GPUs sind ein knappes Gut, seit große Modelle ein heißer Trend geworden sind. Die Rücklagen vieler Unternehmen reichen nicht unbedingt aus, geschweige denn einzelner Entwickler. Gibt es eine Möglichkeit, Rechenleistung zu nutzen, um Modelle effizienter zu trainieren?
In einem kürzlich erschienenen Blog stellte Sebastian Raschka die Methode der „Gradientenakkumulation“ vor, die bei begrenztem GPU-Speicher ein Trainingsmodell mit größerer Batchgröße verwenden und so Hardwareeinschränkungen umgehen kann.
Zuvor veröffentlichte Sebastian Raschka auch einen Artikel über die Verwendung von Multi-GPU-Trainingsstrategien zur Beschleunigung der Feinabstimmung von Sprachmodellen in großem Maßstab, einschließlich Mechanismen wie Modell- oder Tensor-Sharding, die Modellgewichte und Berechnungen auf verschiedene Geräte verteilen, um GPU-Probleme zu lösen . Speicherlimit.
Feinabstimmung des BLOOM-Modells für die Klassifizierung
Angenommen, wir sind daran interessiert, kürzlich vorab trainierte große Sprachmodelle für nachgelagerte Aufgaben wie die Textklassifizierung zu übernehmen. Dann könnten wir uns für die Open-Source-Alternative zu GPT-3 entscheiden, das BLOOM-Modell, konkret die BLOOM-Version mit „nur“ 560 Millionen Parametern – die problemlos in den RAM einer herkömmlichen GPU passen sollte (Google Colab kostenlos). Version verfügt über eine GPU mit 15 GB RAM).
Sobald Sie anfangen, werden Sie wahrscheinlich auf ein Problem stoßen: Der Speicher wird während des Trainings oder der Feinabstimmung schnell wachsen. Die einzige Möglichkeit, dieses Modell zu trainieren, besteht darin, die Batch-Größe auf 1 zu setzen (Batch-Größe = 1).

Der Code zur Feinabstimmung von BLOOM für die Zielklassifizierungsaufgabe unter Verwendung einer Stapelgröße von 1 (Stapelgröße = 1) ist unten dargestellt. Sie können den vollständigen Code auch von der GitHub-Projektseite herunterladen:
https://github.com/rasbt/gradient-accumulation-blog/blob/main/src/1_batchsize-1.py
Sie können diesen Code kopieren und direkt in Google Colab einfügen, müssen aber auch die zugehörige Datei „local_dataset_utilities.py“ per Drag & Drop in denselben Ordner ziehen, aus dem Sie einige Datensatz-Dienstprogramme importiert haben.
# pip install torch lightning matplotlib pandas torchmetrics watermark transformers datasets -Uimport osimport os.path as opimport timefrom datasets import load_datasetfrom lightning import Fabricimport torchfrom torch.utils.data import DataLoaderimport torchmetricsfrom transformers import AutoTokenizerfrom transformers import AutoModelForSequenceClassificationfrom watermark import watermarkfrom local_dataset_utilities import download_dataset, load_dataset_into_to_dataframe, partition_datasetfrom local_dataset_utilities import IMDBDatasetdef tokenize_text (batch):return tokenizer (batch ["text"], truncation=True, padding=True, max_length=1024)def train (num_epochs, model, optimizer, train_loader, val_loader, fabric):for epoch in range (num_epochs):train_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch_idx, batch in enumerate (train_loader):model.train ()### FORWARD AND BACK PROPoutputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])fabric.backward (outputs ["loss"])### UPDATE MODEL PARAMETERSoptimizer.step ()optimizer.zero_grad ()### LOGGINGif not batch_idx % 300:print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Batch {batch_idx:04d}/{len (train_loader):04d}"f"| Loss: {outputs ['loss']:.4f}")model.eval ()with torch.no_grad ():predicted_labels = torch.argmax (outputs ["logits"], 1)train_acc.update (predicted_labels, batch ["label"])### MORE LOGGINGmodel.eval ()with torch.no_grad ():val_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in