1. Logische Speicherstruktur:


Tabellenbereich (IBD-Datei): Eine MySQL-Instanz kann mehreren Tabellenbereichen zum Speichern von Datensätzen, Indizes und anderen Daten entsprechen.
Segment: unterteilt in Datensegment, Indexsegment, Rollback-Segment,
InnoDB ist eine Indexorganisationstabelle, das Datensegment ist der Blattknoten des B+-Baums, das Indexsegment ist der Nicht-Blattknoten des B+-Baums und das Segment wird verwendet, um mehrere (Extent-)Bereiche zu verwalten
Bereich: Die Einheitsstruktur im Tabellenbereich Die Größe jedes Bereichs beträgt 1 M. Standardmäßig beträgt die Seitengröße der InnoDB-Speicher-Engine 16 KB, d. h. es gibt 64 aufeinanderfolgende Seiten in einem Bereich.
Seite: Dies ist die kleinste Einheit der Festplattenverwaltung der InnoDB-Speicher-Engine. Jede Seite ist 16 KB groß. Um die Kontinuität der Seite zu gewährleisten, wendet die InnoDB-Speicher-Engine jedes Mal 4–5 Bereiche der Festplatte an.
Zeile: Die InnoDB-Speicher-Engine wird zeilenweise gespeichert
Trx_id: Jedes Mal, wenn ein Datensatz geändert wird, wird die ID der entsprechenden Transaktion der verborgenen Spalte trx_id zugewiesen, die die ID der letzten Vorgangstransaktion ist
Roll_pointer: Jedes Mal, wenn ein Datensatz geändert wird, wird die alte Version in das Undo-Log geschrieben, und diese versteckte Spalte ist dann gleichbedeutend mit einem Zeiger, durch den die Informationen vor der Änderung des Datensatzes gefunden werden können
2. InnoDB-Architektur

