ZooKeeper ist ein verteilter Koordinationsdienst, der von Apache verwaltet wird.
ZooKeeper kann als hochverfügbares Dateisystem betrachtet werden.
ZooKeeper kann für Funktionen wie Veröffentlichung/Abonnement, Lastausgleich, Befehlsdienst, verteilte Koordination/Benachrichtigung, Clusterverwaltung, Masterwahl, verteilte Sperre und verteilte Warteschlange verwendet werden.
Inhaltsverzeichnis
Was genau ist ZooKeeper? Ausführliche Erklärung von ZooKeeper 1. Einführung in ZooKeeper
1. Grundlegende Einführung in Zookeeper
2. Das Kernkonzept von ZooKeeper
3. Funktionsprinzip von ZooKeeper
Was genau ist ZooKeeper? Ausführliche Erklärung von ZooKeeper 1. Einführung in ZooKeeper
1. Grundlegende Einführung in Zookeeper
1.1 Was ist ZooKeeper?
ZooKeeper ist ein Apache-Top-Level-Projekt. ZooKeeper bietet effiziente und zuverlässige verteilte Koordinationsdienste für verteilte Anwendungen sowie verteilte Basisdienste wie einheitliche Namensdienste, Konfigurationsverwaltung und verteilte Sperren. Um die Konsistenz verteilter Daten zu lösen, verwendet ZooKeeper nicht direkt den Paxos-Algorithmus, sondern ein Konsensprotokoll namens ZAB.
ZooKeeper wird hauptsächlich zur Lösung des Konsistenzproblems von Anwendungssystemen in verteilten Clustern verwendet und kann Datenspeicherung basierend auf einem Verzeichnisknotenbaum ähnlich einem Dateisystem bereitstellen. Aber ZooKeeper wird nicht speziell zum Speichern von Daten verwendet, seine Hauptfunktion besteht darin, die Zustandsänderungen der gespeicherten Daten zu verwalten und zu überwachen. Durch die Überwachung der Änderungen dieser Datenzustände kann eine datenbasierte Clusterverwaltung erreicht werden.
Viele bekannte Frameworks basieren auf ZooKeeper, um eine verteilte Hochverfügbarkeit zu erreichen, z. B. Dubbo, Kafka usw.
1.2 Funktionen von ZooKeeper
ZooKeeper verfügt über die folgenden Funktionen:
-
Sequentielle Konsistenz: Das Datenmodell des Servers, das von allen Clients gesehen wird, ist konsistent; von einem Client initiierte Transaktionsanforderungen werden letztendlich in strikter Übereinstimmung mit der Reihenfolge, in der sie initiiert wurden, an ZooKeeper angewendet. Die spezifische Implementierung ist unten zu sehen: Atomic Broadcast.
-
Atomarität: Die Verarbeitungsergebnisse aller Transaktionsanforderungen werden konsistent auf alle Maschinen im gesamten Cluster angewendet, d. h. der gesamte Cluster wendet eine bestimmte Transaktion entweder erfolgreich an oder wendet sie überhaupt nicht an. Die Implementierung ist unten zu sehen: Transaktion.
-
Einzelansicht: Unabhängig davon, mit welchem Zookeeper-Server sich der Client verbindet, ist das serverseitige Datenmodell, das er sieht, konsistent.
-
Hohe Leistung: ZooKeeper speichert alle Daten im Speicher, daher ist die Leistung sehr hoch. Es ist zu beachten: Da alle Aktualisierungen und Löschungen von ZooKeeper auf Transaktionen basieren, weist ZooKeeper in Anwendungsszenarien mit mehr Lesevorgängen und weniger Schreibvorgängen eine bessere Leistung auf. Wenn der Schreibvorgang häufig erfolgt, wird die Leistung stark verringert.
-
Hohe Verfügbarkeit: Die hohe Verfügbarkeit von ZooKeeper basiert auf dem Kopiermechanismus. Darüber hinaus unterstützt ZooKeeper die Fehlerwiederherstellung, wie unten gezeigt: Wahlleiter.
1.3 Designziele von ZooKeeper
-
einfaches Datenmodell
-
Cluster können aufgebaut werden
-
Sequentieller Zugriff
-
Hochleistung
2. Das Kernkonzept von ZooKeeper
2.1 Datenmodell
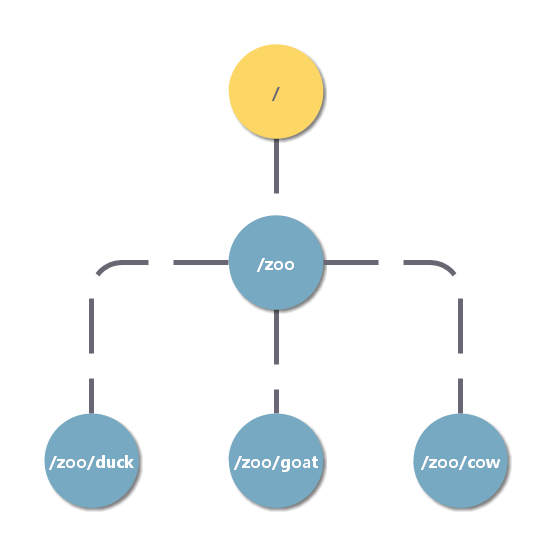
Das Datenmodell von ZooKeeper ist ein baumstrukturiertes Dateisystem.