val_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)val_acc.update (predicted_labels, batch ["label"])print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Train acc.: {train_acc.compute ()*100:.2f}%"f"| Val acc.: {val_acc.compute ()*100:.2f}%")train_acc.reset (), val_acc.reset ()if __name__ == "__main__":print (watermark (packages="torch,lightning,transformers", python=True))print ("Torch CUDA available?", torch.cuda.is_available ())device = "cuda" if torch.cuda.is_available () else "cpu"torch.manual_seed (123)# torch.use_deterministic_algorithms (True)############################# 1 Loading the Dataset##########################download_dataset ()df = load_dataset_into_to_dataframe ()if not (op.exists ("train.csv") and op.exists ("val.csv") and op.exists ("test.csv")):partition_dataset (df)imdb_dataset = load_dataset ("csv",data_files={"train": "train.csv","validation": "val.csv","test": "test.csv",},)############################################ 2 Tokenization and Numericalization#########################################tokenizer = AutoTokenizer.from_pretrained ("bigscience/bloom-560m", max_length=1024)print ("Tokenizer input max length:", tokenizer.model_max_length, flush=True)print ("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)print ("Tokenizing ...", flush=True)imdb_tokenized = imdb_dataset.map (tokenize_text, batched=True, batch_size=None)del imdb_datasetimdb_tokenized.set_format ("torch", columns=["input_ids", "attention_mask", "label"])os.environ ["TOKENIZERS_PARALLELISM"] = "false"############################################ 3 Set Up DataLoaders#########################################train_dataset = IMDBDataset (imdb_tokenized, partition_key="train")val_dataset = IMDBDataset (imdb_tokenized, partition_key="validation")test_dataset = IMDBDataset (imdb_tokenized, partition_key="test")train_loader = DataLoader (dataset=train_dataset,batch_size=1,shuffle=True,num_workers=4,drop_last=True,)val_loader = DataLoader (dataset=val_dataset,batch_size=1,num_workers=4,drop_last=True,)test_loader = DataLoader (dataset=test_dataset,batch_size=1,num_workers=2,drop_last=True,)############################################ 4 Initializing the Model#########################################fabric = Fabric (accelerator="cuda", devices=1, precision="16-mixed")fabric.launch ()model = AutoModelForSequenceClassification.from_pretrained ("bigscience/bloom-560m", num_labels=2)optimizer = torch.optim.Adam (model.parameters (), lr=5e-5)model, optimizer = fabric.setup (model, optimizer)train_loader, val_loader, test_loader = fabric.setup_dataloaders (train_loader, val_loader, test_loader)############################################ 5 Finetuning#########################################start = time.time ()train (num_epochs=1,model=model,optimizer=optimizer,train_loader=train_loader,val_loader=val_loader,fabric=fabric,)end = time.time ()elapsed = end-startprint (f"Time elapsed {elapsed/60:.2f} min")with torch.no_grad ():model.eval ()test_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in test_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)test_acc.update (predicted_labels, batch ["label"])print (f"Test accuracy {test_acc.compute ()*100:.2f}%")
Der Autor hat Lightning Fabric verwendet, weil es Entwicklern ermöglicht, die Anzahl der GPUs und die Multi-GPU-Trainingsstrategie flexibel zu ändern, wenn dieser Code auf unterschiedlicher Hardware ausgeführt wird. Es ermöglicht auch die Aktivierung eines Trainings mit gemischter Präzision, indem einfach die Präzisionsflagge angepasst wird. In diesem Fall kann ein Training mit gemischter Präzision die Trainingsgeschwindigkeit verdreifachen und den Speicherbedarf um etwa 25 % reduzieren.