2.1 Speicherstruktur
2.1.1 BufferPool: Pufferpool
Der Buffer Pool ist ein Bereich im Speicher, der die häufig auf der Platte betriebenen realen Daten zwischenspeichern kann. Bei Ergänzungen, Löschungen, Änderungen und Abfragen werden zuerst die Daten im Buffer Pool bearbeitet (falls nicht vorhanden). Daten im Puffer zu diesem Zeitpunkt, werden sie von der Festplatte und dem Cache geladen) und dann mit einer bestimmten Häufigkeit oder Regel auf die Festplatte aktualisiert, um die Anzahl der Festplatten-E/A zu reduzieren und die Verarbeitung zu beschleunigen.
Wenn kein Puffer vorhanden ist, wird jeder Hinzufügungs-, Lösch-, Änderungs- und Abfragevorgang auf Festplattenspeicher ausgeführt, und es gibt eine große Anzahl von Festplatten-IOs.Im Geschäft ist Festplatten-IO zufällige IO, was sehr zeitaufwändig und sehr zeitintensiv ist leistungsintensiv, daher ist es notwendig, die Festplatten-IO so weit wie möglich zu reduzieren.
Die Verarbeitungseinheit des Pufferpools ist eine Seite, und die unterste Schicht verwendet eine verknüpfte Listendatenstruktur, um die Seite zu verwalten. Je nach Status wird die Seite in drei Typen unterteilt:
- freie Seite: freie Seite, nicht verwendet
- saubere Seite: benutzte Seite, die Daten wurden nicht verändert
- Schmutzige Seite: Schmutzige Seite, verwendete Seite, Daten wurden geändert und die Daten stimmen nicht mit den Daten auf der Festplatte überein
2.2.2 Puffer ändern: Ändern Sie den Puffer
Wenn beim Ausführen einer DML-Anweisung die Datenseiten nicht im Buffer Pool sind, wird die Platte nicht direkt bedient, sondern die aktuellen Datenänderungen werden im Change Buffer (Änderungspuffer) gespeichert, und wenn die Daten gelesen werden in der future , und führen Sie dann die Daten zusammen und stellen Sie sie im Pufferpool wieder her, und aktualisieren Sie dann die zusammengeführten Daten auf der Festplatte.
Funktion: Jede Festplattenoperation verursacht viel Festplatten-IO.Mit ChangeBuffer kann der Zusammenführungsprozess im Pufferpool durchgeführt werden, was die Festplatten-IO stark reduziert
2.2.3 Adaptiver Hash-Index:
Der adaptive Hash-Index wird verwendet, um die Abfrage von Buffer Pool (Buffer Pool)-Daten zu optimieren. InnoDB überwacht die Abfrage jeder Indexseite in der Tabelle und erstellt einen Hash-Index, wenn es feststellt, dass der Hash-Index die Geschwindigkeit verbessern kann. Hinweis: Der adaptive Hash-Index wird ohne manuellen Eingriff automatisch vom System je nach Situation vervollständigt.
Der adaptive Hash-Index hat einen Flag-Schalter, um festzulegen, ob er aktiviert werden soll: adaptive_hash_index.
2.2.4 Protokollpuffer: Protokollpuffer
Protokollpuffer, speichern Sie die Protokolldaten (Redo-Protokoll, Undo-Protokoll), die auf die Festplatte geschrieben werden sollen. Der Standardwert ist 16 MB. Das Protokoll wird regelmäßig auf der Festplatte aktualisiert, wenn Sie viele Transaktionszeilen aktualisieren, einfügen oder löschen müssen. Erhöhen Sie die Größe des Protokollpuffers. Kann Festplatten-E/A speichern
Parameter:
InnoDB_log_buffer_size: Puffergröße,
InnoDB_flush_log_at_trx_commit: Wenn das Protokoll auf die Festplatte geleert wird (dieser Parameter hat 3 Werte: 1, 0, 2)
1. Jedes Mal, wenn eine Transaktion festgeschrieben wird, wird sie auf die Festplatte geschrieben
0. Protokolle werden jede Sekunde geschrieben und auf die Festplatte geleert
2. Nachdem jede Transaktion festgeschrieben wurde, wird sie jede Sekunde auf der Festplatte aktualisiert
2.2 Festplattenstruktur
2.2.1 System Tablespace: Der System Tablespace ist der Speicherbereich von [Change Buffer ] in der Speicherstruktur. Parameter: innodb_data_file_path
2.2.2 Datei-pro-Tabelle-Tablespace: Der Tablespace jeder Tabellendatei enthält die Daten und Indizes einer einzelnen InnoDB-Tabelle und wird in einer einzelnen Datendatei im Dateisystem gespeichert. Parameter: innodb_file_per_table (standardmäßig aktiviert)
2.2.3 Allgemeiner Tablespace: Allgemeiner Tablespace , der durch die create Tablespace-Syntax erstellt werden muss, die beim Erstellen einer Tabelle angegeben werden kann. (entspricht der Tatsache, dass wir den Tablespace selbst manuell erstellen und dann den von uns manuell erstellten Tablespace beim Erstellen einer neuen Tabelle angeben können)
2.2.4 Undo-Tablespace: Undo-Tablespace erstellt die MySQL-Instanz während der Initialisierung automatisch zwei Standard-Undo-Tablespaces (standardmäßig 16 MB), um Undo-Log-Protokolle zu speichern.
2.2.5 Temporärer Tablespace: Temporärer Tablespace , InnoDB verwendet den temporären Tablespace der Sitzung und den globalen temporären Tablespace, um temporäre Tabellendaten zu speichern, die von Benutzern usw. erstellt wurden.
2.2.6 Doublewrite-Pufferdateien: Doublewrite-Puffer Bevor die InnoDB-Engine die Datenseite aus dem Buffer Pool auf die Festplatte schreibt, schreibt sie die Datenseite zunächst in die Doublewrite-Pufferdatei, was für die Datenwiederherstellung praktisch ist, wenn das System anormal ist.
2.2.7 Redo-Log: Redo-Log , das die Persistenz von Transaktionen realisiert, besteht aus Redo-Log-Puffer (Redo-Puffer) und Redo-Log-Datei (Redo-Log) , ersteres befindet sich im Arbeitsspeicher und letzteres auf der Festplatte. Wenn die Transaktion festgeschrieben wird, werden alle Änderungsinformationen in das Protokoll geschrieben, das für die Datenwiederherstellung verwendet wird, wenn Fehler auftreten, wenn fehlerhafte Seiten auf die Festplatte geleert werden.
2.3 Hintergrund-Threads
Funktion: Aktualisieren Sie die Daten im InnoDB-Pufferpool zum richtigen Zeitpunkt in der Plattendatei.
2.3.1 Master-Thread
Der zentrale Hintergrund-Thread ist für die Planung anderer Threads und auch für die asynchrone Aktualisierung der Daten im Pufferpool auf der Festplatte verantwortlich, um die Datenkonsistenz zu wahren.Er umfasst auch das Aktualisieren von Dirty Pages, das Zusammenführen und Einfügen von Caches sowie das Recycling von Undo-Seiten.
2.3.2 IO-Thread
In der InnoDB-Speicher-Engine wird AIO häufig zur Verarbeitung von IO-Anforderungen verwendet, was die Leistung der Datenbank erheblich verbessern kann, und IO-Thread ist hauptsächlich für den Rückruf dieser IO-Anforderungen verantwortlich

