ich ihn hier nicht zeichnen.
4.2 Gemeinsamer Index
Zusätzlich zum einspaltigen Index ist der gemeinsame Index tatsächlich derselbe, mit der Ausnahme, dass die auf der Indexseite gespeicherten Daten mehr Indexspalten haben.
Um beispielsweise einen gemeinsamen Index zu Name und Alter zu erstellen, wird in der Abbildung eine einzelne Indexseite dargestellt
Sortieren Sie zuerst nach Name, dann nach Alter, wenn der Name derselbe ist, wenn andere Spalten vorhanden sind usw., und schließlich nach ID.
Im Vergleich zum Index mit nur dem Namensfeld speichert die Indexseite eine weitere Indexspalte.
Der endgültige B + -Baum ist wie in der folgenden Abbildung dargestellt vereinfacht

4.3 Zusammenfassung
Tatsächlich ist aus der obigen Analyse ersichtlich, dass die Hauptunterschiede zwischen dem Clustered-Index und dem Nicht-Clustered-Index wie folgt sind
-
Die Blattknoten des Clustered-Index speichern die Werte aller Spalten, und die Blattknoten des Nicht-Clustered-Index speichern nur die Werte der Indexspalten und die Primärschlüssel-ID
-
Die Daten des Clustered-Index werden nach ID sortiert, und die Daten des Nicht-Clustered-Index werden nach Indexspalte sortiert
-
Die Nicht-Blattknoten des Clustered-Index speichern die Primärschlüssel-ID und die Seitennummer, und die Nicht-Blattknoten des Nicht-Clustered-Index speichern die Indexspalte, die Primärschlüssel-ID und die Seitennummer
Da der letztere Indexbaum häufig verwendet wird, habe ich der Einfachheit halber die entsprechenden Daten basierend auf den Daten des obigen Indexbaums in die Tabelle eingefügt, und die SQL befindet sich am Ende des Artikels
In Wirklichkeit ist der Index-B+-Baum möglicherweise nicht wie in meinem Bild sortiert, aber das verzögert das Verständnis nicht.
- Rücksendeformular
–
Nachdem wir über den Sekundärindex gesprochen haben, sprechen wir darüber, wie der Sekundärindex zum Suchen von Daten verwendet wird.
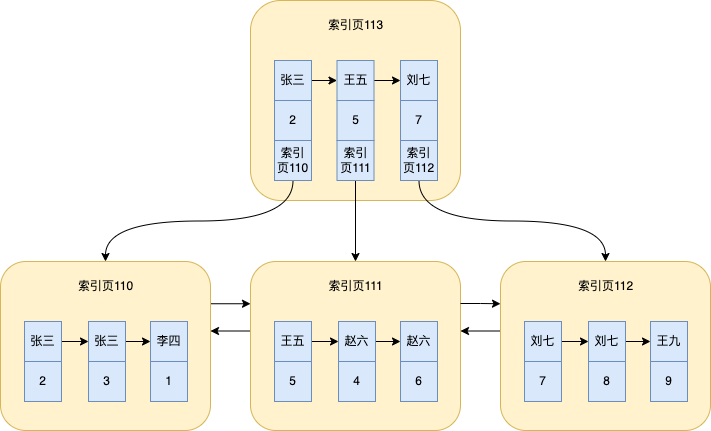
Hier wird davon ausgegangen, dass ein Index für das Namensfeld erstellt wird und mehrere Daten im obigen Beispiel in der Tabelle gespeichert werden. Hier mache ich das Bild noch einmal

Wie soll also die folgende SQL ausgeführt werden?
select * from `user` where name = '赵六';
Da die Abfragebedingung lautet name = '赵六', wird der Namensindex verwendet
Der gesamte Prozess gliedert sich grob in die folgenden Schritte:
-
Starten Sie die binäre Suche auf der obersten Indexseite, in unserer Abbildung die Indexseite 113. Wenn sich über der Indexseite 113 eine weitere Ebene befindet, starten Sie die binäre Suche auf der oberen Ebene
-
Suchen Sie zwischen und auf der Indexseite 113 und
赵六gehen Sie dann zur Suche auf die entsprechende Indexseite 111王五刘七王五赵六 -
赵六Der erste Datensatz , der auf Indexseite 111 gefunden wird , also der mit der ID=4 -
Da dies der Fall ist
select *, müssen Sie andere Felder überprüfen. Zu diesem Zeitpunkt suchen Sie nach anderen Felddaten im Clustered-Index gemäß ID = 4. Dieser Suchvorgang wurde bereits mehrfach erwähnt. Dies dient der Suche nach Daten im Clustered-Index basierend auf ID=4. Backlist _ -
Da es sich um einen nicht eindeutigen Index handelt,
赵六kann dieser Wert wiederholt werden, sodass er weiterhin entlang der verknüpften Liste auf der Indexseite 111 durchlaufen wird. Wenn der Name noch vorhanden ist,赵六wird er entsprechend dem ID-Wert in die Tabelle zurückgegeben. Und so weiter, bis der Name nicht mehr gleich ist赵六. Zur Veranschaulichung handelt es sich tatsächlich um zwei Datenelemente
Aus der Analyse des Datensuchprozesses des Sekundärindex oben können wir die Bedeutung der Rückkehr zur Tabelle verstehen , das heißt, zuerst die entsprechende Primärschlüssel-ID aus dem Sekundärindex entsprechend dem Feldwert der Abfragebedingung nachschlagen, Suchen Sie dann anhand der ID nach den Werten anderer Felder und dann nach dem Clustered-Index.