Der oben gezeigte Hauptcode wird in der Hauptfunktion ausgeführt (im Kontext von if __name__ == „__main__“). Auch wenn nur eine einzelne GPU verwendet wird, wird empfohlen, die PyTorch-Laufzeitumgebung zu verwenden, um ein Training mit mehreren GPUs durchzuführen. Dann sind die folgenden drei Codeabschnitte, die in if __name__ == "__main__" eingebunden sind, für das Laden der Daten verantwortlich:
# 1 Laden Sie den Datensatz
#2 Tokenisierung und Digitalisierung
# 3 Richten Sie den Datenlader ein
In Abschnitt 4 geht es um die Initialisierung des Modells, und dann wird in Abschnitt 5, Feinabstimmung, die Zugfunktion aufgerufen, und hier wird es interessant. In der Funktion train (...) ist eine Standard-PyTorch-Schleife implementiert. Eine kommentierte Version der Kerntrainingsschleife sieht folgendermaßen aus:
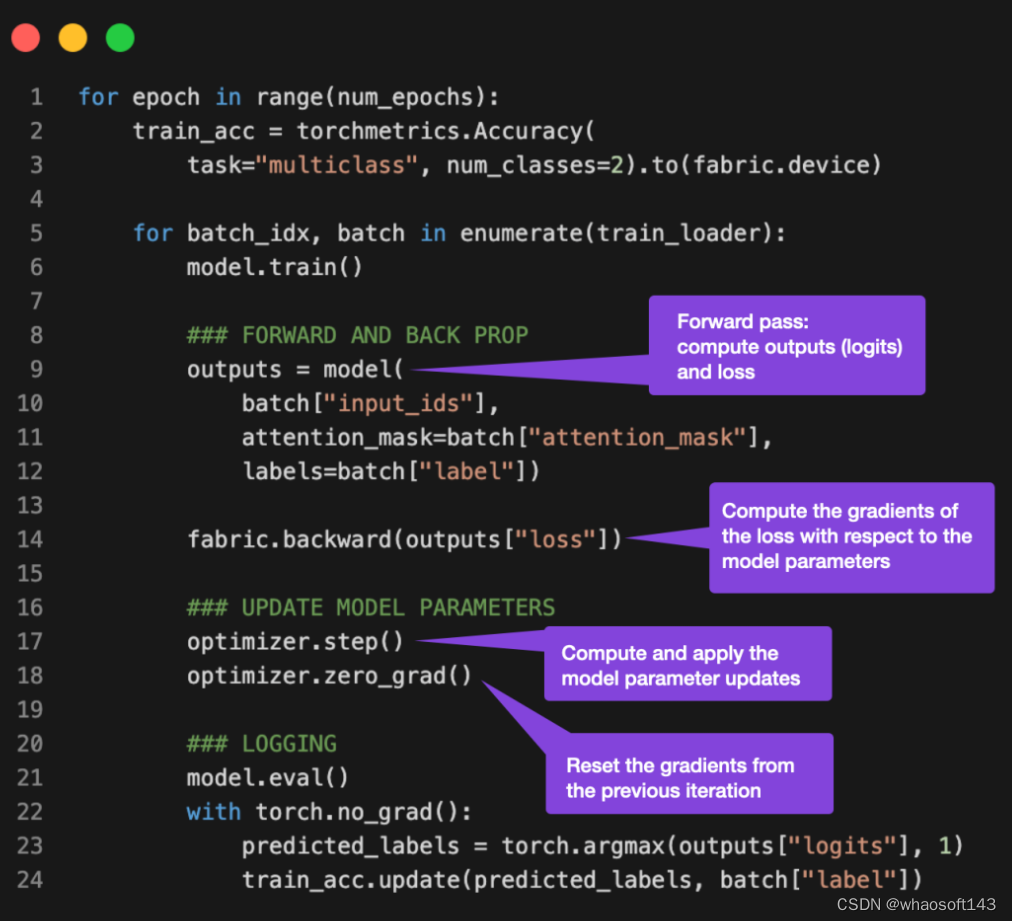
Das Problem bei einer Batch-Größe von 1 (Batch-Größe = 1) besteht darin, dass Gradientenaktualisierungen sehr chaotisch und schwierig werden können, wie man an schwankenden Trainingsverlusten und schlechter Leistung des Testsatzes beim Training des folgenden Modells erkennen kann:
...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0969Epoch: 0001/0001 | Batch 24000/35000 | Loss: 1.9902Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0395Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.2546Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.1128Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.2661Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0044Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0468Epoch: 0001/0001 | Batch 26400/35000 | Loss: 1.7139Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.9570Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.1857Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0090Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.9790Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0503Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.2625Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.1010Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0009Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0234Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.8394Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.9497Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.1437Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.1317Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0073Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.7393Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0512Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.1337Epoch: 0001/0001 | Batch 32400/35000 | Loss: 