Ebene 1: Verwenden Sie die URL, um die Hypertextdatei abzurufen und lokal zu speichern
Implementierungscode:
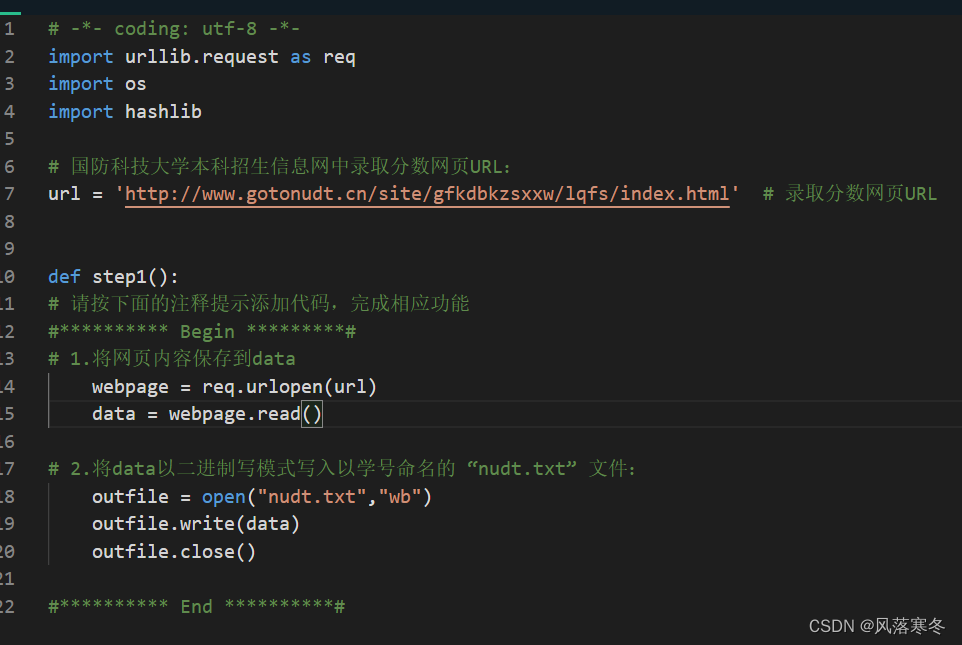
# -*- Codierung: utf-8 -*-
Importieren Sie urllib.request als Anforderung
Importieren Sie uns
Hashlib importieren
# Webseiten-URL für Zulassungsinformationen zum Undergraduate Admissions Network der National University of Defence Technology:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # URL der Zulassungsbewertungsseite
def step1():
# Bitte folgen Sie dem Kommentar unten, um Code hinzuzufügen, um die entsprechende Funktion abzuschließen
#********** Start *********#
# 1. Speichern Sie den Inhalt der Webseite in Daten
webpage = req.urlopen(url)
data = webpage.read()
# 2. Schreiben Sie die Daten im binären Schreibmodus in die nach der Matrikelnummer benannte Datei „nudt.txt“:
outfile = open("nudt.txt","wb")
outfile.write(data)
outfile.close()
#********** Ende **********#
Durchgang 2: Sublinks extrahieren
Implementierungscode:
# -*- Codierung: utf-8 -*-
Importieren Sie urllib.request als Anforderung
# Webseiten-URL für Zulassungsinformationen zum Undergraduate Admissions Network der National University of Defence Technology:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # URL der Zulassungsbewertungsseite
webpage = req.urlopen(url) # Öffnen Sie die Webseite als Klassendatei
data = webpage.read() # Alle Daten der Webseite gleichzeitig lesen
data = data.decode('utf-8') # Dekodieren Sie die Bytetypdaten in eine Zeichenfolge (andernfalls werden sie später separat verarbeitet).
def step2():
# Erstellen Sie eine leere Liste mit URLs, um die URLs von Unterseiten zu speichern
URLs = []
# Bitte folgen Sie dem Kommentar unten, um Code hinzuzufügen, um die entsprechende Funktion abzuschließen
#********** Start *********#
# Extrahieren Sie die Unterseitenadresse der Bruchlinie 2016 bis 2012 für jedes Jahr aus den Daten und fügen Sie sie der URL-Liste hinzu
Jahre = [2016, 2015, 2014, 2013,2012]
für Jahr in Jahren:
index = data.find("National University of Defence Technology %s Jahr Zulassungsbewertungsstatistik" %year)
href = data[index-80:index-39] # Extrahieren Sie URL-Teilzeichenfolgen entsprechend jeder charakteristischen Zeichenfolge
website = 'http://www.gotonudt.cn'
urls.append(website+href)
#********** Ende **********#
Rückgabe-URLs

Ebene 3: Webseitendatenanalyse
Implementierungscode:
# -*- Codierung: utf-8 -*-
Importieren Sie urllib.request als Anforderung
Import bzgl
# URL der Webseite zur Zulassungsbewertung 2016 im Undergraduate Admissions Information Network der National University of Defence Technology:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2017/717.html'
webpage = req.urlopen(url) # Besuchen Sie die verlinkte Webseite gemäß dem Hyperlink
data = webpage.read() # Hyperlink-Webseitendaten lesen
data = data.decode('utf-8') # Bytetyp in String dekodieren
# Holen Sie sich den gesamten Inhalt der ersten Tabelle auf der Webseite:
table = re.findall(r'<table(.*?)</table>', data, re.S)
firsttable = table[0] # Ruft die erste Tabelle auf der Webseite ab
# Datenbereinigung, , \u3000 und Leerzeichen in der Tabelle entfernen
firsttable = firsttable.replace(' ', '')
firsttable = firsttable.replace('\u3000', '')
firsttable = firsttable.replace('', '')
def step3():
Punktzahl = []
# Bitte fügen Sie Code gemäß dem Kommentar unten hinzu, um die entsprechende Funktion abzuschließen. Um den detaillierten HTML-Code anzuzeigen, können Sie die URL im Browser öffnen, um den Quellcode der Seite anzuzeigen.
#********** Start *********#
# 1. Drücken Sie das tr-Tag, um alle Zeilen in der Tabelle abzurufen und sie in den Listenzeilen zu speichern:
rows = re.findall(r'<tr(.*?)</tr>', firsttable, re.S)
# 2. Durchlaufen Sie alle Elemente in Zeilen, rufen Sie die Daten im td-Tag jeder Zeile ab, formen Sie die Daten in eine Elementliste und fügen Sie jedes Element zur Bewertungslistenliste hinzu:
Punkteliste = []
für Zeile in Zeilen:
Artikel = []
tds = re.findall(r'<td.*?>(.*?)</td>', row, re.S)
für td in tds:
rightindex = td.find('</span>') # return -1 bedeutet nicht gefunden
leftindex = td[:rightindex].rfind('>')
items.append(td[leftindex+1:rightindex])
scorelist.append(items)
# 3. Speichern Sie die 7-Elemente-Liste bestehend aus Provinzen und Bewertungen (wenn die Bewertung nicht vorhanden ist, ersetzen Sie sie durch \) als Element in der neuen Listenbewertung. Speichern Sie keine redundanten Informationen
zur Aufnahme in Scorelist[3:]:
record.pop()
score.append(record)
#********** Ende **********#
Ergebnis zurückgeben