Die Knoten im Baum werden Znodes genannt, wobei der Wurzelknoten / ist und jeder Knoten seine eigenen Daten und Knoteninformationen speichert. Ein Znode kann zum Speichern von Daten verwendet werden und verfügt über eine damit verbundene ACL (Einzelheiten finden Sie unter ACL). Das Designziel von ZooKeeper besteht darin, einen Koordinationsdienst zu implementieren, nicht wirklich als Dateispeicher, sodass die Größe der Znode-Speicherdaten auf 1 MB begrenzt ist.
Der Datenzugriff in ZooKeeper ist atomar. Seine Lese- und Schreibvorgänge sind entweder alle erfolgreich oder alle schlagen fehl.
Z-Knoten werden über den Pfad referenziert. Der Znode-Knotenpfad muss ein absoluter Pfad sein.
Es gibt zwei Arten von Znodes:
-
Ephemeral ( EPHEMERAL ): ZooKeeper löscht den ephemeren Znode, wenn die Clientsitzung endet.
-
Persistent (PERSISTENT): ZooKeeper löscht einen persistenten Znode nicht, es sei denn, der Client führt den Löschvorgang aktiv aus.
2.2 Knoteninformationen
Es gibt ein sequentielles Flag (SEQUENTIAL) auf dem Znode . Wenn beim Erstellen eines Znodes das Sequenzflag (SEQUENTIAL) gesetzt ist , verwendet ZooKeeper einen Zähler, um dem Znode einen monoton ansteigenden Wert hinzuzufügen, nämlich zxid. ZooKeeper verwendet zxid, um eine strenge sequentielle Zugriffskontrolle zu erreichen.
Beim Speichern von Daten verwaltet jeder Znode-Knoten eine Datenstruktur namens Stat, in der alle Statusinformationen über den Knoten gespeichert sind. folgendermaßen:

2.3 Clusterrollen
Der Zookeeper-Cluster ist ein Hochverfügbarkeitscluster, der auf Master-Slave-Replikation basiert und jeder Server übernimmt eine der folgenden drei Rollen.
-
Anführer: Er ist für die Initiierung und Aufrechterhaltung des Herzschlags bei jedem Follower und Observer verantwortlich. Alle Schreibvorgänge müssen vom Leader abgeschlossen werden, und dann sendet der Leader die Schreibvorgänge an andere Server. Ein Zookeeper-Cluster kann jeweils nur einen tatsächlich funktionierenden Leader haben.
-
Follower: Es reagiert auf den Herzschlag des Anführers. Der Follower kann die Leseanforderung des Clients direkt verarbeiten und zurücksenden und gleichzeitig die Schreibanforderung zur Verarbeitung an den Leader weiterleiten. Er ist für die Abstimmung über die Anfrage verantwortlich, wenn der Leader die Schreibanforderung verarbeitet. Ein Zookeeper-Cluster kann mehrere Follower gleichzeitig haben.
-
Beobachter: Die Rolle ist ähnlich wie Follower, hat aber kein Stimmrecht.
2.4 ACL
ZooKeeper verwendet ACL-Richtlinien (Access Control Lists) zur Berechtigungskontrolle.
Jeder Znode wird mit einer Liste von ACLs erstellt, die bestimmen, wer welche Vorgänge auf ihm ausführen kann.
ACLs basieren auf dem Client-Authentifizierungsmechanismus von ZooKeeper. ZooKeeper bietet die folgenden Authentifizierungsmethoden:
-
Digest: Benutzername und Passwort zur Identifizierung des Kunden
-
sasl: Identifizieren Sie den Client über Kerberos
-
IP: Identifizieren Sie den Client anhand der IP
ZooKeeper definiert die folgenden fünf Berechtigungen:
-
CREATE: Ermöglicht die Erstellung von untergeordneten Knoten;
-
LESEN: Ermöglicht das Abrufen von Daten von einem Knoten und das Auflisten seiner untergeordneten Knoten.
-
SCHREIBEN: Ermöglicht das Festlegen von Daten für einen Knoten.
-
DELETE: Ermöglicht das Löschen untergeordneter Knoten;
-
ADMIN: Ermöglicht das Festlegen von Berechtigungen für Knoten.
3. Funktionsprinzip von ZooKeeper
Schauen Sie sich mein Code-Verschiedenes-Forum an , um mehr zu erfahren.......
3.1 Lesevorgang
Leader/Follower/Observer können Leseanforderungen direkt verarbeiten, indem sie einfach Daten aus dem lokalen Speicher lesen und an den Client zurückgeben.
Da für die Verarbeitung von Leseanforderungen keine Interaktion zwischen Servern erforderlich ist, gilt: Je mehr Follower/Observer vorhanden sind, desto höher ist der Durchsatz der Leseanforderungen im Gesamtsystem , d. h. desto besser ist die Leseleistung.

3.2 Schreibvorgang
Alle Schreibanfragen werden tatsächlich zur Bearbeitung an den Leiter übergeben. Der Leader sendet die Schreibanforderung in Form einer Transaktion an alle Follower und wartet auf das ACK. Sobald mehr als die Hälfte der ACKs der Follower empfangen wurden, gilt der Schreibvorgang als erfolgreich.
3.2.1 Anführer schreiben

Wie aus der obigen Abbildung ersichtlich ist, ist der Schreibvorgang über Leader hauptsächlich in fünf Schritte unterteilt:
-
Der Client initiiert eine Schreibanfrage an den Leader.
-
Der Leader sendet die Schreibanforderung in Form eines Transaktionsvorschlags an alle Follower und wartet auf die Bestätigung.
-
Der Follower gibt ACK zurück, nachdem er den Transaktionsvorschlag des Leaders erhalten hat.