- abdeckender Index
Im vorherigen Abschnitt wurde gesagt, dass bei der Ausführung dieser SQL die entsprechende Primärschlüssel-ID select * from user where name = '赵六';zuerst auf der Indexseite gefunden und dann an die Tabelle zurückgegeben wird, um die Werte anderer Felder im Clustered-Index abzufragen.name = '赵六';
Was passiert also, wenn die folgende SQL ausgeführt wird?
select id from `user` where name = '赵六';
select *Dieses Mal ändert sich das Abfragefeld von select idund die Abfragebedingungen bleiben unverändert, sodass auch der Namensindex verwendet wird
name = '赵六';Es ist also immer noch dasselbe wie zuvor. Nachdem ich die entsprechende Primärschlüssel-ID auf der Indexseite herausgefunden hatte , war ich überrascht, dass der ID-Wert des Felds, das in SQL abgefragt werden muss, bereits gefunden wurde. Wenn die ID ist erreicht, welche Tabelle zurückgegeben werden soll.
Der Fall, dass sich alle abzufragenden Felder in der Indexspalte befinden, wird als abdeckender Index bezeichnet , und die Indexspalte deckt die Bedeutung des Abfragefelds ab.
Bei Verwendung eines abdeckenden Index wird die Häufigkeit der Rückkehr zur Tabelle reduziert, sodass die Abfragegeschwindigkeit schneller und die Leistung höher ist.
Versuchen Sie daher in der täglichen Entwicklung, * nicht auszuwählen, und prüfen Sie, was Sie benötigen. Wenn ein abdeckender Index vorhanden ist, ist die Abfrage viel schneller.
- Index-Pushdown
Unter der Annahme, dass jetzt ein gemeinsamer Index von Namen und Alter für die Tabelle erstellt wurde, werde ich zum besseren Verständnis die vorherige Abbildung erneut verwenden

Führen Sie als Nächstes die folgende SQL aus
select * from `user` where name > '王五' and age > 22;
Vor MySQL5.6 (außer 5.6) lauten die allgemeinen Ausführungsschritte des gesamten SQL wie folgt:
-
Suchen Sie zunächst gemäß der binären Suche
name > '王五'das erste Datenelement, nämlich Zhao Liu mit der ID = 4 -
Danach kehrt es gemäß ID = 4 zur Tabelle zurück, durchsucht die Daten in anderen Feldern mit ID = 4 im Clustered-Index und beurteilt dann, ob das Alter in den Daten größer als 22 ist. Wenn dies der Fall ist, bedeutet dies dass es die Daten sind, die wir finden müssen, sonst nicht
-
Folgen Sie dann der verknüpften Liste, durchlaufen Sie sie weiter und kehren Sie dann einmal zur Tabelle zurück, wenn ein Datensatz gefunden wird, und beurteilen Sie dann das Alter und so weiter bis zum Ende
Daher durchläuft der gesamte Suchprozess, wie in der Abbildung gezeigt, fünf Back-to-Table-Operationen, zwei Zhao Liu, zwei Liu Qi und eine Wang Jiu, und schließlich sind die Daten, die die Bedingungen erfüllen, die Daten von Zhao Liu mit id=6, und die restlichen Altersgruppen stimmen nicht mit und überein.
Obwohl es bei dieser Ausführung kein Problem gibt, weiß ich nicht, ob Sie festgestellt haben, dass es nicht notwendig ist, so oft zur Tabelle zurückzukehren, da aus dem obigen Indexdiagramm ersichtlich ist, dass die übereinstimmenden Daten die Daten von name > '王五' and age > 22sind Zhao Liu mit ID=6
Nach MySQL5.6 age > 22wird die obige Beurteilungslogik optimiert
Es ist immer noch dasselbe wie zuvor. Finden Sie Zhao Liu mit der ID = 4 und gehen Sie dann nicht zur Tabelle zurück, um das Alter zu beurteilen, da die Indexspalte den Wert des Alters enthält, und beurteilen Sie dann direkt, ob es größer als 22 ist zum Alter im Index, wenn es größer ist, dann Kehren Sie zur Tabelle zurück, um die verbleibenden Felddaten abzufragen (weil es so ist select *) und durchlaufen Sie dann die verknüpfte Liste nacheinander bis zum Ende
Nach dieser Optimierung beträgt die Anzahl der Rückkehr zur Tabelle also 1, was die Anzahl der Rückkehr zur Tabelle im Vergleich zu den vorherigen 5 Malen erheblich reduziert.