2.3.3 Thread bereinigen
Es wird hauptsächlich verwendet, um das Rückgängig-Protokoll zu recyceln, das von der Transaktion gesendet wurde. Nachdem die Transaktion festgeschrieben wurde, darf das Undo-Protokoll nicht verwendet werden, also wird es zum Recyceln verwendet
2.3.4 Seitenreiniger-Thread
Ein Thread, der den Master-Thread dabei unterstützt, schmutzige Seiten auf die Festplatte zu spülen, was den Arbeitsdruck des Master-Threads verringern und Blockierungen verringern kann
3. Geschäftsprinzip
Eine Transaktion ist eine Sammlung von Vorgängen. Sie stellt eine unteilbare Arbeitseinheit dar. Eine Transaktion übermittelt oder widerruft eine Vorgangsanforderung an das System als Ganzes. Diese Vorgänge sind entweder gleichzeitig erfolgreich oder schlagen fehl .
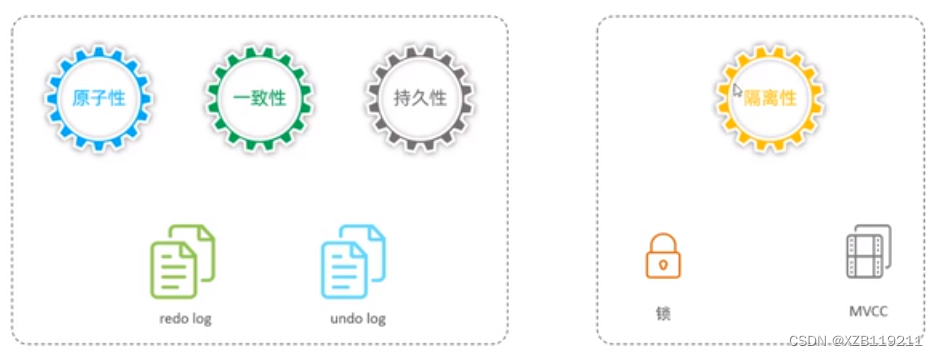
1. Atomarität Eine Transaktion muss als unteilbare Mindesteinheit betrachtet werden.Alle Operationen in der gesamten Transaktion werden entweder erfolgreich übermitteltoder alle schlagen fehl.Für eine Transaktion ist es unmöglich, nur einen Teil der Operationen auszuführen
2. Konsistenz (Consistency) Wenn die Datenbank vor Ausführung der Transaktion konsistent ist, dann ist die Datenbank auch nach Ausführung der Transaktion noch konsistent;
3. Isolation Transaktionsvorgänge sind unabhängig und transparent, ohne sich gegenseitig zu beeinflussen. Transaktionen laufen unabhängig voneinander. Dies wird normalerweise durch Sperren erreicht. Beeinflusst das Ergebnis einer Transaktionsverarbeitung andere Transaktionen, werden andere Transaktionen zurückgezogen. Eine 100-prozentige Isolierung von Transaktionen erfordert Geschwindigkeitseinbußen.
4. Dauerhaftigkeit (Dauerhaftigkeit) Sobald die Transaktion festgeschrieben ist, ist das Ergebnis dauerhaft. Selbst wenn ein Systemausfall auftritt, kann es wiederhergestellt werden.
Atomarität, Konsistenz und Dauerhaftigkeit werden durch Redolog und Undo-Log gesteuert
Die Isolation wird durch Sperren und MVCC gesteuert
—> Persistenz wird durch Redo-Log gewährleistet
Redo-Protokoll: Redo-Protokoll, das die Persistenz von Transaktionen realisiert. Es besteht aus Redo-Protokoll (Redo-Puffer) und Redo-Protokoll (Redo-Protokoll). Ersteres befindet sich im Speicher und letzteres auf der Festplatte. Nachdem die Transaktion festgeschrieben wurde, alle Alle Änderungsinformationen werden in das Protokoll geschrieben, das für die Datenwiederherstellung verwendet wird, wenn beim Leeren von fehlerhaften Seiten auf die Festplatte ein Fehler auftritt.

Erläuterung: Die Abbildung zeigt den Verarbeitungsmechanismus in InnoDB, um die Persistenz der Transaktion sicherzustellen, nachdem eine Transaktion festgeschrieben wurde.Zunächst, nachdem die Transaktion festgeschrieben wurde, geht sie zur entsprechenden Datenseite im Pufferpool in der Speicherstruktur, um die zu ändern Daten. Warten Sie auf die Operation, nachdem die Operation abgeschlossen ist, die Transaktion im Speicher zu diesem Zeitpunkt ausgeführt wurde, aber nicht rechtzeitig auf die Festplatte aktualisiert wurde, wird die aktualisierte Datenseite im aktuellen Speicher als schmutzige Seite bezeichnet. und wenn die Operation im Buffer Pool durchgeführt wird, wird die Datenseite im Speicher Alle Operationen werden im Redolog-Puffer in dem Bereich aufgezeichnet und dann periodisch durch den Hintergrund-Thread in das Redo-Log auf der Festplatte aktualisiert, und dann, wenn an Wenn ein Fehler auftritt, wenn die Daten im Buffer Pool auf die Festplatte aktualisiert werden, können die Daten über das Redo-Protokoll bei der Festplattenwiederherstellung verarbeitet werden. Wenn die Buffer Pool-Daten korrekt mit der Festplatte synchronisiert sind, ist das Redolog auf der Festplatte nutzlos, sodass die beiden Redologs auf der Festplatte aufeinander kopiert werden, um zeitnahe Aktualisierungen zu erreichen. Diese Methode, zuerst Protokolle zu schreiben und dann Daten zu synchronisieren, wird als WAL (Write-Ahead Log) bezeichnet.
Warum sich dann die Mühe machen, erst in den Redolog Buffer zu schreiben und dann ins Redo Log zu übertragen, würde es nicht ausreichen, nach jeder Transaktion die Daten aus dem Buffer Pool auf die Platte zu aktualisieren? Hier gibt es ein Problem. Die meisten Operationen auf Datenseiten in einer Transaktion sind zufällig. Wenn jede Transaktion sofort auf die Festplatte geschrieben wird, werden mehrere Festplatten-IOs generiert, die viel Leistung verbrauchen. Also übergeben wir Redolog, um Daten sicherzustellen Beständigkeit auf diese Weise.
—> Atomarität wird durch Undo-Log garantiert
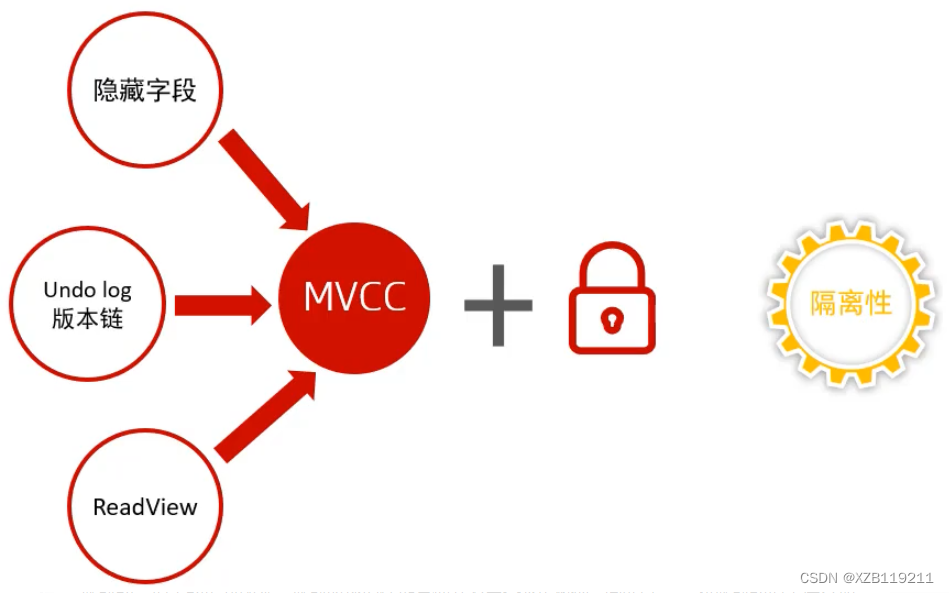
Undo-Protokoll: Rollback-Protokoll, das verwendet wird, um die Informationen aufzuzeichnen, bevor die Daten geändert werden. Die Rolle umfasst: Bereitstellen von Rollback und MVCC (Multi-Version Control Concurrency)
Undo-Log und Redo-Log zeichnen physische Logs unterschiedlich auf. Es ist ein logisches Log. Es kann davon ausgegangen werden, dass beim Löschen eines Datensatzes ein entsprechender Einfüge-Datensatz im Undo-Log aufgezeichnet wird und umgekehrt. Wenn ein Datensatz aktualisiert wird, a entsprechender Datensatz wird aufgezeichnet Datensätze aktualisieren, beim Ausführen von Rollback können Sie den entsprechenden Inhalt aus den logischen Datensätzen im Undo-Protokoll lesen und zurücksetzen.
Zerstörung des Undo-Protokolls: Es wird generiert, wenn die Transaktion ausgeführt wird. Wenn die Transaktion festgeschrieben wird, wird das Undo-Protokoll nicht sofort gelöscht. Diese Protokolle können auch für MVCC verwendet werden.
Undo-Log-Speicherung: Es wird in Form von Segmenten verwaltet und aufgezeichnet, die im Rollback-Rollback-Segment gespeichert sind, das 1024 Undo-Log-Segmente enthält.
4. MVCC
4.1 Konzept
Was ist MVCC?
