속도 제한기는 매우 기본적인 네트워크 패킷 처리 기능으로 다양한 네트워크 요소 장치에서 널리 사용되며 트래픽 스케줄링, 네트워크 보안 및 기타 분야에서 중요한 역할을 합니다. 일반적인 속도 제한기는 토큰 버킷을 기반으로 구현되며 토큰 버킷의 원리는 잘 알려져 있지만 실제로는 몇 가지 문제와 일반적인 문제도 발견했습니다. 이 기사는 지난 2년 동안 속도 제한기 최적화에 대한 Bytedance 시스템 및 기술 엔지니어링 팀(STE 팀이라고 함)의 일부 탐색을 요약하고 독자를 위한 몇 가지 경험과 교훈을 요약합니다.
Token Bucket Rate Limiter의 기본 원리
네트워크 패킷 처리를 작성하는 모든 엔지니어는 기본 토큰 버킷 속도 제한기를 작성했다고 생각합니다. 토큰 버킷은 생생한 설명입니다.특정 양의 토큰을 보관할 수 있는 버킷이 있다고 상상할 수 있습니다.데이터 패킷이 릴리스될 때마다 일정량의 토큰이 소비됩니다.데이터 패킷이 릴리스되는지 또는 토큰 버킷에 따라 달라지지 않습니다. 의 토큰 수입니다.

그림 1 토큰 버킷 다이어그램
예를 들어 토큰 버킷 제한이 PPS(Packet Per Second)인 경우 토큰이 데이터 패킷을 나타낸다고 가정합니다. 그러면 PPS를 300K/s로 제한하는 속도 제한기가 초당 300K 토큰을 생성합니다. 이 속도 제한기를 통과하는 모든 데이터 패킷은 토큰을 소비하며 토큰이 0으로 소비되면 패킷을 폐기합니다.
\(P_t \)가 도착 시간이 \(t\) 인 패킷을 나타내고 데이터 패킷이 토큰 버킷에 전달되는 시간을 \(t' \) 라고 가정하면 이 기간 동안 토큰 버킷은 다음을 생성합니다. 토큰 수:
\((t - t') * 비율\)
토큰 버킷에 남아 있는 토큰 버킷의 수는 \(T \) 이고 \(P_t \)가 도착하면 토큰 버킷의 토큰은 다음과 같습니다 .
\((t - t') * 비율 + T\)
토큰 버킷에는 용량이 있으며, 위 공식의 값은 토큰 버킷의 용량을 초과할 수 있습니다 . \ (버스트 \) 와 같습니다 .
이때 데이터 패킷 \(P_t\) 는 통과해야 하기 때문에 토큰 1개를 소비해야 하므로 토큰 버킷의 타임스탬프를 \(t' \) 로 업데이트 하고 토큰 버킷의 토큰 수를 업데이트합니다. 위의 계산에. 계산을 통해 생성된 토큰의 수가 소비량을 초과하면 데이터 패킷을 해제하고, 그렇지 않으면 데이터 패킷을 폐기해야 합니다.
일부 사람들은 토큰 버킷의 용량이 제한된 이유와 가장 큰 용량의 이름이 \(Burst\) 인 이유를 궁금해할 수 있습니다. 이는 실제로 토큰 버킷이 특정 시간 창에서 속도가 제한 값을 초과하도록 허용하기 때문입니다. 300Kpps 속도 제한기를 예로 들어 \(Burst\) 가 300K이고 현재 토큰 버킷이 가득 찼다고 가정하면 300K 패킷이 100ms 이내에 들어오더라도 토큰 버킷은 모든 데이터 패킷을 해제합니다( 토큰 버킷의 토큰 수가 충분하기 때문에) 이 100ms 내에서 실제 속도는 300Kpps가 아니라 3Mpps입니다. 이름에서 알 수 있듯이 토큰 버킷의 용량은 실제로 허용되는 버스트 속도를 제한합니다.
실제로 토큰 버킷은 구현이 간단하고 효율성이 높은 특성을 가지고 있으며 많은 시나리오에서 속도 제한 장치는 기본적으로 토큰 버킷과 동의어입니다.
기존 문제
특정 프로젝트 시간 동안 다음 세 가지 문제에 직면했습니다.
