Zusammenfassung der Kenntnisse über Computernetzwerke
OSI-7-Schichten-Modell

-
Anwendungsschicht : Computerbenutzer und die Schnittstelle zwischen verschiedenen Anwendungen und dem Netzwerk. Die Funktion besteht darin, Benutzern direkt Dienste bereitzustellen und verschiedene Aufgaben auszuführen, die Benutzer im Netzwerk ausführen möchten. **Die Protokolle dieser Schicht sind: FTP (File Transfer Protocol), DNS (Domain Name Resolution Protocol), SMTP (Simple Mail Transfer Protocol), TELNET (TCP/IP Terminal Emulation Protocol), HTTP (Hypertext Transfer Protocol), HTTPS .
-
Präsentationsschicht : ** Befehle und Daten aus der Anwendungsschicht interpretieren, verschiedenen Grammatiken entsprechende Bedeutungen geben und sie in einem bestimmten Format an die Sitzungsschicht übertragen. Es befasst sich hauptsächlich mit der Darstellung von Benutzerinformationen, wie Codierung, Datenformatkonvertierung, Verschlüsselung und Entschlüsselung usw. **Die Protokolle dieser Schicht sind: LPP (Lightweight Presentation Protocol), XDP (External Data Presentation Protocol)
- Datenformatverarbeitung: Verhandeln und etablieren Sie das Format des Datenaustauschs und lösen Sie die Unterschiede in der Datenformatdarstellung zwischen verschiedenen Anwendungen.
- Codierung von Daten: verarbeitet die Konvertierung von Zeichensätzen und Zahlen.
- Komprimierung und Dekomprimierung: Reduzieren Sie die übertragene Datenmenge.
- Verschlüsselung und Entschlüsselung von Daten: Verbessern Sie die Sicherheit des Netzwerks.
-
Sitzungsschicht: Diese Schicht ist die Schnittstelle zwischen der Benutzeranwendung und dem Netzwerk. Organisiert und koordiniert die Kommunikation zwischen zwei Sitzungsprozessen und verwaltet den Datenaustausch . Benutzer können Sitzungen im Halbduplex-, Simplex- und Vollduplexmodus einrichten. Beim Einrichten einer Sitzung müssen Benutzer die Remote-Adresse angeben, zu der sie eine Verbindung herstellen möchten, z. B. xxx.com. Die Protokolle dieser Schicht sind: SSL (Secure Socket Layer Protocol), TLS (Transport Layer Security Protocol), RPC (Remote Procedure Call Protocol).
- Simplex: Simplex bedeutet, dass A nur Signale senden kann, B nur Signale empfangen kann und die Kommunikation einseitig ist.
- Halbduplex: In einem Zeitraum findet nur eine Aktion statt, entweder Senden oder Empfangen.
- Vollduplex: Dies bedeutet, dass der Switch beim Senden von Daten auch Daten empfangen kann und beides synchronisiert ist.
-
Transportschicht: **Sie bietet Ende-zu-Ende-Datenübertragungsdienste und kann eine logische Verbindung zwischen dem sendenden Host und dem Zielhost im Internet herstellen, Daten von Anwendungen der oberen Schicht segmentieren und wieder zusammensetzen und sie in einer zusammenführen Datenstrom. ** Unter ihnen befinden sich TCP und UDP auf dieser Schicht.
-
Netzwerkschicht : Verwenden Sie die fehlerfreie Datenübertragungsfunktion zwischen benachbarten Knoten, die von der Datenverbindungsschicht bereitgestellt wird, und realisieren Sie die Verbindung zwischen zwei Netzwerkgeräten durch Routing- und Relaisfunktionen . Die Protokolle dieser Schicht sind: IP (IPV4, IPV6), ICMP, IGMP.
-
Sicherungsschicht : eine zuverlässige direkte Datenverbindung von Punkt zu Punkt. Auf der Grundlage des von der physikalischen Schicht bereitgestellten Bitstroms werden Fehlerkontrolle, Flusskontrolle und andere Verfahren verwendet, um die physikalische Leitung mit Fehlern zu einer fehlerfreien Datenverbindung zu machen, dh ein zuverlässiges Verfahren zum Übertragen von Daten bereitzustellen das physische Medium . Die Protokolle dieser Schicht sind: PPP (Point-to-Point Protocol), FR (Frame Relay), HDLC (General Data Link Control Protocol), ARP (Address Resolution Protocol), RARP.
- MAC (Media Access Control)-Unterschicht: löst das Problem des Mehrbenutzer-Wettbewerbs um Kanäle in einem gemeinsam genutzten Netzwerk und vervollständigt die Zugriffssteuerung des Netzwerkmediums.
- LLC-Unterschicht (Logical Link Control): Stellt Netzwerkverbindungen her und hält sie aufrecht, führt Fehlerprüfungen, Flusssteuerung und Verbindungssteuerung durch.
-
Physikalische Schicht : eine Punkt-zu-Punkt-Datenverbindung, die nicht unbedingt zuverlässig ist. Verwenden Sie das Übertragungsmedium, um eine physikalische Verbindung für die Sicherungsschicht bereitzustellen, um die transparente Übertragung des Bitstroms zu realisieren . Das Protokoll dieser Schicht ist IEEE802.3.
Vorteile des Modells:
- Es löst das Kompatibilitätsproblem bei der Zusammenschaltung heterogener Netze, indem es die drei Begriffe Dienst, Schnittstelle und Protokoll klar voneinander unterscheidet: Der Dienst beschreibt, welche Funktionen eine bestimmte Schicht für die obere Schicht bereitstellt, und die Schnittstelle beschreibt, wie die obere Schicht sie nutzt Der Dienst der unteren Schicht, die Vereinbarung beinhaltet, wie der Dienst dieser Schicht zu realisieren ist.
- Dadurch wird jede Schicht hochgradig unabhängig, und es gibt keine Einschränkung für das Protokoll, das von jeder Entität im Verbindungsnetz verwendet wird.Es muss nur denselben Dienst nach oben bereitstellen und die Schnittstelle der benachbartenSchicht nicht ändern. Darüber hinaus übernehmen unterschiedliche Funktionsmodule des Netzwerks unterschiedliche Verantwortlichkeiten, was die Komplexität des Problems reduziert.Sobald ein Netzwerkausfall auftritt, kann die Hierarchie für eine einfache Suche und Fehlerkorrektur schnell lokalisiert werden.
Vierschichtiges TCP/IP-Protokoll
-
Anwendungsschicht (Sitzungsschicht, Präsentationsschicht, Anwendungsschicht): Das TCP/IP-Modell fasst die Funktionen der Sitzungsschicht und der Präsentationsschicht im OSI-Referenzmodell in der Anwendungsschicht zur Implementierung zusammen. Es bietet Benutzern eine Reihe häufig verwendeter Anwendungen wie E-Mail, Dateiübertragungszugriff, Remote-Anmeldung und mehr. Die Anwendungsschicht führt verschiedene Protokolle der Anwendungsschicht in verschiedene Netzwerkanwendungen ein.
- Remote-Login TELNET verwendet das TELNET-Protokoll, um eine Schnittstelle zur Registrierung auf anderen Hosts im Netzwerk bereitzustellen.
- TELNET-Sitzungen stellen zeichenbasierte virtuelle Terminals bereit.
- Dateiübertragungszugriff FTP verwendet das FTP-Protokoll, um das Kopieren von Dateien zwischen Computern innerhalb des Netzwerks bereitzustellen.
-
Transportschicht: **Stellt die Kommunikation zwischen Anwendungen bereit, sodass Peer-Entitäten auf den Quell- und Zielhosts eine Sitzung haben können. **Zu den Funktionen gehören:
- formatierter Strom
- Stellen Sie eine zuverlässige Übertragung bereit : Das Transportschichtprotokoll schreibt vor, dass die empfangende Seite eine Bestätigung zurücksenden muss, und wenn das Paket verloren geht, muss es erneut gesendet werden.
Diese Schicht definiert zwei Protokolle mit unterschiedlicher Dienstgüte: Transmission Control Protocol TCP (Transmission Control Protocol) und User Datagram Protocol UDP (User Datagram Protocol)
- Das TCP-Protokoll ist ein verbindungsorientiertes und zuverlässiges Protokoll , das den von einem Host gesendeten Bytestrom fehlerfrei an andere Hosts im Internet sendet. **Auf der sendenden Seite ist es dafür verantwortlich, den von der oberen Schicht übertragenen Bytestrom in Nachrichtensegmente aufzuteilen und an die untere Schicht weiterzuleiten; auf der empfangenden Seite ist es dafür verantwortlich, die empfangene Nachricht wieder zusammenzusetzen und an die obere zu senden Schicht. **Das TCP-Protokoll übernimmt auch die End-to-End-Flusskontrolle, um zu vermeiden, dass der langsam empfangende Empfänger nicht über genügend Puffer verfügt, um die große Datenmenge zu empfangen, die vom Absender gesendet wird.
- Das UDP-Protokoll ist ein verbindungsloses und unzuverlässiges Protokoll und eignet sich hauptsächlich für Gelegenheiten, bei denen keine Pakete sortiert und der Fluss kontrolliert werden müssen.
-
Netzwerkschicht: Der Kern des gesamten TCP/IP, die Funktion besteht darin, Pakete an das Zielnetzwerk oder den Zielhost zu senden . Um Pakete so schnell wie möglich zu senden, kann es erforderlich sein, die Paketzustellung gleichzeitig auf verschiedenen Pfaden durchzuführen. Daher kann die Ankunftsreihenfolge der Pakete unterschiedlich sein, was erfordert, dass die obere Schicht die Pakete sortiert. Diese Schicht definiert auch das Paketformat und das Protokoll, das IP-Protokoll.
- Verarbeiten Sie Paketübertragungsanforderungen von der Transportschicht : Packen Sie das Paket nach Erhalt der Anforderung in ein IP-Datagramm, füllen Sie den Header aus, wählen Sie einen Pfad zur Zielmaschine aus und senden Sie dann das Datagramm an die entsprechende Netzwerkschnittstelle.
- Eingehende Datagramme verarbeiten : zuerst ihre Legitimität prüfen, dann weiterleiten:
- Wenn das Datagramm an der Senke angekommen ist, wird der Header entfernt.
- Wenn das Datenpaket das Ziel nicht erreicht hat, wird das Datagramm weitergeleitet.
- Behandeln Sie Pfade, Flusskontrolle, Staus und andere Probleme.
-
Netzwerkschnittstellenschicht (Physical Layer, Data Link Layer): Verantwortlich für das Empfangen von IP-Daten und das Senden durch das Netzwerk oder das Empfangen von physischen Frames aus dem Netzwerk und das Extrahieren von IP-Datagrammen an die Netzwerkschicht . Tatsächlich beschreibt TCP/IP nicht wirklich die Implementierung dieser Schicht, sondern erfordert nur, dass es in der Lage ist, eine Zugangsschnittstelle zu seiner oberen Schicht bereitzustellen, um IP-Pakete darauf zu übertragen.
HTTP-Definition, Fähigkeiten und Features
-
HTTP: Hypertext Transfer Protocol, nämlich HyperText Transfer Protocol. Es ist ein Request-Response-basiertes, zustandsloses Protokoll der Anwendungsschicht . Es basiert häufig auf dem TCP/IP-Protokoll zur Datenübertragung. Es ist das am weitesten verbreitete Netzwerkprotokoll im Internet. Alle WWW-Dateien müssen diesem Standard entsprechen. Die ursprüngliche Absicht beim Entwerfen von HTTP besteht darin, eine Möglichkeit zum Veröffentlichen und Empfangen von HTML-Seiten bereitzustellen.
-
Eigenschaften von HTTP
- Einfach: Das grundlegende Nachrichtenformat ist Header+Body, und die Header-Informationen sind ebenfalls ein einfaches Textformat aus Schlüsselwerten, das leicht verständlich ist.
- Flexibel und einfach erweiterbar: Diverse Request-Methoden im HTTP-Protokoll, URI/URL, Statuscode, Header-Felder etc. sind nicht festgelegt, sodass Entwickler sie anpassen und erweitern können. Da HTTP auf der Anwendungsschicht arbeitet, kann seine untere Schicht nach Belieben geändert werden.
- Breite Anwendung und plattformübergreifend.
- keine Verbindung :
- Jeder Zugriff ist verbindungslos, der Server verarbeitet die Zugriffe in der Zugriffswarteschlange nacheinander, schließt die Verbindung nach der Verarbeitung eines Zugriffs und verarbeitet dann den nächsten neuen.
- Die Bedeutung von verbindungslos besteht darin, jede Verbindung darauf zu beschränken, nur eine Anfrage zu verarbeiten. Der Server beendet die Verarbeitung der Anfrage des Clients und trennt die Verbindung, nachdem er die Antwort des Clients erhalten hat.
- staatenlos :
- Vorteil: Der Server merkt sich den HTTP-Status nicht, sodass keine zusätzlichen Ressourcen zum Aufzeichnen der Statusinformationen benötigt werden, was die Belastung des Servers verringern und mehr CPU und Speicher für die Bereitstellung externer Dienste verwenden kann.
- Nachteil: Da der Server keine Speicherkapazität hat, muss er Informationen immer überprüfen, wenn er einige verwandte Operationen ausführt. Zum Beispiel: Login-"Einkaufswagen hinzufügen-"Bestellung-"Abrechnung-"Zahlung, diese Reihe von Operationen muss die Identität des Benutzers kennen, aber der Server weiß nicht, dass diese Operationen zusammenhängen. Der typischste Fall zur Lösung dieses Problems ist Cookie: Der Status des Clients wird gesteuert, indem Cookie-Informationen in die Anfrage- und Antwortnachrichten geschrieben werden, was dem Server entspricht, der einen Aufkleber mit Kundeninformationen sendet, der gebracht wird, wenn der Client eine Anfrage stellt der Server später Dieser Aufkleber wird den Zweck erfüllen.
- Klartextübertragung :
- Vorteile: Die Informationen im Übertragungsprozess können bequem vorab gelesen und direkt über F12 angezeigt werden, was die Debugging-Arbeit sehr erleichtert.
- Nachteile: Information Streaking, überhaupt keine Privatsphäre, sehr unsicher. Das Sicherheitsproblem von HTTP kann durch die Einführung von HTTPS der SSL/TLS-Schicht gelöst werden.
-
Drei Merkmale von HTTP1.1:
- Lange Verbindung : Jedes Mal, wenn HTTP1.0 eine Anfrage initiiert, ist eine neue TCP-Verbindung (Drei-Wege-Handshake) erforderlich, und es handelt sich um eine serielle Anfrage, was den Kommunikationsaufwand erhöht. Um das TCP-Verbindungsproblem zu lösen, schlägt HTTP1.1 eine Kommunikationsmethode für lange Verbindungen vor: Solange eines der beiden Enden nicht explizit die Trennung anfordert, wird der TCP-Verbindungsstatus beibehalten .
- Pipeline-Netzwerkübertragung : In derselben TCP-Verbindung kann der Client mehrere Anfragen senden. Solange die erste Anfrage gesendet wird, kann die zweite Anfrage gesendet werden, ohne auf ihre Rückkehr zu warten, was die Gesamtantwortzeit verkürzen kann. Trotzdem antwortet der Server der Reihe nach immer zuerst auf die erste Anfrage.Wenn die Antwort auf die erste Anfrage besonders langsam ist, stehen später viele Anfragen in der Schlange, was dazu führt, dass der Kopf der Warteschlange blockiert wird .
- Head-of-Queue-Blockierung : Wenn eine sequenziell gesendete Anforderung aus irgendeinem Grund blockiert wird, werden alle nachfolgenden Anforderungen in der Warteschlange ebenfalls blockiert, sodass der Client niemals Daten anfordert.
HTTP vs. HTTPS
der Unterschied
- HTTP ist ein Hypertext-Übertragungsprotokoll, bei dem Informationen im Klartext übertragen werden und dessen Verbindung einfach und zustandslos ist; HTTPS ist ein HTTP-Protokoll plus SSL (Secure Sockets Layer), das eine verschlüsselte Übertragung und Identitätsauthentifizierung durchführen kann, was besser ist als Sicherheit des HTTP-Protokolls.
- HTTP überprüft die Identität des Kommunikationsteilnehmers nicht, die Identität des Kommunikationsteilnehmers kann verschleiert werden, und die Integrität der Nachricht kann nicht nachgewiesen werden, und die Nachricht kann manipuliert werden; HTTPS muss ein Zertifikat von einer Zertifizierungsstelle beantragen die Identität sicherstellen.
- HTTP und HTTPS verwenden völlig unterschiedliche Verbindungsmethoden und auch die Ports sind unterschiedlich: Ersterer ist 80, letzterer 443.
- HTTPS-Verbindungen nehmen viele Serverressourcen in Anspruch, das Zwischenspeichern von Verbindungen ist nicht so effizient wie HTTP und die Verkehrskosten sind hoch.
- Die Handshake-Phase des HTTPS-Protokolls ist zeitaufwändig und beeinträchtigt die Antwortgeschwindigkeit der Website, daher wird im Allgemeinen „Teile und Herrsche“ verwendet. 12306 bedeutet, dass die Startseite HTTP verwendet und die relevanten Benutzerinformationen HTTPS verwenden.
Problem gelöst
HTTP ist eine Klartextübertragung, daher gibt es die folgenden drei Probleme:
- Abhörrisiko : Kommunikationsinhalte können über die Kommunikationsverbindung abgerufen werden.
- Manipulationsrisiko : erzwungene Platzierung von Spam-Werbung usw.
- Identitätsrisiko : Es ist einfach, sich als andere Websites auszugeben.
HTTPS fügt das SSL/TLS-Protokoll zwischen den HTTP- und TCP-Schichten hinzu, wodurch die oben genannten Probleme gut gelöst werden können:
- Informationsverschlüsselung: Interaktionsinformationen können nicht gestohlen werden.
- Überprüfungsmechanismus: Der Inhalt der Kommunikation kann nicht manipuliert werden, und wenn er manipuliert wird, kann er nicht normal angezeigt werden.
- Identitätszertifikat: Beweist, dass eine Website authentisch ist.
HTTP gegen TCP
- HTTP ist ein Protokoll der Anwendungsschicht, das hauptsächlich löst, wie Daten verpackt werden, während das TCP-Protokoll ein Protokoll der Transportschicht ist, das hauptsächlich löst, wie Daten im Netzwerk übertragen werden.