MVCC soll mehrere Versionen von Daten beim gleichzeitigen Zugriff auf die Datenbank verwalten, um zu vermeiden, dass die Anforderung zum Lesen von Daten blockiert wird, weil beim Schreiben von Daten eine Schreibsperre hinzugefügt werden muss, was zu dem Problem führt, dass Daten beim Schreiben von Daten nicht gelesen werden können.
Laienhaft ausgedrückt speichert MVCC die historische Version der Daten und entscheidet anhand der Versionsnummer der verglichenen Daten, ob die Daten angezeigt werden.Es kann den Isolationseffekt der Transaktion erzielen, ohne eine Lesesperre hinzuzufügen, und kann schließlich die Daten lesen Gleichzeitig ändern, wenn Sie Daten ändern, können Sie sie gleichzeitig lesen, was die Gleichzeitigkeitsleistung von Transaktionen erheblich verbessert.
4.2 Kernwissenspunkte der InnoDB MVCC-Implementierung
4.2.1 Versionsnummer der Transaktion
Bevor jede Transaktion gestartet wird, wird eine sich selbst erhöhende Transaktions-ID aus der Datenbank erhalten, und die Ausführungsreihenfolge von Transaktionen kann anhand der Transaktions-ID beurteilt werden.
4.2.2 Versteckte Tabellenspalten
| DB_TRX_ID | Notieren Sie die Transaktions-ID der Datentransaktion; |
| DB_ROLL_PTR | Zeiger auf den Positionszeiger der vorherigen Versionsdaten im Undo-Log; |
| DB_ROW_ID | Versteckte ID, beim Erstellen einer Tabelle ohne geeigneten Index als Clustered-Index wird die versteckte ID verwendet, um einen Clustered-Index zu erstellen; |
4.2.3 Undo Log
Das Undo-Protokoll wird hauptsächlich verwendet, um das Protokoll aufzuzeichnen, bevor die Daten geändert werden. Bevor die Tabelleninformationen geändert werden, werden die Daten in das Undo-Protokoll kopiert. Wenn die Transaktion rückgängig gemacht wird, können die Daten im Undo-Protokoll wiederhergestellt werden.
Zweck des Rückgängig-Protokolls
(1) Atomarität und Konsistenz garantieren, wenn die Transaktion rückgängig gemacht wird.Wenn die Transaktion rückgängig gemacht wird, können die Rückgängig-Protokolldatenzur Wiederherstellung verwendet werden.
(2) Die Daten, die zum Lesen von MVCC-Snapshots verwendet werden.In der MVCC-Mehrversionskontrolle können unterschiedliche Transaktionsversionsnummerndurch Lesen der historischen Versionsdaten des Rückgängig-Protokolls ihre eigenenunabhängigen Snapshot-Datenversionen haben.
4.2.4 Zusammenhang zwischen Transaktionsversionsnummer, versteckter Tabellenspalte und Undo-Log
Wir verwenden einen Datenänderungssimulationsprozess, um die Beziehung zwischen der Transaktionsversionsnummer, ausgeblendeten Spalten und Undolog zu verstehen
(1) Bereiten Sie zuerst eine Originaldatentabelle vor
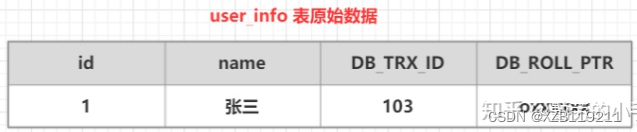
(2) Starte eine Transaktion A: führe update user_info set name = "Li Si" aus, wobei id = 1 in der user_info-Tabelle ist, und der folgende Prozess wird durchgeführt
| 1. Besorgen Sie sich zuerst eine Transaktionsnummer 104 |
| 2. Kopieren Sie die Daten vor der Änderung der user_info-Tabelle in das Rückgängig-Protokoll |
| 3. Ändern Sie die Daten der user_info-Tabelle id=1 |
| 4. Ändere die modifizierte Datentransaktionsversionsnummer in die aktuelle Transaktionsversionsnummer und zeige die DB_ROLL_PTR-Adresse auf die Undo-Log-Datenadresse. |
(3) Das Ergebnis der endgültigen Ausführung ist in der Abbildung dargestellt

