Angenommen, Sie haben jetzt die Daten und das Budget, alles ist bereit und Sie sind bereit, mit dem Training eines großen Modells zu beginnen. Sobald Sie Ihre Fähigkeiten unter Beweis gestellt haben, scheint „alle Blumen in Chang'an an einem Tag zu sehen“ nahe zu liegen die Ecke ... Moment mal! Das Training ist nicht so einfach wie die Aussprache dieser beiden Wörter. Es kann hilfreich sein, sich das Training von BLOOM anzusehen.
In den letzten Jahren ist es zur Norm geworden, dass Sprachmodelle immer größer werden. Normalerweise wird kritisiert, dass die Informationen dieser großen Modelle selbst nicht für die Forschung offengelegt werden, aber dem Wissen hinter der Trainingstechnologie für große Modelle wird wenig Aufmerksamkeit geschenkt. Dieser Artikel zielt darauf ab, das Sprachmodell BLOOM mit 176 Milliarden Parametern als Beispiel zu nehmen, um die software- und hardwaretechnischen Aspekte hinter dem Training solcher Modelle zu verdeutlichen, um so die Diskussion über die Trainingstechnologie für große Modelle zu fördern.
Zunächst möchten wir den Unternehmen, Einzelpersonen und Gruppen danken, die den Höhepunkt unserer Gruppe bei der unglaublichen Meisterleistung des Trainierens eines Modells mit 176 Milliarden Parametern ermöglicht oder gesponsert haben.
Dann beginnen wir mit der Diskussion der Hardwarekonfiguration und der wichtigsten technischen Komponenten.

Nachfolgend eine kurze Zusammenfassung des Projekts:
| Hardware | 384 80-GB-A100-GPUs |
| Software | Megatron-DeepSpeed |
| Modellarchitektur | Basierend auf GPT3 |
| Datensatz | 350 Milliarden Wörter in 59 Sprachen |
| Trainings zeit | 3,5 Monate |
Personalzusammensetzung
Das Projekt wurde von Thomas Wolf (Mitbegründer und CSO von Hugging Face) konzipiert, der es wagte, mit den großen Unternehmen zu konkurrieren, indem er vorschlug, ein Model, das im weltweit größten Wald mehrsprachiger Models steht, nicht nur zu trainieren, sondern auch herzustellen für alle zugänglich Der öffentliche Zugang zu Trainingsergebnissen erfüllt die Träume der meisten Menschen.
Dieser Artikel konzentriert sich auf die technischen Aspekte des Modelltrainings. Einige der wichtigsten Teile der Technologie hinter BLOOM sind die Menschen und Unternehmen, die ihr Fachwissen teilen und uns beim Programmieren und Trainieren helfen.
Wir müssen uns hauptsächlich bei 6 Gruppen bedanken:
- Das BigScience-Team von HuggingFace widmete mehr als sechs Vollzeitmitarbeitern der Forschung und dem Betrieb des Trainings, und sie stellten auch die gesamte Infrastruktur außer dem Computer von Jean Zay bereit oder erstatteten sie.
- Die Entwickler des Microsoft DeepSpeed-Teams, das DeepSpeed entwickelt und später in Megatron-LM integriert hat, haben wochenlang die Anforderungen des Projekts recherchiert und vor und während der Schulung viele tolle praktische Ratschläge gegeben.
- Das NVIDIA Megatron-LM-Team, das Megatron-LM entwickelt hat, beantwortet gerne unsere vielen Fragen und bietet erstklassige Anwendungsberatung.
- Das IDRIS/GENCI-Team, das den Jean-Zay-Supercomputer verwaltet, stellte dem Projekt erhebliche Rechenleistung und starke Systemverwaltungsunterstützung zur Verfügung.
- Das PyTorch-Team hat ein leistungsstarkes Framework geschaffen, auf dem der Rest der Software basiert, und hat uns sehr dabei unterstützt, uns auf das Training vorzubereiten, mehrere Fehler zu beheben und die Trainingsnutzbarkeit der PyTorch-Komponenten zu verbessern, auf die wir angewiesen sind.
- Freiwilliger der BigScience Engineering Working Group
Es ist schwer, alle brillanten Leute zu nennen, die zur technischen Seite des Projekts beigetragen haben, deshalb nenne ich nur ein paar Schlüsselpersonen außerhalb von Hugging Face, die in den letzten 14 Monaten die technische Grundlage für das Projekt gelegt haben:
Olatunji Ruwase, Deepak Narayanan, Jeff Rasley, Jared Casper, Samyam Rajbhandari und Rémi Lacroix
Wir danken auch allen Unternehmen, die ihren Mitarbeitern erlaubt haben, sich an diesem Projekt zu beteiligen.
Überblick
Die Modellarchitektur von BLOOM ist GPT3 sehr ähnlich, mit einigen Verbesserungen, die später in diesem Dokument besprochen werden.
Das Modell wurde auf Jean Zay trainiert, einem von der französischen Regierung finanzierten Supercomputer, der von GENCI verwaltet und im IDRIS, dem nationalen Rechenzentrum des französischen Nationalen Zentrums für wissenschaftliche Forschung (CNRS), installiert wurde. Die für die Ausbildung benötigte Rechenleistung wird diesem Projekt großzügig von GENCI gespendet (Spendennummer 2021-A0101012475).
Trainingshardware:
- GPU: 384 NVIDIA A100 80 GB GPUs (48 Knoten) + 32 Ersatz-GPUs
- 8 GPUs pro Knoten, 4 NVLink-Verbindungen zwischen Karten, 4 OmniPath-Links
- CPU: AMD EPYC 7543 32-Kern-Prozessor
- CPU-Speicher: 512 GB pro Knoten
- GPU-Speicher: 640 GB pro Knoten
- Verbindung zwischen Knoten: Es wird eine Omni-Path Architecture (OPA)-Netzwerkkarte verwendet, und die Netzwerktopologie ist ein nicht blockierender Fat Tree
- NCCL - Communications Network: ein vollständig dediziertes Subnetz
- Disk-IO-Netzwerk: GPFS wird mit anderen Knoten und Benutzern geteilt
Kontrollpunkte:
- wichtigsten Kontrollpunkte
- Jeder Prüfpunkt enthält einen Optimiererstatus mit einer Genauigkeit von fp32 und ein Gewicht mit einer Genauigkeit von bf16+fp32 und belegt einen Speicherplatz von 2,3 TB. Wird nur das Gewicht von bf16 eingespart, werden nur 329GB Speicherplatz belegt.
Datensatz:
- 1,5 TB stark deduplizierter und bereinigter Text in 46 Sprachen, konvertiert in 350 B-Token
- Der Wortschatz des Modells umfasst 250.680 Token
- Weitere Einzelheiten finden Sie unter The BigScience Corpus A 1.6TB Composite Multilingual Dataset
Das Training des 176B BLOOM-Modells dauerte von März bis Juli 2022 etwa 3,5 Monate (etwa 1 Million Rechenstunden).
Megatron-DeepSpeed
Das Modell 176B BLOOM wird mit Megatron-DeepSpeed trainiert , das zwei Haupttechniken kombiniert:
- Megatron-DeepSpeed :
- DeepSpeed ist eine Deep-Learning-Optimierungsbibliothek, die verteiltes Training einfach, effizient und effektiv macht.
- Megatron-LM ist ein großes und leistungsstarkes Transformer-Modell-Framework, das vom NVIDIA-Forschungsteam für angewandtes Deep Learning entwickelt wurde.
Das DeepSpeed-Team entwickelte ein 3D-parallelbasiertes Schema, indem es ZeRO-Sharding und Pipeline-Parallelismus in der DeepSpeed-Bibliothek mit Tensor-Parallelismus in Megatron-LM kombinierte. Weitere Einzelheiten zu den einzelnen Komponenten finden Sie in der folgenden Tabelle.
Bitte beachten Sie, dass Megatron-DeepSpeed von BigScience auf der ursprünglichen Codebasis von Megatron-DeepSpeed basiert und wir einige Codes hinzugefügt haben.
Die folgende Tabelle listet auf, welche Komponenten der beiden Frameworks wir beim Training von BLOOM verwenden:
| Komponenten | Tiefgeschwindigkeit | Megatron-LM |
|---|---|---|
| ZeRO Datenparallel | Ja | |
| Tensorparallel | Ja | |
| Pipeline parallel | Ja | |
| BF16-Optimierer | Ja | |
| CUDA-Fusion-Kernel-Funktion | Ja | |
| Datenlader | Ja |
Beachten Sie, dass sowohl Megatron-LM als auch DeepSpeed parallelisierte Implementierungen für Parallelität und BF16-Optimierer haben, aber wir verwenden die Implementierung von DeepSpeed, da sie in ZeRO integriert sind.
Megatron-DeepSpeed erreicht 3D-Parallelität, um große Modelle auf sehr effiziente Weise trainieren zu können. Lassen Sie uns kurz besprechen, was 3D-Komponenten sind.
- Datenparallelität (DP) – Dasselbe Setup und Modell werden mehrfach repliziert, wobei jedes Mal eine andere Kopie der Daten zugeführt wird. Die Verarbeitung erfolgt parallel, wobei alle Freigaben am Ende jedes Trainingsschritts synchronisiert werden.
- Tensor-Parallelität (TP) – Jeder Tensor ist in Blöcke aufgeteilt, sodass sich jeder Abschnitt des Tensors auf seiner zugewiesenen GPU befindet, anstatt dass sich der gesamte Tensor auf einer einzelnen GPU befindet. Während der Verarbeitung wird jeder Shard separat und parallel auf einer anderen GPU verarbeitet, und die Ergebnisse werden am Ende des Schritts synchronisiert. Dies wird als horizontale Parallelität bezeichnet, da dies horizontal erfolgt.
- Pipeline-Parallelität (PP) – Das Modell wird vertikal (dh nach Schicht) auf mehrere GPUs aufgeteilt, sodass nur eine oder mehrere Modellschichten auf einer einzelnen GPU platziert werden. Jede GPU verarbeitet verschiedene Stufen der Pipeline parallel und verarbeitet einen Teil des Stapels.
- Zero Redundancy Optimizer (ZeRO) – führt auch Tensor-Sharding ähnlich wie TP durch, aber der gesamte Tensor wird rechtzeitig für die Vorwärts- oder Rückwärtsberechnung neu erstellt, sodass keine Modelländerungen erforderlich sind. Es unterstützt auch verschiedene Offloading-Techniken, um den begrenzten GPU-Speicher auszugleichen.
Datenparallelität
Die meisten Benutzer mit nur wenigen GPUs sind wahrscheinlich mit DistributedDataParallel(DDP) vertraut, der entsprechenden PyTorch-Dokumentation . Bei diesem Ansatz werden die Modelle vollständig auf jede GPU repliziert, und dann synchronisieren alle Modelle ihre Zustände nach jeder Iteration miteinander. Diese Methode kann das Training beschleunigen und Probleme lösen, indem mehr GPU-Ressourcen investiert werden. Aber es hat die Einschränkung, dass es nur funktioniert, wenn das Modell auf eine einzelne GPU passt.
ZeRO Datenparallel
Das folgende Diagramm zeigt schön die ZeRO-Datenparallelität (aus diesem Blogbeitrag ).
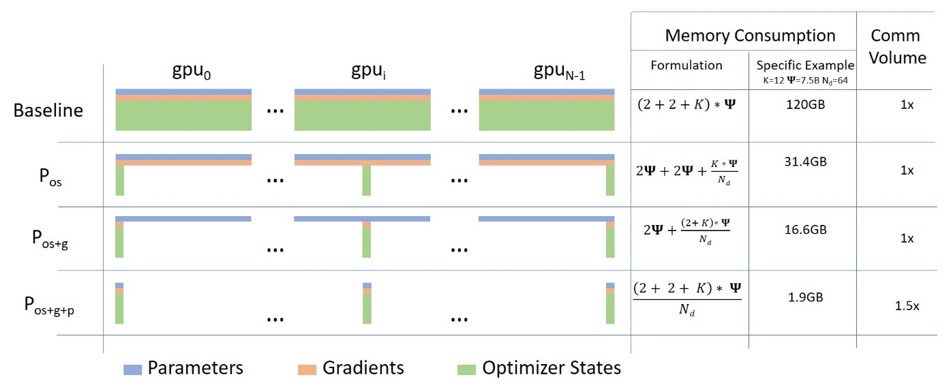
Es scheint relativ groß zu sein, was es für Sie schwierig machen kann, sich auf das Verständnis zu konzentrieren, aber tatsächlich ist das Konzept sehr einfach. Dies ist nur das übliche DDP, außer dass jede GPU nicht die vollständigen Modellparameter, Gradienten und den Optimiererstatus repliziert, sondern jede GPU nur einen Teil davon speichert. Wenn bei nachfolgenden Läufen die vollständigen Layer-Parameter für einen bestimmten Layer erforderlich sind, synchronisieren sich alle GPUs, um sich gegenseitig mit ihren fehlenden Teilen zu versorgen – mehr nicht.
Diese Komponente wird von DeepSpeed implementiert.
Tensorparallel
Bei der Tensorparallelität (TP) verarbeitet jede GPU nur einen Teil eines Tensors, und Aggregationsvorgänge werden nur ausgelöst, wenn bestimmte Operatoren den vollständigen Tensor benötigen.
In diesem Abschnitt verwenden wir Konzepte und Diagramme aus dem Megatron-LM -Papier Efficient Large-Scale Language Model Training on GPU Clusters .
Die Hauptmodule des Transformer-Klassenmodells sind: eine vollständig verbundene Schicht, nn.Lineargefolgt von einer nichtlinearen Aktivierungsschicht GeLU.
Der Notation aus dem Megatron-Papier folgend, können wir den Skalarproduktteil schreiben als Y = GeLU (XA), wobei Xund Ydie Eingabe- und Ausgabevektoren sind Aund die Gewichtsmatrix ist.
Es ist leicht zu sehen, wie die Matrixmultiplikation auf mehrere GPUs aufgeteilt werden kann, wenn sie in Matrixform ausgedrückt wird:
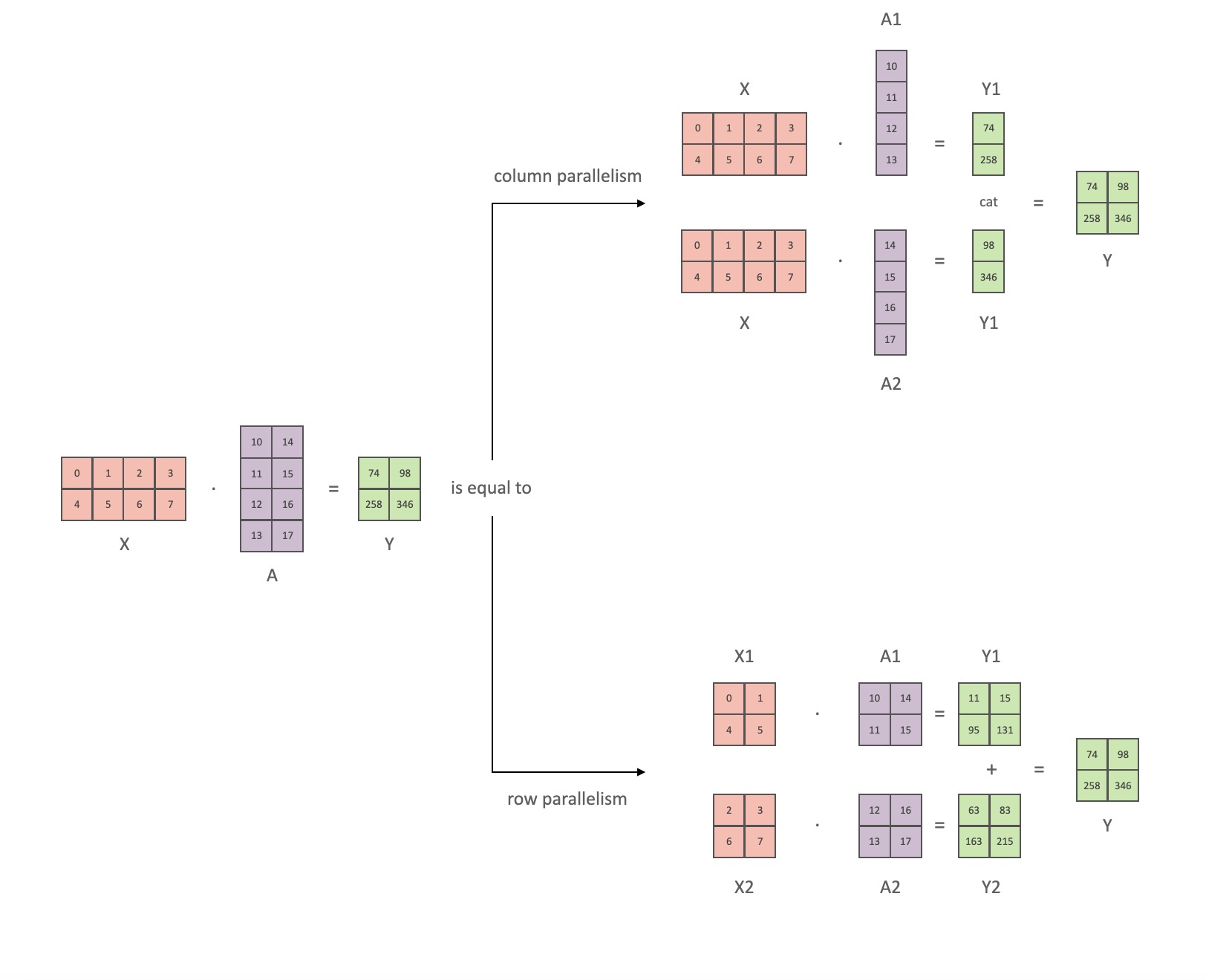
Wenn wir die Gewichtsmatrizen Aspaltenweise Nauf GPUs aufteilen und dann XA_1parallel XA_n, dann erhalten wir am NEnde Ausgabevektoren Y_1、Y_2、…… 、 Y_n, die unabhängig voneinander gefüttert werden können GeLU:
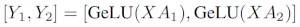
Beachten Sie, dass wir, da Ydie Matrix spaltenweise aufgeteilt ist, das zeilenweise Aufteilungsschema für das nachfolgende GEMM auswählen können, sodass es ohne zusätzliche Kommunikation direkt die Ausgabe der GeLU der vorherigen Schicht erhalten kann.
Mit diesem Prinzip können wir ein MLP beliebiger Tiefe aktualisieren, indem wir einfach die GPU nach jeder 拆列 - 拆行Sequenz . Die Autoren des Megatron-LM-Papiers liefern dafür eine schöne Illustration:
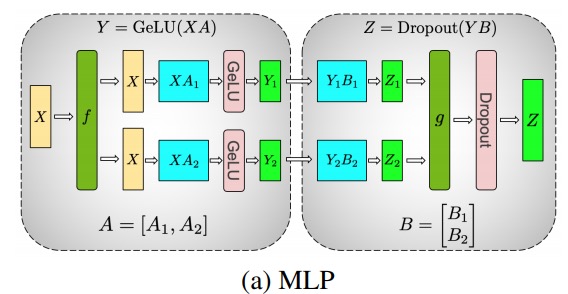
Hier fist der Identitätsoperator im Vorwärtsdurchlauf und alle Reduktionen im Rückwärtsdurchlauf, und gist der Identitätsoperator im Vorwärtsdurchlauf und die Identität im Rückwärtsdurchlauf.
Das Parallelisieren von Aufmerksamkeitsschichten mit mehreren Köpfen ist sogar noch einfacher, da sie aufgrund mehrerer unabhängiger Köpfe von Natur aus parallel sind!