- Warum brauchen wir HTTP, wenn es TCP gibt: Wenn wir Daten übertragen, können wir nur das TCP-Protokoll (Transportschicht) verwenden, aber ohne die Anwendungsschicht können Benutzer den Inhalt der Daten nicht identifizieren.Wenn Sie die übertragenen Daten aussagekräftig machen möchten , müssen Sie das Protokoll der Anwendungsschicht verwenden.
- HTTP baut auf dem TCP-Protokoll auf.
Die spezifische Methode der HTTPS-Verschlüsselung
HTTPS ist kein neues Protokoll, sondern ermöglicht es HTTP, zuerst mit SSL (Secure Sockets Layer) und dann mit SSL und TCP zu kommunizieren . Das heißt, HTTPS verwendet Tunnel für die Kommunikation.** Durch die Verwendung von SSL verfügt HTTP über Verschlüsselung (Anti-Eavesdropping), Authentifizierung (Anti-Masquerading) und Integritätsschutz (Anti-Tampering). **
-
Authentifizierung: Verwenden Sie eine externe Authentifizierungsstelle für digitale Zertifikate, um die kommunizierenden Parteien zu authentifizieren. Das Einfügen des öffentlichen Schlüssels des Servers in das digitale Zertifikat beseitigt das Risiko des Identitätswechsels. Solange dem Zertifikat vertraut wird, wird dem öffentlichen Schlüssel vertraut.
-
Warum brauche ich eine CA-Zertifizierungsstelle, um ein Zertifikat auszustellen?
-
Das HTTP-Protokoll gilt als unsicher, da es während des Übertragungsprozesses leicht von Listenern und gefälschten Servern überwacht werden kann, während das HTTPS-Protokoll hauptsächlich Sicherheitsprobleme bei der Netzwerkübertragung löst. Unter der Annahme, dass es keine Zertifizierungsstelle gibt, kann jeder ein Zertifikat erstellen, was zu einem Man-in-the-Middle-Angriffsproblem führt : Obwohl der Client eine HTTPS-Anfrage initiiert, hat der Client keine Ahnung, dass sein Netzwerk abgefangen wurde, und der Übertragungsinhalt wird vollständig vom Mittelsmann gestohlen.
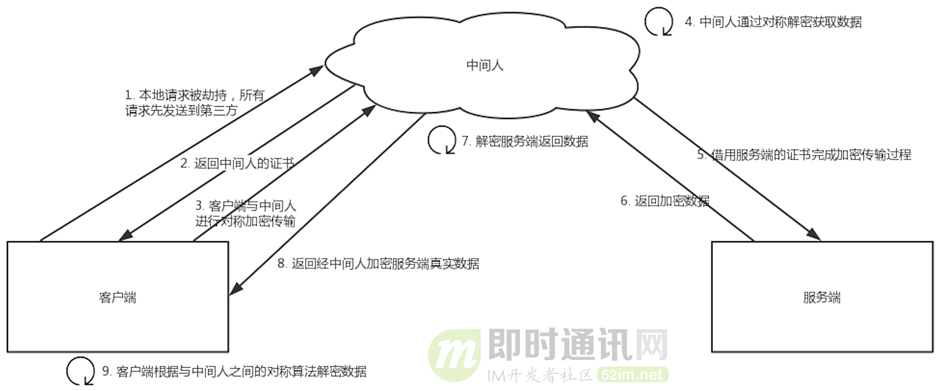
-
-
-
Verschlüsselung: Hybride Verschlüsselung aus symmetrischer Verschlüsselung und asymmetrischer Verschlüsselung (symmetrische Verschlüsselung wird zum Übertragen von Daten verwendet und asymmetrische Verschlüsselung wird zum Austausch von Sitzungsschlüsseln verwendet.) Asymmetrische Verschlüsselung wird verwendet, um Sitzungsschlüssel auszutauschen, bevor die Kommunikation aufgebaut wird, und asymmetrische Verschlüsselung wird nicht mehr verwendet in der Zukunft. Während des Kommunikationsvorgangs werden die Klartextdaten mit dem symmetrisch verschlüsselten Sitzungsschlüssel verschlüsselt .
-
Was ist symmetrische Verschlüsselung und asymmetrische Verschlüsselung?
- Symmetrische Verschlüsselung, auch Verschlüsselung mit privatem Schlüssel genannt, bezieht sich auf einen Verschlüsselungsalgorithmus, der denselben geheimen Schlüssel für die Verschlüsselung und Entschlüsselung verwendet .
- Asymmetrische Verschlüsselung erfordert zwei Schlüssel: einen öffentlichen Schlüssel und einen privaten Schlüssel, und diese beiden erscheinen paarweise. Unter ihnen ist der öffentliche Schlüssel öffentlich zugänglich und kann von jedem erlangt werden, während der private Schlüssel nicht öffentlich ist.
-
Warum hybride Verschlüsselung?
- Die symmetrische Verschlüsselung verwendet nur einen geheimen Schlüssel, und die Berechnungsgeschwindigkeit ist hoch. Der geheime Schlüssel muss geheim gehalten werden, und ein sicherer Schlüsselaustausch kann nicht erreicht werden.
- Die asymmetrische Verschlüsselung verwendet zwei geheime Schlüssel: einen öffentlichen Schlüssel und einen privaten Schlüssel.Der öffentliche Schlüssel kann beliebig verteilt werden, während der privateSchlüssel geheim gehalten wird, wodurch das Sicherheitsproblem des Schlüsselaustauschsgelöst wird.
-
Warum wird die Datenübertragung symmetrisch verschlüsselt?
- Die Entschlüsselungseffizienz der asymmetrischen Verschlüsselung ist sehr gering, und es gibt normalerweise viele Interaktionen zwischen Ende-zu-Ende in HTTP-Anwendungsszenarien, und die Effizienz der asymmetrischen Verschlüsselung ist nicht akzeptabel.
- In HTTPS speichert nur der Server den privaten Schlüssel, und ein Paar aus öffentlichem und privatem Schlüssel kann nur eine unidirektionale Verschlüsselung und Entschlüsselung realisieren, sodass die Verschlüsselung der Inhaltsübertragung in HTTPS eine symmetrische Verschlüsselung ist.
-
Der Gesamtprozess der Verschlüsselung?
- **Authentifizierungsserver:** Der Browser hat eine eingebaute Liste vertrauenswürdiger CA-Institutionen und speichert die Zertifikate dieser CA-Institutionen. In der ersten Stufe stellt der Server ein von der Zertifizierungsstelle zertifiziertes Serverzertifikat bereit. **Wenn die Zertifizierungsstelle, die das Serverzertifikat zertifiziert, in der Liste der vertrauenswürdigen Zertifizierungsstellen des Browsers vorhanden ist und die Informationen im Serverzertifikat mit denen der identisch sind aktuell besuchte Website (Domainname usw.), dann betrachtet der Browser den Server als vertrauenswürdig und bezieht den öffentlichen Schlüssel des Servers aus dem Serverzertifikat für nachfolgende Prozesse. ** Andernfalls fordert der Browser den Benutzer auf zu entscheiden, ob er gemäß der Wahl des Benutzers fortfahren möchte. Natürlich können wir diese Liste vertrauenswürdiger CA-Institutionen verwalten, um die CA-Institutionen, denen wir vertrauen möchten, hinzuzufügen oder zu entfernen.
- Sitzungsschlüssel aushandeln: Der Prozess, bei dem auch ein privater Schlüssel für die symmetrische Verschlüsselung ausgehandelt wird. Nachdem der Client den Server authentifiziert und den öffentlichen Schlüssel des Servers erhalten hat, verwendet er den öffentlichen Schlüssel, um mit dem Server in verschlüsselter Form zu kommunizieren, und handelt zwei Sitzungsschlüssel aus, bei denen es sich um den Client-Sitzungsschlüssel handelt, der zum Verschlüsseln der vom Client an den gesendeten Daten verwendet wird Server und Der Serversitzungsschlüssel, der zum Verschlüsseln von Daten verwendet wird, die vom Server an den Client gesendet werden. Unter der Prämisse, dass der vorhandene öffentliche Schlüssel des Servers die Kommunikation verschlüsseln kann, besteht der Grund für das Aushandeln zweier symmetrischer Schlüssel darin, dass asymmetrische Verschlüsselung relativ komplexer ist und die Verwendung der symmetrischen Verschlüsselung während der Datenübertragung Rechenressourcen einsparen kann. Außerdem wird der Sitzungsschlüssel zufällig generiert, und jede Aushandlung hat ein anderes Ergebnis, sodass die Sicherheit relativ hoch ist.
- **Verschlüsselte Kommunikation:** Zu diesem Zeitpunkt haben sowohl der Client als auch der Server den Sitzungsschlüssel für diese Kommunikation, und alle danach übertragenen HTTP-Daten werden mit dem Sitzungsschlüssel verschlüsselt. Auf diese Weise wird es für andere Benutzer im Netzwerk schwierig, die zwischen dem Client und dem Server übertragenen Daten zu stehlen und zu manipulieren, wodurch der Datenschutz und die Integrität der Daten gewährleistet werden.
-
-
Integritätsschutz: SSL bietet eine Message Digest-Funktion für den Integritätsschutz. HTTP bietet auch die MD5-Message-Digest-Funktion, ist aber nicht sicher. Diese Funktion kann einen eindeutigen „Fingerabdruck“ für die Daten erzeugen, um die Integrität der Daten zu überprüfen und das Manipulationsrisiko zu beseitigen. Vor dem Senden des Klartextes berechnet der Client den „Fingerabdruck" des Klartextes durch den Digest-Algorithmus. Beim Senden wird der „Fingerabdruck + Klartext" zusammen in Chiffretext verschlüsselt und an den Server gesendet. Verwenden Sie nach der Entschlüsselung durch den Server denselben Digest-Algorithmus, um den gesendeten Klartext zu berechnen, und vergleichen Sie den vom Client getragenen „Fingerabdruck“ mit dem aktuell berechneten „Fingerabdruck". Wenn sie gleich sind, sind die Daten vollständig.
SSL-Prozess
Der SSL-Prozess besteht aus den spezifischen Schritten zum Einrichten eines sicheren HTTPS-Kanals:
- Der Client startet die SSL-Kommunikation, indem er eine Client-Hello-Nachricht sendet. Die Nachricht enthält die vom Client unterstützte SSL-Version, eine Liste der Verschlüsselungskomponenten (verwendeter Verschlüsselungsalgorithmus, Schlüssellänge usw.)
- Wenn der Server weiß, dass SSL-Kommunikation möglich ist, antwortet er mit einer Server-Hello-Nachricht. Wie der Client enthält die Nachricht die SSL-Version und Verschlüsselungskomponenten. Der Inhalt der Verschlüsselungskomponenten des Servers wird aus den empfangenen Client-Verschlüsselungskomponenten gefiltert . Danach wird eine Zertifikatsnachricht (öffentlicher Schlüssel und Zertifikat) gesendet, und schließlich sendet der Server eine Server-Hello-Done-Nachricht, um den Client zu benachrichtigen, und die Anfangsphase der SSL-Handshake-Aushandlung ist beendet.
- Der Client antwortet mit einer Client Key Exchange-Nachricht (einschließlich einer zufälligen Pre-masterSecret-Kennwortzeichenfolge, die bei der Kommunikationsverschlüsselung verwendet wird), die mit dem vorherigen öffentlichen Schlüssel verschlüsselt ist. Dann sendet der Client weiterhin die Change Ciper Spec-Nachricht, die den Server daran erinnert, dass die Kommunikation nach dieser Nachricht mit dem Pre-masterSecret-Schlüssel verschlüsselt wird. Abschließend sendet der Client eine Finish-Nachricht, die den Gesamtprüfwert aller bisher verbundenen Nachrichten enthält Ob der Handshake erfolgreich ist, hängt davon ab, ob der Server die Nachricht korrekt entschlüsseln kann.
- Der Server sendet auch eine Change Cipher Spec-Nachricht und eine Finished-Nachricht.
Im Allgemeinen ist es:
- Versionsnummern des SSL-Protokolls austauschen
- Wählen Sie ein Verschlüsselungsverfahren, das von beiden Kommunikationspartnern unterstützt wird
- Implementieren Sie die Identitätsauthentifizierung an beiden Enden
- Schlüsselaustausch
Statuscode der HTTP-Antwort
- 1xx (Fortsetzung): Neu eingeführt in HTTP 1.1. Der Anforderer sollte mit der Anfrage fortfahren, und der Server gibt diesen Code zurück, um anzuzeigen, dass er den ersten Teil der Anfrage erhalten hat und auf den Rest wartet.
- 2xx (Erfolg): Ein Statuscode, der angibt, dass die Anfrage erfolgreich verarbeitet wurde.
- 3xx (Redirect): Weitere Maßnahmen sind erforderlich, um die Anforderung abzuschließen. Diese Statuscodes werden für die Umleitung verwendet, und die nachfolgende Anforderungsadresse (Umleitungsziel) wird im Feld Standort dieser Antwort angegeben.
- 4xx (Request Error): Bei der Client-Anfrage ist ein Fehler aufgetreten, der die Verarbeitung durch den Server verhindert hat.
- 5xx (Serverfehler): Der Server hat einen Fehler oder es tritt ein anormaler Zustand während der Verarbeitung der Anfrage auf Es ist auch möglich, dass der Server erkennt, dass die Verarbeitung der Anfrage mit den aktuellen Hardware- und Softwareressourcen nicht abgeschlossen werden kann.


weiterleiten und umleiten
- Die Umleitungsadressleiste ändert sich; der Pfad der Weiterleitungsadressleiste ändert sich nicht
- Die Umleitung kann auf Ressourcen auf anderen Sites zugreifen, die Weiterleitung kann nur auf Ressourcen unter dem aktuellen Server zugreifen
- Die Umleitung besteht aus zwei Anforderungen, und das Anforderungsobjekt kann nicht zum Teilen von Daten verwendet werden; die Weiterleitung ist eine Anforderung, und das Anforderungsobjekt kann zum Teilen von Daten verwendet werden
HTTP-Nachricht
Eine HTTP-Anforderungsnachricht besteht aus vier Teilen: Anforderungszeile, Anforderungsheader, Leerzeile und Anforderungstext .

- Die Anforderungszeile besteht aus drei Teilen: Anforderungsmethodenfeld, URL-Feld und HTTP-Protokollversionsfeld , getrennt durch Leerzeichen. Die am häufigsten verwendeten HTTP-Anforderungsmethoden sind: GET, POST, HEAD, PUT, DELETE, OPTIONS, TRACE, CONNECT. Unter ihnen sind die ersten drei in HTTP1.0 verfügbar und die letzten fünf sind HTTP1.1.
- GET: **Diese Methode wird verwendet, wenn der Client eine Ressource vom Server lesen möchte. **Die GET-Methode erfordert, dass der Server die von der URL gefundene Ressource in den Datenteil der Antwortnachricht einfügt und sie an den Client zurücksendet. Bei Verwendung der GET-Methode werden die Anfrageparameter und die entsprechenden Werte an die URL angehängt, und ein englisches Fragezeichen wird verwendet, um das Ende der URL und den Anfang der Anfrageparameter darzustellen. Zum Beispiel /page?size=11&total=111
- POST: **Diese Methode wird verwendet, wenn der Client dem Server Informationen bereitstellt. **Die POST-Methode übermittelt im Allgemeinen einige Formulardaten, kapselt die Anforderungsparameter in den HTTP-Anforderungsdaten ein und erscheint in Form von Name/Wert, wodurch eine große Datenmenge übertragen werden kann.
- HEAD: **Ähnlich wie GET, außer dass der Server nur den Response-Header zurückgibt, nachdem er die HEAD-Anforderung erhalten hat, und den Response-Inhalt nicht sendet. **Wenn wir nur den Status einer bestimmten Seite überprüfen müssen, ist die Verwendung von HEAD sehr effizient, da der Inhalt der Seite während der Übertragung weggelassen wird.
- Die Situation der Ressourcen verstehen, ohne Ressourcen zu erwerben (Urteilstyp)
- Prüfen Sie, ob das Objekt vorhanden ist, indem Sie sich den Statuscode in der Antwort ansehen
- Testen Sie anhand des Headers, ob die Ressource geändert wurde
- PUT: **Ähnlich wie POST, aber wenn zwei Anfragen gleich sind, überschreibt die letztere Anfrage die erste Anfrage. ** Im Allgemeinen verwendet, um Ressourcen zu ändern.
- LÖSCHEN: Fordern Sie den Server auf, die von der Anforderungs-URL angegebene Ressource zu löschen, wird jedoch nicht unbedingt ausgeführt, da der Server die Anforderung widerrufen kann, ohne den Client zu benachrichtigen.
- OPTIONEN: **Wird verwendet, um die Methoden abzurufen, die von der aktuellen URL unterstützt werden. **Wenn die Anfrage erfolgreich ist, enthält sie einen Header namens „Allow“ im HTTP-Header, und der Wert ist die unterstützte Methode, z. B. „GET, POST“.
- TRACE: Ermöglicht dem Client zu sehen, wie die Anfrage aussieht, wenn er sie schließlich an den Server sendet.
- CONNECT: Verwenden Sie den Server als Sprungbrett, lassen Sie den Server den Benutzer ersetzen, um andere Webseiten zu besuchen, und geben Sie dann die Daten an den Benutzer zurück.
- Request-Header: Er besteht aus Schlüsselwörtern und Werten, ein Paar pro Zeile, und die Schlüsselwörter und Werte sind durch Doppelpunkte getrennt. Der Request-Header informiert den Server über die vom Client angeforderten Informationen Typische Request-Header sind:
- User-Agent: Der Browsertyp, der die Anfrage gestellt hat
- Akzeptieren: Eine Liste von Antwortinhaltstypen, die vom Client erkannt werden; das Sternchen „*“ wird verwendet, um Typen nach Bereich zu gruppieren, „/“ zeigt an, dass alle Typen akzeptabel sind, und „Typ/*“ zeigt an, dass alle Untertypen des Typs Typ sind sind akzeptabel
- Accept-Language: Die für den Client akzeptable natürliche Sprache
- Accept-Encoding: Das für den Client akzeptable Codierungs- und Komprimierungsformat
- Accept-Charset: Akzeptabler Zeichensatz für Antworten
- Host: Der angeforderte Hostname, der es ermöglicht, dass mehrere Domänennamen dieselbe IP-Adresse haben, d. h. ein virtueller Host
- Verbindung: Verbindungsmodus (Schließen oder Keepalive)
- Cookie: Im Client-Erweiterungsfeld gespeichert, senden Sie das zur Domain gehörende Cookie an den Server mit demselben Domainnamen;
- Inhaltslänge: Wie viele Datenbytes sind im Körper der Entität enthalten
- Inhaltstyp: Der Dateityp des Körperteils der Entität
- Datum: Die Uhrzeit, zu der der Server die Antwort generiert hat
- Fordern Sie eine Leerzeile an: Nachdem der letzte Antwortheader eine Leerzeile ist, senden Sie einen Wagenrücklauf und einen Zeilenvorschub, um den Server darüber zu informieren, dass unten keine weiteren Antwortheader vorhanden sind .