4.2.5 Undolog-Versionskette
Das Modifizieren desselben Datensatzes durch verschiedene Transaktionen oder dieselbe Transaktion bewirkt, dass das Undo-Protokoll des Datensatzes eine Datensatzversions-Verknüpfungsliste erzeugt.Der Kopf der verknüpften Liste ist der neueste alte Datensatz, und das Endeder verknüpften Liste ist der früheste alte aufzeichnen.

4.2.6 Leseansicht
Nachdem jede Transaktion in InnoDB geöffnet wurde, erhalten Sie eine (Leseansicht). Die Kopie speichert hauptsächlich die ID-Nummern von Transaktionen, die (ohne Commit) im aktuellen Datenbanksystem aktiv sind, oder einfach gesagt, diese Kopie speichert eine Liste anderer Transaktions-IDs im System, die von dieser Transaktion nicht gesehen werden sollen. ( Wenn jede Transaktion geöffnet wird, wird ihr eine ID zugewiesen, die inkrementiert wird, sodass die letzte Transaktion einen größeren ID-Wert hat. )
Wir wissen also, dass Read View hauptsächlich zur Beurteilung der Sichtbarkeit verwendet wird, d. h. wenn wir einen Snapshot-Read für eine bestimmte Transaktion ausführen, erstellen wir eine Read View-Leseansicht für den Datensatz und vergleichen sie mit einer Bedingung, um zu beurteilen, ob die aktuelle Transaktion vorliegt können sehen, welche Version der Daten die letzten aktuellen Daten sein können, oder eine bestimmte Version der Daten im Undo-Protokoll, das in dieser Zeile aufgezeichnet ist.
Read View folgt einem Sichtbarkeitsalgorithmus, der hauptsächlich die DB_TRX_ID (d. h. die aktuelle Transaktions-ID) aus dem letzten Datensatz der zu ändernden Daten herausnimmt und sie mit den IDs anderer aktiver Transaktionen im System vergleicht (verwaltet von Read View ), wenn DB_TRX_ID folgt Die Attribute von Read View haben einige Vergleiche durchgeführt, die nicht der Sichtbarkeit entsprechen, dann verwenden Sie den DB_ROLL_PTR-Rollback-Zeiger, um die DB_TRX_ID im Undo-Protokoll zu entnehmen und erneut zu vergleichen, d. h. die DB_TRX_ID zu durchlaufen die verknüpfte Liste (vom Anfang der Kette bis zum Ende der Kette, d. h. vom letzten Modify und Check), bis Sie eine DB_TRX_ID finden, die bestimmte Bedingungen erfüllt, dann ist der alte Datensatz, in dem sich diese DB_TRX_ID befindet, die neueste alte Version, die die aktuelle Transaktion sehen kann
Mehrere wichtige Eigenschaften der Leseansicht:
| m_ids: Aktueller systemaktiver (nicht festgeschriebener) Transaktionsversionsnummernsatz |
| min_trx_id: Minimale aktive Transaktions-ID |
| max_trx_id: Vorab zugewiesene Transaktions-ID, die aktuelle maximale Transaktions-ID+1 (weil die Transaktions-ID selbsterhöhend ist) |
| Creator_trx_id: Erstellen Sie die Transaktionsversionsnummer der aktuellen Leseansicht |
Übereinstimmungsbedingungen der Leseansicht:

1. Datentransaktions-ID==creator_trx_id
Wenn festgestellt, können Sie auf diese Version zugreifen, die anzeigt, dass die Daten durch die aktuelle Transaktion geändert wurden
2. Wenn die Datentransaktions-ID <min_trx_id ist, wird sie angezeigt
Wenn die Datentransaktions-ID kleiner als die minimal aktive Transaktions-ID in der Leseansicht ist, ist es sicher, dass die Daten bereits existierten, bevor die aktuelle Transaktion gestartet wurde, sodass sie angezeigt werden können.
3. Datentransaktions-ID>=max_trx_id wird nicht angezeigt
Wenn die Datentransaktions-ID größer als die maximale Transaktions-ID des aktuellen Systems in der Leseansicht ist, bedeutet dies, dass die Daten generiert werden, nachdem die aktuelle Leseansicht erstellt wurde, sodass die Daten nicht angezeigt werden.
4. Wenn min_trx_id<=Datentransaktions-ID<max_trx_id, stimmt es mit dem aktiven Transaktionssatz trx_ids überein
Wenn die Transaktions-ID der Daten größer als die kleinste aktive Transaktions-ID und kleiner oder gleich der größten Transaktions-ID des Systems ist, zeigt diese Situation an, dass die Daten möglicherweise nicht übermittelt wurden, als die aktuelle Transaktion gestartet wurde.
Zu diesem Zeitpunkt müssen wir also die Transaktions-ID der Daten mit dem aktiven Transaktionssatz trx_ids in der aktuellen Leseansicht abgleichen:
Fall 1: Wenn die Transaktions-ID nicht in der trx_ids-Sammlung vorhanden ist (dies bedeutet, dass die Transaktion beim Generieren der Leseansicht festgeschrieben wurde), können die Daten in diesem Fall angezeigt werden.
Fall 2: Wenn die Transaktions-ID in trx_ids vorhanden ist, bedeutet dies, dass die Daten beim Generieren der Leseansicht nicht übermittelt wurden, aber wenn die Transaktions-ID der Daten gleich der „creator_trx_id“ ist, bedeutet dies, dass die Daten von generiert wurden aktuelle Transaktion selbst, und die von ihm generierten Daten können von ihm selbst gesehen werden, so dass in diesem Fall die Daten auch angezeigt werden können.
Fall 3: Wenn die Transaktions-ID in trx_ids vorhanden ist und nicht gleich Creator_trx_id ist, bedeutet dies, dass die Daten beim Generieren der Leseansicht nicht übermittelt wurden und nicht von selbst generiert werden, sodass die Daten in diesem Fall nicht angezeigt werden können .
5. Wenn die Bedingung der Leseansicht nicht erfüllt ist, werden die Daten aus dem Rückgängig-Protokoll erhalten
Wenn die Transaktions-ID der Daten die Leseansichtsbedingung nicht erfüllt, wird die historische Version der Daten aus dem Undo-Protokoll erhalten, und dann wird die Transaktionsnummer der historischen Version der Daten mit der Leseansichtsbedingung bis auf ein Stück abgeglichen von historischen Daten, die die Bedingung erfüllen, gefunden werden, oder wenn sie nicht gefunden werden, dann wird ein leeres Ergebnis zurückgegeben;
4.3 Das Prinzip der InnoDB-Implementierung von MVCC

