1. Einführung in XPath
XPath ist eine Sprache zum Auffinden von Informationen in XML-Dokumenten. Ursprünglich zum Durchsuchen von XML-Dokumenten konzipiert, kann aber auch zum Durchsuchen von HTML-Dokumenten verwendet werden.
2. Installieren Sie lxml
lxml ist eine Parsing-Bibliothek eines Drittanbieters für Python, unterstützt das Parsen von HTML und XML und ist äußerst effizient, wodurch die Mängel der XML-Standardbibliothek von Python beim XML-Parsen ausgeglichen werden.
So installieren Sie Bibliotheken von Drittanbietern:
pip install lxml
3. Prinzip der XPath-Analyse
- Instanziieren Sie ein Etree-Objekt. Die analysierten Seitenquelldaten müssen in das Objekt geladen werden.
- Rufen Sie die XPath-Methode im Etree-Objekt in Kombination mit XPath-Ausdrücken auf, um die Positionierung von Etiketten und die Erfassung von Inhalten zu realisieren.
4. Instanziieren Sie das Etree-Objekt
- Laden Sie die Quellcodedaten im lokalen HTML-Dokument in das Etree-Objekt:
etree.parse(filePath) - Laden Sie die aus dem Internet erhaltenen Quellcodedaten in das Objekt:
etree.HTML(response.text) - xpath('xpath expression')
5. XPath-Pfadausdruck
| Ausdruck | veranschaulichen |
|---|---|
| / | Wählen Sie aus dem Wurzelknoten aus |
| // | Stellt mehrere Ebenen dar, beginnend an einer beliebigen Position |
| . | Aktuellen Knoten auswählen |
| … | Wählen Sie den übergeordneten Knoten des aktuellen Knotens aus |
| @ | Attribut auswählen |
| //div[@class='title'] tag[@attrName=“attrValue“] | Attributpositionierung |
| //div[@class=“zhang“]/p[3] | Indexpositionierung, der Index beginnt bei 1 |
| /Text() | Was erhalten wird, ist der direkte Textinhalt im Etikett |
| //Text() | Nicht unmittelbarer Textinhalt in Tags (alle Textinhalte) |
| /@attrName ==>img/src | Nehmen Sie Attribute |
6. Kombiniert mit einer tatsächlichen Kampferklärung
Nehmen Sie zur Erläuterung die CSDN-Website als Beispiel
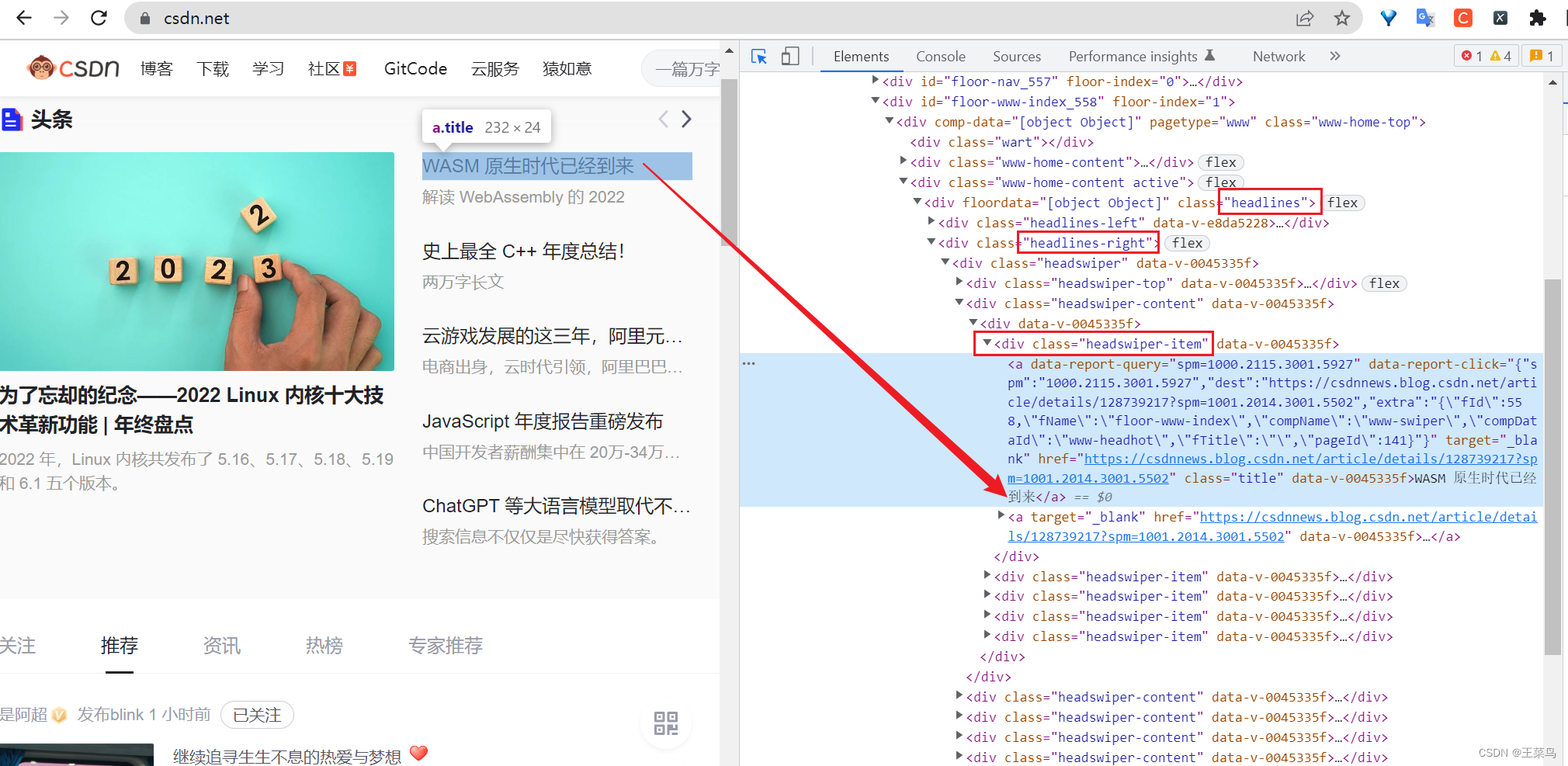
Beispiel: Hier möchte ich den Titel des Hauptblogs auf der Startseite der offiziellen Website abrufen, die Konsole öffnen (klicken Sie auf den kleinen Pfeil auf der Konsole oder drücken Sie gleichzeitig Strg + Umschalt + C), auf den Titel zeigen und Suchen Sie es entsprechend dem Klassenwert des div-Tags (dies ist normalerweise der Fall). Normalerweise verwenden wir mehr XPath-Syntax.