- Anforderungstext: Enthält einen Datenblock, der aus beliebigen Daten besteht . Nicht alle Nachrichten haben einen Text. Es ist der Hauptübertragungsinhalt von HTTP.
Der Unterschied zwischen GET und POST
- Definition: Die Bedeutung der GET-Methode besteht darin, Ressourcen vom Server anzufordern , die statischer Text, Seiten, Bilder und Videos usw. sein können. Wenn Sie beispielsweise einen Link öffnen, sendet der Browser eine GET-Anforderung an den Server, und der Server gibt den gesamten Text und die Ressourcen im Link zurück; die POST-Methode ist eine umgekehrte Operation, bei der Daten an die von der angegebene Ressource gesendet werden URI , und die Daten werden in den Body gestellt . Geben Sie beispielsweise die Registrierungsinformationen in einen bestimmten Link ein und klicken Sie auf Senden. Der Browser führt eine POST-Anforderung aus, fügt die gesendeten Informationen in den Anforderungstext der Nachricht ein und fügt dann den POST-Anforderungsheader zusammen und sendet ihn an den Server durch das TCP-Protokoll.
- Die Parameter des GET-Requests bleiben vollständig im Browserverlauf erhalten, die Parameter im POST jedoch nicht; der GET-Request wird durch die URL geleitet, während der POST im Request-Body platziert wird; der GET-Request wird übergeben die URL Der Parameter ist in der Länge begrenzt, POST nicht.
- GET-Anforderungen werden vom Browser aktiv zwischengespeichert, POST jedoch nicht.
- GET generiert ein TCP-Datenpaket: Der Browser sendet den HTTP-Header und Daten zusammen, und der Server antwortet mit 200 ok; während POST zwei Datenpakete generiert: Der Browser sendet zuerst den Header, der Server antwortet mit 100 Continue, der Browser sendet Daten , und der Server antwortet Respond mit 200 ok. ps: Nicht alle Browser senden per POST zwei Datenpakete.
HTTP1.0 vs. HTTP1.1 vs. HTTP2 vs. HTTP3
- HTTP1.1 unterstützt lange Verbindungen und die Pipeline-Verarbeitung von Anfragen .
- HTTP1.0 legt fest, dass der Browser und der Server nur eine kurze Verbindung unterhalten. Jede Anfrage des Browsers muss eine TCP-Verbindung mit dem Server aufbauen. Der Server trennt die TCP-Verbindung sofort nach Abschluss der Anfrageverarbeitung. Der Server verfolgt nicht beide Client und zeichnet die vergangene Frage nicht auf.
- HTTP1.1 unterstützt lange Verbindungen und verwendet standardmäßig lange Verbindungen. Mehrere HTTP-Anforderungen und -Antworten können in derselben TCP-Verbindung übertragen werden, und mehrere Anforderungen und Antworten können sich überschneiden und gleichzeitig ablaufen. Und weitere Request-Header und Response-Header (Host), Methoden usw. (PUT, DELETE, CONNECT, TRACE, OPTIONS) wurden hinzugefügt. Diese dauerhafte Verbindung muss jedoch einen neuen Anforderungsheader hinzufügen, um sie zu realisieren. Wenn beispielsweise der Wert von Connection Keep-Alive ist, benachrichtigt der Client den Server, die Verbindung aufrechtzuerhalten, nachdem er das Ergebnis dieser Anforderung zurückgegeben hat; wenn der Wert des Connection-Request-Headers geschlossen ist, benachrichtigt der Client den Server Close the connection, nachdem er das Ergebnis dieser Anfrage zurückgegeben hat.
- HTTP1.1 ermöglicht es dem Client auch, die nächste Anfrage zu stellen, ohne auf die Rückgabe des vorherigen Anfrageergebnisses zu warten, aber der Server muss die Antwortergebnisse in der Reihenfolge zurücksenden, in der die Clientanfragen empfangen werden, um sicherzustellen, dass der Client sie unterscheiden kann Antwortinhalt anfordern.
- HTTP1.1 bietet auch Anforderungsheader und Antwortheader in Bezug auf Authentifizierung, Zustandsverwaltung und Cache-Mechanismen wie Cache-Control . HTTP1.1 fügt einige neue Cache-Funktionen basierend auf 1.0 hinzu. Wenn das Alter des zwischengespeicherten Objekts Expire überschreitet, wird es zu einem veralteten Objekt. Der Cache muss das veraltete Objekt nicht direkt verwerfen, sondern wird mit dem Quellserver reaktiviert (Revalidierung).
- HTTP1.1 neu hinzugefügtes Hostfeld
- HTTP1.0 geht davon aus, dass jeder Server an eine eindeutige IP-Adresse gebunden ist, sodass die URL in der Anforderungsnachricht den Hostnamen (Hostname) nicht weitergibt. Aber mit der Entwicklung der virtuellen Host-Technologie können mehrere virtuelle Hosts auf einem physischen Server existieren und sie teilen sich dieselbe IP-Adresse.
- HTTP1.1-Anforderungsnachrichten und -Antwortnachrichten sollten das Host-Header-Feld unterstützen, um den Host zu identifizieren, und wenn die Anforderungsnachricht kein Host-Header-Feld enthält, wird 400Bad Request gemeldet .
- Bandbreitenoptimierung für HTTP1.1
- In HTTP1.0 gibt es einige Phänomene der Bandbreitenverschwendung, zum Beispiel benötigt der Client nur einen Teil eines Objekts, aber der Server sendet das gesamte Objekt. Beispielsweise muss der Client nur einen Teil eines Dokuments anzeigen oder beim Herunterladen einer großen Datei die Unterbrechungspunkt-Wiederaufnahme unterstützen, anstatt die vollständige Datei nach einer Unterbrechung erneut herunterladen zu müssen.
- HTTP1.1 führt das Range-Header-Feld in die Anforderungsnachricht ein, wodurch nur ein bestimmter Teil der Ressource angefordert werden kann . Das Header-Feld Content-Range in der Antwortnachricht deklariert den Offset-Wert und die Länge des zurückgegebenen Objekts. Wenn der Server mit dem vom Objekt angeforderten Bereichsinhalt antwortet, lautet der Antwortcode 206, wodurch verhindert wird, dass der Cache die Antwort als vollständiges Objekt missversteht.
- Wenn die Anforderungsnachricht einen relativ großen Entitätsinhalt enthält, aber nicht sicher ist, ob der Server die Anforderung annehmen kann (z. B. ob er die Berechtigung hat), wird er zu diesem Zeitpunkt verschwendet, wenn eine Anforderung mit einer großen Entität vorschnell gesendet wird Bandbreite, wenn sie abgelehnt wird. HTTP1.1 hat einen neuen Statuscode 100 hinzugefügt. **Der Client sendet eine Anfrage nur mit dem Header-Feld im Voraus. Wenn der Server die Anfrage aus Gründen wie Berechtigungen ablehnt, gibt er einen Antwortcode 401 zurück, wenn der Server akzeptiert die Anfrage, es wird gesendet. Wenn der Response-Code 100 ist, kann der Client weiterhin eine vollständige Anfrage mit Entitäten senden. **ps: HTTP1.0 unterstützt den Antwortcode 100 nicht, aber der Client kann das Header-Feld „Expect“ in die Anforderungsnachricht einfügen und seinen Wert auf „100-Continue“ setzen.
- HTTP1.1 definiert außerdem 24 weitere Antwortcodes: Das neu hinzugefügte 1xx zeigt an, dass der Server einen Teil der Daten akzeptiert hat und der Anforderer die Anfrage weiter senden soll, außerdem gibt es 409 (Konflikt), das anzeigt, dass die angeforderte Ressource mit dem in Konflikt steht aktueller Status der Ressource; 410 (Gone) gibt an, dass eine Ressource auf dem Server dauerhaft gelöscht wurde.
- HTTP1.1-Leistungsengpass
- Unkomprimierter Header : Der Request-Response-Header wird direkt ohne Komprimierung gesendet, je mehr Header-Informationen, desto größer die Verzögerung. Wenn Sie mehrere Anfragen mit großen Headern senden, verursacht dies einen hohen Systemaufwand.
- Head-of-Line-Blockierung : Der Server antwortet in der Reihenfolge der Anfragen. Wenn der Server langsam antwortet oder eine Anfrage blockiert wird, kann der Client keine Daten abrufen, was zu einer Head-of-Line-Blockierung führt.
- Eingeschränkte Prioritätseinstellung : Wenn der Browser mehrere Anfragen für einen bestimmten Domainnamen öffnet und einige Ressourcen auf der Webseite wichtiger sind als andere, erhöht dies den Warteschlangeneffekt von Ressourcen: Das heißt, Ressourcen mit hoher Priorität werden zuerst angefordert und Ressourcen mit hoher Priorität werden zuerst angefordert, dann wird eine Ressource mit niedrigerer Priorität angefordert, und der Browser wird während des Zeitintervalls zum Anfordern einer Ressource mit höherer Priorität keine neue Anforderung mit niedrigerer Priorität initiieren.
- HTTP2 basiert auf HTTPS, daher ist die Sicherheit von HTTP2 gewährleistet
- Header-Komprimierung : HTTP2 komprimiert den Header. Wenn mehrere Anfragen gleichzeitig gesendet werden und ihre Header alle gleich oder ähnlich sind, komprimiert HTTP2 den wiederholten Teil. Der sogenannte HPACK-Algorithmus: Pflegen Sie gleichzeitig eine Header-Informationstabelle auf Client und Server, alle Felder werden in dieser Tabelle gespeichert, eine Indexnummer wird generiert und das gleiche Feld wird in Zukunft nicht mehr gesendet. Es wird nur die Indexnummer gesendet, was die Geschwindigkeit verbessern kann.
- Binärformat : Im Gegensatz zu den Klartextnachrichten in HTTP1.1 nimmt HTTP2 das Binärformat auf umfassende Weise an. Sowohl Header-Informationen als auch Datenkörper sind binär und werden zusammen als Frames bezeichnet: Header-Informationsrahmen und Datenrahmen. Dies ist sehr rechnerfreundlich, da er beim Empfang der Nachricht den Klartext nicht in Binärtext umwandeln muss, sondern die Binärnachricht direkt parst, was die Effizienz der Datenübertragung erhöht.
- Datenfluss : HTTP2-Pakete werden nicht der Reihe nach gesendet. Aufeinanderfolgende Datenpakete in derselben Verbindung können zu unterschiedlichen Antworten gehören. Daher muss das Paket markiert werden, um anzuzeigen, zu welcher Antwort es gehört. Jedes Anforderungs- oder Antwortdatagramm wird als Datenstrom bezeichnet, und jeder Datenstrom ist mit einer eindeutigen Nummer gekennzeichnet, die festlegt, dass die Anzahl der vom Client gesendeten Datenströme ungerade und die Anzahl der vom Server gesendeten Datenströme gerade ist . Der Client kann auch die Priorität des Datenstroms angeben, und der Server antwortet zuerst mit hoher Priorität auf die Anfrage.
- Multiplexing wird verwendet, um Head-of-Line-Blocking zu lösen : HTTP2 kann gleichzeitig mehrere Anforderungen oder Antworten in einer Verbindung senden, anstatt eine Eins-zu-Eins-Korrespondenz nacheinander. Die serielle Antwort in HTTP1.1 wurde entfernt, sodass Sie nicht in der Warteschlange warten müssen und es kein Problem mit Head-of-Line-Blockierung geben wird, was die Verzögerung reduziert und die Verbindungsauslastung erheblich verbessert. Bei einer TCP-Verbindung erhält der Server beispielsweise zwei Anfragen von Client A und B. Wenn er feststellt, dass der Verarbeitungsprozess von A sehr zeitaufwändig ist, antwortet er auf den verarbeiteten Teil der Anfrage von A und antwortet dann auf die Anfrage von B. und antwortet dann auf A nach Abschluss. Fordern Sie den Rest an.
- Server-Push : HTTP2 verbessert auch in gewisser Weise die traditionelle Request-Response-Arbeitsweise: Der Server antwortet nicht mehr passiv, sondern kann auch aktiv Nachrichten an den Client senden. Wenn der Browser beispielsweise nur HTML anfordert, sendet er aktiv statische Ressourcen wie JS- und CSS-Dateien, die im Voraus an den Client verwendet werden können, um Verzögerungen zu reduzieren.
- Das Problem mit HTTP2 besteht darin, dass mehrere HTTP-Anforderungen eine TCP-Verbindung multiplexen.Das zugrunde liegende TCP-Protokoll weiß nicht, wie viele HTTP-Anforderungen vorhanden sind. Sobald ein Paketverlust auftritt, wird der TCP-Neuübertragungsmechanismus ausgelöst, sodass in einer TCP-Verbindung alle HTTP-Anforderungen müssen warten, bis das verlorene Paket erneut übertragen wird, was zu einer Blockierung führt. Und HTTP2 basiert auf HTTPS, hat nicht nur einen TCP-Handshake, sondern auch einen TCP + TLS-Handshake, der zwei Handshake-Verzögerungsprozesse erfordert.
- HTTP3 ersetzt das TCP-Protokoll auf der unteren HTTP-Schicht durch UDP, um das Paketverlustproblem zu lösen. UDP kümmert sich nicht um die Reihenfolge der Anfragenantworten und um Paketverluste, selbst wenn Paketverluste auftreten, werden andere Anfragen nicht blockiert. UDP ist eine unzuverlässige Übertragung, aber das UDP-basierte QUIC-Protokoll kann ähnlich wie TCP eine zuverlässige Übertragung erreichen.
- QUIC ist ein von Google entwickeltes UDP-basiertes Internet-Transport-Layer-Protokoll mit niedriger Latenz, das über einen eigenen Satz von Übertragungsmechanismen verfügt, um die Zuverlässigkeit der Übertragung zu gewährleisten. Wenn in einem Datenfluss ein Paketverlust auftritt, wird nur dieser Datenfluss blockiert, und andere Datenflüsse sind nicht betroffen.
- Das TLS3-Upgrade lässt die neueste Version 1.3 aus, und der Header-Komprimierungsalgorithmus wird ebenfalls auf QPack aktualisiert
- HTTPS benötigt sechs Interaktionen, um eine Verbindung herzustellen (Drei-Wege-Handshake und TLS/1.3-Drei-Wege-Handshake); QUIC führt die vorherigen sechs Interaktionen von TCP und TLS/1.3 direkt zu drei zusammen, wodurch die Anzahl der Interaktionen reduziert wird.
HTTP lange Verbindung und kurze Verbindung
- HTTP1.0 verwendet standardmäßig eine kurze Verbindung (keine Verbindung), d. h. jedes Mal, wenn der Browser und der Server auf eine Anfrage antworten, wird eine TCP-Verbindung hergestellt und die Verbindung wird beendet, nachdem die Anfrage abgeschlossen ist. Wenn eine HTML- oder andere Art von Webseite, auf die der Client-Browser zugreift, andere Webressourcen wie JavaScript-Dateien, Bilddateien, CSS-Dateien usw. enthält, erstellt der Browser, wenn er auf eine solche Webressource trifft, eine HTTP-Sitzung. Dies hat offensichtlich das Problem, dass es Zeitverschwendung ist, TCP-Verbindungen mehrmals aufzubauen und zu unterbrechen.
- HTTP1.1 begann damit, lange Verbindungen zu verwenden, um die Verbindungseigenschaften beizubehalten. Um lange Verbindungen zu verwenden, sollten Sie Connection:keep-alive in den Header einfügen
- Vorteile und Nachteile:
- Lange Verbindungen können mehr TCP-Einrichtungs- und Schließvorgänge einsparen, Abfall reduzieren und Zeit sparen.Für Kunden, die häufig Ressourcen anfordern, sind lange Verbindungen besser geeignet. Das Problem ist jedoch, dass der Server, wenn die lange Verbindung nicht geschlossen wurde, mit zunehmender Anzahl von Client-Verbindungen früher oder später nicht mehr damit umgehen kann, sodass der Server einige Strategien anwenden muss, z lange Zeit nicht aufgetreten ist. Es kann einige böswillige Verbindungen daran hindern, Dienstschäden auf dem Server zu verursachen, oder die maximale Anzahl langer Verbindungen für jeden Client festlegen.
- Kurze Verbindungen sind für den Server leicht zu verwalten, und die bestehenden Verbindungen sind nützliche Verbindungen ohne zusätzliche Steuermittel, aber wenn der Client häufig anfragt, werden Zeit und Bandbreite für TCP-Einrichtungs- und Schließungsoperationen verschwendet.
- Wann verwenden:
- Lange Verbindungen werden hauptsächlich für häufige Operationen und Punkt-zu-Punkt-Kommunikation verwendet, und die Anzahl der Verbindungen sollte nicht zu hoch sein.
- Kurze Verbindungen eignen sich für Situationen, in denen eine große Menge gleichzeitiger, aber seltener Operationen vorhanden sind.
DNS-bezogene Kenntnisse
DNS verwendet das TCP-Protokoll oder das UDP-Protokoll
DNS: Domain Name System ist ein Dienst des Internets, eine verteilte Datenbank, die Domain-Namen und IP-Adressen einander zuordnet und so einen bequemeren Zugang zum Internet ermöglicht. DNS verwendet TCP- und UDP-Port 53. Seine Hauptfunktion besteht darin, Domänennamen in IP-Adressen zu übersetzen.Dieser Vorgang wird als Auflösung von DNS-Domänennamen bezeichnet.
-
DNS verwendet das TCP-Protokoll bei der Durchführung von Zonenübertragungen und das UDP-Protokoll für die Domänennamenauflösung
-
Zonentransfer: Die DNS-Spezifikation spezifiziert zwei Arten von DNS-Servern, einer wird als primärer DNS-Server und der andere als sekundärer DNS-Server bezeichnet. In einer Zone liest der primäre DNS-Server die DNS-Dateninformationen der Zone aus seiner eigenen Datendatei, und der sekundäre DNS-Server liest die DNS-Dateninformationen der Zone vom primären DNS-Server der Zone. Wenn ein sekundärer DNS-Server gestartet wird, muss er mit dem primären DNS-Server kommunizieren und Dateninformationen laden.