Und diese Optimierung wird als Index-Pushdown bezeichnet , der die Anzahl der Rückkehr zur Tabelle verringern soll.
Der Grund, warum diese Optimierung als Index-Pushdown bezeichnet wird, hängt tatsächlich
age > 22mit dem Ort zusammen, an dem die Beurteilungslogik ausgeführt wird, daher werde ich hier nicht auf Details eingehen.
- Indexzusammenführung
Indexzusammenführung (Indexzusammenführung) ist ein Indexoptimierungsmechanismus, der mit MySQL5.1 eingeführt wurde. In früheren MySQL-Versionen können mehrere Abfragebedingungen in einer SQL nur einen Index verwenden. Bei mehreren Indizes werden die Scanergebnisse gescannt und anschließend überprüft zusammengeführt werden
Die Ergebnisse werden in den folgenden drei Situationen zusammengeführt:
-
Nehmen Sie die Kreuzung (Kreuzung)
-
Nehmen Sie die Gewerkschaft
-
Union nach dem Sortieren (sort-union)
Um die Demonstration nicht zu verzögern, löschen Sie alle vorherigen Indizes und erstellen Sie dann einen sekundären Index idx_name und idx_age für Name und Alter
8.1 Kreuzung (kreuzen)
Wenn die folgende SQL ausgeführt wird, wird der Schnittpunkt angezeigt
select * from `user` where name = '赵六' and age= 22;
Ausführungsplan ansehen
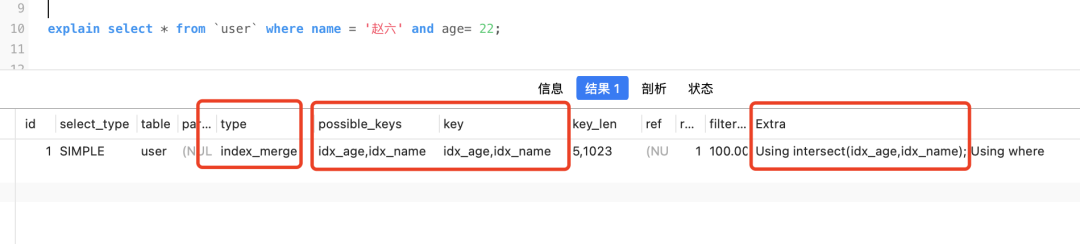
Der Typ ist „yes“ index_merge, und sowohl „möglicher_Schlüssel“ als auch „Schlüssel“ sind Summen idx_name, idx_agewas darauf hinweist, dass die Indexzusammenführung verwendet wird, und „Extra“ verfügbar ist Using intersect(idx_age,idx_name), und „intersect“ bedeutet „Schnittpunkt“.
Der gesamte Prozess ist ungefähr so: Nehmen Sie die entsprechende Primärschlüssel-ID gemäß idx_nameund heraus und nehmen Sie dann den Schnittpunkt der Primärschlüssel-ID. Dann muss die ID dieses Teils des Schnittpunkts die Abfragebedingungen der Abfrage erfüllen Gleichzeitig (denken Sie sorgfältig nach) und kehren Sie dann entsprechend der Schnittpunkt-ID zur Tabelle zurückidx_agename = '赵六' and age= 22
Wenn Sie jedoch den gemeinsamen Index verwenden möchten, der die Schnittmenge ermittelt, müssen Sie sicherstellen, dass die von den jeweiligen Indizes gefundenen Primärschlüssel-IDs sortiert sind, um die Schnittmenge schneller ermitteln zu können
Beispielsweise kann die folgende SQL den gemeinsamen Index nicht verwenden
select * from `user` where name = '赵六' and age > 22;
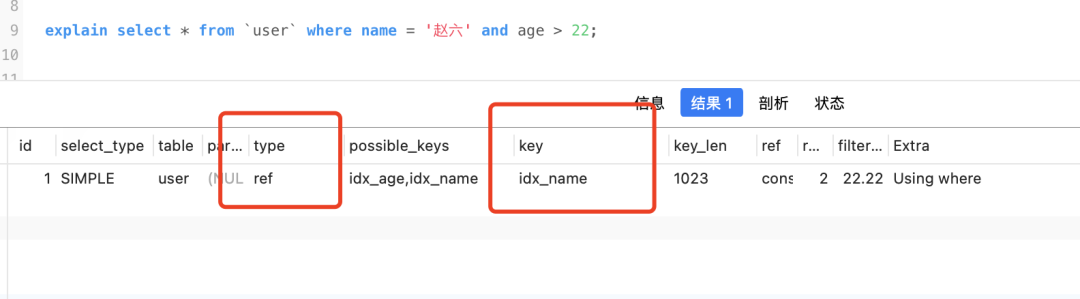
Sie können nur den Namensindex verwenden, da age > 22die ermittelten IDs nicht in der richtigen Reihenfolge sind. Ich habe die Sortierregeln von Indexspalten erwähnt, als ich über Indizes gesprochen habe.
Daraus ist ersichtlich, dass die Bedingungen für die Verwendung eines gemeinsamen Index relativ hart sind.
8.2 Union
andWenn Sie die Gewerkschaft verwenden, ersetzen Sie das vorherige Beispiel durchor
select * from `user` where name = '赵六' or age = 22;
Die vorherige Ausführung ist dieselbe. Gehen Sie gemäß den Bedingungen zu den entsprechenden Indizes, um zu suchen, nehmen Sie dann die Vereinigung der Abfrage-ID zum Deduplizieren und kehren Sie dann zur Tabelle zurück
In ähnlicher Weise erfordert die Verwendung der Union auch, dass die von den jeweiligen Indizes gefundenen Primärschlüssel-IDs sortiert werden. Wenn die Abfragebedingung age > 22in geändert wird
select * from `user` where name = '赵六' or age > 22;
8.3 Vereinigung nach dem Sortieren (sort-union)
Obwohl die Vereinigung erfordert, dass die von den jeweiligen Indizes gefundenen Primärschlüssel-IDs sortiert werden, wenn jedoch eine unsortierte Situation vorliegt, optimiert MySQL diese Situation automatisch, indem zuerst die Primärschlüssel-ID sortiert und dann abgerufen und zusammengeführt wird Set, diese Situation wird aufgerufen Sortiervereinigung.
Beispielsweise entspricht die oben erwähnte SQL, die die Union nicht direkt übernehmen kann, der Situation, die Union nach dem Sortieren zu übernehmen (sort-union).
select * from `user` where name = '赵六' or age > 22;
- Wie wählt MySQL Indizes aus?
In der täglichen Produktion verfügt eine Tabelle möglicherweise über mehrere Indizes. Wie bestimmt MySQL, welcher Index bei der Ausführung von SQL verwendet werden soll, oder scannt die gesamte Tabelle?
Wenn MySQL den Index auswählt, beurteilt es anhand der Kosten für die Verwendung des Index
Die Kosten einer SQL-Ausführung teilen sich grob in zwei Teile auf
-
E/A-Kosten: Da sich diese Seiten alle auf der Festplatte befinden, müssen Sie sie, wenn Sie sie beurteilen möchten, zuerst in den Speicher laden. MySQL legt fest, dass die Kosten für das Laden einer Seite 1,0 betragen
-
CPU-Kosten, zusätzlich zu den E/A-Kosten gibt es auch die Kosten der bedingten Beurteilung, also die CPU-Kosten. Im vorherigen Beispiel müssen Sie beispielsweise beurteilen, dass das geladene Datenzeichen
name = '赵六'die Bedingungen nicht erfüllt. MySQL legt fest, dass die Kosten für jede beurteilte Daten 0,2 betragen
9.1 Kostenberechnung für den vollständigen Tabellenscan
Für einen vollständigen Tabellenscan sieht die Kostenberechnung ungefähr wie folgt aus
MySQL zählt die Daten der Tabelle. Diese Statistik ist ungefähr und nicht sehr genau. Sie show table status like '表名'können die statistischen Daten durchsehen
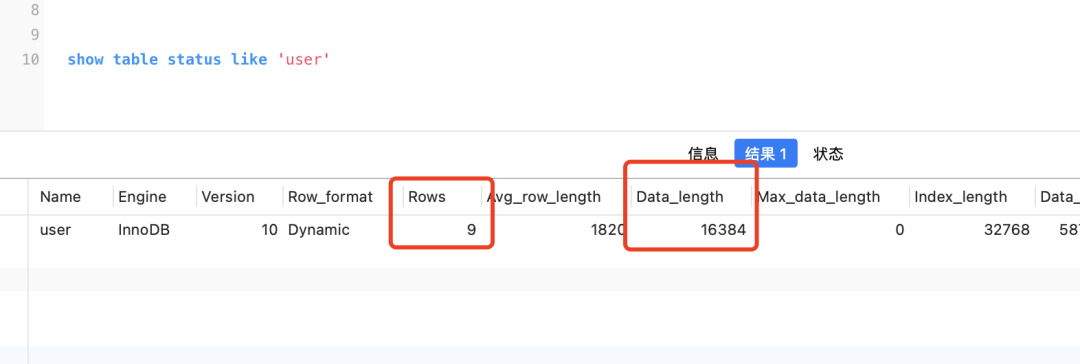
Wie viele Datenzeilen gibt es beispielsweise in dieser Tabelle und wie viele Bytes data_length der Clustered-Index belegt? Da der Standardwert 16 KB beträgt, können Sie die ungefähre Anzahl der Datenseiten berechnen (data_length/1024/16).