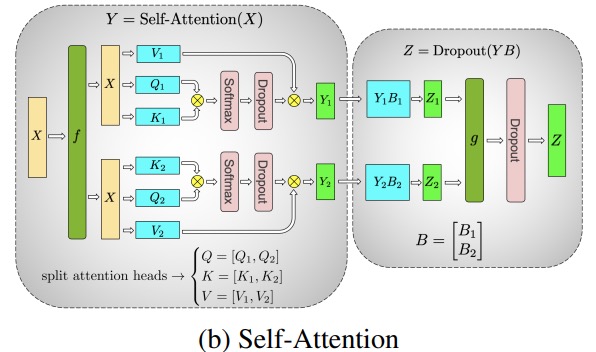
Besondere Überlegungen: Da es zwei All-Reduces pro Schicht in den Vorwärts- und Rückwärtsdurchgängen gibt, erfordert TP sehr schnelle Verbindungen zwischen Geräten. Daher ist es nicht empfehlenswert, TP über mehrere Knoten hinweg durchzuführen, es sei denn, Sie haben ein sehr schnelles Netzwerk. In unserer Hardwarekonfiguration für das Training von BLOOM ist die Geschwindigkeit zwischen Knoten viel langsamer als bei PCIe. Wenn der Knoten 4 GPUs hat, ist ein maximaler TP-Grad von 4 besser. Wenn Sie einen TP-Grad von 8 benötigen, müssen Sie einen Knoten mit mindestens 8 GPUs verwenden.
Diese Komponente wird von Megatron-LM implementiert. Megatron-LM hat kürzlich die Tensor-Parallelfähigkeit erweitert und die Fähigkeit der Sequenzparallelität für Operatoren hinzugefügt, die den oben genannten Segmentierungsalgorithmus, wie LayerNorm, nur schwer verwenden können. Einzelheiten zu dieser Technik finden Sie im Artikel Reducing Activation Recomputation in Large Transformer Models . Die Sequenzparallelität wurde nach dem Training von BLOOM entwickelt, daher wurde BLOOM ohne diese Technik trainiert.
Pipeline parallel
Naive Pipeline-Parallelität (naive PP) besteht darin, Modellschichten in Gruppen über mehrere GPUs zu verteilen und Daten einfach von GPU zu GPU zu verschieben, als wäre es eine große zusammengesetzte GPU. Der Mechanismus ist relativ einfach – Sie binden die gewünschte Schicht mit .to()der Methode , und jetzt, wenn Daten in diese Schichten eintreten oder diese verlassen, schalten die Schichten die Daten auf dasselbe Gerät wie die Schicht um, und der Rest bleibt gleich.
Dies ist eigentlich eine vertikale Modellparallelität, denn wenn Sie sich daran erinnern, wie wir die Topologie der meisten Modelle zeichnen, teilen wir die Schichten des Modells tatsächlich vertikal auf. Wenn das Bild unten beispielsweise ein 8-Schichten-Modell zeigt:
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
Wir schneiden es vertikal in zwei Teile und platzieren die Schichten 0-3 auf GPU0 und die Schichten 4-7 auf GPU1.
Wenn nun Daten von Schicht 0 zu Schicht 1, von Schicht 1 zu Schicht 2 und von Schicht 2 zu Schicht 3 übertragen werden, ist dies genau wie beim normalen Weiterleiten auf einer einzelnen GPU. Aber wenn Daten von Schicht 3 zu Schicht 4 übertragen werden müssen, müssen sie von GPU0 zu GPU1 übertragen werden, was einen Kommunikations-Overhead mit sich bringt. Wenn sich die teilnehmenden GPUs auf demselben Rechenknoten befinden (z. B. dieselbe physische Maschine), ist die Übertragung sehr schnell, aber wenn sich die GPUs auf unterschiedlichen Rechenknoten befinden (z. B. mehrere Maschinen), kann der Kommunikationsaufwand viel größer sein.
Dann sind die Schichten 4 bis 5 bis 6 bis 7 wieder wie normale Modelle, und wenn Schicht 7 fertig ist, müssen wir normalerweise Daten an Schicht 0 zurücksenden, wo sich die Etiketten befinden (oder die Etiketten an die letzte Schicht senden). Jetzt kann der Verlust berechnet werden und der Optimierer kann verwendet werden, um die Parameter zu aktualisieren.
Frage:
- Warum wird diese Methode als naive Pipeline-Parallelität bezeichnet, und was sind ihre Nachteile? Hauptsächlich, weil das Schema alle bis auf eine GPU zu einem bestimmten Zeitpunkt im Leerlauf hat. Wenn Sie also 4 GPUs verwenden, vervierfachen Sie fast die Menge an Arbeitsspeicher auf einer einzelnen GPU, und andere Ressourcen (wie Rechenleistung) sind ziemlich nutzlos. Fügen Sie den Aufwand für das Kopieren von Daten zwischen Geräten hinzu. So können 4 6-GB-Karten parallel mit naiver Pipeline das gleiche Größenmodell wie 1 24-GB-Karte aufnehmen, die schneller trainiert, da sie keinen Datenübertragungs-Overhead hat. Wenn Sie jedoch beispielsweise eine 40-GB-Karte haben, aber ein 45-GB-Modell ausführen müssen, können Sie 4x 40-GB-Karten verwenden (was gerade ausreicht, da es auch Gradienten und Optimiererzustände gibt, die Videospeicher erfordern).
- Die gemeinsame Nutzung von Einbettungen erfordert möglicherweise das Hin- und Herkopieren zwischen GPUs. Die von uns verwendete Pipeline-Parallelität (PP) ist fast die gleiche wie die naive PP oben, aber sie löst das GPU-Leerlaufproblem, indem sie eingehende Stapel in Micros-Batches aufteilt und künstlich Pipelines erstellt, die es verschiedenen GPUs ermöglichen, gleichzeitig am Berechnungsprozess teilzunehmen.
Die folgende Abbildung stammt aus dem GPipe-Papier , der obere Teil stellt das naive PP-Schema dar und der untere Teil die PP-Methode:

Aus der unteren Hälfte der Abbildung ist leicht ersichtlich, dass PP weniger Totzone hat (was bedeutet, dass die GPU im Leerlauf ist), dh weniger "Blasen".
Der Parallelitätsgrad der beiden Schemata in der Abbildung beträgt 4, d. h. die Pipeline besteht aus 4 GPUs. Es gibt also vier Vorwärtspfade von F0, F1, F2 und F3 und dann den Rückwärtspfad von B3, B2, B1 und B0.
PP führt einen neuen zu optimierenden Hyperparameter namens 块 (chunks). Sie definiert, wie viele Datenblöcke sequentiell durch dieselbe Pipe-Ebene gesendet werden. In der unteren Hälfte der Abbildung sehen Sie beispielsweise chunks = 4. GPU0 führt den gleichen Vorwärtspfad auf den Chunks 0, 1, 2 und 3 (F0,0, F0,1, F0,2, F0,3) aus und wartet dann, bis die anderen GPUs ihre Arbeit beendet haben, bevor GPU0 wieder mit der Arbeit beginnt , execute der Rückwärtspfad für die Blöcke 3, 2, 1 und 0 (B0,3, B0,2, B0,1, B0,0).
Beachten Sie, dass dies konzeptionell dasselbe ist wie Gradientenakkumulationsschritte (GAS). PyTorch nennt es 块, und DeepSpeed nennt es GAS.
Denn 块PP führt das Konzept der Micro-Batches (MBS) ein. DP teilt die globale Stapelgröße in kleine Stapelgrößen auf, wenn also der DP-Grad 4 ist, wird die globale Stapelgröße 1024 in 4 kleine Stapelgrößen aufgeteilt, und jede kleine Stapelgröße ist 256 (1024/4). Und wenn 块die Zahl (oder GAS) 32 ist, haben wir am Ende eine Mikro-Batch-Größe von 8 (256/32). Jede Röhrchenstufe verarbeitet jeweils eine Mikrocharge.
Die Formel zur Berechnung der globalen Stapelgröße für die DP+PP-Einstellung lautet: mbs * chunks * dp_degree( 8 * 32 * 4 = 1024).
Gehen wir zurück und sehen uns das Bild noch einmal an.
Wenn Sie naives PP verwenden, landen chunks=1Sie bei naivem PP, das sehr ineffizient ist. Und bei sehr großen 块Stückzahlen landen Sie bei kleinen Mikrochargengrößen, die wahrscheinlich auch nicht sehr effizient sind. Daher muss man experimentieren, um 块die Zahl .
Das Diagramm zeigt, dass es „tote“ Zeitblasen gibt, die nicht parallelisiert werden können, da die letzte forwardStufe auf backwarddas Ende der Pipeline warten muss. Dann wird das Problem, die optimale 块Anzahl damit alle beteiligten GPUs eine hohe gleichzeitige Auslastung erreichen können, tatsächlich in die Minimierung der Anzahl von Blasen umgewandelt.
Dieser Scheduling-Mechanismus heißt 全前全后. Einige andere Optionen sind Tandem und Interleaved Tandem .
Während sowohl Megatron-LM als auch DeepSpeed ihre eigenen Implementierungen des PP-Protokolls haben, verwendet Megatron-DeepSpeed die DeepSpeed-Implementierung, da sie in andere Funktionen von DeepSpeed integriert ist.
Ein weiterer wichtiger Punkt hier ist die Größe der Word-Embedding-Matrix. Während Word-Embedding-Matrizen im Allgemeinen weniger Speicher benötigen als Transformer-Blöcke, benötigt die Embedding-Schicht im Fall von BLOOM mit einem Vokabular von 250.000 7,2 GB für bf16-Gewichte, verglichen mit nur 4,9 GB für den Transformer-Block. Daher mussten wir Megatron-Deepspeed dazu bringen, die Einbettungsschicht als Transformatorblock zu behandeln. Wir haben also eine Pipeline von 72 Stufen, von denen 2 dem Einbetten gewidmet sind (erste und letzte). Dadurch können wir den Speicherverbrauch der GPU ausgleichen. Wenn wir dies nicht tun würden, würden die ersten und letzten Stufen viel GPU-Speicher verbrauchen, und 95 % der GPU-Speichernutzung wären sehr gering, sodass das Training sehr ineffizient wäre.
DP+PP
Es gibt ein Bild im DeepSpeed Pipeline Parallel Tutorial , das zeigt, wie DP und PP kombiniert werden, wie unten gezeigt.
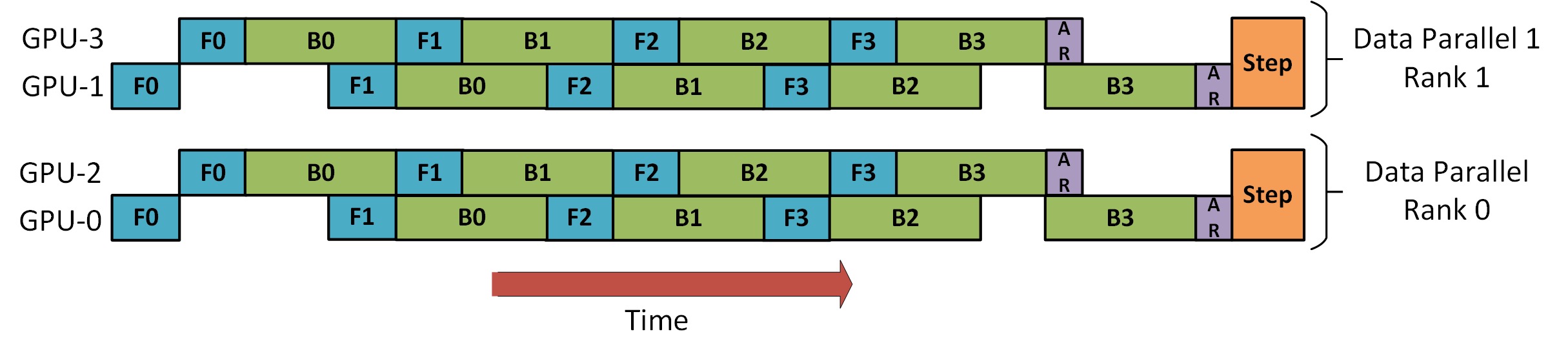
Es ist wichtig, hier zu verstehen, dass DP-Rang 0 GPU2 nicht sehen kann und DP-Rang 1 GPU3 nicht sehen kann. Für DP gibt es nur die GPUs 0 und 1, denen Daten zugeführt werden. GPU0 verwendet PP, um „heimlich“ einen Teil seiner Last auf GPU2 zu verlagern. Ebenso wird GPU1 auch Hilfe von GPU3 erhalten.
Da für jede Dimension mindestens 2 GPUs benötigt werden, sind hier mindestens 4 GPUs erforderlich.
DP+PP+TP
Für ein effizienteres Training können PP, TP und DP kombiniert werden, was als 3D-Parallelität bezeichnet wird, wie in der folgenden Abbildung gezeigt.
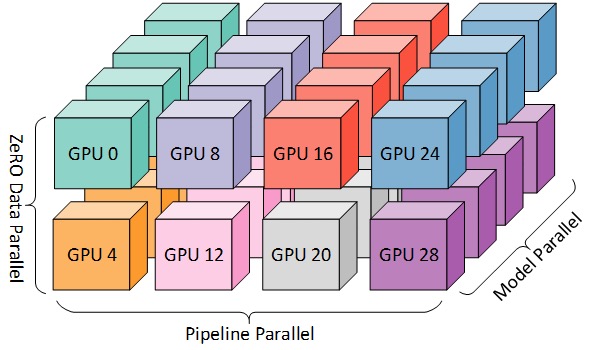
Diese Abbildung stammt aus dem Blog-Beitrag 3D Parallelism: Scaling to Trillion Parameter Models ), der ebenfalls ein guter Artikel ist.
Da Sie mindestens 2 GPUs pro Dimension benötigen, benötigen Sie hier mindestens 8 GPUs für volle 3D-Parallelität.
Null DP+PP+TP
Eines der Hauptmerkmale von DeepSpeed ist ZeRO, eine superskalierbare erweiterte Version von DP, die wir im Abschnitt [ZeRO Data Parallel] (#ZeRO- Data Parallel) besprochen haben. Normalerweise ist es eine unabhängige Funktion und erfordert weder PP noch TP. Es kann aber auch mit PP, TP kombiniert werden.
Wenn ZeRO-DP mit PP (und damit TP) kombiniert wird, aktiviert es normalerweise nur ZeRO-Phase 1, die nur den Optimiererzustand fragmentiert. ZeRO Stufe 2 fragmentiert auch Farbverläufe und Stufe 3 fragmentiert auch Modellgewichtungen.
Obwohl es theoretisch möglich ist, ZeRO Stufe 2 mit Pipeline-Parallelität zu verwenden, kann dies negative Auswirkungen auf die Leistung haben. Jeder Mikro-Batch erfordert eine zusätzliche Kommunikation zum Reduzieren der Streuung, um Gradienten vor dem Sharding zu aggregieren, was einen potenziell erheblichen Kommunikations-Overhead hinzufügt. Entsprechend der Parallelität der Pipeline werden wir kleine Mikrobatches verwenden und uns auf den Kompromiss zwischen arithmetischer Intensität (Mikrobatchgröße) und Minimierung von Pipelineblasen (Anzahl der Mikrobatches) konzentrieren. Daher schadet der erhöhte Kommunikationsaufwand der Pipeline-Parallelität.
Außerdem ist die Anzahl der Schichten aufgrund von PP bereits geringer als normal, sodass nicht viel Speicherplatz gespart wird. PP hat die Gradientengröße reduziert 1/PP, sodass der Gradientenschnitt auf dieser Basis im Vergleich zu reinem DP nicht viel Speicherplatz spart.
ZeRO stage 3 kann auch zum Trainieren von Modellen dieser Größe verwendet werden, erfordert jedoch parallel mehr Kommunikation als DeepSpeed 3D. Vor einem Jahr stellten wir nach sorgfältiger Bewertung unserer Umgebung fest, dass die Megatron-DeepSpeed-3D-Parallelität am besten abschneidet. Die Leistung von ZeRO Phase 3 hat sich seitdem erheblich verbessert, und wenn wir es heute neu bewerten würden, würden wir uns vielleicht für Phase 3 entscheiden.
BF16-Optimierer
Das Training riesiger LLM-Modelle mit FP16 ist ein No-Go.
Wir haben dies selbst demonstriert , indem wir das 104B-Modell monatelang trainiert , was, wie Sie auf Tensorboard sehen können , völlig versagt hat. Im Kampf gegen den immer weiter auseinander gehenden Filmverlust haben wir viel gelernt:
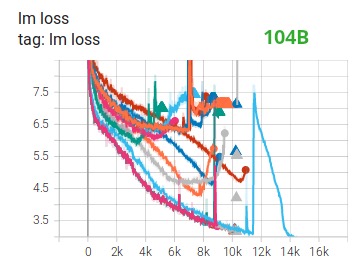
Wir haben auch den gleichen Vorschlag von den Teams Megatron-LM und DeepSpeed erhalten, nachdem sie das Modell 530B trainiert hatten . Der kürzlich veröffentlichte OPT-175B berichtete auch, dass er im FP16 sehr hart trainiert hat.
So wussten wir bereits im Januar, dass wir auf dem A100 trainieren würden, der das BF16-Format unterstützt. Olatunji Ruwase hat einen „BF16Optimizer“ für das Training von BLOOM entwickelt.
Wenn Sie mit diesem Datenformat nicht vertraut sind, sehen Sie sich sein . Der Schlüssel zum BF16-Format ist, dass es dieselbe Anzahl von Exponenten wie FP32 hat, sodass es nicht überläuft, aber FP16 läuft oft über! FP16 hat einen maximalen Wertebereich von 64k, man kann nur kleinere Zahlen multiplizieren. Zum Beispiel können Sie tun 250*250=62500, aber wenn Sie es versuchen 255*255=65025, werden Sie überlaufen, was die Hauptursache für Probleme beim Training ist. Dies bedeutet, dass Ihre Gewichte klein gehalten werden müssen. Eine Technik namens Verlustskalierung hilft, dieses Problem zu lindern, aber die kleine Reichweite von FP16 kann immer noch ein Problem sein, wenn Modelle sehr groß werden.
Der BF16 hat dieses Problem nicht, das geht problemlos 10_000*10_000=100_000_000, überhaupt kein Problem.
Da BF16 und FP16 die gleiche Größe haben, 2 Bytes, gibt es natürlich kein kostenloses Mittagessen, und der Nachteil bei der Verwendung von BF16 ist, dass es eine sehr schlechte Genauigkeit hat. Sie sollten jedoch bedenken, dass die stochastische Gradientenabstiegsmethode und ihre Varianten, die wir im Training verwendet haben, diese Methode ein bisschen wie Staffeln ist. Wenn Sie in diesem Schritt nicht die perfekte Richtung finden, ist das in Ordnung, Sie werden sie im nächsten korrigieren Schritt Eigen.
Unabhängig davon, ob Sie BF16 oder FP16 verwenden, gibt es immer eine Kopie der Gewichtungen in FP32 - diese wird vom Optimierer aktualisiert. Das 16-Bit-Format wird also nur für Berechnungen verwendet, der Optimierer aktualisiert die FP32-Gewichte mit voller Genauigkeit und konvertiert sie dann für die nächste Iteration in das 16-Bit-Format.
Alle PyTorch-Komponenten wurden aktualisiert, um sicherzustellen, dass sie keine Akkumulation in FP32 durchführen, sodass kein Präzisionsverlust auftritt.
Ein Schlüsselproblem ist die Gradientenakkumulation, die eines der Hauptmerkmale der Pipeline-Parallelität ist, da die von jedem Mikrobatch verarbeiteten Gradienten akkumuliert werden. Die Implementierung der Gradientenakkumulation in FP32 für die Trainingsgenauigkeit ist von entscheidender Bedeutung, und genau BF16Optimizerdas wurde getan .
Neben anderen Verbesserungen glauben wir, dass die Verwendung von BF16 Mixed-Precision-Training einen potenziellen Albtraum in einen relativ reibungslosen Prozess verwandelt hat, wie aus dem folgenden lm-Loss-Diagramm ersichtlich ist:
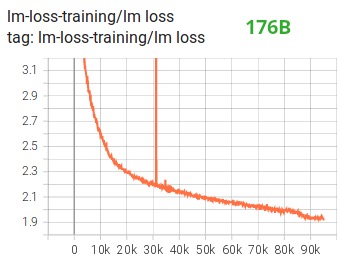
CUDA-Fusion-Kernel-Funktion
Die GPU macht hauptsächlich zwei Dinge. Es kann Daten in den Videospeicher schreiben und Daten daraus lesen und Berechnungen mit diesen Daten durchführen. Wenn die GPU damit beschäftigt ist, Daten zu lesen und zu schreiben, sind die Recheneinheiten der GPU im Leerlauf. Wenn wir die GPU effizient nutzen wollen, wollen wir die Leerlaufzeit auf ein Minimum reduzieren.