-
Es gibt zwei Hauptüberlegungen bei der Verwendung von TCP für Zonenübertragungen:
- Der sekundäre DNS-Server fragt regelmäßig (normalerweise drei Stunden) den primären Domain Name Server ab, um zu erfahren, ob sich die Daten geändert haben. Bei einer Änderung wird ein Zonentransfer durchgeführt, um die Daten zu synchronisieren. Die Zonenübertragung wird TCP anstelle von UDP verwenden, da die synchron übertragene Datenmenge viel größer ist als die einer Anfrage und Antwort (TCP kann 1440 Bytes gleichzeitig senden).
- TCP ist eine zuverlässige Verbindung, die die Genauigkeit der Daten gewährleistet.
-
Das UDP-Protokoll wird für die Domänennamenauflösung verwendet: Der Client fragt den DNS-Server nach dem Domänennamen ab, und der zurückgegebene Inhalt überschreitet im Allgemeinen nicht 512 Bytes, die per UDP übertragen werden können. Es ist nicht erforderlich, den Drei-Wege-Handshake von TCP zu durchlaufen, sodass die Last auf dem DNS-Server geringer und die Antwort schneller ist.
DNS-Hijacking
Beim Domainnamen-Hijacking wird der Domainname der Zielwebsite in die falsche IP-Adresse aufgelöst, indem der Domainnamenauflösungsserver (DNS) angegriffen oder der Domainnamenauflösungsserver (DNS) gefälscht wird, sodass der Benutzer nicht auf die Zielwebsite zugreifen kann oder absichtlich oder fordert den Benutzer böswillig auf, auf die angegebene IP zuzugreifen. Der Zweck der Adresse (Website). Die Folge ist , dass auf eine bestimmte URL nicht zugegriffen werden kann oder auf eine gefälschte URL zugegriffen wird .
Einerseits kann das Hijacking von Domainnamen die Online-Erfahrung des Benutzers beeinträchtigen. Benutzer werden auf gefälschte Websites geleitet und können nicht normal im Internet surfen. Nachdem der Domainname einer Website mit einer großen Anzahl von Benutzern gekapert wurde, werden die nachteiligen Auswirkungen weitergehen erweitern, andererseits können Nutzer auf gefälschte Websites gelockt werden, Login- und andere Vorgänge auf der Website führen zum Durchsickern privater Daten.
Lösung: Wenn Sie die IP-Adresse der Kommunikation kennen, können Sie über die IP-Adresse direkt darauf zugreifen.
DNS-Vergiftung
Da DNS das UDP-Protokoll verwendet, um Abfrage- und Antwortpakete zu übertragen, handelt es sich um einen einfachen Vertrauensmechanismus. Für das empfangene Antwortdatenpaket werden nur die IP-Adresse, der Port und die zufällige Anfrage-ID des ursprünglichen Abfragepakets bestätigt, ohne dass die Rechtmäßigkeit des Datenpakets analysiert wird. Wenn es übereinstimmt, erhält es es als korrektes Antwortpaket, führt eine DNS-Auflösung durch und verwirft alle nachfolgenden Antwortpakete, was es dem Angreifer ermöglicht, sich als Root-DNS-Server auszugeben und ein gefälschtes Antwortpaket an den lokalen DNS-Server zu senden, um diesen präventiv zu verseuchen Lokaler DNS-Server DNS-Caching
DNS-Poisoning-Cracking, wenn sich Daten im lokalen DNS-Cache befinden, wird es nicht gelingen.
Analyse von Domainnamen
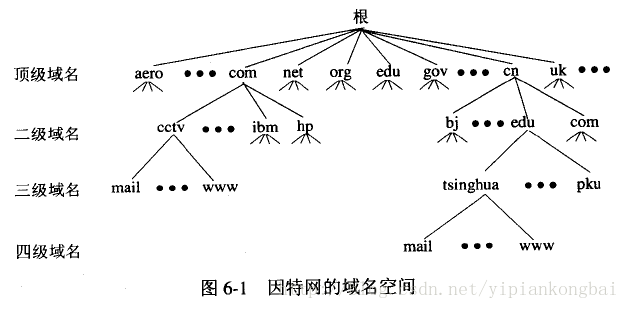
Zum Beispiel ein Domänenname: www.hty.com
- Top-Level-Domain (TLD): .com
- Sub-Level (Second-Level) Domain Name (SLD): .hty, diese Ebene des Domain-Namens kann von Benutzern registriert werden
- Hostname (Host): www, auch als Third-Level-Domain-Name bekannt, das ist der Name, den der Benutzer dem Server in seiner eigenen Domäne zuweist und der vom Benutzer beliebig vergeben werden kann.
DNS-Domänennamenauflösung
-
Der Browser überprüft seinen eigenen Cache, um zu sehen, ob es eine Regel gibt, die dem Domainnamen entspricht, und gibt sie direkt zurück, andernfalls prüfen Sie die Hosts-Datei, um zu sehen, ob es eine Regel gibt, die dem Domainnamen entspricht, und wenn ja, verwenden Sie direkt die IP Adresse in der hosts-Datei.
-
Wenn keine Hosts-Datei vorhanden ist, sendet der Browser eine DNS-Anfrage an den lokalen DNS-Server. Der lokale DNS-Server wird im Allgemeinen vom Anbieter des lokalen Netzwerkzugriffsservers bereitgestellt. Nachdem die DNS-Anfrage beim lokalen DNS-Server angekommen ist, fragt der lokale DNS-Server zunächst seinen Cache-Eintrag ab, kann, falls vorhanden, das Ergebnis direkt zurückgeben, und wenn es nicht gefunden wird, fragt er auch den DNS-Root-Server ab.
-
Wenn es einen DNS-Root-Domain-Nameserver gibt, wird er zurückgeben, wenn nicht, teilt er dem lokalen DNS-Server mit, dass Sie zum Top-Level-Domain-Server gehen können, um die Abfrage fortzusetzen, und die Adresse der Top-Level-Domain angeben Server.
-
Der lokale DNS-Server sendet weiterhin Anfragen an den Top-Level-Domain-Server, also den .com-Domain-Server Nach Erhalt der Anfrage gibt der .com-Domain-Server die entsprechende Beziehung zwischen dem Domain-Namen und der IP-Adresse nicht direkt zurück , aber teilen Sie dem lokalen DNS-Server die aufgelöste Serveradresse mit.
-
Schließlich sendet der lokale DNS-Server eine Anfrage an den Auflösungsserver des Domänennamens. Zu diesem Zeitpunkt kann eine entsprechende Beziehung zwischen dem Domänennamen und der IP-Adresse empfangen werden. Der lokale DNS-Server gibt nicht nur die IP-Adresse an den Benutzer zurück Computer, sondern speichert die entsprechende Beziehung auch in der hosts-Datei im Cache, damit bei der nächsten Abfrage anderer Benutzer die Ergebnisse direkt zurückgegeben werden können.
DNS iterative Abfrage rekursive Abfrage
Die Anfrage vom Host an den lokalen Domain-Name-Server nimmt im Allgemeinen eine rekursive Anfrage an : Wenn der vom Host angefragte lokale Domain-Name-Server die IP-Adresse des abgefragten Domain-Namens nicht kennt, sendet der lokale Domain-Name-Server weiterhin eine Anfrage Anfragen an andere Root-Domain-Name-Server als DNS-Client-Nachricht (mit der Abfrage des Hosts fortfahren), anstatt dem Host zu erlauben, die nächste Abfrage selbst durchzuführen. Daher ist das von der rekursiven Abfrage zurückgegebene Abfrageergebnis entweder die abzufragende IP-Adresse oder es wird ein Fehler gemeldet, der anzeigt, dass die gewünschte IP-Adresse nicht abgefragt werden kann.
**Iterative Abfrage vom lokalen Domain-Server an den Root-Domain-Name-Server: **Wenn der Root-Domain-Name-Server die vom lokalen Domain-Name-Server gesendete Iterative-Query-Request-Nachricht empfängt, gibt er entweder die abzufragende IP-Adresse an oder teilt sie mit der lokale Server, der aufgerufen werden soll. Welcher Nameserver abgefragt werden soll. Lassen Sie dann den lokalen Server nachfolgende Abfragen durchführen.Der Root-Domain-Name-Server teilt dem lokalen Domain-Name-Server normalerweise dieIP-Adresse des Top-Level-Domain-Name-Servers mit, die er kennt, und bittet denlokalen Domain-Name-Server, die Top-Level-Domain abzufragen Name Server. Der Top-Level-Domain-Name-Server gibt entweder die IP-Adresse an oder teilt dem lokalen Server mit, welcher autoritative Domain-Name-Server (hty.com) als nächstes abgefragt werden soll.
Was passiert, nachdem der Browser die URL eingegeben hat
-
Der Browser löst den Hostnamen des Servers aus der URL auf und wandelt ihn in eine IP-Adresse um (DNS Domain Name Resolution)
-
Der Browser baut eine TCP-Verbindung zum Server auf (Drei-Wege-Handshake)
- Nach Erhalt der dem Domänennamen entsprechenden IP-Adresse wird eine TCP-Verbindungsanforderung an Port 80 des WEB-Serverprogramms mit einem zufälligen Port (1024-65535) initiiert, und die Verbindungsanforderung wird in den TCP/IP-Protokollstapel des Kernels eingegeben ( verwendet, um die Anfrage zu identifizieren).
-
Der Browser sendet eine HTTP-Anforderungsnachricht an den Server
-
Der Server analysiert die Anforderung und sendet eine HTTP-Antwortnachricht zurück an den Browser
- Nachdem die Serverseite die Anfrage erhalten hat, verarbeitet der Webserver (genauer gesagt sollte es der http-Server sein) die Anfrage, wie Apache, Ngnix (Load Balancing), IIS usw. Der Webserver analysiert die Benutzeranforderung, weiß, welche Ressourcendateien geplant werden müssen, und verarbeitet dann die Benutzeranforderung und Parameter über die entsprechenden Ressourcendateien, ruft die Datenbankinformationen ab und gibt das Ergebnis schließlich über den Webserver an den Browser-Client zurück.
-
Der Browser analysiert den Antwortinhalt
-
Schließen Sie die TCP-Verbindung (vier Wellen)
-
Seite rendern (DOM-Baum, CSS-Regelbaum erstellen)
TCP-Drei-Wege-Handshake und Vier-Wege-Wave
TCP-Nachrichtenformat:
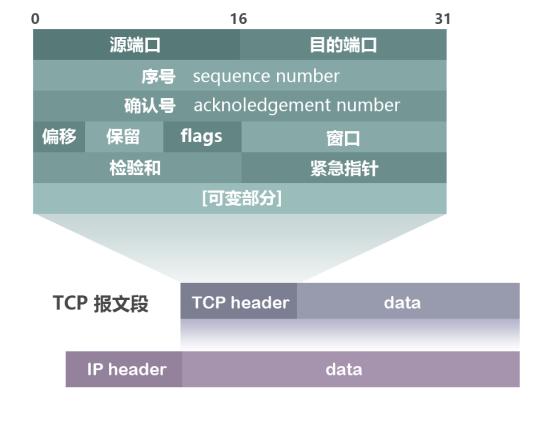
- Sequenznummer: Die Sequenznummer, die 32 Bits belegt, wird verwendet, um den von der TCP-Quelle zum Ziel gesendeten Bytestrom zu identifizieren, und wird markiert, wenn der Initiator Daten sendet. Ziel ist es, das Störungsproblem zu lösen.
- Acknowledgement Number: Ack Sequence Number, belegt 32 Bits, nur wenn das Ack Flag 1 ist, ist das Acknowledgement Sequence Number Feld gültig, die Acknowledgement Party Ack = Sender Seq + 1.
- Flag-Bits: insgesamt 6, nämlich URG, ACK, PSH, RST, SYN, FIN usw.
- URG: Der dringende Zeiger ist gültig.
- ACK: Bestätigen Sie, dass die Sequenznummer gültig ist.
- PSH: Der Empfänger sollte diese Nachricht so schnell wie möglich an die Anwendungsschicht liefern.
- RST: Verbindung zurücksetzen.
- SYN: Initiiere eine neue Verbindung.
- FIN: Lösen Sie eine Verbindung.
- Fenstergröße: Flusskontrolle, die verwendet wird, um die eigenen Verarbeitungsfähigkeiten zu identifizieren
Drei-Wege-Handshake: Stellen Sie eine TCP-Verbindung her
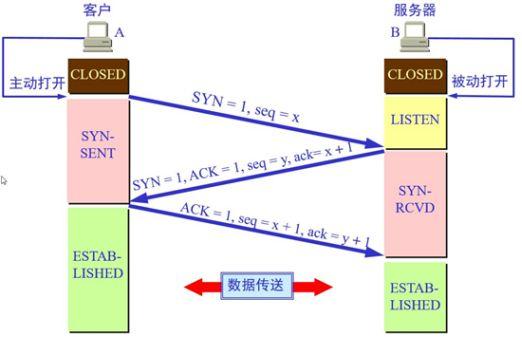
Eine TCP-Verbindung muss von einer Partei aktiv und von der anderen passiv geöffnet werden. Der Client, der die Verbindung vor dem Handshake aktiv öffnet, beendet die CLOSED-Phase, und der Server, der passiv geöffnet wird, beendet ebenfalls die CLOSED-Phase und tritt in die LISTEN-Phase ein. Starten Sie dann den Drei-Wege-Handshake:
-
Erstens: Zuerst sendet der Client eine TCP-Nachricht an den Server.
- Das Flag-Bit ist SYN = 1, ACK = 0, was anzeigt, dass eine neue Verbindung angefordert wird;
- Die Sequenznummer ist seq = x; +
- Dann tritt der Client in die SYN-SENT-Phase ein.
-
Zweitens: Nachdem der Server die TCP-Nachricht vom Client empfangen hat, beendet er die LISTEN-Phase und gibt eine TCP-Nachricht zurück.
- Die Flag-Bits sind SYN = 1 und ACK = 1, was bedeutet, dass die Seq-Seriennummer der Nachricht des Clients als gültig bestätigt wird, der Server die vom Client gesendeten Daten normalerweise empfangen kann und zustimmt, eine neue Verbindung herzustellen (das sagen Sie dem Client, dass der Server Ihre Daten erhalten hat) ;
- Die Sequenznummer ist seq = y und gibt die anfängliche Sequenznummer des gesendeten Bytestroms an, wenn der Server als Sender fungiert;
- Die Bestätigungsnummer ist ack = x + 1, was bedeutet, dass der Client seq empfangen wird und sein Wert um 1 als Wert seiner eigenen Bestätigungsnummer ack erhöht wird, und dann tritt der Server in die SYN-RCVD-Stufe ein.
-
Drittens: Nachdem der Client die TCP-Nachricht vom Server zur Bestätigung des Datenempfangs empfangen hat, ist klar, dass die Datenübertragung vom Client zum Server normal ist, und die SYN-SENT-Phase ist beendet. Und geben Sie die letzte TCP-Nachricht zurück.
- Das Flag-Bit ACK = 1, was bedeutet, den Empfang des Signals zu bestätigen, dass der Server der Verbindung zustimmt (das heißt, dem Server mitzuteilen, dass ich weiß, dass Sie die von mir gesendeten Daten erhalten haben);
- Die Seriennummer ist seq = x + 1, was bedeutet, dass die serverseitige Bestätigungsnummer ack empfangen wird und ihr Wert als eigener Seriennummernwert verwendet wird;
- Die Bestätigungsnummer ist ack = y + 1, was bedeutet, dass die serverseitige Seriennummer seq empfangen wird und ihr Wert um 1 zum Wert ihrer eigenen Bestätigungsnummer Ack hinzugefügt wird;
Der Klient tritt dann in die ERWEITERTE (etablierte) Phase ein. Nachdem der Server die TCP-Nachricht "Bestätigung des Empfangs von Serverdaten" vom Client erhalten hat, ist klar, dass die Datenübertragung vom Server zum Client normal ist. Beenden Sie die SYN-SENT-Phase und betreten Sie die ESTABLISHED-Phase.
In der vom Client und vom Server übertragenen TCP-Nachricht werden die Werte der Bestätigungsnummer ack und der Sequenznummer seq beider Parteien auf der Grundlage der seq- und ack-Werte der anderen Partei berechnet, wodurch die Kontinuität der TCP-Nachrichtenübertragung sichergestellt wird. Sobald die von einer bestimmten Partei gesendete TCP-Nachricht verloren gegangen ist, kann der Handshake nicht fortgesetzt werden, um den reibungslosen Abschluss des Drei-Wege-Handshake sicherzustellen.
Vier Wellen: Schließen Sie die TCP-Verbindung
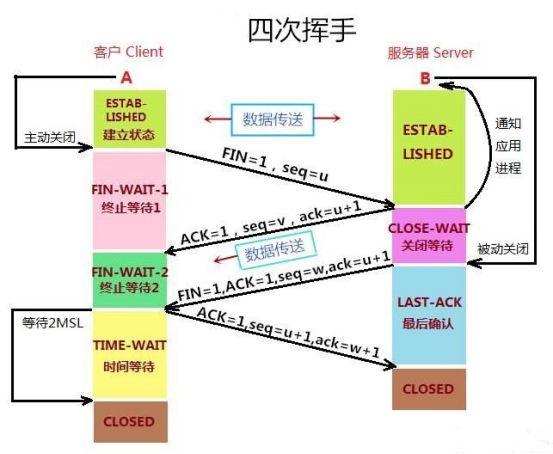
Die TCP-Verbindung ist bidirektional, und der Verbindungsabbau muss von einer Seite aktiv und von der anderen Seite passiv abgebaut werden. Der Client, der die Verbindung vor dem Winken aktiv abbaut, beendet die ESTABLISHED-Phase und beginnt viermal zu winken.
-
Erstens: Der Client möchte die Verbindung abbauen und sendet eine TCP-Nachricht an den Server
- Das Flag-Bit ist FIN = 1, was anzeigt, dass die Freigabe der Verbindung angefordert wird.
- Die Sequenznummer ist seq = u
- Dann tritt der Klient in die Phase FIN-WAIT-1 ein, die die halbgeschlossene Phase ist. Und hören Sie auf, Daten in Richtung vom Client zum Server zu senden (normale Bestätigungsnachrichten können weiterhin gesendet werden), aber der Client kann weiterhin Daten vom Server akzeptieren.