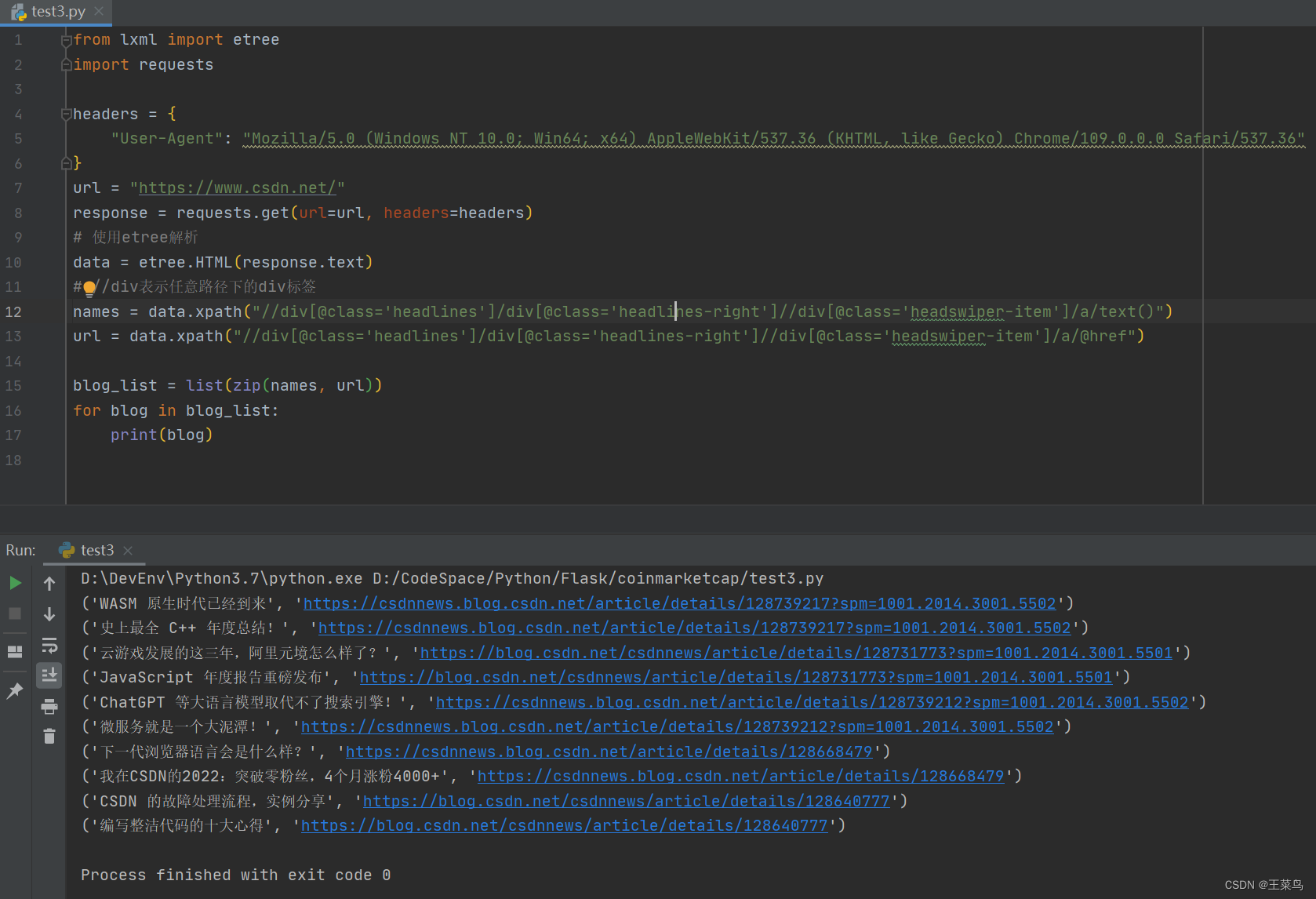
from lxml import etree
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
url = "https://www.csdn.net/"
response = requests.get(url=url, headers=headers)
# 使用etree解析
data = etree.HTML(response.text)
# //div表示任意路径下的div标签
names = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/text()")
url = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/@href")
blog_list = list(zip(names, url))
for blog in blog_list:
print(blog)
Erkennen Sie den Effekt: