Autor: JD Einzelhandel Zhang Luyao
1. Anwendungsszenarien
Derzeit gibt es viele Funktionen im System, die eine verzögerte Verarbeitung erfordern: Zahlungs-Timeout-Stornierung, Warteschlangen-Timeout, verzögertes Senden von SMS, WeChat und anderen Erinnerungen, Token-Aktualisierung, Ablauf der Mitgliedskarte usw. Durch die verzögerte Verarbeitung werden Systemressourcen stark eingespart, und es besteht keine Notwendigkeit, die Datenbank für Verarbeitungsaufgaben abzufragen.
Derzeit werden die meisten Funktionen durch Timing-Tasks erledigt.Es gibt zwei Arten von Timing-Tasks: Quarz und XXLJob.Die Abfragezeit ist kurz und wird einmal pro Sekunde ausgeführt, was die Datenbankbelastet und eine 1-Sekunde hat Fehler. Die Abfragezeit ist lang, zum Beispiel einmal alle 30 Minuten wird ein Datenelement um 03:01 eingefügt, und der Ablauf wird normalerweise um 3:31 ausgeführt, aber wenn das Abfragen um 3:30 durchgeführt wird, werden die Daten von 3:00-3:30 wird gescannt, aber der Scan ist kleiner als 3: Die Daten von 31 können erst um 4:00 gescannt werden, was einer Verzögerung von 29 Minuten entspricht!
2. Forschung zu Verzögerungsverarbeitungsmethoden
1.Verzögerungswarteschlange
1. Implementierungsmethode:
Die von jvm bereitgestellte Verzögerungsblockierungswarteschlange sortiert die Aufgaben mit unterschiedlichen Verzögerungszeiten durch die Prioritätswarteschlange, blockiert durch die Bedingung und ruft die verzögerten Aufgaben während der Ruhezeit ab.
Wenn eine neue Aufgabe hinzugefügt wird, beurteilt sie, ob die neue Aufgabe die erste auszuführende Aufgabe ist.Wenn dies der Fall ist, wird der Warteschlangenschlaf freigegeben, um zu verhindern, dassneu hinzugefügte Elemente ausgeführt werden müssen und normalerweise nichtdurch die Ausführung erhalten werden können Gewinde.
2. Bestehende Probleme:
1. Standalone-Betrieb, nachdem das System heruntergefahren ist, kann kein effektiver Wiederholungsversuch durchgeführt werden
2. Versäumnis, Protokollierung und Sicherung durchzuführen
3. Kein Wiederholungsmechanismus
4. Wenn das System neu startet, wird die Aufgabe gelöscht!
5. Der Konsum von Fragmenten ist nicht erlaubt
3. Vorteile: einfache Implementierung, Blockieren, wenn keine Aufgabe vorhanden ist, Einsparung von Ressourcen und genaue Ausführungszeit
2. Verzögerungswarteschlange mq
Implementierungsmethode: Verlassen Sie sich auf mq und erreichen Sie die verzögerte Verbrauchsfunktion, indem Sie die verzögerte Verbrauchszeit einstellen. Wie bei rabbitMq und jmq können Sie die verzögerte Verbrauchszeit einstellen. RabbitMq wird implementiert, indem die Ablaufzeit der Nachricht festgelegt und zum Verbrauch in die Warteschlange für unzustellbare Nachrichten gestellt wird.
Bestehende Probleme:
1. Die Zeiteinstellung ist nicht flexibel. Jede Warteschlange hat eine feste Ablaufzeit. Jedes Mal, wenn eine Verzögerungswarteschlange neu erstellt wird, muss eine neue Nachrichtenwarteschlange erstellt werden
Vorteile: Indem es sich auf jmq verlässt, kann es effektiv überwachen, Aufzeichnungen verbrauchen und es erneut versuchen, hat die Fähigkeit, mehrere Maschinen gleichzeitig zu verbrauchen, und hat keine Angst vor Ausfallzeiten
3. Geplante Aufgaben
Abfrage qualifizierter Daten durch geplante Aufgaben
Mangel:
1. Es ist notwendig, die Unternehmensdatenbank zu lesen, was einen gewissen Druck auf die Datenbank ausübt.
2. Es gibt eine Verzögerung
3. Wenn die Menge der gescannten Daten zu groß ist, werden zu viele Systemressourcen beansprucht.
4. Fragmentierung kann nicht verbraucht werden
Vorteil:
1. Nachdem der Verbrauch fehlgeschlagen ist, können Sie beim nächsten Mal weiter verbrauchen und die Möglichkeit haben, es erneut zu versuchen.