Die Kosten für einen vollständigen Tabellenscan werden also wie folgt berechnet
rows * 0.2 + data_length/1024/16 * 1.0
9.2 Sekundärindex + Kostenberechnung der Renditetabelle
Die Kostenberechnung für Sekundärindex + Tabellenrückgabe ist komplizierter und ihre Kostendaten hängen von der Anzahl der Scanintervalle und der Anzahl der Tabellenrückgabezeiten in zwei Teilen ab
Um die Beschreibung des Scanintervalls zu erleichtern, mache ich hier noch einmal das obige Bild

select * from `user` where name = '赵六';
Sehen Sie das Bild an!
Die Abfragebedingung name = '赵六'generiert ein Scanintervall von Zhao Liu mit der ID = 4 bis Zhao Liu mit der ID = 6
Wenn die Abfragebedingung beispielsweise lautet name > '赵六', wird ein Scanintervall von Liu Qi mit der ID=7 bis zum Ende der Daten (Wang Jiu mit der ID=9) generiert.
Wenn in einem anderen Beispiel die Abfragebedingung lautet name < '李四' and name > '赵六', werden zu diesem Zeitpunkt zwei Scanintervalle generiert, eines wird von Zhang San mit ID = 2 bis Zhang San mit ID = 3 gezählt und das andere wird von Liu Qi mit ID = 7 gezählt bis zum Ende der Daten
Das Scanintervall bedeutet also das Aufzeichnungsintervall, das die Abfragebedingungen erfüllt
Bei der Berechnung der Kosten des Sekundärindex legt MySQL fest, dass die Kosten für das Lesen eines Bereichs mit den E/A-Kosten für das Lesen einer Seite identisch sind. Beide Werte betragen 1,0
Nachdem das Intervall verfügbar ist, wird anhand statistischer Daten geschätzt, wie viele Daten sich in diesen Intervallen befinden, da die Kosten für das Lesen und Schreiben dieser Daten ungefähr der Anzahl der Teile * 0,2 entsprechen
Die Kosten für die Durchsicht des Sekundärindex betragen also区间个数 * 1.0 + 条数 * 0.2
Anschließend müssen diese Daten (falls erforderlich) an die Tabelle zurückgegeben werden. MySQL schreibt vor, dass die E/A-Kosten für jede Rückgabe an die Tabelle mit denen für das Lesen einer Seite identisch sind und ebenfalls 1,0 betragen
Bei der Rückkehr zur Tabelle müssen die verbleibenden Abfragebedingungen für die aus dem Clustered-Index abgerufenen Daten beurteilt werden. Dies sind die CPU-Kosten, die ungefähr der Anzahl der Einträge * 0,2 entsprechen
Die Kosten für die Rücksendung des Tisches betragen also ungefähr条数 * 1.0 + 条数 * 0.2
Die ungefähren Kosten für Sekundärindex + Tabellenrendite betragen also区间个数 * 1.0 + 条数 * 0.2 + 条数 * 1.0 + 条数 * 0.2
Wenn die Kosten des Index und die Kosten des vollständigen Tabellenscans berechnet werden, wählt MySQL den Index mit den niedrigsten Ausführungskosten aus
MySQL wird die oben genannten Kostenberechnungsergebnisse verfeinern, der Feinabstimmungswert ist jedoch sehr gering, daher lasse ich ihn hier weg und gebe hier nur eine allgemeine Einführung in die Kostenberechnungsregeln. Die tatsächliche Situation wird komplizierter sein, z Beim Abfragen von Tabellen usw. können interessierte Partner auf relevante Informationen verweisen
9.3 Zusammenfassung
Im Allgemeinen dient dieser Abschnitt hauptsächlich dazu, Ihnen eines zu verdeutlichen: Wenn MySQL einen Index auswählt, berechnet es die Kosten für die Verwendung jedes Index anhand statistischer Daten und Kostenberechnungsregeln und wählt dann die Verwendung des Index mit den niedrigsten Kosten. Abfrage ausführen
- Indexfehler
In der täglichen Entwicklung müssen Sie mehr oder weniger auf das Problem eines Indexfehlers gestoßen sein. Hier fasse ich einige häufige Indexfehlerszenarien zusammen.