1. 정확도 문제
실제 엔지니어링 실무에서 시간 측정 단위는 실제로 시스템에 의해 제한됩니다.예를 들어 타임 스탬프는 마이크로초(us)일 수 있으며 각 계산 간의 시간 차이는 1~2us일 수 있습니다. 그러면 PPS=300K인 속도 제한기가 한 번에 계산될 수 있으며 생성된 토큰은 정수 연산으로 쉽게 무시되는 0.3입니다. 최종 결과는 실제 제한이 300K/s이고 최종 효과는 250Kpps 트래픽만 허용된다는 것입니다. 정확도가 너무 낮고 효과가 이상적이지 않습니다.
이 솔루션도 비교적 간단하며 데이터 패킷이 소비하는 토큰의 양은 1이 아니라 1000이 될 수 있습니다. 이렇게 하면 1us라도 토큰 버킷에서 생성되는 토큰의 개수가 0.3개가 아니라 300개가 되어 정확도가 보장됩니다. 그런데 이때 토큰의 개수가 1000배로 늘어나서 새로운 문제가 발생했고, 토큰 버킷의 깊이가 32비트를 넘을지 여부를 고려해야 합니다. 넘치면 다른 이상한 문제가 나타납니다.
2. 캐스케이드 보상 문제

그림 2 속도 제한기 캐스케이드 보상
우리는 여러 속도 제한 장치가 계단식으로 연결될 때 보상 토큰이 필요하다는 사실을 실제로 발견했습니다. 예를 들어, 속도 제한기 A의 경우 이 패킷이 해제되고 A의 토큰을 소비합니다. 속도 제한기 B의 경우 B에 토큰이 없기 때문에 이 패킷이 삭제됩니다. 이 시점에서 패킷이 손실됩니다. 그러면 이때 A의 토큰은 헛되이 소비됩니다. 즉, 토큰이 소비되고 패킷은 여전히 손실됩니다. 정확한 속도 제한 효과를 얻으려면 속도 제한 장치 A의 토큰을 보상해야 합니다. 그림 2와 같이.
계단식 보상은 여러 개의 속도 제한기를 서로 결합하게 만들고 코드 작성에서 더 번거롭습니다. 우리는 실제로 속도 제한기 A와 속도 제한기 B의 속도 제한 값이 가깝고 둘 다 패킷 손실이 있는 경우 캐스케이드 보상 부족이 정확도에 심각한 영향을 미친다는 것을 발견했습니다. 그러나 속도 제한 값이 멀리 떨어져 있으면 정확도에 미치는 영향은 그다지 크지 않습니다.
3. TCP는 패킷 손실에 민감합니다.
토큰 버킷에 캐시가 없으며 속도가 제한 값을 초과하면 패킷 손실이 발생합니다. TCP 프로토콜은 패킷 손실에 매우 민감하며 패킷 손실이 발생하면 TCP는 속도를 보다 적극적으로 조정합니다. 토큰 버킷의 특성상 TCP 트래픽에 적용할 때 100Mbps로 제한하는 경우가 많으며, 실제로는 지속적인 패킷 손실로 인해 TCP가 지속적으로 전송 창을 줄이기 때문에 최대 80Mbps까지만 실행될 수 있습니다.
vSwitch를 사용하는 경우 BPS(Bits Per Second) 속도 제한은 TCP에서 특히 큰 손실이 발생하는데 이는 일반 가상 네트워크 카드가 TSO(TCP Segmentation Offload) 최적화를 활성화했기 때문입니다. 호스트 패킷이 매우 크고 패킷이 64K 바이트일 수 있습니다.이렇게 큰 경우 몇 개의 패킷을 임의로 손실하면 TCP 속도에 미치는 영향은 매우 분명합니다.
첫 번째 개선: 포트 렌딩 배압 속도 제한기
우리는 실제로 캐스케이드 보상 피드백 문제가 존재하지만 그다지 눈에 띄지 않는다는 것을 발견했습니다.그 이유는 일반적인 캐스케이드 속도 제한기의 속도 제한 값이 매우 다르기 때문입니다.예를 들어 단일 네트워크 카드의 속도와 전체 기계의 속도는 일반적으로 큰 차이가 있으며 정밀도 문제가 발생하기 쉽지 않습니다. 가장 심각한 문제는 사용자 경험에 영향을 미치는 TCP 패킷 손실에 대한 민감도로 인해 속도 제한 대역폭에 도달할 수 없다는 것입니다. 그림 3에서 볼 수 있듯이 TCP RTT가 증가하면 실제 달성 가능한 대역폭은 분명히 감소합니다.