Eine Kernel-Funktion ist ein Satz von Anweisungen, die eine bestimmte PyTorch-Operation implementieren. torch.addWenn Sie beispielsweise aufrufen , durchläuft es einen PyTorch-Scheduler , der anhand der Werte der Eingabetensoren und anderer Variablen entscheidet, welchen Code er ausführen soll, und führt ihn schließlich aus. CUDA-Kernel verwenden CUDA, um diese Codes zu implementieren und laufen daher nur auf NVIDIA-GPUs.
c = torch.add (a, b); e = torch.max ([c,d])Wenn Sie jetzt die GPU zum Berechnen von verwenden , startet PyTorch normalerweise zwei separate Kernel, einen, der die Addition avon bund durchführt, cund den anderen, der das Maximum von dbeiden . In diesem Fall aholt bdie Summe aus ihrem Videospeicher, führt die Addition durch und schreibt dann das Ergebnis zurück in den Videospeicher. Es nimmt dann cund dund führt maxdie Operation und schreibt das Ergebnis wieder zurück in den Videospeicher.
Wenn wir diese beiden Operationen fusionieren, d. h. sie in eine "fusionierte Kernel-Funktion" stecken und dann diesen Kernel starten würden, anstatt cdas Zwischenergebnis in den Videospeicher zu schreiben, würden wir es in GPU-Registern behalten dtun die Schlussrechnung. Dies spart viel Overhead und verhindert, dass die GPU im Leerlauf ist, sodass der gesamte Vorgang viel effizienter ist.
Die Fusion-Kernel-Funktion macht genau das. Sie ersetzen in erster Linie mehrere diskrete Berechnungen und Datenbewegungen zum und vom Videospeicher durch verschmolzene Berechnungen mit sehr geringer Datenbewegung. Darüber hinaus wandeln einige Fusionskerne Operationen mathematisch um, sodass bestimmte Kombinationen von Berechnungen schneller durchgeführt werden können.
Um BLOOM schnell und effizient zu trainieren, ist es notwendig, mehrere benutzerdefinierte CUDA-Fused-Kernel-Funktionen zu verwenden, die von Megatron-LM bereitgestellt werden. Insbesondere gibt es einen LayerNorm-Fusionskernel und Kernel für verschiedene Kombinationen von Fusionsskalierung, Maskierung und Softmax-Operationen. Bias Add ist außerdem über die JIT-Funktion von PyTorch in GeLU integriert. Diese Operationen sind alle speichergebunden, daher ist es wichtig, sie miteinander zu verschmelzen, um den Rechenaufwand nach jedem Lesen des Videospeichers zu maximieren. So erhöht beispielsweise die Ausführung von Bias Add während der Ausführung einer GeLU-Operation, deren Engpass im Arbeitsspeicher liegt, die Laufzeit nicht. Diese Kernel-Funktionen sind in der Megatron-LM-Code-Bibliothek zu finden .
Datensatz
Ein weiteres wichtiges Merkmal von Megatron-LM ist der effiziente Datenlader. Bevor das erste Training beginnt, wird jedes Sample in jedem Dataset in Samples mit fester Sequenzlänge (BLOOM ist 2048) unterteilt, und es wird ein Index erstellt, um jedes Sample zu nummerieren. Basierend auf den Trainings-Hyperparametern bestimmen wir die Anzahl der Epochen, an denen jeder Datensatz teilnehmen muss, und erstellen basierend darauf eine geordnete Liste von Beispielindizes und mischen sie dann. Wenn ein Datensatz beispielsweise 10 Stichproben enthält, die für 2 Epochen trainiert werden sollen, sortiert das System zuerst die Stichprobenindizes in [0, ..., 9, 0, ..., 9]der Reihenfolge mischt dann die Reihenfolge, um die endgültige globale Reihenfolge für den Datensatz zu erstellen. Beachten Sie, dass dies bedeutet, dass das Training nicht einfach über den gesamten Datensatz iteriert und wiederholt, Sie sehen möglicherweise dieselbe Probe zweimal, bevor Sie eine andere sehen, aber am Ende des Trainings sieht das Modell jede Probe nur zweimal Zweitklassig. Dies trägt zu einer reibungslosen Trainingskurve während des gesamten Trainings bei. Diese Indizes, einschließlich des Offsets jedes Samples im ursprünglichen Datensatz, werden in einer Datei gespeichert, um zu vermeiden, dass sie jedes Mal neu berechnet werden, wenn das Training gestartet wird. Schließlich können mehrere dieser Datensätze mit unterschiedlichen Gewichtungen in die endgültigen Daten für das Training gemischt werden.
LayerNorm einbetten
Bei unseren Bemühungen, die Divergenz des 104B-Modells zu verhindern, stellten wir fest, dass das Hinzufügen einer zusätzlichen LayerNorm nach der ersten Worteinbettungsschicht das Training stabiler machte.
Diese Erkenntnis stammt aus Experimenten mit bitsandbytes , die eine Operation haben, die eine normale Einbettung mit einer LayerNorm ist, die mit einer einheitlichen xavier-Funktion initialisiert wird.StableEmbedding
Standortcode
Basierend auf dem Artikel Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation ersetzen wir auch die normalen Positionseinbettungen durch AliBi, was die Extrapolation von Eingabesequenzen ermöglicht, die länger sind als die zum Trainieren des Modells verwendeten Eingabesequenzen. Daher kann das Modell, obwohl wir mit Sequenzen der Länge 2048 trainieren, längere Sequenzen während der Inferenz verarbeiten.
Schwierigkeiten im Training
Mit der vorhandenen Architektur, Hardware und Software konnten wir Anfang März 2022 mit der Schulung beginnen. Seitdem läuft aber nicht alles rund. In diesem Abschnitt diskutieren wir einige der Haupthindernisse, auf die wir gestoßen sind.
Bevor das Training beginnt, gibt es viele Fragen zu klären. Insbesondere haben wir mehrere Probleme festgestellt, die erst auftraten, nachdem wir mit dem Training auf 48 Knoten begonnen hatten, nicht in kleinen Maßstäben. CUDA_LAUNCH_BLOCKING=1Um beispielsweise ein Hängenbleiben des Frameworks zu verhindern, müssen wir die Optimizer-Gruppe in kleinere Gruppen aufteilen, sonst bleibt das Framework wieder hängen. Sie können mehr darüber in den Pre-Training Chronicles lesen.