-
Leader sendet Commit an alle Follower und Observer, nachdem er mehr als die Hälfte der ACKs erhalten hat (Leader hat standardmäßig ein ACK für sich selbst).
-
Der Leiter gibt das Verarbeitungsergebnis an den Kunden zurück.
Notiz
-
Der Anführer muss keine Bestätigung vom Beobachter erhalten, das heißt, der Beobachter hat kein Stimmrecht.
-
Der Leader muss nicht von allen Followern ACKs erhalten, er muss nur mehr als die Hälfte der ACKs erhalten. Gleichzeitig hat der Leader selbst ein ACK für sich. In der obigen Abbildung gibt es 4 Follower, nur zwei von ihnen müssen ACK zurückgeben, da $$(2+1) / (4+1) > 1/2$$.
-
Obwohl Observer kein Stimmrecht hat, muss er dennoch die Daten von Leader synchronisieren, damit dieser bei der Verarbeitung von Leseanfragen möglichst aktuelle Daten zurückgeben kann.
3.2.2 und Follower/Beobachter

Sowohl Follower als auch Observer können Schreibanfragen annehmen, diese jedoch nicht direkt verarbeiten, sondern müssen die Schreibanfragen zur Verarbeitung an Leader weiterleiten.
Abgesehen von einem weiteren Schritt der Anforderungsweiterleitung unterscheiden sich die anderen Prozesse nicht vom direkten Schreiben an den Leader.
3.3 Transaktionen
Für jede Aktualisierungsanforderung des Clients verfügt ZooKeeper über strenge sequentielle Zugriffskontrollfunktionen.
Um die sequentielle Konsistenz von Transaktionen sicherzustellen, verwendet ZooKeeper eine steigende Transaktions-ID-Nummer (zxid), um Transaktionen zu identifizieren.
Der Leader-Dienst weist jedem Follower-Server eine separate Warteschlange zu, stellt dann nacheinander den Transaktionsvorschlag in die Warteschlange und sendet Nachrichten gemäß der FIFO-Strategie (First In, First Out). Nachdem der Follower-Dienst den Vorschlag erhalten hat, schreibt er ihn in Form eines Transaktionsprotokolls auf die lokale Festplatte und gibt nach erfolgreichem Schreiben eine Bestätigungsantwort an den Leader zurück. Wenn der Leader mehr als die Hälfte der Ack-Antworten der Follower erhält, sendet er eine Commit-Nachricht an alle Follower, um sie zu benachrichtigen, die Transaktion festzuschreiben, und dann führt der Leader die Transaktionsfestschreibung selbst durch. Und jeder Follower schließt die Festschreibung der Transaktion ab, nachdem er die Festschreibungsnachricht erhalten hat.
Bei allen Vorschlägen wird zxid hinzugefügt, wenn sie vorgeschlagen werden. zxid ist eine 64-Bit-Zahl, und ihre oberen 32 Bits werden von der Epoche verwendet, um zu identifizieren, ob sich die Anführerbeziehung geändert hat. Jedes Mal, wenn ein Anführer gewählt wird, gibt es eine neue Epoche, die die aktuelle Regierungsperiode dieses Anführers identifiziert. Die unteren 32 Bit werden zum Hochzählen verwendet.
Der detaillierte Ablauf ist wie folgt:
-
Leader wartet auf Serververbindung;
-
Der Follower stellt eine Verbindung zum Leader her und sendet die größte zxid an den Leader.
-
Der Anführer bestimmt den Synchronisationspunkt gemäß der zxid des Anhängers.
-
Benachrichtigen Sie den Follower nach Abschluss der Synchronisierung darüber, dass der Status aktuell ist.
-
Nachdem der Follower die Aktualisierungsnachricht erhalten hat, kann er die Serviceanfrage des Clients erneut annehmen.
3.4 Beobachtung
Der Client registriert sich, um den Znode zu überwachen, um den er sich kümmert. Wenn sich der Status des Znodes ändert (Datenänderung, Erhöhung oder Verringerung des untergeordneten Knotens), benachrichtigt der ZooKeeper-Dienst den Client.
Es gibt im Allgemeinen zwei Formen, die Verbindung zwischen Client und Server aufrechtzuerhalten:
-
Der Client fragt weiterhin den Server ab
-
Der Server übermittelt den Status an den Client
Die Wahl von Zookeeper besteht darin, den Status des Servers aktiv zu pushen, bei dem es sich um einen Beobachtungsmechanismus (Watch) handelt.
Der Beobachtungsmechanismus von ZooKeeper ermöglicht es Benutzern, Listener für interessierte Ereignisse auf bestimmten Knoten zu registrieren. Wenn ein Ereignis auftritt, wird der Listener ausgelöst und die Ereignisinformationen werden an den Client übertragen.
Wenn der Client eine Schnittstelle wie getData verwendet, um den Znode-Status abzurufen, wird ein Rückruf zur Verarbeitung von Knotenänderungen übergeben, und der Server überträgt die Knotenänderungen dann aktiv an den Client:
Das von dieser Methode übergebene Watcher-Objekt implementiert die entsprechende Prozessmethode. Jedes Mal, wenn sich der Status des entsprechenden Knotens ändert, ruft der WatchManager die an den Watcher übergebene Methode auf folgende Weise auf:
Set<Watcher> triggerWatch(String path, EventType type, Set<Watcher> supress) { WatchedEvent e = new WatchedEvent(type, KeeperState.SyncConnected, path); Set<Watcher> watchers; synchronized (this) { watchers = watchTable.remove(path); } for (Watcher w : watchers) { w.process(e); } returnAlle Daten in Zookeeper werden tatsächlich von einer Datenstruktur namens DataTree verwaltet. Alle Anforderungen zum Lesen und Schreiben von Daten ändern letztendlich den Inhalt dieses Baums. Wenn eine Leseanforderung ausgegeben wird, kann sie an Watcher übergeben werden, um eine Rückruffunktion zu registrieren. Das Schreiben Die Anfrage kann den entsprechenden Rückruf auslösen und der WatchManager benachrichtigt den Client über die Datenänderung.