2. Stabile Kaufkraft
4.redis
Die Aufgaben werden in redis gespeichert und die zset-Queue von redis wird zum Sortieren nach der Punktzahl verwendet.Das Programm erhält kontinuierlich den Queue-Datenverbrauch durch den Thread, um die Delay-Queue zu realisieren
Vorteil:
1. Das Abfragen von Redis ist schneller als die Datenbank, und die eingestellte Warteschlangenlänge ist zu groß, und die Abfrage wird gemäß der Sprungtabellenstruktur durchgeführt, was sehr effizient ist
2. Redis können nach dem Zeitstempel sortiert werden, Sie müssen nur die Aufgabe der Partitur im aktuellen Zeitstempel abfragen
3. Keine Angst vor Neustart der Maschine
4. Verteilter Verbrauch
Mangel:
1. Begrenzt durch Redis-Leistung, gleichzeitig 10 W
2. Mehrere Befehle können keine Atomarität garantieren. Die Verwendung von Lua-Skripten erfordert, dass sich alle Daten auf einem Redis-Shard befinden.
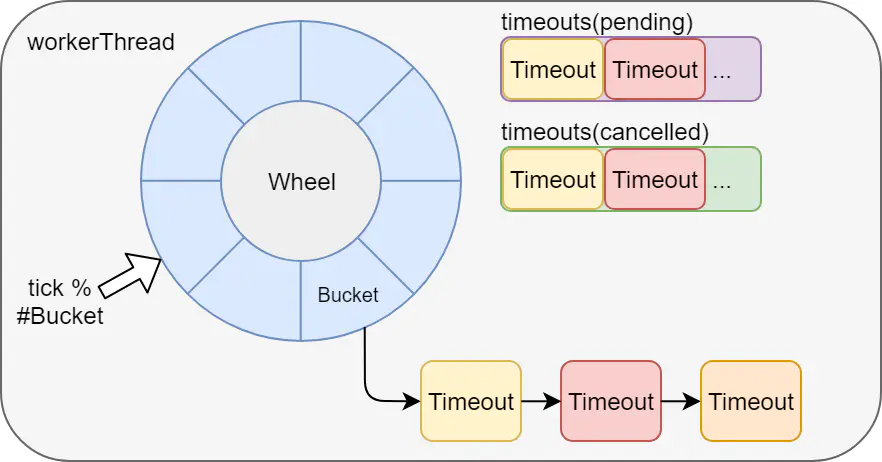
5. Zeitrad
Die verzögerte Aufgabenausführung durch das Zeitrad basiert ebenfalls auf dem Stand-alone-Betrieb von jvm. Beispielsweise implementieren kafka und netty beide Zeiträder, und der Watchdog von redisson wird ebenfalls durch das Zeitrad von netty realisiert.
Nachteile: Es ist nicht für die Nutzung von verteilten Diensten geeignet, und Tasks gehen nach Ausfallzeiten verloren.
3. Ziele erreichen
Kompatibel mit den derzeit verwendeten asynchronen Ereigniskomponenten und bieten zuverlässigere, wiederholbare, aufgezeichnete, alarmüberwachende und leistungsstarke Verzögerungskomponenten.
•Zuverlässigkeit der Nachrichtenübertragung: Nachdem eine Nachricht in die Verzögerungswarteschlange gelangt ist, wird sie garantiert mindestens einmal verarbeitet.
•Client unterstützt Rich: unterstützt mehrere Sprachen.
• Hohe Verfügbarkeit: Unterstützt die Bereitstellung mehrerer Instanzen. Nachdem eine Instanz ausgesetzt wurde, gibt es eine Sicherungsinstanz, die weiterhin Dienste bereitstellt.
•Echtzeit: Ein gewisser Zeitfehler ist erlaubt.
• Nachrichtenlöschung unterstützen: Geschäftsbenutzer können bestimmte Nachrichten jederzeit löschen.