-
Zweitens: Nachdem der Server die vom Client gesendete TCP-Nachricht empfangen hat, weiß er, dass der Client die Verbindung abbauen möchte, dann beendet der Server die ESTABLISHED-Phase, tritt in die CLOST-WAIT-Phase (geschlossener Wartezustand) ein und sendet eine TCP-Nachricht zurück
- Das Flag-Bit ist ACK = 1, was anzeigt, dass die vom Client gesendete Anforderung zum Trennen der Verbindung empfangen wurde.
- Folgenummer seq = v
- Die Bestätigungsnummer ist ack = u + 1, was bedeutet, dass auf der Grundlage des Empfangs der Client-Nachricht 1 zu ihrem fortlaufenden Nummernseq-Wert als Wert der Bestätigungsnummer ack dieses Segments der Nachricht addiert wird. Dann beginnt der Server mit der Vorbereitung, die Verbindung vom Server zum Client freizugeben.
- Nach Erhalt der TCP-Nachricht vom Server bestätigt der Client, dass der Server die Verbindungsfreigabeanforderung vom Client erhalten hat, und dann beendet der Client die FIN-WAIT-1-Phase und tritt in die FIN-WAIT-2-Phase ein.
Die ersten beiden Wellen teilen dem Server nicht nur mit, dass der Client die Verbindung abbauen möchte, sondern lassen den Client auch wissen, dass der Server weiß, dass er die Verbindung abbauen möchte. So kann bestätigt werden, dass die Verbindung vom Client zum Server geschlossen ist.
-
Drittens: Nachdem der Server die ACK-Bestätigungsnachricht gesendet hat, ist er nach der CLOSED-WAIT-Phase bereit, die Verbindung vom Server zum Client zu trennen, und sendet erneut eine TCP-Nachricht an den Client.
- Die Flag-Bits sind FIN, ACK, was bedeutet, dass Sie bereit sind, die Verbindung zu trennen (das ACK ist hier keine Bestätigungsnachricht, um den Empfang der serverseitigen Nachricht zu bestätigen).
- Die Sequenznummer ist seq = w
- Die Bestätigungsnummer ist ack = u + 1, was bedeutet, dass auf der Grundlage des Empfangs der Client-Nachricht 1 zu ihrem fortlaufenden Nummernseq-Wert als Wert der Bestätigungsnummer ack dieses Segments der Nachricht addiert wird.
- Dann beendet der Server die CLOSE-WAIT-Phase und tritt in die LAST-ACK-Phase ein. Und hören Sie auf, Daten in Richtung vom Server zum Client zu senden, aber der Server kann immer noch Daten empfangen, die vom Client übertragen werden.
- Das Vorhandensein der Stufe CLOST-WAIT soll sicherstellen, dass der Server ein Bestätigungspaket sendet, um den Client darüber zu informieren, dass er die nicht verarbeiteten Daten verarbeiten soll.
-
Viertens: Der Client empfängt die vom Server gesendete TCP-Nachricht, bestätigt, dass der Server zum Trennen der Verbindung bereit ist, beendet die Phase FIN-WAIT-2, tritt in die Phase TIME-WAIT ein und sendet eine Nachricht an den Server
- Das Flag-Bit ist ACK, was bedeutet, dass das Signal empfangen wurde, dass der Server bereit ist, die Verbindung abzubauen.
- Die Sequenznummer ist seq = u + 1, was bedeutet, dass aufgrund des Empfangs der serverseitigen Nachricht der Wert ihrer Bestätigungsnummer ack als Wert der Sequenznummer dieses Segments der Nachricht verwendet wird.
- Die Bestätigungsnummer ist ack = w + 1, was bedeutet, dass aufgrund des Empfangs der serverseitigen Nachricht der Wert ihrer Seriennummer seq + 1 als Wert der Bestätigungsnummer dieses Segments der Nachricht verwendet wird.
Dann beginnt der Client in der TIME-WAIT-Phase auf 2MSL zu warten . Nach Erhalt der vom Client gesendeten TCP-Nachricht beendet der Server die LAST-ACK-Phase und tritt in die CLOSED-Phase ein. Damit wird der Verbindungsabbau in Server-zu-Client-Richtung offiziell bestätigt. Nachdem der Client in der TIME-WAIT-Phase auf 2MSL gewartet hat, tritt er in die CLOSED-Phase ein und vervollständigt somit vier winkende Hände.
Die letzten beiden Wellen lassen den Client nicht nur wissen, dass der Server bereit ist, die Verbindung abzubauen, sondern lassen den Server auch wissen, dass der Client weiß, dass er bereit ist, die Verbindung abzubauen. Daher kann bestätigt werden, dass die Verbindung vom Server zum Client geschlossen ist, wodurch die "Vierwellen" abgeschlossen sind.
In der zwischen dem Client und dem Server übertragenen TCP-Nachricht werden die Werte der Bestätigungsnummer ack und der Sequenznummer seq beider Parteien auf der Grundlage der seq- und ack-Werte des jeweils anderen berechnet, wodurch die Kohärenz der TCP-Nachrichtenübertragung einmal sichergestellt wird Geht die von einer bestimmten Partei gesendete TCP-Nachricht verloren, kann sie nicht weiter winken, wodurch der reibungslose Abschluss der vier Handbewegungen sichergestellt wird.
Warum nicht zwei oder vier Händedrucke?
- Um zu verhindern, dass der Server einige nutzlose Verbindungen öffnet, um den Server-Overhead zu erhöhen und zu verhindern, dass das ungültige Verbindungsanforderungssegment plötzlich an den Server übertragen wird, was zu einem Fehler führt. Wenn es nur zwei Handshakes gibt, entspricht dies einem Verbindungsaufbau nach dem Ende des zweiten Handshakes, dann kann der Server nicht bestätigen, ob der Client sein eigenes Synchronisationssignal erhalten hat.Wenn das Signal, das der Verbindung zustimmt, aus irgendeinem Grund verloren geht, dann Client und Die anfängliche Seriennummer des Servers ist immer inkonsistent, was dazu führt, dass keine Verbindung hergestellt werden kann (der Client kann nicht wissen, ob der Server das Signal erhalten hat, das er verbinden möchte).
- Um eine zuverlässige Datenübertragung zu erreichen, müssen im Wesentlichen beide Parteien bei der TCP-Kommunikation eine Sequenznummer führen, um zu identifizieren, welche der gesendeten Datenpakete von der anderen Partei empfangen wurden. Der Prozess des Drei-Wege-Handshakes ist ein notwendiger Schritt für beide kommunizierenden Parteien, um sich gegenseitig über den Anfangswert der Seriennummer zu informieren und zu bestätigen, dass die andere Partei den Anfangswert der Seriennummer erhalten hat. Wenn es nur zwei Handshakes gibt, kann höchstens nur die anfängliche Seriennummer des Verbindungsinitiators bestätigt werden, während die Seriennummer des anderen Teilnehmers nicht bestätigt werden kann.
- Der Vier-Wege-Handshake ist offensichtlich unnötig, denn drei Mal kann bereits die Verbindung garantiert werden. Der zweite Handshake bedeutet, dass der Server die Anfrage des Clients erhalten hat, und es bedeutet auch, dass der Server zustimmt, sich mit dem Client zu verbinden.
Was soll ich tun, wenn beim Drei-Wege-Handshake ein Paketverlust (Nachrichtenverlust) auftritt?
- Wenn das vom Client an den Server gesendete SYN verloren geht und nicht ankommt, wird der Client regelmäßig eine Zeitüberschreitung feststellen und erneut übertragen, bis er die Bestätigung vom Server erhält.
- Wenn im TCP-Protokoll ein bestimmtes Ende auf eine Reihe von Anfragen innerhalb eines bestimmten Zeitbereichs antwortet, solange es das ACK-Paket der Antwort nicht erhält, ist es egal, ob die andere Partei, die es selbst angefordert hat, es nicht erhalten hat , oder die andere Partei hat es nicht erhalten, Es wird davon ausgegangen, dass ein Paketverlust aufgetreten ist, und der Timeout-Neuübertragungsmechanismus wird ausgelöst.
- Die erneute Übertragung von SYN wird dreimal versucht, und die Zeitintervalle sind 5,8 s, 24 s, 48 s
- Wenn das vom Server an den Client gesendete SYN + ACK verloren geht und nicht ankommt:
- Der Client denkt, dass der Server nicht das erhalten hat, was er gesendet hat, und sendet regelmäßig mit einer Zeitüberschreitung erneut.
- Der Server geht davon aus, dass das, was er gesendet hat, nicht zugestellt wurde, und hat die ACK nicht innerhalb der angegebenen Zeit erhalten, was eine Timeout-Neuübertragung auslöst. Es sendet das SYN + ACK-Paket erneut, nachdem es abwechselnd 3 Sekunden, 6 Sekunden und 12 Sekunden gewartet hat.
- Wenn das vom Client an den Server gesendete ACK auf halbem Weg verloren geht und den Server nicht erreicht. Zu diesem Zeitpunkt denkt der Client, dass die Verbindung nach dem Senden des ACK hergestellt wurde, und tritt in EXTABLISHED ein, aber der Server befindet sich immer noch im SYN-RCVD-Zustand, weil er das letzte ACK-Paket nicht erhalten hat.
- Aus Sicht des Servers wird der Server denken, dass das von ihm selbst gesendete SYN + ACK-Paket verloren gegangen ist, und er wird einen Timeout-Neuübertragungsmechanismus auslösen. **Wenn es nicht erfolgreich war, hat der Server eine Timeout-Einstellung für die Timeout-Neuübertragung. Nach dem Timeout sendet er eine RTS-Nachricht an den Client und tritt in die CLOSE-Phase ein. **Dies geschieht, um SYN-Flood-Angriffe zu verhindern, an denen der Client auch die Verbindung schließen sollte.
- SYN-Flood-Angriff (DoS-Angriff): Der Angreifer sendet eine große Anzahl von TCP-SYN-Nachrichtensegmenten, ohne den dritten Handshake abzuschließen.Der Server weist Ressourcen für eine große Anzahl solcher halboffenen Verbindungen zu, was schließlich zur Erschöpfung der Serverressourcen führt.
- Befindet sich der Server im Zustand SYN-RCVD und empfängt das tatsächlich vom Client gesendete Datenpaket, betrachtet er die Verbindung als aufgebaut und geht in den Zustand ESTABLISHED über. Wenn der Client ein Datenpaket im ESTABLISHED-Zustand sendet, trägt es die Bestätigungssequenznummer der vorherigen ACK, sodass der Server selbst dann, wenn das vom Client geantwortete ACK-Paket verloren geht, die Bestätigungssequenznummer der ACK weitergeben kann Paket beim Empfang des Datenpakets Gehen Sie normal in den ESTABLISHED-Zustand.
- Aus Sicht des Servers wird der Server denken, dass das von ihm selbst gesendete SYN + ACK-Paket verloren gegangen ist, und er wird einen Timeout-Neuübertragungsmechanismus auslösen. **Wenn es nicht erfolgreich war, hat der Server eine Timeout-Einstellung für die Timeout-Neuübertragung. Nach dem Timeout sendet er eine RTS-Nachricht an den Client und tritt in die CLOSE-Phase ein. **Dies geschieht, um SYN-Flood-Angriffe zu verhindern, an denen der Client auch die Verbindung schließen sollte.
Warum gibt es dreimal Händeschütteln, aber viermal Winken?
- Der Grund, warum die TCP-Verbindung nur drei Handshakes benötigt, ist: Während des zweiten Handshake-Prozesses verwendet die vom Server an den Client gesendete TCP-Nachricht SYN und ACK als Flags Verbindung; ACK Dies ist eine Bestätigungsnachricht, die dem Client mitteilt, dass der Server seine Anforderungsnachricht erhalten hat. Die SYN-Verbindungsaufbaunachricht und die ACK-Bestätigungsnachricht werden im selben Handshake übertragen, sodass der Drei-Wege-Handshake weder zu viel noch zu wenig ist, nur damit die beiden Parteien miteinander kommunizieren können.
- Der Grund, warum TCP beim Abbau der Verbindung viermal winken muss, liegt darin, dass die ACK-Bestätigungsnachricht und die FIN-Verbindungsfreigabenachricht von der zweiten bzw. dritten Welle übertragen werden. Dies liegt daran, dass der Server die Verbindung nicht sofort abbauen kann, wenn er die Verbindungsfreigabeanforderung des Clients erhält, da noch notwendige Daten verarbeitet werden müssen, sodass der Server zuerst ACK zurücksendet, um den Empfang der Nachricht zu bestätigen, und dann die Daten durch CLOSE verarbeitet -WAIT-Stufe Erst nachdem die Verbindung zum Abbau bereit ist, kann die FIN-Release-Connection-Nachricht zurückgesendet werden .
Warum wartet der Client in der TIME-WAIT-Phase auf 2MSL?
Bestätigen Sie, ob der Server die vom Client gesendete ACK-Bestätigungsnachricht erhalten hat : Wenn der Client die endgültige ACK-Bestätigungsnachricht sendet, ist nicht sicher, ob der Server die Nachricht empfangen kann. Nachdem der Client die ACK-Bestätigungsnachricht gesendet hat, stellt er daher einen Timer mit einer Dauer von 2 MSL ein. (MSL ist die maximale Segmentlebensdauer, der maximale Lebenszyklus einer TCP-Nachricht während der Übertragung. 2MSL ist die maximale Zeitdauer, die die vom Server gesendete FIN-Nachricht und die vom Client gesendete ACK-Bestätigungsnachricht gültig bleiben können. 2MSL).
Da der Server die vom Client innerhalb von 1MSL gesendete ACK-Bestätigungsnachricht nicht erhält, sendet er erneut eine FIN-Nachricht an den Client.
- Wenn der Client die FIN-Nachricht innerhalb von 2MSL erneut vom Server empfängt, bedeutet dies, dass der Server die vom Client gesendete ACK-Bestätigungsnachricht aus verschiedenen Gründen nicht erhalten hat und der Client erneut eine ACK-Bestätigungsnachricht an den Server sendet Starten Sie die Zeitmessung von 2MSL neu.
- Wenn der Client die FIN-Nachricht nicht vom Server innerhalb von 2MSL erhält, bedeutet dies, dass der Server die ACK-Bestätigungsnachricht normal erhalten hat und der Client in die CLOSED-Phase eintreten und vier Handzeichen vervollständigen kann.
** Verspätete TCP-Pakete im Netzwerk verschwinden lassen. **Damit soll verhindert werden, dass das ungültige Verbindungsanforderungssegment in dieser Verbindung erscheint. Nachdem der Client die letzte ACK-Nachricht gesendet hat, können alle Textsegmente, die während der Dauer dieser Verbindung generiert wurden, nach 2MSL aus dem Netzwerk verschwinden, so dass diese alte Nachricht nicht im nächsten neuen Verbindungsanforderungssegment erscheint.
Was ist falsch an der TIME-WAIT-Phase?
Auf einem TCP-Server mit vielen gleichzeitigen kurzen Verbindungen wird die Verbindung aktiv und normalerweise sofort geschlossen, wenn der Server die Verarbeitung der Anfrage beendet hat. In diesem Szenario befindet sich eine große Anzahl von Sockets im Zustand TIME_WAIT. Wenn die Parallelität des Clients weiterhin hoch ist, können einige Clients zu diesem Zeitpunkt keine Verbindung herstellen.
- Hohe Parallelität ermöglicht es dem Server, in kurzer Zeit eine große Anzahl von Ports gleichzeitig zu belegen , und die Ports reichen von 0 bis 65535, was nicht viele sind, außer denen, die vom System und anderen Diensten verwendet werden, gibt es sogar weniger Ports übrig.
- In diesem Szenario bedeutet eine kurze Verbindung eine Verbindung, bei der "die Zeit für die Geschäftsverarbeitung + Datenübertragung viel kürzer ist als die Zeit für das TIME-WAIT-Timeout" .
TCP-Keepalive-Mechanismus?
Der Keep-Alive-Mechanismus soll beurteilen, ob die andere Partei online ist oder nicht. TCP kann ungewöhnlich getrennte Verbindungen nicht erkennen. Es gibt keine Keep-Alive-Funktion für Verbindungen, die in der TCP-Spezifikation spezifiziert sind.
Implementierung des TCP-Keep-Alive-Mechanismus: Wenn der Timer aktiviert ist, sendet ein Ende der Verbindung über den Keep-Alive-Timer eine Keep-Alive-Erkennungsnachricht, und das andere Ende sendet eine ACK als Antwort, wenn die Nachricht empfangen wird .
- tcp_keepalice_time: 7200, Keep-Alive-Zeit, Standard 7200s
- tcp_keepalice_intvl: 75, Keep-Alive-Intervall, Standard 75s
- tcp_keepalice_probes: 9, die Anzahl der Keep-Alive-Probes, der Standardwert ist 9 mal
Der Prozess des Keep-Alive-Mechanismus: Das Ende der Verbindung, das die Keep-Alive-Funktion aktiviert, und die Verbindung ist innerhalb der Keep-Alive-Zeit inaktiv, sendet eine Keep-Alive-Erkennungsnachricht an die andere Partei und setzt das Keep zurück -alive timer, wenn eine Antwort empfangen wird. Wenn keine Antwortnachricht empfangen wird, sende eine Keep-Alive-Erkennungsnachricht nach einem Keep-Alive-Zeitintervall erneut an die andere Partei. Wenn die Antwortnachricht nicht empfangen wurde, fahre fort bis zur Anzahl von Sendezeiten erreicht die Anzahl der Keep-Alive-Probes. Zu diesem Zeitpunkt wird der andere Host als nicht erreichbar bestätigt und die Verbindung wird unterbrochen.
Der Unterschied und die Anwendungsszenarien von TCP und UDP
Sowohl TCP als auch UDP sind Transportschichtprotokolle
**User Datagram Protocol UDP (User Datagram Protocol) ist verbindungslos, wird so weit wie möglich geliefert, ohne Flusskontrolle und Staukontrolle, nachrichtenorientiert, unterstützt One-to-One, One-to-Many, Many-to-One und Viele-zu-viele interaktive Kommunikation. **UDP kann keine Flusskontrolle, Staukontrolle und andere Methoden durchführen, um eine Netzwerküberlastung zu vermeiden, wenn das Netzwerk überlastet ist. Wenn während der Übertragung ein Paketverlust auftritt, ist UDP außerdem nicht für die erneute Übertragung verantwortlich, selbst wenn die Reihenfolge des Eintreffens von Paketen falsch ist, gibt es keine Korrekturfunktion. Wenn Sie dieses Verhalten steuern müssen, müssen Sie es der Anwendung übergeben, die UDP implementiert, um es selbst zu handhaben.UDP stellt nur die Grundfunktionen als Transportschichtprotokoll bereit.
UDP-Anwendungsszenarien: Effizienz hat Priorität, und die Netzwerkkommunikationsgeschwindigkeit muss so schnell wie möglich sein, aber die Genauigkeit ist nicht sehr hoch und die Netzwerkkommunikationsqualität ist nicht hoch. Zum Beispiel: QQ-Chat, Online-Video, VoIP (Instant Messaging, hohe Geschwindigkeitsanforderungen, aber gelegentliche Unterbrechungen sind kein großes Problem, und der Neuübertragungsmechanismus ist völlig unnötig) und Rundfunk usw.
Das Übertragungssteuerungsprotokoll TCP (Transmission Control Protocol) ist verbindungsorientiert, bietet eine zuverlässige Zustellung, verfügt über Flusskontrolle und Staukontrolle, bietet Vollduplexkommunikation und ist auf Byteströme ausgerichtet (die von der Anwendungsschicht nach unten weitergegebenen Pakete werden als Bytestreams, Bytestreams in Datenblöcke ungleicher Größe organisieren) . Jede TCP-Verbindung kann nur eine Punkt-zu-Punkt-Verbindung (Eins-zu-Eins) sein.TCP verwirklicht vollständig verschiedene Steuerfunktionen während der Datenübertragung,kann eine Neuübertragungssteuerung von verlorenen Paketen durchführen und kannauch eine Sequenzsteuerung für Teilpakete durchführen, deren Reihenfolge ist außer Betrieb. Und diese hat UDP nicht. Darüber hinaus sendet TCP als verbindungsorientiertes Protokoll Daten nur dann, wenn die Existenz des Kommunikationspartners bestätigt wird , sodass die Verschwendung von Kommunikationsverkehr kontrolliert werden kann. TCP realisiert eine zuverlässige Übertragung durch Mechanismen wie Prüfsumme, Sequenznummer und Bestätigungsantwort, Neuübertragungssteuerung, Verbindungsmanagement und Fenstersteuerung.
TCP-Anwendungsszenarien: Szenarien, die keine hohe Effizienz, aber eine hohe Genauigkeit erfordern. Da während der Übertragung Vorgänge wie Datenbestätigung, erneute Übertragung und Sortierung erforderlich sind, ist die Effizienz nicht so hoch wie bei UDP, wie z. B. Dateiübertragung, E-Mail-Versand und -Empfang. TCP wird häufig in einigen zuverlässigen Anwendungen wie HTTP, HTTPS, FTP (File Transfer Protocol) und SMTP (Mail Transfer Protocol) verwendet.
Wie stellt TCP eine zuverlässige Übertragung sicher?
TCP stellt die Zuverlässigkeit hauptsächlich durch die folgenden Methoden sicher: ** Prüfsumme, Sequenznummer und Bestätigungsantwort, Timeout-Neuübertragung, Verbindungsmanagement, Flusskontrolle und Staukontrolle. ** Unter ihnen gehören die ersten drei zur Fehlerkontrolle.
- Prüfsumme: Bei der Datenübertragung wird das gesendete Datensegment als 16-Bit-Integer behandelt. Addieren Sie diese ganzen Zahlen. Und der vorherige Übertrag kann nicht verworfen werden, das Komplement wird später hinzugefügt und schließlich wird die Prüfsumme durch Invertieren erhalten.

Absender: Berechnen Sie die Prüfsumme und füllen Sie die Prüfsumme aus, bevor Sie die Daten senden.
Empfänger: Nach Erhalt der Daten berechnen Sie die Daten auf die gleiche Weise und vergleichen die Prüfsumme mit der des Senders.
Wenn die Prüfsumme des Empfängers nicht mit der des Senders übereinstimmt, müssen die Daten falsch übertragen worden sein. Die Konsistenz bedeutet jedoch nicht, dass die Daten korrekt übertragen werden müssen.
-
Seriennummer und Bestätigungsantwort
- Seriennummer: Jedes Datenbyte wird während der TCP-Übertragung nummeriert, was die Seriennummer ist.
- Die Seriennummer garantiert Zuverlässigkeit (wenn den empfangenen Daten Daten einer bestimmten Seriennummer fehlen, kann dies sofort erkannt werden)
- Garantiertes Eintreffen der Daten in zeitlicher Reihenfolge
- Verbessern Sie die Effizienz, realisieren Sie das mehrmalige Senden einer Bestätigung und entfernen Sie doppelte Daten
- Bestätigungsantwort: Während des TCP-Übertragungsprozesses sendet der Empfänger jedes Mal, wenn er Daten empfängt, eine Bestätigungsantwort an den Sender, dh er sendet eine ACK-Nachricht. Der Empfänger bestätigt die der Reihe nach ankommenden Daten und bestätigt, wenn das Flag-Bit ACK = 1 ist, dass das Bestätigungsfeld des Headers gültig ist. Beim Bestätigen zeigt der Bestätigungsfeldwert an, dass die Daten vor diesem Wert in der richtigen Reihenfolge angekommen sind. Wenn der Absender die Bestätigungsnachricht der gesendeten Daten erhält, wird er mit der Übertragung des nächsten Teils der Daten fortfahren, und wenn er die Bestätigungsnachricht nach einer gewissen Wartezeit nicht erhalten hat, startet er den Neuübertragungsmechanismus.
- Seriennummer: Jedes Datenbyte wird während der TCP-Übertragung nummeriert, was die Seriennummer ist.
-
Zeitüberschreitung Neuübertragung
-
Wenn die Nachricht gesendet wird und die Bestätigung des Empfängers nicht innerhalb eines bestimmten Zeitraums empfangen wird, sendet der Sender erneut (normalerweise stellt er nach dem Senden des Nachrichtensegments einen Wecker und sendet erneut, wenn zu gegebener Zeit keine Antwort empfangen wird).
-
Zwei Fälle: Datenpaketverlust oder Bestätigungspaketverlust


-
-
Verbindungsverwaltung: Drei-Wege-Handshake und Vier-Wege-Handshake, wenn TCP eingerichtet ist
-
Flusskontrolle: Wenn der Empfänger keine Zeit hat, die Daten des Absenders zu verarbeiten, kann er den Absender auffordern, die Senderate zu reduzieren, um Paketverluste zu vermeiden .
- Ursache: Die Geschwindigkeit, mit der der Empfänger Daten verarbeiten kann, ist begrenzt. Wenn der Sender Daten zu schnell sendet, ist der Puffer beim Empfänger voll und der Sender sendet weiter, was zu Paketverlusten führt, die wiederum eine Serie verursachen von Paketverlust und Neuübertragung Kettenreaktion.
- Es ist ein End-to-End-Problem.
-
Überlastungskontrolle: Reduzieren Sie die Datenübertragung, wenn das Netzwerk überlastet ist.
- Ursache: Wenn das Netzwerk sehr überlastet ist, erhöht das Senden von Daten zu diesem Zeitpunkt die Belastung des Netzwerks. Möglicherweise überschreiten die vom Sender gesendeten Daten die maximale Lebensdauer und erreichen den Empfänger nicht, was zu Paketverlusten führt. Um den TCP-Slow-Start-Mechanismus einzuführen, wird zunächst eine kleine Datenmenge gesendet, ähnlich wie bei der Pfadfindung, und nachdem der aktuelle Netzwerküberlastungszustand ermittelt wurde, wird entschieden, wie schnell Daten übertragen werden.
- Das Verhindern einer übermäßigen Dateneinspeisung in das Netzwerk ist ein globales Problem.
Gleitendes Fenster in TCP (Flusskontrolle)
Einführung
TCP ist ein Duplex-Protokoll, beide Gesprächspartner können gleichzeitig Daten empfangen und senden. Beide Parteien einer TCP-Sitzung unterhalten ein Sendefenster und ein Empfangsfenster . Die Größe des jeweiligen Empfangsfensters hängt von den Einschränkungen der Anwendung, des Systems und der Hardware ab (die TCP-Übertragungsrate kann nicht größer sein als die Datenverarbeitungsrate der Anwendung). Die Anforderungen an das jeweilige Sendefenster hängen von dem vom Peer mitgeteilten Empfangsfenster ab, und die Anforderungen sind dieselben.
Das gleitende Fenster löst das Problem der Flusskontrolle: Wenn das empfangende und das sendende Ende Datenpakete mit unterschiedlichen Geschwindigkeiten verarbeiten, wie kann man die beiden Parteien dazu bringen, eine Einigung zu erzielen ? Die gepufferten Daten auf der Empfängerseite werden an die Anwendungsschicht übertragen, aber dieser Prozess ist nicht zeitgerecht.Wenn die Sendegeschwindigkeit zu hoch ist, kommt es auf der Empfängerseite zu einem Datenüberlauf.
Fensterkonzept
Die Daten im Sendepuffer des Senders lassen sich in 4 Kategorien einteilen:
- 1. ACK gesendet und empfangen
- 2. Gesendete, aber nicht empfangene ACK
- 3. Nicht gesendet, aber senden erlaubt
- 4. Nicht gesendet, aber nicht zum Senden zugelassen
- Sowohl 2 als auch 3 gehören zum Sendefenster
Die zwischengespeicherten Daten des Empfängers werden in 3 Kategorien unterteilt:
- 1. Erhalten
- 2. Nicht empfangen, aber empfangsbereit
- 3. Nicht empfangen und nicht empfangsbereit
- 2 davon gehören zum Empfangsfenster
Die Fenstergröße stellt dar, wie viele Daten das Gerät gleichzeitig vom Peer verarbeiten und dann an die Anwendungsschicht weitergeben kann. Die zwischengespeicherten und an die Anwendungsschicht übergebenen Daten können nicht außer Betrieb sein, und der Fenstermechanismus garantiert dies.
Schiebemechanismus
- Das Sendefenster verschiebt die linke Grenze des Sendefensters nur, wenn die ACK-Bestätigung der Bytes im Sendefenster empfangen wird.
- Das Empfangsfenster bewegt sich nur dann zur linken Begrenzung, wenn alle vorhergehenden Segmente bestätigt sind. Wenn die vorherigen Bytes nicht empfangen werden, aber die folgenden Bytes empfangen werden, bewegt sich das Fenster nicht und bestätigt die nachfolgenden Bytes nicht, um sicherzustellen, dass das Peer-Ende die Daten erneut überträgt.
Tiefenanalyse
- Die TCP-Verbindung wird durch Datenpakete und ACKs implementiert. Als Dritte können wir den Prozess beider Parteien beim Senden von Paketen sehen, aber der Empfänger weiß nicht, was der Absender gesendet hat, bevor er es empfängt, und der Absender weiß nicht, was der Absender gesendet, bevor die ACK empfangen wird. Wissen, ob die andere Partei erfolgreich empfangen hat.
- Der Absender kann nicht nach rechts streichen, ohne die Bestätigung des Empfängers zu erhalten. Wenn der Sender ABCD sendet, kann es nicht gleiten, solange der Empfänger A nicht empfängt, so dass die beiden nicht asynchron sind.
- Die Größe des Fensters darf nicht größer als die Hälfte des Platzes für die Seriennummer sein, um zu verhindern, dass sich die beiden Fenster überlappen. Beispielsweise beträgt die Gesamtgröße 7 und die Größe jedes Fensters 4. Das Empfangsfenster sollte um 4 gleiten, aber es sind nur noch 3 Sequenznummern übrig.
- Der Absender sendet vier Daten ABCD, und der Empfänger rutscht nach rechts, nachdem er alle Daten empfangen hat, aber alle ACK-Antwortpakete gehen verloren, der Absender erhält keine ACK, und ABCD wird nach Zeitüberschreitung zu diesem Zeitpunkt erneut gesendet Empfänger drückt die kumulierte Bestätigung Im Prinzip wird nach dem Empfang von ABCD nur das ACK von D erneut gesendet, und der Absender rutscht direkt nach dem Empfang.
dynamische Präsentation
Zuerst sendet das sendende Ende vier ABCD-Pakete, aber AB geht verloren, und nur CD erreicht das empfangende Ende.
Das empfangende Ende empfängt kein A, also antwortet es nicht auf das ACK-Paket. Der Sender sendet ABCD erneut, und diesmal kommen alle an.
Das empfangende Ende erhält zuerst A, sendet das ACK-Paket von A, verliert es aber auf halbem Weg; nachdem es B erhalten hat, sendet es gemäß dem Prinzip der kumulativen Bestätigung das ACK-Paket von D, und dann verschiebt sich das Fenster des empfangenden Endes um 4 Bits. Nachdem Sie die CD erneut erhalten haben, antworten Sie nacheinander mit zwei ACK-Paketen von D.
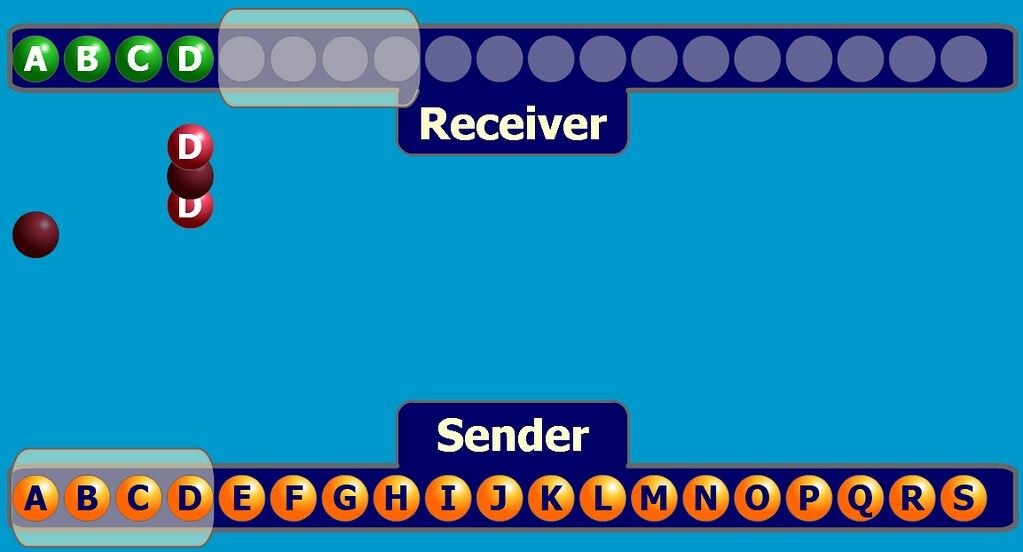
Das sendende Ende empfängt das ACK-Paket von D, was anzeigt, dass die andere Partei alle 4 Pakete empfangen hat, und das sendende Endefenster verschiebt sich um 4 Bits. Es werden EFGH-Pakete gesendet, wobei G-Pakete verloren gehen. Jetzt ist der Status der gesamten Sequenz: ABCD wurde gesendet, EFGH wurde gesendet, aber nicht bestätigt, und IS kann nicht gesendet werden.
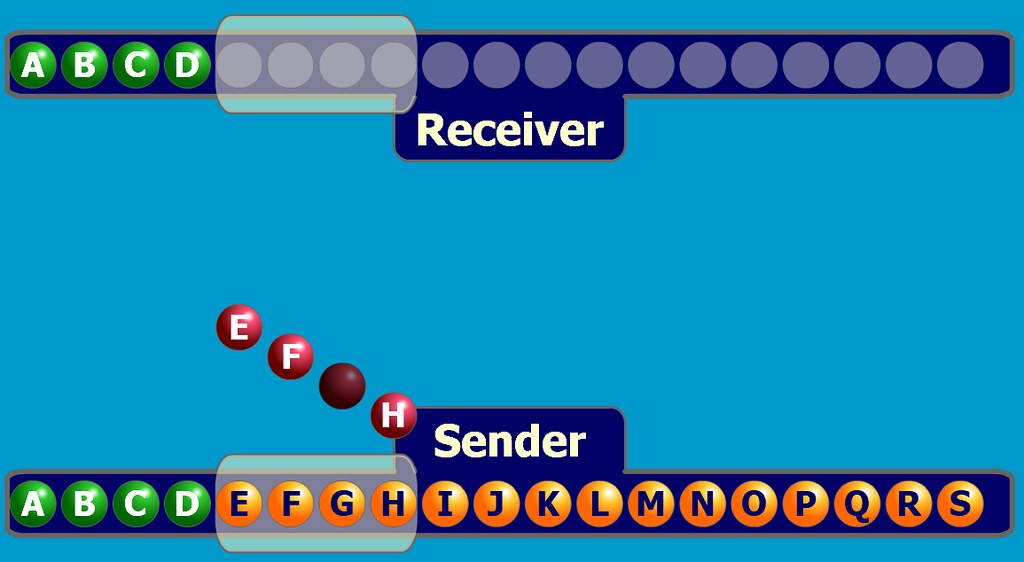
Das empfangende Ende empfängt zuerst E und sendet ein ACK-Paket von E. Dann F empfangen, F gesendet. Nach dem Prinzip der kumulativen Bestätigung: Wenn Sie kein G erhalten, senden Sie immer noch F; wenn Sie H erhalten, senden Sie immer noch F. Leider gehen die ACK-Pakete der drei Fs alle verloren.
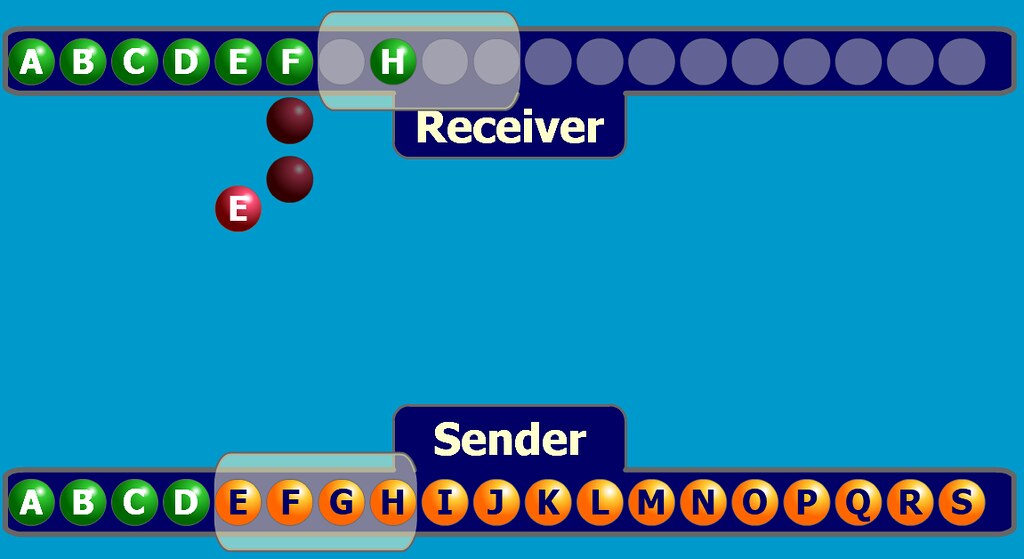
Der Sender empfängt das ACK-Paket von E, verschiebt das Sendefenster um ein Bit nach rechts und sendet dann FGHI, wobei F verloren geht.
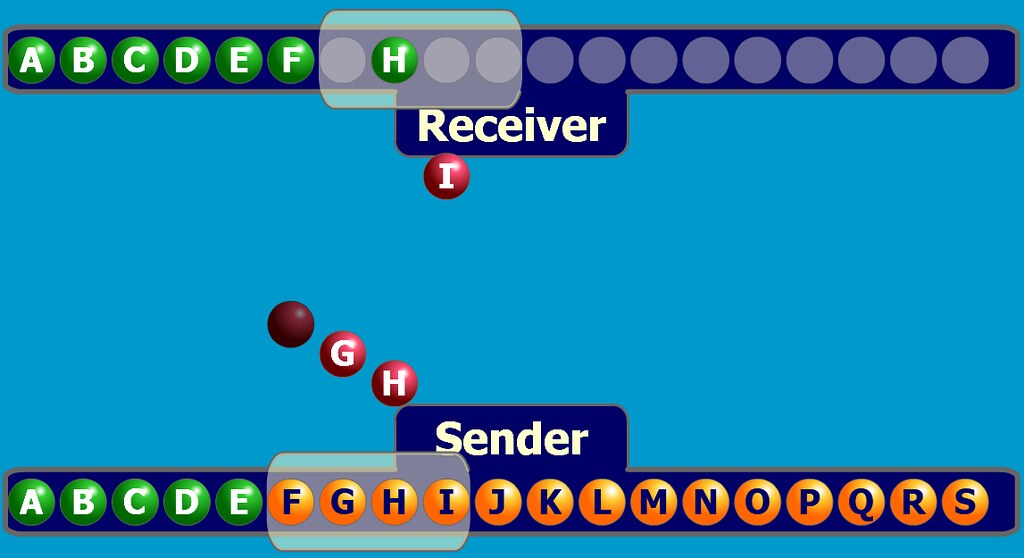
Das empfangende Ende erhält zuerst I, aber es gibt kein G, also muss es zuerst das ACK-Paket von F senden. Dann nacheinander GH-Pakete erhalten.
Gemäß der kumulativen Bestätigung sendet die Empfangsseite nacheinander zwei I-Pakete, von denen H dem Verlust entspricht. Das Empfangsfenster gleitet um 4 Bits nach rechts.

Der Sender erhält das ACK-Paket von I, schiebt 4 Bit nach rechts und analysiert es später nicht
Ausführliche Erläuterung der TCP-Überlastkontrolle
Einführung
Die Staukontrolle soll eine übermäßige Dateninjektion in das Netzwerk verhindern, damit die Router oder Verbindungen im Netzwerk nicht überlastet werden. Überlastkontrolle hat eine Prämisse: Das Netzwerk kann die vorhandene Netzwerklast tragen. Überlastungskontrolle ist ein globaler Prozess , der alle Hosts, Router und alle Faktoren einbezieht, die mit der Reduzierung der Netzwerkübertragungsleistung zusammenhängen.
Es gibt im Allgemeinen vier Methoden zu seiner Realisierung: Slow Start (Slow-Start), Congestion Avoidance (Congestion Avoidance), Fast Retransmit (Fast Retransmit) und Fast Recovery (Fast Recovery).
Der Sender behält eine Zustandsvariable des Überlastungsfensters cwnd bei. Die Größe des Überlastungsfensters hängt vom Grad der Netzwerküberlastung ab und ändert sich dynamisch. Der Sender macht die Größe seines Sendefensters gleich der Größe des Überlastungsfensters. Das Prinzip für den Sender, das Überlastungsfenster zu kontrollieren, lautet: Solange es keine Überlastung im Netzwerk gibt, wird das Überlastungsfenster vergrößert, um mehr Pakete zu senden; wenn das entsprechende Netzwerk überlastet ist, wird das Überlastungsfenster kleiner, um die Injektion zu reduzieren in das Netzwerk Anzahl der Gruppen.
Langsamer Start: cwnd exponentiell wachsen
-
Wenn der Host mit dem Senden von Daten beginnt und sofort eine große Anzahl von Datenbytes in das Netzwerk eingespeist wird, kann dies zu einer Netzwerküberlastung führen, da nicht klar ist, wie belastet das Netzwerk ist. Daher ist es am besten, zuerst ein kleines Datenelement zu senden und es zuerst zu erkennen und das Sendefenster schrittweise von klein auf groß zu vergrößern. Setzen Sie normalerweise zu Beginn des Sendens eines Nachrichtensegments zuerst das Überlastungsfenster cwnd auf einen Wert von MSS (maximal). Erhöhen Sie nach einer Bestätigung für ein neues Segment das Überlastungsfenster um höchstens einen MSS-Wert. Die Verwendung dieser Methode zum schrittweisen Erhöhen des Überlastungsfensters cwnd des Absenders kann die Rate, mit der Pakete in das Netzwerk eingespeist werden, vernünftiger machen.
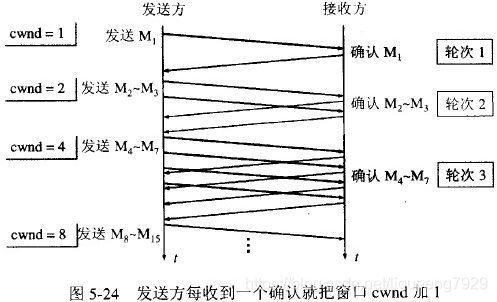
Jedes Mal, wenn eine Runde passiert, wird die cwnd des Staufensters verdoppelt. Die in einer Übertragungsrunde verstrichene Zeit ist die Umlaufzeit RTT . Die Übertragungsrunde betont jedoch: Die vom Überlastungsfenster cwnd zugelassenen Nachrichtensegmente werden kontinuierlich gesendet, und die Bestätigung des letzten gesendeten Bytes wurde empfangen.
Der langsame Start bedeutet nicht, dass die Wachstumsrate von cwnd langsam ist, sondern dass cwnd = 1 ist, wenn TCP mit dem Senden von Segmenten beginnt , sodass der Sender zu Beginn nur ein Segment sendet (der Zweck besteht darin, die Überlastung des Netzwerks zu testen). und dann Erhöhen Sie dann allmählich cwnd.
Um eine durch übermäßiges Wachstum von cwnd verursachte Netzwerküberlastung zu verhindern, ist es außerdem erforderlich, eine Zustandsvariable ssthresh für einen langsamen Startschwellenwert festzulegen.
- Wenn cwnd < ssthresh, wird der oben beschriebene langsame Startalgorithmus verwendet.
- Wenn cwnd > ssthresh, beenden Sie die Verwendung des langsamen Startalgorithmus und verwenden Sie stattdessen den Überlastungsvermeidungsalgorithmus.
- Wenn cwnd = ssthresh, kann entweder der langsame Startalgorithmus oder der Stauvermeidungsalgorithmus verwendet werden.
Stauvermeidungsalgorithmus: Exponential zu Linear
- Lassen Sie das Überlastungsfenster langsam wachsen, d. h. erhöhen Sie das Überlastungsfenster cwnd des Senders jedes Mal um 1, wenn eine Roundtrip-Zeit RTT vergeht, anstatt es zu verdoppeln, sodass das Überlastungsfenster cwnd linear und langsam wächst, was langsamer als das exponentielle Wachstum ist Rate des langsamen Starts viele.
- Unabhängig davon, ob es sich in der langsamen Startphase oder der Überlastungsvermeidungsphase befindet, solange der Sender beurteilt, dass das Netzwerk überlastet ist (die Grundlage ist, dass der Sender keine Bestätigung erhalten hat), muss der langsame Startschwellenwert ssthresh eingestellt werden die Hälfte des Senderfensterwerts, wenn eine Überlastung auftritt (aber nicht weniger als 2). Setzen Sie dann das Überlastungsfenster cwnd auf 1 zurück und führen Sie den langsamen Startalgorithmus aus. Dadurch soll die Anzahl der vom Host an das Netzwerk gesendeten Pakete schnell reduziert werden, damit der überlastete Router genügend Zeit hat, den Rückstand an Paketen in der Warteschlange zu verarbeiten.
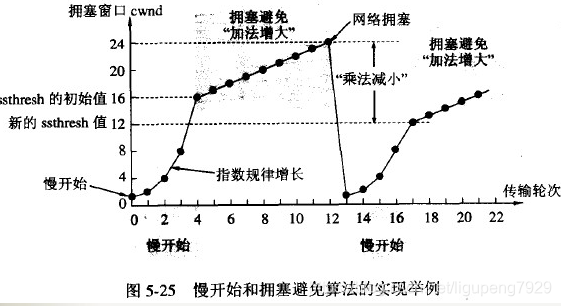
schnelle Weiterleitung
-
Wenn der vom Absender eingestellte Timeout-Timer abgelaufen ist, aber keine Bestätigung empfangen wurde, ist das Netzwerk wahrscheinlich überlastet, was dazu führt, dass das Segment irgendwo im Netzwerk gelöscht wird. Zu diesem Zeitpunkt reduziert TCP sofort das Überlastungsfenster cwnd auf 1 und führt den Slow-Start-Algorithmus aus und halbiert gleichzeitig den Slow-Start-Schwellenwert ssthresh. Dies ist ohne schnelle Neuübertragung der Fall.
-
Der Fast-Retransmission-Algorithmus erfordert zunächst, dass der Empfänger jedes Mal, wenn er eine Out-of-Sequence-Nachricht empfängt, sofort eine wiederholte Bestätigung sendet (um den Absender frühzeitig zu informieren, dass ein Nachrichtensegment die andere Partei nicht erreicht hat), anstatt darauf zu warten die zu versendenden Daten selbst und trägt dann die Bestätigung. Sobald der Sender drei doppelte Bestätigungen nacheinander erhält, sollte er das vorherige Nachrichtensegment, das die andere Partei nicht erhalten hat, sofort erneut übertragen, anstatt darauf zu warten, dass der durch das Nachrichtensegment festgelegte Zeitgeber für die erneute Übertragung abläuft.
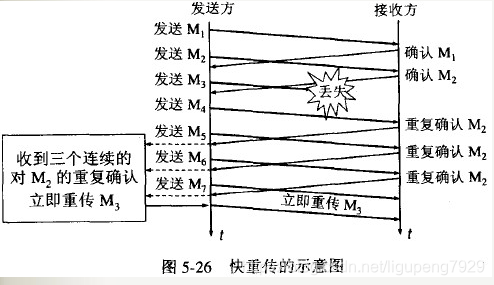
Nach dem Empfang von M1 und M2 hat die empfangende Partei jeweils Bestätigungen gesendet.Nehmen Sie nun an, dass die empfangende Partei M3 nicht empfangen hat, aber dann M4 empfangen hat. Offensichtlich kann der Empfänger M4 nicht bestätigen. M4 ist ein Nachrichtensegment außerhalb der Reihenfolge. Gemäß dem Prinzip der zuverlässigen Übertragung kann der Empfänger nichts tun oder zu einem geeigneten Zeitpunkt eine Bestätigung von M2 senden. Aber der Fast-Retransmission-Algorithmus schreibt vor: **Der Empfänger sollte rechtzeitig eine wiederholte Bestätigung von M2 senden, damit der Sender wissen kann, dass das von ihm gesendete M3 den Empfänger nicht erreicht hat. **Da der Sender unbestätigte Segmente so früh wie möglich erneut überträgt, kann der Durchsatz des gesamten Netzwerks um etwa 20 % erhöht werden, nachdem die schnelle Neuübertragung angenommen wurde.
schnelle Erholung
-
In Verbindung mit der schnellen Neuübertragung gibt es auch einen schnellen Wiederherstellungsalgorithmus, dessen Hauptprozess ist:
- Wenn der Sender drei wiederholte Bestätigungen hintereinander empfängt, führt er den Algorithmus der Multiplikationsreduktion aus, um den Slow-Start-Schwellenwert ssthresh zu halbieren. Damit soll eine Netzwerküberlastung verhindert werden.
- Da der Absender jetzt denkt, dass das Netzwerk wahrscheinlich nicht überlastet ist, besteht der Unterschied zum langsamen Start darin, dass der langsame Startalgorithmus jetzt nicht ausgeführt wird (cwnd nicht auf 1 gesetzt wird), sondern cwnd auf den gleichen Wert wie der aktuelle langsame Start gesetzt wird Schwelle ssthresh, Und führe den Stauvermeidungsalgorithmus aus (additive Erhöhung), so dass das Staufenster langsam und linear zunimmt.
-
Einige schnelle Wiederherstellungsimplementierungen erhöhen den Wert des Überlastungsfensters cwnd am Anfang, was gleich ssthresh + 3 x MSS ist. Der Grund dafür ist, dass, da der Absender drei doppelte Bestätigungen erhalten hat, er anzeigt, dass drei Pakete das Netzwerk verlassen haben. Diese drei Pakete verbrauchen keine Netzwerkressourcen mehr, sondern verbleiben im Puffer des Empfängers.Es ist ersichtlich, dass das Netzwerk keine Pakete ansammelt, sondern drei Paketereduziert. Daher kann das Überlastungsfenster entsprechend erweitert werden.
-
Bei Verwendung des schnellen Wiederherstellungsalgorithmus wird der langsame Startalgorithmus nur verwendet, wenn die TCP-Verbindung hergestellt ist und das Netzwerk abläuft. Durch die Übernahme eines solchen Überlastungskontrollverfahrens wird die Leistung von TCP erheblich verbessert.
-
Der Empfänger setzt das Empfangsfenster rwnd gemäß seiner eigenen Empfangsfähigkeit und schreibt den Fensterwert in das Fensterfeld im TCP-Header und sendet ihn an den Sender. Daher wird das Empfangsfenster auch als Benachrichtigungsfenster bezeichnet. Daher darf aus Sicht der Flusskontrolle des Empfängers über den Sender das Sendefenster des Senders das von der anderen Partei angegebene Empfangsfenster rwnd nicht überschreiten.
- Obergrenze des Senderfensters = Min [ rwnd, cwnd ]
- Wenn rwnd < cwnd, begrenzt die Empfangsfähigkeit des Empfängers den maximalen Wert des Fensters des Senders.
- Wenn cwnd < rwnd, ist dies der Maximalwert des durch Überlastung begrenzten Senderfensters des Netzwerks.
Problem beim Entpacken von TCP Sticky Packets
Herkunft
TCP ist ein Bytestrom-orientiertes Protokoll, das eine Datenfolge ohne Grenzen ist. Die untere Schicht von TCP versteht die spezifische Bedeutung der Geschäftsdaten der oberen Schicht nicht, sie teilt die Pakete entsprechend der tatsächlichen Situation des TCP-Puffers auf, sodass ein vollständiges Paket in geschäftlicher Hinsicht durch TCP in mehrere Pakete aufgeteilt werden kann Es ist möglich, mehrere kleine Pakete in ein großes Datenpaket zu kapseln und zu senden.Dies ist das Problem des TCP-Entpackens und Anheftens von Paketen.
Szene
Unter der Annahme, dass der Client jeweils zwei Datenpakete D1 und D2 an den Server sendet, da die Anzahl der vom Server gleichzeitig gelesenen Bytes ungewiss ist, können die folgenden fünf Situationen auftreten:
- Der Server liest zweimal zwei unabhängige Datenpakete, nämlich D1 und D2, und es gibt kein Hängenbleiben oder Entpacken.
- Der Server empfängt jeweils zwei Datenpakete, und D1 und D2 werden zusammengehalten, was als TCP Sticky Packet bezeichnet wird.
- Der Server liest zwei Datenpakete zweimal, das erste Mal liest er das vollständige D1-Paket und einen Teil von D2, und das zweite Mal liest er den restlichen Inhalt des D2-Pakets, was als TCP-Entpacken bezeichnet wird.
- Der Server liest zwei Datenpakete zweimal, das erste Mal liest er einen Teil des Inhalts des D1-Pakets und das zweite Mal liest er den restlichen Inhalt des D1-Pakets und den gesamten Inhalt des D2-Pakets.
- Wenn das TCP-Empfangsfenster des Servers sehr klein ist, kann der Server die D1- und D2-Pakete mehrmals empfangen, und es kann zu mehrfachem Entpacken kommen.
Ursache für
- Die zu sendenden Daten sind kleiner als die Größe des TCP-Sendepuffers, und TCP sendet die Daten, die mehrmals gleichzeitig in den Puffer geschrieben wurden, und Sticky-Pakete treten auf.
- Wenn die zu sendenden Daten größer sind als der verbleibende Platz des TCP-Sendepuffers, wird entpackt.
- Wenn die zu sendenden Daten größer als MSS (maximale Nachrichtengröße) sind, entpackt TCP sie vor der Übertragung. Die Länge des TCP-Pakets muss garantiert sein - die Länge des TCP-Headers > MSS
Klebrige Verpackung und Auspacklösung
Da TCP die Geschäftsdaten der oberen Schicht nicht verstehen kann, kann die Lösung nur aus dem Anwendungsprotokollstapel der oberen Schicht gelöst werden.Entsprechend der Lösung des Mainstream-Protokolls in der Industrie:
- Nachricht mit fester Länge : Der Sender kapselt jedes Datenpaket in eine feste Länge (nicht genug, um durch 0 ergänzt zu werden), so dass der Empfänger jedes Mal, wenn er Daten einer festen Länge im Empfangspuffer liest, jedes Datenpaket natürlich aufteilt.
- Legen Sie die Nachrichtengrenze fest : Der Server trennt den Nachrichteninhalt vom Netzwerkstrom gemäß der Nachrichtengrenze und fügt am Ende des Pakets ein Wagenrücklauf- und Zeilenvorschubzeichen zur Segmentierung hinzu, wie z. B. beim FTP-Protokoll.
- Unterteilen Sie die Nachricht in einen Nachrichtenkopf und einen Nachrichtentext : Der Nachrichtenkopf enthält die Gesamtlängeninformationen der Nachricht. Beim Senden jedes Datenstücks wird die Länge der Daten zusammen gesendet. Zum Beispiel die ersten 4 Bits der Daten als die Länge der Daten spezifiziert sind und die Anwendungsschicht verarbeitet wird. Zu diesem Zeitpunkt können die Start- und Endpositionen jedes Pakets gemäß der Länge beurteilt werden.
Hat UDP das Problem von Sticky Packets?
Um eine zuverlässige Übertragung zu gewährleisten und zusätzlichen Overhead zu reduzieren (bei jedem Senden eines Pakets ist eine Überprüfung erforderlich), verwendet TCP eine bytestrombasierte Übertragung.Die strombasierte Übertragung betrachtet eine Nachricht nicht als ein Stück, sondern als ungeschützte Nachrichtengrenze ( geschützte Nachrichtengrenze : Bezieht sich auf das Übertragungsprotokoll, das Daten als unabhängige Nachricht im Internet überträgt und das empfangende Ende nur eine unabhängige Nachricht gleichzeitig akzeptieren kann).
UDP ist nachrichtenorientiert und hat eine Schutzgrenze.Der Empfänger akzeptiert nur eine unabhängige Nachricht auf einmal, und es gibt keinProblem mit Sticky Packets.
IP-Protokoll
Das IP-Protokoll (Internet Protocol, Internet Protocol) ist ein Netzwerkschichtprotokoll in TCP/IP. Der Zweck der Emergenz besteht darin, die Skalierbarkeit des Netzwerks zu verbessern und die Verbindung und Kommunikation von großen und heterogenen Netzwerken zu realisieren. Gemäß dem Ende-zu-Ende-Designprinzip stellt IP nur einen verbindungslosen, unzuverlässigen Best-Effort-Datenpaketübertragungsdienst für den Host bereit.
Weiterleitungsregeln für IP-Pakete: Wenn ein IP-Paket von einem Router weitergeleitet wird und das Zielnetzwerk direkt mit dem lokalen Router verbunden ist, wird das Paket direkt an den Zielhost zugestellt, was als direkte Zustellung bezeichnet wird; andernfalls sucht der Router nach die Routing-Informationen durch die Routing-Tabelle und sendet das Paket an den angegebenen Next-Hop-Router, was als indirekte Zustellung bezeichnet wird. Bei indirekter Zustellung sendet der Router, wenn in der Routing-Tabelle eine Route zum Zielnetzwerk vorhanden ist, das Datenpaket an den in der Routing-Tabelle angegebenen Next-Hop-Router; wenn keine Route vorhanden ist, aber eine Standardroute in der Routing-Tabelle wird das Datenpaket an den angegebenen Standard-Router gesendet; wenn keiner vorhanden ist, wird das Paket verworfen und ein Fehler gemeldet.
Fünf Arten von IP-Adressen
Geben Sie eine Adresse ein: Das erste Byte beginnt mit 0, die restlichen 7 Bits sind die Netzwerkadresse und die letzten 3 Bytes sind die Hostadresse. Die Startadresse ist 1-126 und der Bereich ist 1.0.0.1-126.225.255.254 Klasse A ist für Regierungsbehörden reserviert.
- 10.0.0.0 bis 10.255.255.255 sind private Adressen (im Internet nicht verwendet, im lokalen Netzwerk verwendete Adressen)
- 127.XXX ist eine reservierte Adresse für Schleifentests
Adresse der Klasse B: Das erste Byte beginnt mit 10, die ersten 2 Bytes sind die Netzwerkadresse und die letzten 2 Bytes sind die Hostadresse. Die Startadresse ist 128-191, der Bereich ist 128.0.0.1 – 191.255.255.254 Klasse B wird mittelständischen Unternehmen zugeteilt.
- 172.16.0.0—172.31.255.255 ist eine private Adresse
- 169.254.XX ist eine reservierte Adresse. Wenn Ihre IP-Adresse automatisch bezogen wird, Sie aber keinen verfügbaren DHCP-Server im Netzwerk gefunden haben. Eine der IPs wird abgerufen.
- 191.255.255.255 ist die Broadcast-Adresse und wird nicht zur Zuordnung verwendet.
Klasse-C-Adresse: Das 1. Byte, 2. Byte und 3. Byte einer Klasse-C-Adresse sind die Netzwerkadresse und das 4. Byte ist die Hostadresse. Außerdem sind die ersten drei Ziffern des ersten Bytes auf 110 festgelegt. Adressbereich der Klasse C: 192.0.0.1–223.255.255.254 . 192.168.XX in Klasse-C-Adressen ist eine private Adresse. Adressen der Klasse C sind für den persönlichen Gebrauch bestimmt.
Adresse der Klasse D: Die Adresse der Klasse D unterscheidet nicht zwischen Netzwerkadresse und Hostadresse, und die ersten vier Ziffern ihres ersten Bytes sind auf 1110 festgelegt. Adressbereich der Klasse D: 224.0.0.1—239.255.255.254 . Wird im Allgemeinen für Multicast verwendet.
Adresse der Klasse E: Sie unterscheidet nicht zwischen Netzwerkadresse und Hostadresse, und die ersten fünf Ziffern ihres ersten Bytes sind auf 11110 festgelegt. Adressbereich der Klasse E: 240.0.0.1—255.255.255.254 . Wird im Allgemeinen für Experimente verwendet.
Computer, der IP-Parameter einstellt
IP-Adresse: 192.168.1.2-254 ist akzeptabel
Subnetzmaske: 255.255.255.0
- Es wird verwendet, um einen Teil der IP-Adresse abzuschirmen, um zwischen der Netzwerkkennung und dem Host zu unterscheiden, und um anzuzeigen, ob sich die IP-Adresse in einem lokalen Netzwerk oder einem entfernten Netzwerk befindet; es wird verwendet, um ein großes IP-Netzwerk in mehrere zu unterteilen kleine Subnetze.
- Die Verwendung von Subnetzen dient dazu, die Verschwendung von IP zu reduzieren. Mit der Entwicklung des Internets werden immer mehr Netzwerke generiert. Einige Netzwerke haben Hunderte von Netzwerken und nur wenige. Dadurch wird viel verschwendet IP-Adressen, daher ist es notwendig, Subnetze zu teilen, die Verwendung von Subnetzen kann die Effizienz von Netzwerkanwendungen verbessern.
Standard-Gateway: 192.168.1.1
- Das Standard-Gateway ist ein Gerät, das das Subnetz mit dem externen Netzwerk verbindet, normalerweise ein Router.Wenn ein Computer Informationen sendet, bestimmt er anhand der Subnetzmaske anhand der Zieladresse der gesendeten Informationen, ob sich der Zielhost im lokalen Subnetz befindet. Befindet sich der Zielhost im lokalen Subnetz, kann direkt versendet werden. Wenn sich das Ziel nicht im lokalen Subnetz befindet, werden die Informationen an das Standard-Gateway/den Standardrouter gesendet, und der Router leitet sie an andere Netzwerke weiter, um weiter nach dem Zielhost zu suchen.
DNS oder regionales gemeinsames DNS
ARP-Protokoll
**ARP steht für Address Resolution Protocol. Im Ethernet-Umfeld hängt die Datenübertragung eher von der MAC-Adresse als von der IP-Adresse ab, und die Umwandlung der bekannten IP-Adresse in die MAC-Adresse wird durch das ARP-Protokoll erledigt. **Im LAN wird tatsächlich ein Frame im Netzwerk übertragen, und der Frame enthält die MAC-Adresse des Zielhosts. Im Ethernet kommuniziert ein Host direkt mit einem anderen Host und muss die MAC-Adresse des Zielhosts kennen.
Jedes Mal, wenn ein Host ein IP-Datagramm an einen anderen Host senden muss, muss er die logische (IP-)Adresse des Empfängers kennen. Die IP-Adresse muss jedoch in einen Frame eingekapselt werden, um das physische Netzwerk zu passieren . Das bedeutet, dass der Absender die physische Adresse (MAC) des Empfängers haben muss, sodass eine Zuordnung von logisch zu physischer Adresse erfolgen muss. Das ARP-Protokoll kann die logische Adresse vom IP-Protokoll akzeptieren, sie der entsprechenden physikalischen Adresse zuordnen und dann die physikalische Adresse an die Datenverbindungsschicht übermitteln.
ARP-Mapping-Methode
statische Zuordnung
Erstellen Sie manuell eine ARP-Tabelle, die logische (IP-)Adressen physischen Adressen zuordnet. Diese ARP-Tabelle wird auf jeder Maschine im Netzwerk gespeichert. Beispielsweise kann eine Maschine, die die IP-Adresse ihrer Maschine kennt, aber ihre physikalische Adresse nicht kennt, die entsprechende physikalische Adresse durch Nachschlagen in der ARP-Tabelle herausfinden.
Dabei gibt es bestimmte Einschränkungen:
- Der Computer hat möglicherweise NICs (Netzwerkadapter) geändert, was zu einer neuen physischen Adresse führt.
- In einigen lokalen Netzwerken ändert sich die physische Adresse jedes Mal, wenn der Computer eingeschaltet wird, einmal.
- Mobile Computer können von einem physischen Netzwerk in ein anderes verschoben werden, was zu einer Änderung der physischen Adresse führt.
Um diese Situationen zu vermeiden, muss die ARP-Tabelle regelmäßig gewartet und aktualisiert werden, was sehr mühsam ist und die Netzwerkleistung beeinträchtigt.
dynamische Zuordnung
Jedes Mal, wenn eine Maschine die logische (IP-)Adresse einer anderen Maschine kennt, kann sie das Protokoll verwenden, um die entsprechende physische Adresse herauszufinden. ARP implementiert die Abbildung von logischen Adressen auf physische Adressen und RARP implementiert die Abbildung von physischen Adressen auf logische Adressen.
ARP-Prozess
ARP-Anfrage: Wenn ein Host die physische Adresse eines anderen Hosts im Netzwerk herausfinden muss, kann er eine ARP-Anfragenachricht senden, die die MAC-Adresse und IP-Adresse des Absenders und die IP-Adresse des Empfängers packt. Da der Sender die Empfangsadresse des Empfängers nicht kennt, wird diese Anfrage in der Vermittlungsschicht rundgesendet.
ARP-Antwort: Jeder Host im LAN akzeptiert und verarbeitet die ARP-Anforderungsnachricht und überprüft dann, ob die IP-Adresse des Empfängers seine eigene Adresse ist. Nur der Host, der erfolgreich verifiziert wurde, sendet eine ARP-Antwortnachricht zurück. Diese Antwortnachricht enthält die IP-Adresse und die physische Adresse des Empfängers. Diese Nachricht wird unter Verwendung der physikalischen Adresse des Anforderers in der empfangenen ARP-Anforderungsnachricht auf Unicast-Weise direkt an den Anforderer der ARP-Anforderungsnachricht gesendet.
Erweiterung: Cookie und Sitzung
Cookie: Eine kleine Textinformation Der Server kann die Identität des Clients nicht allein aus der Netzwerkverbindung erkennen, also gibt der Server einen Pass an den Client aus. Bei jedem Besuch müssen Sie Ihren eigenen Pass mitbringen, damit der Server die Identität des Kunden anhand des Passes bestätigen kann. Der Server kann auch den Inhalt des Cookies nach Bedarf ändern.
Session: Session ist ein Mechanismus, mit dem der Server den Status des Clients aufzeichnet, der einfacher zu verwenden ist als Cookies und den Speicherdruck auf dem Server entsprechend erhöht. Es wird automatisch erstellt, wenn der Benutzer zum ersten Mal auf den Server zugreift (statische Ressourcen wie der reine Zugriff auf HTML und IMAGE werden nicht generiert. Wenn es nicht generiert wird, können Sie die Generierung mit request.getSession(true) erzwingen Nachdem die Sitzung generiert wurde, aktualisiert der Server die letzte Zugriffszeit der Sitzung und hält die Sitzung aufrecht, solange der Benutzer sie weiterhin besucht. Die Sitzung wird standardmäßig zerstört, wenn sie 30 Minuten lang nicht verwendet wird, und die Zeit kann durch setMaxInactiveInterval festgelegt werden.
Warum sollte es eine Sitzung geben?
Da das HTTP-Protokoll zustandslos ist, sendet der Client eine Anfrage an den Server, und der Server gibt dann eine entsprechende Antwort zurück, und dann wird die Verbindung geschlossen, und es besteht keine Beziehung zwischen den beiden, dh der Server speichert nicht diesmal Für die angeforderten relevanten Informationen kann der Server nicht wissen, ob diese Anfrage und die letzte Anfrage derselbe Client sind, wenn die Anfrage erneut gestellt wird. Daher müssen wir die Sitzungssitzung verwenden, um die Informationen dieser Verbindung aufzuzeichnen.
Wenn ein Client auf den Server zugreift, kann er kontinuierlich zwischen mehreren Seiten des Servers aktualisieren, sich wiederholt mit derselben Seite verbinden oder Informationen an eine Seite senden.Mit dem Sitzungsdatensatz kann der Server wissen, dass dies derselbe Client auf dem Server ist Führen Sie diese Aktionen aus.
Der Unterschied zwischen Cookie und Session
- Der Speicherort ist anders:
- Die Dateninformationen des Cookies werden im Client-Browser gespeichert, und es ist für andere nicht sicher, das lokale Cookie zu analysieren und das Cookie zu betrügen.
- Die Dateninformationen der Sitzung werden auf dem Server gespeichert, der für den Client unsichtbar ist, und es besteht kein Risiko, dass vertrauliche Informationen verloren gehen.
- Der Lebenszyklus ist anders:
- Der Lebenszyklus einer Sitzung besteht darin, dass der Browser geschlossen wird und die Sitzung verschwindet, sobald sie geschlossen wird.
- Das Cookie ist ein voreingestellter Lebenszyklus oder wird dauerhaft in der lokalen Datei gespeichert.
- Speicherkapazität variiert:
- Die von einem einzelnen Cookie gespeicherten Daten <= 4 KB, und eine Website kann bis zu 20 Cookies speichern
- Es gibt keine Obergrenze für die Sitzung, aber speichern Sie aus Gründen der serverseitigen Leistung nicht zu viele Dinge in der Sitzung und stellen Sie den Mechanismus zum Löschen der Sitzung ein
- Anders gelagert:
- In Cookies können nur ASCII-Zeichenfolgen gespeichert werden, die als Unicode-Zeichen oder Binärdaten codiert werden müssen
- Jede Art von Daten kann in der Sitzung gespeichert werden, einschließlich, aber nicht beschränkt auf String, Integer, List, Map usw.
- Die Gültigkeitsdauer ist unterschiedlich:
- Die Eigenschaften des Cookies können über den Code eingestellt werden, um den Effekt zu erzielen, dass das Cookie lange wirksam bleibt.
- Die Sitzung basiert auf dem Cookie von JSESSIONID, und die Ablaufzeit des Cookies JSESSIONID ist standardmäßig -1. Solange das Fenster geschlossen ist, ist die Sitzung ungültig, sodass die Sitzung keine langfristig wirksamen Ergebnisse erzielen kann.
- Serverdruck ist anders:
-
Cookies werden clientseitig gespeichert und belegen keine Serverressourcen.Für Websites mit vielen gleichzeitigen Benutzern sind Cookies eine gute Wahl.
-
Die Sitzung wird serverseitig gespeichert und jeder Benutzer generiert eine Sitzung. Wenn viele Benutzer gleichzeitig zugreifen, werden viele Sitzungen generiert und viel Speicher verbraucht.
-
Idempotenz
**Idempotenz: Dies bedeutet, dass die Ergebnisse einer Anfrage oder mehrerer Anfragen, die vom Benutzer für denselben Vorgang initiiert wurden, konsistent sind und es keine Nebenwirkungen aufgrund mehrerer Klicks gibt. **Achten Sie bei den vier Vorgängen Hinzufügen, Löschen, Ändern und Prüfen besonders auf Hinzufügen oder Ändern . Das Ergebnis der Abfrage ändert sich nicht, und die Löschung wird nur einmal durchgeführt. Das Ergebnis mehrerer Klicks durch den Benutzer ist das gleiche, und das Ergebnis der Änderung in den meisten Szenarien das gleiche ist, wird die Erhöhung im Szenario der wiederholten Einreichung erscheinen. Für gängige HTTP-Anforderungsmethoden sind GET, PUT und DELETE alle idempotent, während POST dies nicht ist.
Verstehen: Workflow des TCP/IP-Protokolls
- Auf dem Quellhost sendet die Anwendungsschicht einen Strom von Anwendungsdaten an die Transportschicht.
- In der Transportschicht wird der Datenfluss der Anwendungsschicht in Pakete geschnitten und mit einem TCP-Header zu einem TCP-Segment ergänzt, das an die Vermittlungsschicht gesendet wird.
- Fügen Sie dem TCP-Segment auf der Vermittlungsschicht einen IP-Header mit Quell- und Ziel-Host-IP-Adressen hinzu, generieren Sie ein IP-Datenpaket und senden Sie das IP-Datenpaket an die Vermittlungsschicht.
- Die Verbindungsschicht lädt das IP-Datenpaket in den Datenteil ihres MAC-Frames, fügt die MAC-Adresse und den Frame-Header des Quell- und des Zielhosts hinzu und sendet den MAC-Frame entsprechend der Ziel-MAC-Adresse an den Zielhost oder IP-Router.
- Auf dem Zielhost entfernt die Sicherungsschicht den Rahmenkopf des MAC-Rahmens und sendet das IP-Datenpaket an die Vermittlungsschicht.
- Die Vermittlungsschicht prüft den IP-Header, und wenn die Prüfsumme im Header nicht mit dem Berechnungsergebnis übereinstimmt, wird das IP-Datenpaket verworfen; wenn das Ergebnis der Prüfsummenberechnung konsistent ist, wird der IP-Header entfernt und das TCP-Segment an gesendet die Transportschicht.
- Die Transportschicht überprüft die Sequenznummer, um festzustellen, ob es sich um ein korrektes TCP-Paket handelt, und überprüft dann die TCP-Header-Daten. Wenn es richtig ist, sendet es eine Bestätigungsnachricht an den Quellhost; wenn es falsch ist oder das Paket verloren geht, wird es den Quellhost bitten, die Informationen erneut zu senden.
- Am Zielhost entfernt die Transportschicht den TCP-Header und sendet die sequenzierten Pakete zur Bildung des Anwendungsdatenstroms an das Anwendungsprogramm. Auf diese Weise ist der vom Zielhost vom Quellhost empfangene Bytestrom genauso wie der direkte Empfang des Bytestroms vom Quellhost.