Die Implementierung des Benachrichtigungsmechanismus ist eigentlich relativ einfach: Stellen Sie den Watcher so ein, dass er das Ereignis über die Leseanforderung abhört, und die Schreibanforderung kann die Benachrichtigung an den angegebenen Client senden, wenn das Ereignis ausgelöst wird.
3,5 Sitzung
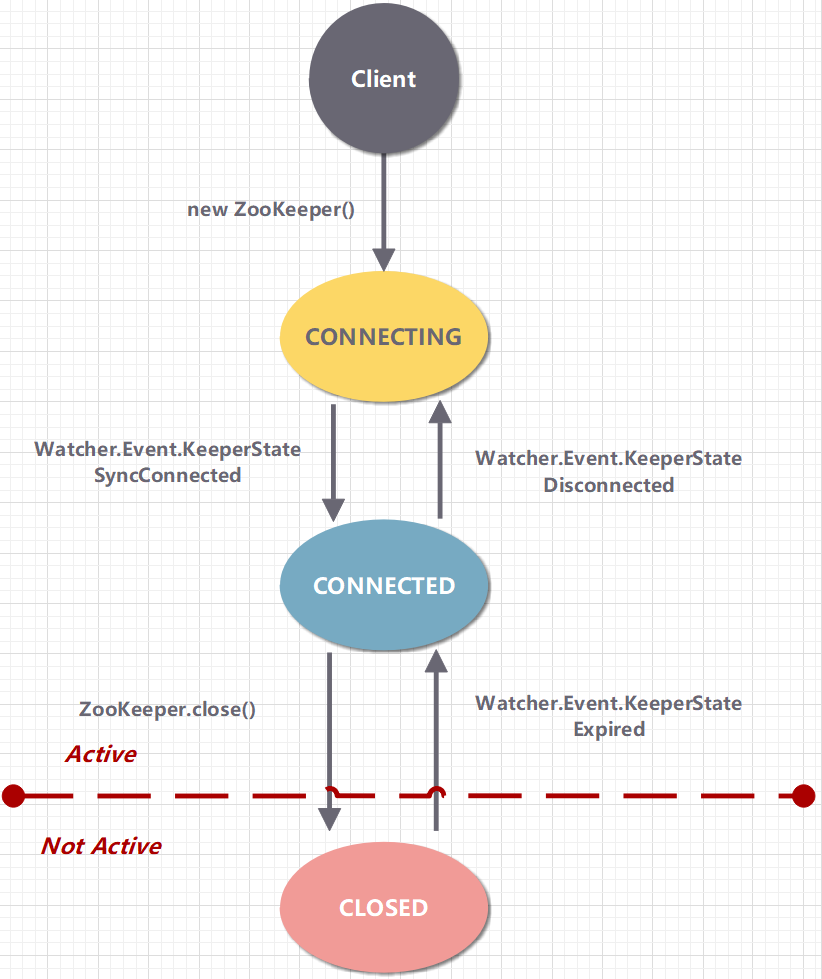
Der ZooKeeper-Client stellt über eine lange TCP-Verbindung eine Verbindung zum ZooKeeper-Dienstcluster her. Die Sitzung (Sitzung) wurde von der ersten Verbindung an hergestellt und behält dann über den Heartbeat-Erkennungsmechanismus einen gültigen Sitzungsstatus bei . Über diese Verbindung kann der Client Anfragen senden und Antworten empfangen sowie Benachrichtigungen über Watch-Ereignisse erhalten.
In jeder ZooKeeper-Clientkonfiguration wird eine Liste von ZooKeeper-Serverclustern konfiguriert. Beim Start durchläuft der Client die Liste und versucht, eine Verbindung herzustellen. Wenn dies fehlschlägt, versucht es, eine Verbindung zum nächsten Server herzustellen usw.
Sobald ein Client eine Verbindung mit einem Server herstellt, erstellt der Server eine neue Sitzung für den Client. Jede Sitzung hat eine Zeitüberschreitung. Wenn der Server innerhalb der Zeitüberschreitung keine Anfrage erhält, gilt die entsprechende Sitzung als abgelaufen. Sobald eine Sitzung abläuft, kann sie nicht erneut geöffnet werden und alle mit der Sitzung verknüpften temporären Z-Knoten werden gelöscht.
Im Allgemeinen sollten Sitzungen von langer Dauer sein, und dies muss vom Kunden gewährleistet werden. Der Client kann den Ablauf der Sitzung mittels Heartbeat (Ping) verhindern.
Eine ZooKeeper-Sitzung verfügt über vier Attribute
-
sessionID: Sitzungs-ID, die eine Sitzung eindeutig identifiziert. Jedes Mal, wenn ein Client eine neue Sitzung erstellt, weist Zookeeper ihr eine global eindeutige Sitzungs-ID zu.
-
TimeOut: Die Zeitüberschreitungszeit der Sitzung. Wenn der Client eine Zookeeper-Instanz erstellt, konfiguriert er den Parameter sessionTimeout, um die Zeitüberschreitungszeit der Sitzung anzugeben. Nachdem der Zookeeper-Client die Zeitüberschreitungszeit an den Server gesendet hat, bestimmt der Server die Sitzung schließlich anhand seiner Eigenes Timeout-Zeitlimit Timeout-Zeitraum.