1.1875Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.2727Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.1545Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0022Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.2681Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.2467Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0620Epoch: 0001/0001 | Batch 34500/35000 | Loss: 2.5039Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0131Epoch: 0001/0001 | Train acc.: 75.11% | Val acc.: 78.62%Time elapsed 69.97 minTest accuracy 78.53%
Was kann getan werden, um Modelle mit größeren Batchgrößen zu trainieren, da nicht viele GPUs für Tensor-Sharding verfügbar sind?
Eine solche Lösung ist die Gradientenakkumulation, die die oben genannte Trainingsschleife modifiziert.
Was ist Gradientenakkumulation?
Die Gradientenakkumulation ist eine Möglichkeit, die Batch-Größe während des Trainings virtuell zu erhöhen. Dies ist nützlich, wenn der verfügbare GPU-Speicher nicht ausreicht, um die gewünschte Batch-Größe aufzunehmen. Bei der Gradientenakkumulation werden Gradienten für kleinere Chargen berechnet und über mehrere Iterationen akkumuliert (normalerweise summiert oder gemittelt), anstatt die Modellgewichte nach jeder Charge zu aktualisieren. Sobald der kumulative Gradient die angestrebte „virtuelle“ Stapelgröße erreicht, werden die Modellgewichte mithilfe des kumulativen Gradienten aktualisiert.
Sehen Sie sich die aktualisierte PyTorch-Trainingsschleife unten an:

Wenn „akkumulation_steps“ auf 2 gesetzt ist, werden „zero_grad()“ und „optimierer.step()“ nur jede Sekunde aufgerufen. Daher hat das Ausführen der geänderten Trainingsschleife mit „akkumulation_steps=2“ den gleichen Effekt wie eine Verdoppelung der Stapelgröße.
Wenn Sie beispielsweise eine Stapelgröße von 256 verwenden möchten, aber nur eine Stapelgröße von 64 in den GPU-Speicher passen, können Sie eine Gradientenakkumulation für vier Stapel der Größe 64 durchführen. (Wenn alle vier Stapel verarbeitet wurden, entsprechen die kumulativen Gradienten einer einzelnen Stapelgröße von 256.) Dadurch werden effektiv größere Stapelgrößen simuliert, ohne dass ein größerer GPU-Speicher erforderlich ist oder Tensoren auf verschiedene Geräte aufgeteilt werden. Stück.
Während die Gradientenakkumulation uns dabei helfen kann, Modelle mit größeren Stapelgrößen zu trainieren, verringert sie nicht den gesamten Rechenaufwand. Tatsächlich kann es manchmal dazu führen, dass der Trainingsprozess etwas langsamer abläuft, weil Gewichtsaktualisierungen seltener durchgeführt werden. Dennoch hilft es uns, die Einschränkung zu umgehen, dass sehr kleine Batchgrößen häufige und chaotische Updates verursachen.
Lassen Sie uns nun beispielsweise den obigen Code mit einer Stapelgröße von 1 ausführen, was 16 Akkumulationsschritte erfordert, um eine Stapelgröße von 16 zu simulieren.