• Verbrauchsabfrage unterstützen
• Manuelle Wiederholung unterstützen
• Verbesserte Überwachung der Ausführung des aktuellen asynchronen Ereignisses
4. Architekturdesign
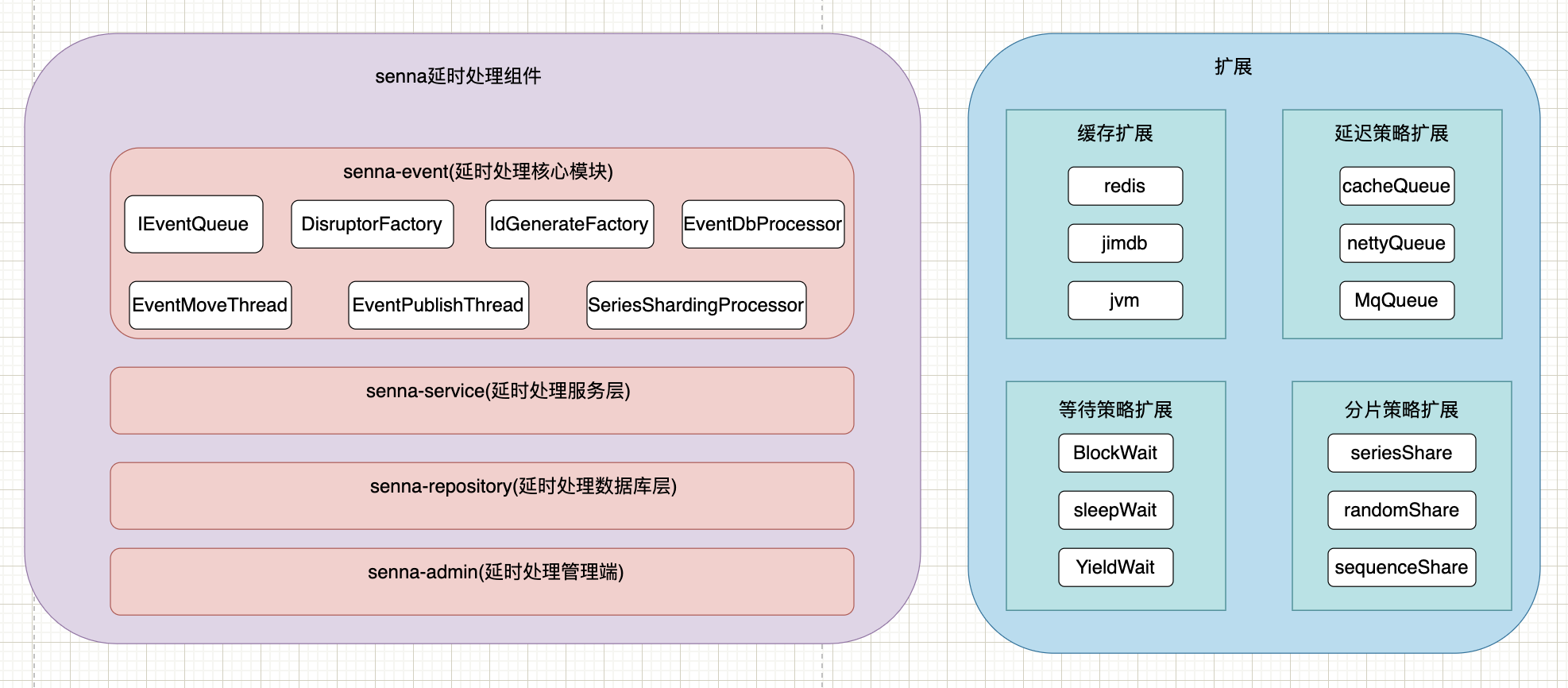
5. Komponentenimplementierung verzögern
1. Umsetzungsprinzip
Derzeit verwenden wir jimdb, um die Verzögerungsfunktion über zset zu implementieren, und speichern die Aufgaben-ID und die entsprechende Ausführungszeit als Punktzahl in der zset-Warteschlange. Standardmäßig werden sie nach Punktzahl sortiert, und jedes Mal, wenn wir die Aufgaben-ID nehmen von 0-Punktzahl innerhalb der aktuellen Zeit,
Beim Senden einer verzögerten Aufgabe wird eine eindeutige ID gemäß Zeitstempel + Maschinen-IP + Warteschlangenname + Sequenz generiert, und der Nachrichtentext wird erstellt, verschlüsselt und in die zset-Warteschlange gestellt.
Durch das Verschieben des Threads wird die Aufgabe, die die Ausführungszeit erreicht hat, in die Freigabewarteschlange verschoben und wartet darauf, dass der Verbraucher sie erhält.
Die überwachende Partei integriert ump
Verbrauchsaufzeichnungen werden durch Redis-Backup + Datenbankpersistenz vervollständigt.
Die durch Caching implementierte Methode ist nur eine Art der Implementierung, welche Implementierungsmethode durch Parameter gesteuert werden kann und durch spi frei erweitert werden kann.
2. Nachrichtenstruktur
Jeder Job muss die folgenden Attribute enthalten:
•Thema: Auftragstyp, dh QueueName
•ID: Die eindeutige Kennung des Jobs. Wird verwendet, um die angegebenen Jobinformationen abzurufen und zu löschen.
•Verzögerung: Der Job muss die Zeit verzögern. Einheit: Sekunden. (Der Server konvertiert es in absolute Zeit)
•Body: Der Inhalt des Jobs, der im json-Format gespeichert wird, damit Verbraucher bestimmte Geschäftsprozesse durchführen können.
•traceId: die traceId des sendenden Threads, nachdem der nachfolgende pfinder das Setzen von traceId unterstützt, kann er dieselbe traceid mit dem sendenden Thread teilen, was praktisch für die Protokollverfolgung ist
Die spezifische Struktur ist in der folgenden Abbildung dargestellt:

TTR wurde entwickelt, um die Zuverlässigkeit der Nachrichtenübertragung sicherzustellen.