-
TickTime: Der nächste Sitzungs-Timeout-Zeitpunkt. Um Zookeeper die Implementierung der „Bucket-Strategie“-Verwaltung für Sitzungen zu erleichtern und die Sitzungs-Timeout-Überprüfung und -Bereinigung effizient und kostengünstig zu implementieren, markiert Zookeeper für jede Sitzung einen nächsten Sitzungs-Timeout-Zeitpunkt , dessen Wert ungefähr der aktuellen Zeit plus TimeOut entspricht.
-
isClosing: Markieren Sie, ob eine Sitzung geschlossen wurde. Wenn der Server erkennt, dass die Sitzung abgelaufen ist, markiert er isClosing der Sitzung als „geschlossen“, um sicherzustellen, dass keine neuen Anforderungen aus der Sitzung verarbeitet werden.
Die Sitzungsverwaltung von Zookeeper erfolgt hauptsächlich über SessionTracker, der eine Bucketing-Strategie (Verwaltung ähnlicher Sitzungen im selben Block) für die Verwaltung anwendet, sodass Zookeeper Sitzungen in verschiedenen Blöcken und demselben Block isolieren kann Einheitliche Verarbeitung.
Schauen Sie sich mein Code-Verschiedenes-Forum an , um mehr zu erfahren.......
4. ZAB-Vereinbarung
ZooKeeper verwendet nicht direkt den Paxos-Algorithmus, sondern ein Konsensprotokoll namens ZAB. Das ZAB-Protokoll ist nicht der Paxos-Algorithmus, aber es ist ähnlich und die beiden funktionieren nicht gleich.
Das ZAB-Protokoll ist ein atomares Broadcast-Protokoll, das speziell von Zookeeper zur Unterstützung der Wiederherstellung nach einem Absturz entwickelt wurde.
Das ZAB-Protokoll ist die Datenkonsistenz- und Hochverfügbarkeitslösung von ZooKeeper.
Das ZAB-Protokoll definiert zwei Prozesse , die eine Endlosschleife ausführen können:
-
Wahlleiter: Wird zur Fehlerbehebung verwendet, um eine hohe Verfügbarkeit sicherzustellen.
-
Atomic Broadcast: Wird für die Master-Slave-Synchronisation verwendet, um die Datenkonsistenz sicherzustellen.
4.1 Wahlleiter
Wiederherstellung nach ZooKeeper-Fehlern
Der ZooKeeper-Cluster verwendet einen Master-Modus (genannt Leader) und mehrere Slaves (genannt Follower), und die Master- und Slave-Knoten stellen durch den Kopiermechanismus die Datenkonsistenz sicher.
-
Wenn der Follower-Knoten aufhängt, behält jeder Knoten im ZooKeeper-Cluster seinen eigenen Status im Speicher unabhängig bei und die Kommunikation zwischen den Knoten wird aufrechterhalten. Solange die Hälfte der Maschinen im Cluster normal arbeiten kann, kann der gesamte Cluster normal arbeiten dienen.
-
Wenn der Leader-Knoten ausgefallen ist – Wenn der Leader-Knoten ausgefallen ist, funktioniert das System nicht ordnungsgemäß. Zu diesem Zeitpunkt muss die Fehlerwiederherstellung über den Leader-Wahlmechanismus des ZAB-Protokolls durchgeführt werden.
Der Leader-Wahlmechanismus des ZAB-Protokolls ist einfach: Basierend auf dem Mehrheitswahlmechanismus wird ein neuer Leader generiert, und dann synchronisieren andere Maschinen ihren Status mit dem neuen Leader. Wenn mehr als die Hälfte der Maschinen die Statussynchronisierung abgeschlossen haben, werden sie dies tun Verlassen Sie den Wahlleitermodus und wechseln Sie zum Atomic-Broadcast-Modell.
4.1.1 Terminologie
myid: Jeder Zookeeper-Server muss im Datenordner eine Datei mit dem Namen myid erstellen, die die eindeutige ID (Ganzzahl) des gesamten Zookeeper-Clusters enthält.
zxid: Ähnlich wie die Transaktions-ID in RDBMS wird sie zur Identifizierung der Vorschlags-ID eines Aktualisierungsvorgangs verwendet. Um die Ordnung zu gewährleisten, muss der zkid monoton steigend sein. Daher verwendet Zookeeper zur Darstellung eine 64-Bit-Zahl, und die oberen 32 Bit stellen die Epoche des Anführers dar. Beginnend bei 1 wird die Epoche jedes Mal, wenn ein neuer Anführer ausgewählt wird, um eins erhöht. Die unteren 32 Bit sind die Seriennummer in der Epoche, und jedes Mal, wenn sich die Epoche ändert, wird die untere 32-Bit-Seriennummer zurückgesetzt. Dadurch wird das globale Inkrement von zkid sichergestellt.
4.1.2 Serverstatus
-
SUCHEN: Unsicher über den Leader-Status. Der Server in diesem Zustand geht davon aus, dass es im aktuellen Cluster keinen Anführer gibt, und initiiert eine Anführerwahl.
-
FOLGENDES: Follower-Status. Zeigt an, dass die aktuelle Serverrolle „Follower“ ist und weiß, wer der Anführer ist.
-
LEADING: Führungsstatus. Zeigt an, dass die aktuelle Serverrolle „Leader“ ist und dass der Heartbeat mit dem „Follower“ aufrechterhalten wird.
