Batch-Normalisierung
Derzeit ist BN die am weitesten verbreitete Normalisierungsmethode in CV . Die Funktion von BN besteht darin, das Verschwinden des Gradienten und die Explosion des Gradienten zu lösen. Die Funktion von BN besteht darin, die Parameter in den Bereich zurückzuziehen, in dem die Aktivierungsfunktion empfindlicher ist.
Die Normalisierung kann während des Berechnungsprozesses beobachtet werden:
1. Ermitteln Sie den Mittelwert der Daten.
2. Ermitteln Sie die Varianz der Daten
. 3. Standardisieren Sie die Daten.
4. Trainieren Sie die Parameter γ, β
. 5. Der Ausgang y erhält durch die lineare Transformation einen neuen Wert von γ und β

gemäß der Stichprobe. Um vertikal zu normalisieren, müssen Sie den berechneten Mittelwert und die Varianz für die Schlussfolgerung speichern.Gilt für Szenarien, in denen die Chargengröße groß und die Verteilung zwischen den Proben relativ konzentriert ist。
Für die Daten in der folgenden Abbildung ist die Verwendung von BN, ähnlich wie bei herkömmlichen maschinellen Lerndaten , sehr sinnvoll und funktioniert gut. Das grüne Kästchen ist der Bereich von BN
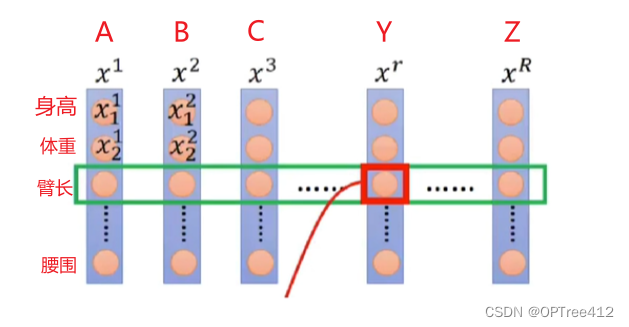
Für Sequenzdaten wie RNN ist BN jedoch nicht geeignet
- Da natürliche Sprache relativ flexibel ist, variiert die Verteilung von Wörtern an derselben Position in verschiedenen Stichproben stark, was im Widerspruch zur von BN geforderten Verteilungskonzentration steht, sodass der Effekt relativ gering ist.
- Darüber hinaus ist die Länge der Sätze für die Verarbeitung natürlicher Sprache nicht festgelegt, und der Unterschied wird groß sein.
Ebenennormalisierung
Im NLP wird ein Wort oder eine Phrase durch eine Wörterinbettungsmatrix dargestellt, und Sie können die Dimension dieser Matrix festlegen. In LN befasst er sich zur Normalisierung mit den entsprechenden Merkmalen in jeder Worteinbettungsmatrix.
Es hört sich so an, als gäbe es keinen Unterschied zum oben Gesagten, aber bei der NLP-Datenverarbeitung besteht ein Stapel aus mehreren Sätzen und ein Satz aus mehreren Worteinbettungsmatrizen.
Zusammenfassen
BN: verschiedene Stichproben, gleiches Merkmal, normalisiert
LN: ein Satz, in jedes Wort eingebettete Merkmale, normalisiert