3. Datenfluss und Flussdiagramm

Veröffentlichen und konsumieren Sie basierend auf der Redis-Disruptor-Methode, die als Nachricht verwendet werden kann. Verbraucher verwenden die ursprüngliche asynchrone ereignisunterbrechungsfreie Warteschlange für die Nutzung, und es gibt keine Sperre zwischen verschiedenen Anwendungen und verschiedenen Warteschlangen
1. Unterstützen Sie die Anwendung, um nur zu veröffentlichen, nicht zu konsumieren, und erreichen Sie die Funktion der Nachrichtenwarteschlange.
2: Bucketing unterstützen: Für das Problem großer Schlüssel können Sie bei vielen Ereignissen die Anzahl der Verzögerungswarteschlangen und Aufgabenwarteschlangen-Buckets festlegen, um das durch große Schlüssel verursachte Redis-Blockierungsproblem zu reduzieren.
3: Durch die Ducc-Konfiguration wird die Leistung erweitert, aktuell ist nur der Verbrauch aktiviert und der Verbrauch deaktiviert.
4: Unterstützung der Einstellung der Timeout-Konfiguration, um zu verhindern, dass Consumer-Threads zu lange ausgeführt werden
Engpass: Die Verbrauchsgeschwindigkeit ist langsam und die Produktionsgeschwindigkeit ist zu hoch, was dazu führt, dass die Ringbuffer-Warteschlange voll ist. Wenn die aktuelle Anwendung sowohl ein Produzent als auch ein Verbraucher ist, schläft der Produzent und die Leistung hängt von der Verbrauchsgeschwindigkeit ab Die Maschine kann horizontal erweitert werden, um die Leistung direkt zu verbessern. Überwachen Sie die Länge der Redis-Warteschlange. Wenn sie weiter anwächst, sollten Sie erwägen, Verbraucher hinzuzufügen, um die Leistung direkt zu verbessern.
Mögliche Situation: Da eine Anwendung einen Disruptor gemeinsam nutzt und 64 Consumer-Threads hat, verbrauchen alle 64 Threads dieses Ereignis, wenn die Verarbeitung eines bestimmten Ereignisses zu langsam ist, was dazu führt, dass andere Ereignisse von keinem Consumer-Thread und dem Produzenten verarbeitet werden Thread wird ebenfalls verbrauchen, wird blockiert, was dazu führt, dass der Verbrauch aller Ereignisse blockiert wird.
Um später zu beobachten, ob ein solcher Performance-Engpass vorliegt, können Sie jeder Warteschlange einen Consumer-Thread-Pool zuweisen.
6. Demo-Beispiel
Konfigurationsdatei hinzufügen
Bestimmen Sie, ob jd.event.enable:true aktiviert werden soll
<dependency> <groupId>com.jd.car</groupId>
<artifactId>senna-event</artifactId>
<version>1.0-SNAPSHOT</version> </dependency>
Aufbau
jd:
senna:
event:
enable: true
queue:
retryEventQueue:
bucketNum: 1
handleBean: retryHandle
Verbrauchscode:
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@Component("retryHandle")
public class RetryQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
Anmerkungsformular:
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@SennaEvent(queueName = "testQueue", bucketNum = 5,delayBucketNum = 5,delayEnable = true)
public class TestQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
Code senden
package com.jd.car.senna.admin.controller;
import com.jd.car.senna.event.queue.IEventQueue;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Lazy;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.concurrent.CompletableFuture;
/**
* @author zly
*/
@RestController
@Slf4j
public class DemoController {
@Lazy
@Resource(name = "testQueue")
private IEventQueue eventQueue;
@ResponseBody
@GetMapping("/api/v1/demo")
public String demo() {
log.info("发送无延迟消息");
eventQueue.push("no delay 5000 millseconds message 3");
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo1")
public String demo1() {
log.info("发送延迟5秒消息");
eventQueue.push(" delay 5000 millseconds message,name",1000*5L);
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo2")
public String demo2() {
log.info("发送延迟到2022-04-02 00:00:00执行的消息");
eventQueue.push(" delay message,name to 2022-04-02 00:00:00", new Date(1648828800000));
return "ok";
}
}
Siehe Youzan's Design: https://tech.youzan.com/queuing_delay/
7. Aktuelle Anwendung:
1. Yunxiu storniert automatisch nach 24 Stunden in der Schlange im Geschäft
2. Meituan fordert regelmäßig eine Token-Aktualisierung an.
3. Die Garantiekarte wird innerhalb von 24 Stunden erstellt
5. Verschiebung der Kontoauszugserstellung
6. Verzögerter SMS-Versand