-
BEOBACHTUNG: Beobachterstatus. Zeigt an, dass die aktuelle Serverrolle Observer ist. Der einzige Unterschied zu Follower besteht darin, dass er während Cluster-Schreibvorgängen nicht an Wahlen und Abstimmungen teilnimmt.
4.1.3 Stimmzetteldatenstruktur
Wenn jeder Server die Wahl des Anführers durchführt, sendet er die folgenden Schlüsselinformationen:
-
LogicClock: Jeder Server verwaltet eine sich selbst erhöhende Ganzzahl namens LogicClock, die die Anzahl der vom Server initiierten Abstimmungsrunden angibt.
-
state: der aktuelle Status des Servers.
-
self_id: myid des aktuellen Servers.
-
self_zxid: die maximale zxid der auf dem aktuellen Server gespeicherten Daten.
-
vote_id: die myid des gewählten Servers.
-
vote_zxid: Die maximale zxid der auf dem empfohlenen Server gespeicherten Daten.
4.1.4 Abstimmungsprozess
(1) Sich selbst steigernde Wahlrunden
Zookeeper schreibt vor, dass alle gültigen Stimmen in derselben Runde abgegeben werden müssen. Wenn jeder Server eine neue Abstimmungsrunde startet, führt er zunächst einen automatischen Inkrementierungsvorgang für die von ihm verwaltete LogicClock durch.
(2) Initialisieren Sie den Stimmzettel
Jeder Server leert seine eigene Wahlurne, bevor er seine eigene Stimme ausstrahlt. In dieser Wahlurne werden die eingegangenen Stimmzettel erfasst. Beispiel: Server 2 stimmt für Server 3 und Server 3 stimmt für Server 1, dann lauten die Wahlurnen von Server 1 (2, 3), (3, 1), (1, 1). In der Wahlurne wird nur die letzte Stimme jedes Wählers aufgezeichnet. Wenn ein Wähler seinen eigenen Stimmzettel aktualisiert, aktualisieren andere Server den Stimmzettel des Servers in ihrer eigenen Wahlurne, nachdem sie den neuen Stimmzettel erhalten haben.
(3) Senden Sie den Initialisierungsstimmzettel
Jeder Server stimmt zunächst per Broadcast für sich selbst ab.
(4) Externe Stimmen erhalten
Der Server wird versuchen, Stimmen von anderen Servern zu erhalten und diese in seine eigene Wahlurne zu werfen. Wenn er keine externen Stimmen erhalten kann, bestätigt er, ob er eine gültige Verbindung mit anderen Servern im Cluster aufrechterhält. Wenn ja, senden Sie Ihre eigene Stimme erneut; wenn nein, stellen Sie sofort eine Verbindung dazu her.
(5) Beurteilung der Wahlrunde
Nach Erhalt einer externen Abstimmung führt es zunächst eine unterschiedliche Verarbeitung gemäß der in den Abstimmungsinformationen enthaltenen Logikuhr durch:
-
Der LogicClock der externen Abstimmung ist größer als sein eigener LogicClock. Dies bedeutet, dass die Wahlrunde dieses Servers hinter den Wahlrunden anderer Server liegt. Leeren Sie sofort Ihre Wahlurne und aktualisieren Sie Ihre LogicClock auf die empfangene LogicClock. Vergleichen Sie dann Ihre vorherigen Stimmen mit den erhaltenen Stimmen, um festzustellen, ob Sie Ihre Stimme ändern müssen , und senden Sie Ihre Stimme endlich noch einmal.
-
Der LogicClock der externen Abstimmung ist kleiner als sein eigener LogicClock. Der aktuelle Server ignoriert die Abstimmung direkt und verarbeitet die nächste Abstimmung weiter.
-
Die LogikkClock der externen Stimme ist gleich ihrer eigenen . Zu diesem Zeitpunkt wurde eine Abstimmungs-PK durchgeführt.
(6) Stimmzettel-PK
Die Abstimmungs-PK basiert auf dem Vergleich zwischen (self_id, self_zxid) und (vote_id, vote_zxid):
-
Wenn der LogicClock der externen Abstimmung größer ist als Ihr eigener LogicClock, ändern Sie Ihren eigenen LogicClock und den LogicClock Ihres eigenen Stimmzettels in den empfangenen LogicClock.
-
Wenn die Logikuhr konsistent ist , vergleichen Sie die vote_zxid der beiden. Wenn die vote_zxid der externen Abstimmung relativ groß ist, aktualisieren Sie vote_zxid und vote_myid in Ihrer eigenen Abstimmung auf vote_zxid und vote_myid in der empfangenen Abstimmung und senden Sie sie. Darüber hinaus ist die erhaltene Stimme und Ihr eigenes aktualisiertes Ticket in Ihre eigene Wahlurne. Wenn der gleiche Stimmzettel (self_myid, self_zxid) bereits in der Wahlurne vorhanden ist, wird er direkt überschrieben.
-
Wenn die vote_zxid der beiden gleich ist, vergleichen Sie die vote_myid der beiden. Wenn die vote_myid der externen Abstimmung größer ist, aktualisieren Sie die vote_myid in Ihrer eigenen Abstimmung auf die vote_myid in der empfangenen Abstimmung und senden Sie sie. Außerdem die empfangene Abstimmung und Ihre eigene Das aktualisierte Ticket wird in eine eigene Wahlurne gelegt.
(7) Auszählung der Stimmen
Wenn festgestellt wurde, dass mehr als die Hälfte der Server ihre Abstimmung genehmigt haben (möglicherweise eine aktualisierte Abstimmung), wird die Abstimmung beendet. Andernfalls erhalten Sie weiterhin Stimmen von anderen Servern.