Der Einfachheit halber mache ich hier noch einmal das Bild
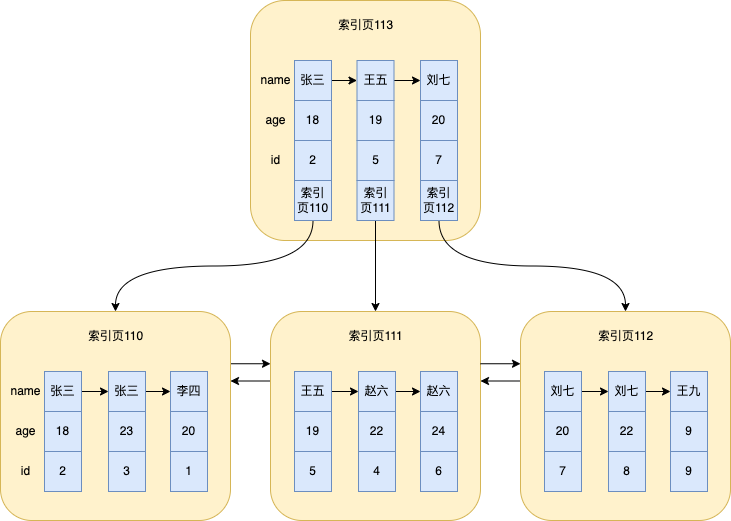
10.1 Inkonsistenz und Prinzip der Übereinstimmung des Präfixes ganz links
d.h. ganz links zuerst
Wenn es nicht mit dem Präfix-Übereinstimmungsprinzip ganz links übereinstimmt, schlägt der Index fehl
- Wenn er beispielsweise
likemit % beginnt, ist der Index ungültig oder der gemeinsame Index belegt nicht die erste Indexspalte. - Gemeinsamer Indexname, Alter. Tatsächlich werden zwei Indizes erstellt, nämlich (Name), (Name, Alter). Daher hat die Abfrage des Index nur mit dem Alter keine Wirkung; MySQL wird immer nach rechts abgeglichen, bis es auf eine Bereichsabfrage (>, <, between, like) stößt und den Abgleich beendet
Wenn beispielsweise der gemeinsame Index von Name und Alter ausgeführt wird und select * from user where name > '王五' and age > 22;Sie den Index verwenden möchten, müssen Sie zu diesem Zeitpunkt den gesamten Index scannen, da die Indexspalten zuerst nach dem Namensfeld und dann nach dem Alter sortiert werden Feld. Für Alter, in Der gesamte Index ist ungeordnet. Aus der Abbildung ist auch ersichtlich, dass 18, 23 ... 9 nicht in der richtigen Reihenfolge sind, sodass anhand der binären Suche nicht ermittelt werden kann, age > 22von welcher Indexseite aus begonnen wird
Wenn Sie also den Index verwenden, müssen Sie den gesamten Index scannen, einen nach dem anderen beurteilen und schließlich zur Tabelle zurückkehren, was viel Leistung verbraucht. Es ist besser, den Clustered-Index, also den vollständigen Index, direkt zu scannen Tabellenscan.
10.2 Indizierte Spalten werden berechnet
+1,abs(),f;oor()usw.
Wenn Sie Ausdrucksberechnungen durchführen oder Funktionen für den Index verwenden, wird der Index ebenfalls ungültig
Dies liegt hauptsächlich daran, dass der ursprüngliche Wert des Indexfelds im Index gespeichert wird. Wie aus dem oben gezeichneten Bild ersichtlich ist, gibt es bei der Berechnung des Werts durch die Funktion keine Möglichkeit, zum Index zu gelangen
10.3 Implizite Konvertierungen
Wenn die Indexspalte eine implizite Konvertierung aufweist, kann der Index ungültig werden
Beispielsweise legt MySQL fest, dass beim Vergleich einer Zeichenfolge mit einer Zahl zunächst die Zeichenfolge in eine Zahl umgewandelt und dann verglichen wird . Für die Konvertierung einer Zeichenfolge in eine Zahl gelten für MySQL eigene Regeln
Beispielsweise erfolgt eine implizite Konvertierung, wenn ich die folgende SQL ausführe
select * from `user` where name = 9527;
Das Namensfeld ist ein Varchar-Typ, 9527, ohne Anführungszeichen, es ist eine Zahl. MySQL konvertiert namezuerst den Wert des Felds gemäß den Regeln in eine Zahl und vergleicht ihn dann mit 9527. Zu diesem Zeitpunkt nameist der Index ungültig, da das Feld konvertiert wurde
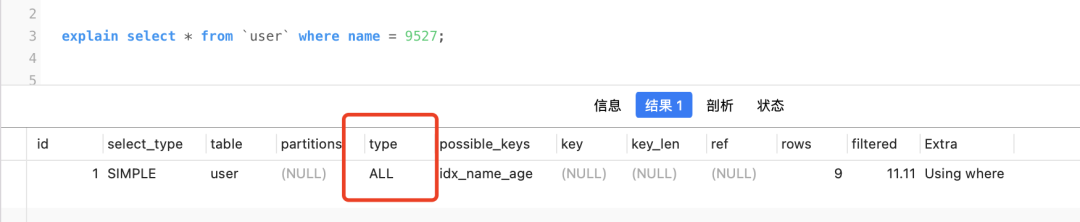
ALL bedeutet, dass der Index nicht verwendet wird und ungültig ist.
Angenommen, Sie erstellen jetzt einen Altersindex und führen die folgende SQL aus
select * from `user` where age = '22';
Zu diesem Zeitpunkt ist der Altersindex nicht ungültig, hauptsächlich aufgrund des zuvor erwähnten Satzes:
Wenn eine Zeichenfolge mit einer Zahl verglichen wird, wird die Zeichenfolge vor dem Vergleich in eine Zahl umgewandelt
Daher '22'wird es implizit in eine Zahl umgewandelt und dann mit dem Alter verglichen. Zu diesem Zeitpunkt wurde das Altersfeld noch keiner impliziten Konvertierung unterzogen, sodass es nicht ungültig ist.
Daher können implizite Konvertierungen den Index ungültig machen.
10.4 MySQL-Statistikdatenfehler ist groß
Große Fehler in den statistischen MySQL-Daten können auch zu Indexfehlern führen, da MySQL, wie bereits erwähnt, die Kosten für die Verwendung von Indizes auf der Grundlage statistischer Daten berechnet. Wenn also die statistischen Datenfehler groß sind, sind auch die berechneten Kostenfehler groß ist möglich. Die tatsächlichen Kosten der Indizierung sind gering, aber die berechneten Kosten der Indizierung sind hoch, was zu einem Indexfehler führt
Wenn dies geschieht, können Sie analyze table 表名diese SQL ausführen, und MySQL zählt die Daten erneut und der Index ist wieder gültig
- Indexierungsprinzipien
11.1 Die Anzahl der einzelnen Tabellenindizes sollte nicht zu groß sein
-
Aus der obigen Analyse wissen wir, dass jeder Index einem B + -Baum entspricht und die Blattknoten die gesamte Datenmenge in der Indexspalte speichern. Sobald die Anzahl der Indizes groß ist, wird viel Speicherplatz belegt
-
Gleichzeitig werden, wie bereits erwähnt, die Indexkosten vor der Abfrage berechnet. Sobald viele Indizes vorhanden sind, ist die Anzahl der Berechnungen groß und es kann zu Leistungsverschwendung kommen
11.2 Felder, die häufig nach „wo“ erscheinen, sollten indiziert werden
Es versteht sich von selbst, dass der Index beschleunigt werden soll. Wenn kein geeigneter Index vorhanden ist, wird ein vollständiger Tabellenscan durchgeführt. Bei InnoDB beginnt der vollständige Tabellenscan am ersten Blattknoten des Clustered-Index und beurteilt einen nach dem anderen Verknüpfte Liste. Der Datendienst erfüllt die Abfragebedingungen nicht
11.3 Felder nach Sortieren nach und Gruppieren nach können indiziert werden
Zum Beispiel die folgende SQL
select * from `user` where name = '赵六' order by age asc;
Index nach Reihenfolge, Name und Alter abfragen name = '赵六'und beitretenage
Möglicherweise erinnern Sie sich nicht an den Indexbaum. Ich bringe den Indexbaum mit
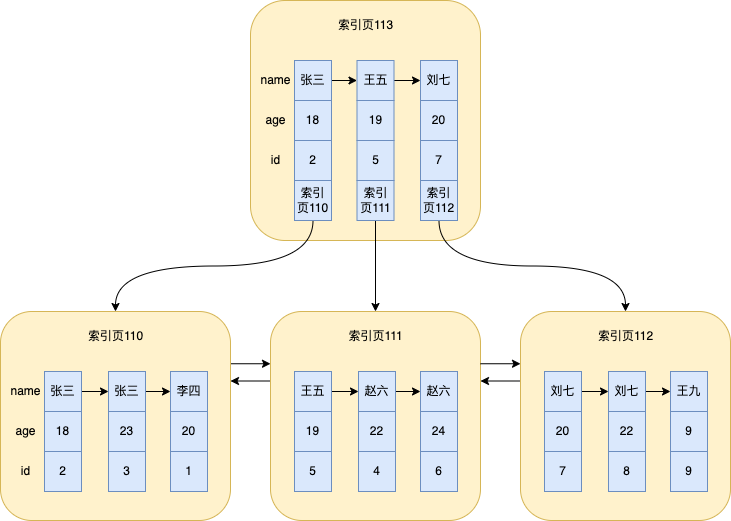
An dieser Stelle können Sie beim Betrachten des Indexbaums feststellen, name = '赵六'dass ageer zu diesem Zeitpunkt sortiert wurde (die Sortierregeln wurden in der vorherigen Einführung in den Index erwähnt), sodass Sie agedie Indexspalte zum Sortieren verwenden können.