Die Hauptprobleme, die während des Trainings auftreten, sind Hardwarefehler. Da es sich um einen neuen Cluster mit etwa 400 GPUs handelt, kommt es im Durchschnitt zu 1-2 GPU-Ausfällen pro Woche. Wir speichern alle 3 Stunden einen Checkpoint (100 Iterationen). Dadurch gehen uns durchschnittlich 1,5 Stunden Training pro Woche durch Hardwareabstürze verloren. Der Systemadministrator von Jean Zay ersetzt dann die fehlerhafte GPU und stellt den Knoten wieder her. In der Zwischenzeit haben wir freie Nodes zur Verfügung.
Wir hatten auch verschiedene andere Probleme, die mehrmals zu 5-10-stündigen Ausfallzeiten führten, einige im Zusammenhang mit Deadlock-Fehlern in PyTorch, andere aufgrund von unzureichendem Speicherplatz. Wenn Sie an Einzelheiten interessiert sind, sehen Sie sich die .
All diese Ausfallzeiten wurden in der Machbarkeitsanalyse zum Trainieren dieses Modells eingeplant, und wir wählten die geeignete Modellgröße und die Datenmenge, die das Modell entsprechend verbrauchen sollte. Trotz dieser Ausfallzeiten konnten wir die Schulung also innerhalb der geschätzten Zeit abschließen. Wie bereits erwähnt, dauert die Fertigstellung etwa 1 Million Rechenstunden.
Ein weiteres Problem besteht darin, dass SLURM nicht für die Verwendung durch eine Gruppe von Personen konzipiert wurde. SLURM-Jobs gehören einem einzelnen Benutzer, und wenn sie nicht in der Nähe sind, können andere Mitglieder der Gruppe nichts mit dem laufenden Job anfangen. Wir haben ein Beendigungsschema, das es anderen Benutzern in der Gruppe ermöglicht, den aktuellen Prozess zu beenden, ohne dass der Benutzer anwesend ist, der den Prozess gestartet hat. Das funktioniert bei 90 % der Probleme hervorragend. Wenn die SLURM-Designer dies lesen, fügen Sie bitte das Konzept einer Unix-Gruppe hinzu, damit ein SLURM-Job Eigentum einer Gruppe sein kann.
Da das Training rund um die Uhr läuft, brauchen wir jemanden auf Abruf – aber da wir Mitarbeiter in Europa und an der Westküste Kanadas haben, ist es nicht erforderlich, dass jemand einen Pager trägt, und wir sind ziemlich gut darin, uns gegenseitig zu unterstützen. Natürlich muss das Wochenendtraining angeschaut werden. Wir automatisieren die meisten Dinge, einschließlich der automatischen Wiederherstellung nach Hardwareabstürzen, aber manchmal ist dennoch menschliches Eingreifen erforderlich.
abschließend
Der schwierigste und stressigste Teil des Trainings sind die 2 Monate vor Trainingsbeginn. Wir standen unter großem Druck, so schnell wie möglich mit dem Training zu beginnen, und aufgrund der begrenzten Zeit, die uns die Ressourcen zur Verfügung stellten, erhielten wir erst in letzter Minute Zugang zum A100. Es war also eine sehr schwierige Zeit, wenn man bedenkt BF16Optimizer, dass es in letzter Minute geschrieben wurde , wir mussten es debuggen und verschiedene Fehler beheben. Wie im vorherigen Abschnitt erwähnt, haben wir neue Probleme gefunden, die erst auftraten, nachdem wir mit dem Training auf 48 Knoten begonnen hatten, und nicht in kleinen Maßstäben.
Aber als wir das geklärt hatten, verlief das Training selbst überraschend reibungslos ohne größere Probleme. Meistens schaut nur einer von uns zu und nur wenige Personen sind an der Fehlerbehebung beteiligt. Wir hatten eine großartige Unterstützung durch das Management von Jean Zay, das sich umgehend um die meisten Bedürfnisse kümmerte, die während des Trainings auftauchten.
Insgesamt war es eine super intensive, aber lohnende Erfahrung.
Das Trainieren großer Sprachmodelle bleibt eine herausfordernde Aufgabe, aber wir hoffen, dass andere durch den Aufbau und die öffentliche Verbreitung dieser Technik aus unserer Erfahrung lernen können.
Ressource
wichtige Verbindungen
Aufsätze und Artikel
Es ist uns unmöglich, in diesem Artikel alles im Detail zu erklären, also wenn die hier vorgestellten Techniken Ihre Neugier wecken und Sie Lust darauf machen, mehr zu erfahren, lesen Sie bitte die folgenden Artikel:
Megatron-LM:
- Effizientes groß angelegtes Sprachmodelltraining auf GPU-Clustern .
- Reduzierung der Aktivierungsneuberechnung in großen Transformatormodellen
Tiefgeschwindigkeit:
- ZeRO: Speicheroptimierungen für das Training von Billionen Parametermodellen
- ZeRO-Offload: Modelltraining im Milliardenbereich demokratisieren
- ZeRO-Infinity: Durchbrechen der GPU-Speichermauer für Deep Learning im extremen Maßstab
- DeepSpeed: Modelltraining im Extremmaßstab für jedermann
Megatron-LM und Deepspeedeed kombiniert:
Alibi:
- Trainieren Sie kurz, testen Sie lang: Aufmerksamkeit mit linearen Verzerrungen ermöglicht Extrapolation der Eingabelänge
- Welches Sprachmodell trainieren, wenn Sie eine Million GPU-Stunden haben? - Dort finden Sie die Experimente, die uns letztendlich dazu veranlasst haben, uns für ALiBi zu entscheiden.
BitsNBytes:
- 8-Bit-Optimierer über blockweise Quantisierung (wir haben in diesem Papier die Einbettung von LaynerNorm verwendet, aber andere Teile des Papiers und seine Techniken sind auch sehr gut, der einzige Grund, warum wir keine 8-Bit-Optimierer verwendet haben, ist, dass wir sie bereits verwendet haben DeepSpeed-ZeRO, um Optimiererspeicher zu sparen).
Blogbeitrag danke
Vielen Dank an die folgenden Personen, die gute Fragen gestellt und dazu beigetragen haben, die Lesbarkeit des Artikels zu verbessern (in alphabetischer Reihenfolge):
- Britney Müller,
- Douwe Kiela,
- Jared Kasper,
- Jeff Rasley,
- Julien Launay,
- Leandro von Werra,
- Omar Sanseviero,
- Stefan Schweter and
- Thomas Wang.
Die Diagramme in diesem Artikel wurden hauptsächlich von Chunte Lee erstellt.
Englischer Originaltext: https://hf.co/blog/bloom-megatron-deepspeed
Ursprünglicher Autor: Stas Bekman
Übersetzer: Matrix Yao (Yao Weifeng), ein Deep-Learning-Ingenieur von Intel, arbeitet an der Anwendung von Transformer-Familienmodellen auf verschiedene modale Daten und dem Training und der Argumentation von großen Modellen.
Korrekturlesen und Satz: zhongdongy (Adong)