Die Ausgabe ist wie folgt:
...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0168Epoch: 0001/0001 | Batch 24000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0152Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.0003Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.0623Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0047Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 26400/35000 | Loss: 0.1016Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0021Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0060Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0426Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0000Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0495Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0164Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0037Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0013Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0053Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1365Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0210Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0374Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0341Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.0259Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4792Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0003Epoch: 0001/0001 | Train acc.: 78.67% | Val acc.: 87.28%Time elapsed 51.37 minTest accuracy 87.37%
Den obigen Ergebnissen zufolge ist die Verlustschwankung geringer als zuvor. Darüber hinaus verbesserte sich die Leistung des Testsatzes um 10 %. Da der Trainingssatz nur einmal iteriert wird, wird jedes Trainingsbeispiel nur einmal angetroffen. Trainingsmodelle für mehrere Epochen können die Vorhersageleistung weiter verbessern.
Möglicherweise stellen Sie auch fest, dass dieser Code auch schneller ausgeführt wird als der zuvor verwendete Code der Stapelgröße 1. Wenn wir die virtuelle Stapelgröße mithilfe der Gradientenakkumulation auf 8 erhöhen, gibt es immer noch die gleiche Anzahl an Vorwärtsdurchgängen. Da das Modell jedoch nur alle acht Epochen aktualisiert wird, gibt es weniger Rückwärtsdurchläufe, was eine schnellere Iteration über Stichproben innerhalb einer Epoche (Anzahl der Trainingsrunden) ermöglicht.
abschließend
Die Gradientenakkumulation ist eine Technik, die größere Chargengrößen simuliert, indem mehrere kleine Chargengradienten akkumuliert werden, bevor Gewichtsaktualisierungen durchgeführt werden. Diese Technik ist hilfreich, wenn der verfügbare Speicher begrenzt ist und die Stapelgröße, die in den Speicher passt, klein ist.
Aber stellen Sie sich zunächst ein Szenario vor, in dem Sie mit einer Batch-Größe arbeiten können, was bedeutet, dass der verfügbare Speicher groß genug ist, um die gewünschte Batch-Größe aufzunehmen. In diesem Fall ist eine Gradientenakkumulation möglicherweise nicht erforderlich. Tatsächlich kann es effizienter sein, mit einer größeren Batch-Größe zu arbeiten, da es mehr Parallelität ermöglicht und die Anzahl der zum Trainieren des Modells erforderlichen Gewichtsaktualisierungen reduziert.
Zusammenfassend lässt sich sagen, dass die Gradientenakkumulation eine praktische Technik ist, die verwendet werden kann, um die Auswirkungen des Rauschens bei Mini-Batch-Größen auf die Genauigkeit von Gradientenaktualisierungen zu reduzieren. Dies ist bei weitem eine einfache und effektive Technik, die es uns ermöglicht, Hardware-Einschränkungen zu umgehen.
PS: Kann man das schneller machen?
Kein Problem. Mithilfe von Torch.compile, das in PyTorch 2.0 eingeführt wurde, kann es noch schneller ausgeführt werden. Sie müssen nur etwas model = Torch.compile hinzufügen, wie im Bild unten gezeigt:

Das vollständige Skript ist auf GitHub verfügbar.
In diesem Fall spart Torch.compile weitere zehn Minuten Trainingszeit ein, ohne die Modellierungsleistung zu beeinträchtigen:
poch: 0001/0001 | Batch 26400/35000 | Loss: 0.0320Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0157Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0540Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0016Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0877Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0232Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0014Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0062Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0066Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0017Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1485Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0324Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0155Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0049Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.1170Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0002Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4201Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0018Epoch: 0001/0001 | Train acc.: 78.39% | Val acc.: 86.84%Time elapsed 43.33 minTest accuracy 87.91%
Beachten Sie, dass der leichte Anstieg der Genauigkeit im Vergleich zu zuvor höchstwahrscheinlich auf Zufälligkeit zurückzuführen ist.

whaosoft aiot http://143ai.com