11.4 Häufig aktualisierte Felder sollten nicht indiziert werden
Da der Index nach dem Wert der Indexspalte sortiert werden muss, muss die Position der Indexspalte auf der Indexseite häufig verschoben werden, sobald die Indexfelddaten häufig aktualisiert werden, um die Reihenfolge des Index sicherzustellen
Wie Name und Alters-Gelenkindex
王九Ändern Sie zu diesem Zeitpunkt den Namen der Daten mit der ID = 9 von 赵六in und verschieben Sie dann die geänderten Daten auf der Indexseite zwischen Wang Wu und Zhao Liu mit der ID = 4, denn wenn die Namen gleich sind, wird die Reihenfolge garantiert. und gleichzeitig nach Alter sortieren, das Alter von id = 9 ist 9, das kleinste, dann wird es zuerst eingestuft.
Daher erhöht die Erstellung eines Indexes für häufig aktualisierte Felder die Kosten für die Pflege des Indexes.
11.5 Wählen Sie hochdifferenzierte Felder für die Indizierung
Dies liegt daran, dass bei geringer Diskriminierung der Indexeffekt nicht gut ist.
Angenommen, es gibt ein Geschlechtsfeld „Geschlecht“, das entweder „männlich“ oder „weiblich“ ist. Wenn das Geschlecht indiziert wird und davon ausgegangen wird, dass „männlich“ vor „weiblich“ steht, sind die Daten auf der Indexseite grob wie folgt angeordnet:

Hier habe ich 6 Datenelemente gezeichnet. Unter der Annahme, dass es 10 W Datenelemente gibt, wird dies weiterhin so angeordnet, dass Männer vorne und Frauen hinten stehen.
Wenn Sie zu diesem Zeitpunkt zum Geschlechtsindex gehen und die Daten mit Geschlecht = männlich abfragen und davon ausgehen, dass die männlichen und weiblichen Daten halb halb sind, haben die gescannten Datensätze 5 W. Wenn Sie zur Tabelle zurückkehren möchten, Dann werden Sie gemäß den Kostenberechnungsregeln feststellen, dass die Kosten enorm sind und nicht so gut sind wie ein direkter vollständiger Tabellenscan.
Wählen Sie daher als Index ein Feld mit einem hohen Grad an Diskriminierung
- Zusammenfassung
–
An diesem Punkt ist dieser Artikel beendet. Hier finden Sie eine Überprüfung des Inhalts dieses Artikels
Zunächst ging es hauptsächlich um Clustered-Indizes und Nicht-Clustered-Indizes und dann um die Optimierung von MySQL für einige häufige Abfragen, z. B. das Abdecken von Indizes und Index-Pushdowns die Tabelle, wodurch der verursachte Leistungsverbrauch reduziert wird. Später wird erwähnt, wie MySQL Indizes auswählt, und schließlich werden die Szenarios von Indexfehlern und die Prinzipien der Indexerstellung vorgestellt.
Abschließend hoffe ich, dass dieser Artikel für Sie hilfreich ist!
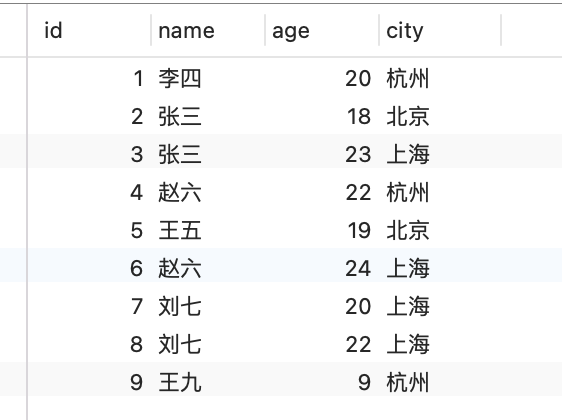
Schließlich lauten die SQL-Tabellendaten wie folgt
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (1, '李四', 20, '杭州');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (2, '张三', 18, '北京');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (3, '张三', 23, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (4, '赵六', 22, '杭州');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (5, '王五', 19, '北京');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (6, '赵六', 24, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (7, '刘七', 20, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (8, '刘七', 22, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (9, '王九', 9, '杭州');
Referenz:
[1]. „Wie MySQL funktioniert“
[2].https://blog.csdn.net/weixin_44953658/article/details/127878350