(8) Serverstatus aktualisieren
Nachdem die Abstimmung beendet ist, beginnt der Server, seinen eigenen Status zu aktualisieren. Wenn mehr als die Hälfte der Stimmen für Sie selbst ist, aktualisieren Sie Ihren Serverstatus auf FÜHREND, andernfalls aktualisieren Sie Ihren Serverstatus auf FOLGEND.
Durch die Analyse des obigen Prozesses können wir leicht erkennen, dass die Anzahl der ZooKeeper-Clusterknoten eine ungerade Zahl sein muss, damit der Leader die Unterstützung der meisten Server erhält . Und die Anzahl der überlebenden Knoten darf nicht kleiner als N + 1 sein .
Der obige Vorgang wird nach jedem Serverstart wiederholt. Wenn sich der Server im Wiederherstellungsmodus gerade nach einem Absturz erholt hat oder gerade erst gestartet wurde, werden Daten und Sitzungsinformationen aus Festplatten-Snapshots wiederhergestellt, und zk zeichnet Transaktionsprotokolle auf und erstellt regelmäßig Snapshots, um die Statuswiederherstellung während der Wiederherstellung zu erleichtern.
4.2 Atomsendung
ZooKeeper erreicht eine hohe Verfügbarkeit durch einen Replikatmechanismus.
Wie implementiert ZooKeeper den Replikationsmechanismus? Die Antwort lautet: Atomic Broadcast des ZAB-Protokolls.

Die atomaren Broadcast-Anforderungen des ZAB-Protokolls:
Alle Schreibanfragen werden an den Leader weitergeleitet und der Leader benachrichtigt den Follower in einer atomaren Übertragung. Wenn mehr als die Hälfte der Follower den Status aktualisiert und beibehalten hat, übermittelt der Leader das Update und der Client erhält eine Antwort, dass das Update erfolgreich war. Dies ähnelt in gewisser Weise dem zweiphasigen Festschreibungsprotokoll in Datenbanken.
Während des Broadcast-Prozesses der gesamten Nachricht generiert der Leader-Server für jede Transaktionsanforderung einen entsprechenden Vorschlag, weist ihm eine global eindeutige inkrementelle Transaktions-ID (ZXID) zu und sendet ihn dann.
Schauen Sie sich mein Code-Verschiedenes-Forum an , um mehr zu erfahren.......
5. ZooKeeper-Anwendung
ZooKeeper kann für Funktionen wie Veröffentlichung/Abonnement, Lastausgleich, Befehlsdienst, verteilte Koordination/Benachrichtigung, Clusterverwaltung, Masterwahl, verteilte Sperre und verteilte Warteschlange verwendet werden.
5.1 Namensdienst
In einem verteilten System ist normalerweise ein global eindeutiger Name erforderlich, z. B. die Generierung einer global eindeutigen Bestellnummer usw. ZooKeeper kann anhand der Merkmale aufeinanderfolgender Knoten eine global eindeutige ID generieren und so Benennungsdienste für verteilte Systeme bereitstellen.

5.2 Konfigurationsmanagement
Mithilfe des Beobachtungsmechanismus von ZooKeeper kann es als hochverfügbarer Konfigurationsspeicher verwendet werden, sodass Teilnehmer an verteilten Anwendungen Konfigurationsdateien abrufen und aktualisieren können.
5.3 Verteilte Sperren
Verteilte Sperren können über die temporären Knoten und den Watcher-Mechanismus von ZooKeeper implementiert werden.
Beispielsweise gibt es ein verteiltes System mit drei Knoten A, B und C, die versuchen, verteilte Sperren über ZooKeeper zu erhalten.
(1) Besuchen Sie /lock (dieser Verzeichnispfad wird vom Programm selbst bestimmt) und erstellen Sie einen temporären Knoten (EPHEMERAL) mit einer Seriennummer.
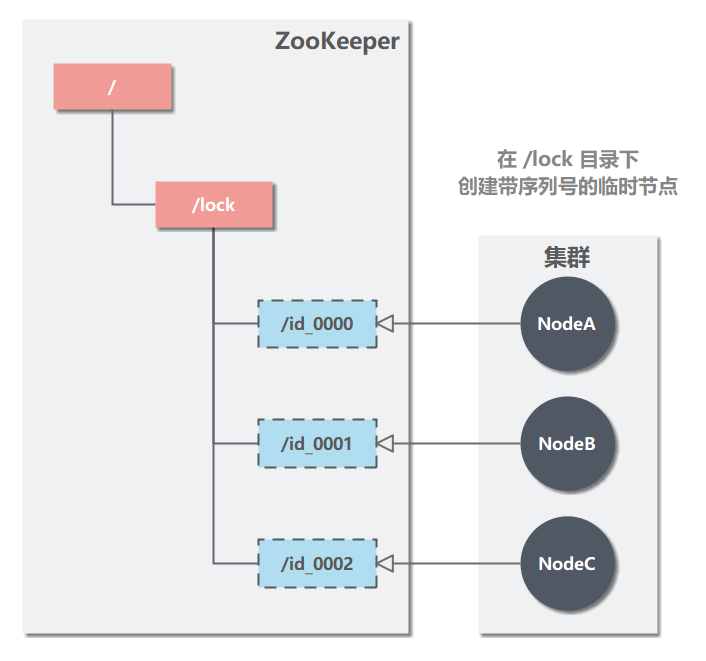
(2) Wenn jeder Knoten versucht, eine Sperre zu erhalten, ruft er alle untergeordneten Knoten (id_0000, id_0001, id_0002) unter dem Knoten / locks ab und beurteilt, ob der von ihm selbst erstellte Knoten der kleinste ist.