4.3.1 MVCC-Implementierungsprozess simulieren
Im Folgenden simulieren wir den Workflow von MVCC, indem wir zwei gleichzeitige Transaktionen öffnen.
(1) Erstellen Sie eine user_info-Tabelle und fügen Sie Initialisierungsdaten ein

(2) Transaktion A und Transaktion B modifizieren und fragen gleichzeitig user_info ab
Transaktion A: update user_info set name = "Lisi"
Transaktion B: select * from user_info where id=1
Frage:
Starten Sie zuerst Transaktion A und führen Sie Transaktion B aus, nachdem Transaktion A Daten geändert, aber nicht festgeschrieben hat. Was ist das endgültige Rückgabeergebnis.
Der Ausführungsablauf ist wie folgt:

Die Beschreibung des Ausführungsablaufs in der obigen Abbildung:
1. Transaktion A: Um eine Transaktion zu starten, erhalten Sie zuerst eine Transaktionsnummer 102;
2. Transaktion B: Öffnen Sie die Transaktion und erhalten Sie die Transaktionsnummer 103;
3. Transaktion A: Um die Operation zu ändern, kopieren Sie zuerst die ursprünglichen Daten in das Undo-Protokoll, ändern Sie dann die Daten, markieren Sie die Transaktionsnummer und die Adresse der letzten Datenversion im Undo-Protokoll.

4. Transaktion B: Zu diesem Zeitpunkt erhält Transaktion B eine Leseansicht, und der entsprechende Wert der Leseansicht ist wie folgt

5. Transaktion B: Führen Sie die Abfrageanweisung aus, und die modifizierten Daten von Transaktion A werden zu diesem Zeitpunkt erhalten

6. Transaktion B: Daten mit Leseansicht abgleichen

Es wird festgestellt, dass die Anzeigebedingungen für die gelesene Ansicht nicht erfüllt sind, daher werden die Daten der historischen Version von Undo lo erhalten und dann mit der gelesenen Ansicht abgeglichen, und schließlich sind die zurückgegebenen Daten wie folgt.

4.4 Snapshot-Lesen und aktuelles Lesen
Liest gerade:
Gelesen wird die neueste Version des Datensatzes.Beim Lesen muss sichergestellt werden, dass andere gleichzeitige Transaktionenden aktuellen Datensatz nicht ändern können und der gelesene Datensatz gesperrtwird. Für tägliche Operationen, wie z. B.: Auswählen ... Sperren im Freigabemodus (geteilte Sperre), Auswählen ... zum Aktualisieren, Aktualisieren, Einfügen, Löschen (exklusive Sperre) sind alle aktuellen Lesevorgänge
Schnappschuss gelesen:
Eine einfache Auswahl (ohne Sperre) ist ein Snapshot-Lesevorgang. Der Snapshot-Lesevorgang liest die sichtbare Version der aufgezeichneten Daten, bei denen es sich um historische Daten handeln kann. Entsperrt ist eine nicht blockierende Sperre
Read Committed: Bei jeder Auswahl wird ein Snapshot-Lesevorgang generiert
Repeatable Read: In der ersten Select-Anweisung nach dem Start der Transaktion wird der Snapshot gelesen
Serialisierbar: Snapshot-Lesevorgänge degenerieren zu aktuellen Lesevorgängen
Es gibt drei Arten von Datenbankparallelitätsszenarien:
read-read: keine Probleme und keine Parallelitätssteuerung erforderlich
Lesen/Schreiben: Es gibt Thread-Sicherheitsprobleme, die zu Problemen bei der Transaktionsisolation führen können und Dirty Reads, Phantom Reads und Non-repeatable Reads begegnen können
Schreiben-Schreiben: Es gibt Thread-Sicherheitsprobleme und möglicherweise Probleme mit verlorenen Updates, z. B. der ersten Kategorie