-
Wenn ja, besorgen Sie sich das Schloss.
Sperre aufheben: Nachdem Sie den Vorgang ausgeführt haben, löschen Sie den erstellten Knoten.
-
Wenn nicht, überwachen Sie die Änderung des Knotens, der um 1 kleiner als er selbst ist.
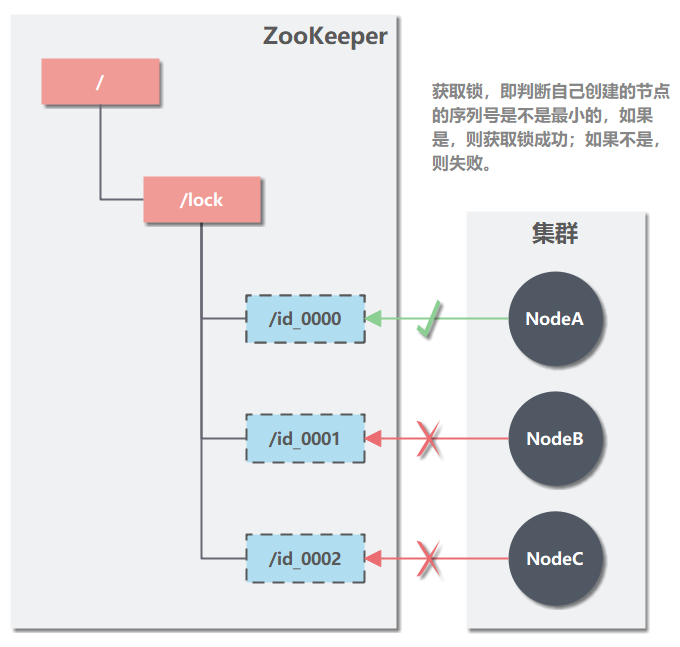
(3) Lösen Sie die Sperre, dh löschen Sie den von Ihnen erstellten Knoten.

In der Abbildung löscht NodeA den von ihm selbst erstellten Knoten id_0000, und NodeB erkennt die Änderung und stellt fest, dass sein eigener Knoten bereits der kleinste Knoten ist, sodass er die Sperre erwerben kann.
5.4 Cluster-Management
ZooKeeper löst auch die meisten Probleme in verteilten Systemen:
-
Beispielsweise kann durch die Erstellung eines temporären Knotens ein Heartbeat-Erkennungsmechanismus eingerichtet werden. Wenn ein Dienstknoten des verteilten Systems ausfällt, läuft die von ihm gehaltene Sitzung ab. Zu diesem Zeitpunkt wird der temporäre Knoten gelöscht und das entsprechende Überwachungsereignis ausgelöst.
-
Jeder Dienstknoten des verteilten Systems kann auch seinen eigenen Knotenstatus auf den temporären Knoten schreiben, um den Statusbericht oder den Arbeitsfortschrittsbericht des Knotens zu vervollständigen.
-
Durch die Datenabonnement- und Veröffentlichungsfunktionen kann ZooKeeper auch Module entkoppeln und Aufgaben für verteilte Systeme planen.
-
Durch den Überwachungsmechanismus können die Dienstknoten des verteilten Systems auch dynamisch online und offline sein, um die dynamische Erweiterung von Diensten zu realisieren.
5.5 Wahl der Leader-Knoten
Ein wichtiger Modus eines verteilten Systems ist der Master-Slave-Modus (Master/Salves), und ZooKeeper kann in diesem Modus für die Matser-Auswahl verwendet werden. Alle Dienstknoten können im Wettbewerb denselben ZNode erstellen. Da ZooKeeper keine ZNodes mit demselben Pfad haben kann, muss nur ein Dienstknoten erfolgreich erstellt werden, damit der Dienstknoten zum Masterknoten werden kann.
5.6 Warteschlangenverwaltung
ZooKeeper kann zwei Arten von Warteschlangen verarbeiten:
-
Wenn alle Mitglieder einer Warteschlange gesammelt sind, ist die Warteschlange verfügbar, andernfalls wartet sie auf das Eintreffen aller Mitglieder. Dies ist eine synchrone Warteschlange.
-
Die Warteschlange führt Enqueue- und Dequeue-Vorgänge gemäß der FIFO-Methode durch, z. B. die Implementierung von Produzenten- und Konsumentenmodellen.
Die von ZooKeeper implementierte Implementierungsidee der synchronen Warteschlange lautet wie folgt:
Erstellen Sie ein übergeordnetes Verzeichnis /synchronizing. Jedes Mitglied überwacht, ob das Flag (Set Watch) im Verzeichnis /synchronizing/start vorhanden ist, und dann tritt jedes Mitglied dieser Warteschlange bei. Der Beitritt zur Warteschlange besteht darin, einen temporären Verzeichnisknoten von /synchronizing/ zu erstellen. member_i, jedes Mitglied erhält dann alle Verzeichnisknoten des /synchronizing-Verzeichnisses, das member_i ist. Bestimmen Sie, ob der Wert von i bereits der Anzahl der Mitglieder entspricht. Wenn er kleiner als die Anzahl der Mitglieder ist, warten Sie, bis /synchronizing/start angezeigt wird. Wenn er bereits gleich ist, erstellen Sie /synchronizing/start.
Schauen Sie sich mein Code-Verschiedenes-Forum an , um mehr zu erfahren.......