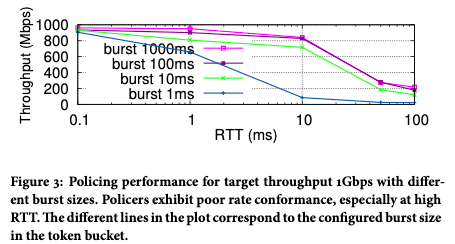
그림 3 트래픽이 1Gbps 속도 제한기를 통과한 후 얻은 실제 속도
배압은 TCP가 패킷 손실에 민감한 문제를 개선한 것입니다. 우리가 처음 디자인했을 때 우리는 실제로 특정 장면을 겨냥했습니다. 가상 머신의 가상 네트워크 카드 속도가 제한됩니다. 그리고 우리의 속도 제한기는 각 네트워크 카드에 특정 속도 제한기가 있다는 것입니다.
각 가상 네트워크 카드에는 여러 대기열이 있으며 vSwitch는 이러한 대기열을 지속적으로 폴링하여 보낼 데이터 패킷을 가져옵니다. 이러한 대기열은 기본적으로 패킷용 버퍼입니다. 사실 배압은 이러한 대기열의 폴링을 중지하거나 지연하고, 데이터 패킷이 대기열에 축적되도록 하고, 게스트 커널에 대한 압력을 피드백하는 목적을 달성하여 게스트 커널의 TCP 스택이 혼잡을 감지하고 보내는 리듬을 조정합니다.
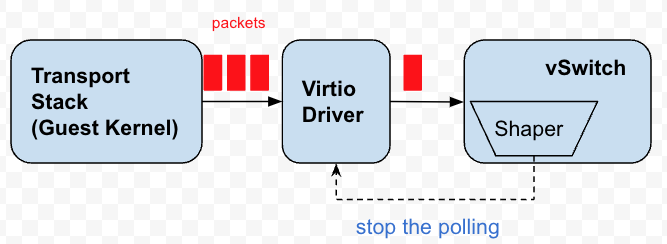
그림 4 배압 속도 제한기
배압 속도 제한기를 설계할 때 최종 구현에 영향을 미치는 제한 사항이 있었습니다.
가상 머신의 가상 네트워크 카드는 Peek 기능을 제공하지 않습니다. 즉, vSwitch는 데이터 패킷을 Peek만 할 뿐 실제로 데이터 패킷을 대기열에서 꺼내지는 않습니다. 이러한 제한으로 인해 "차용"이라는 개념을 사용하게 되었습니다. 둘 다 폴링을 시작할 권한 시점을 설정합니다. 현재 시간이 권한 시점을 초과하면 토큰이 충분한지 여부와 관계없이 큐에 있는 모든 데이터 패킷이 한 번에 전송됩니다. 토큰이 충분하면 문제는 없지만 토큰이 충분하지 않으면 미래에서 토큰을 빌려오는 것을 고려하고 미래 타임스탬프를 역으로 계산한 다음 이 타임스탬프 전에 vSwitch가 가상 네트워크 카드 폴링을 중지합니다.
대출 방법은 가상 머신 대기열에서 데이터 패킷 복사를 피하기 위해 처음에는 성능 고려 사항으로만 제안되었지만 토큰이 충분하지 않아 폐기해야 했습니다. 나는 그것을 버리고 싶지 않기 때문에 나는 단순히 토큰을 미래로 보냅니다.
지금 이 디자인을 되돌아 보면 Peek와 비교할 때 실제로 장점과 단점이 있습니다.
1) 매번 빌린 토큰의 양은 통제할 수 없습니다. 이로 인해 공정성 문제가 발생할 수 있습니다. 상류는 계속해서 대출자격을 획득하고, 소류는 굶어죽는 경향이 있으며, 속도 제한 경쟁에서는 한 쪽이 유리하면 우세한 쪽이 쉽게 계속해서 우위를 점하게 된다.
2) 엿보기보다 낮은 오버헤드로 간단한 타임스탬프 비교. 데이터 패킷을 엿볼 수 있으면 대출 메커니즘이 없고 폴링을 중지할 가능성이 없으며 대신 가상 대기열로 이동하여 매번 확인하지만 오버헤드가 약간 높습니다.
3) 반대로 엿보기 기능이 있는 경우 먼저 대기열에 있는 데이터 패킷의 백로그를 보고 대기열이 일정량의 데이터 패킷을 축적할 때까지 기다린 다음 다음 일괄 전송을 위한 타임스탬프를 계산할 수도 있습니다. 데이터 패킷 폴링을 중지합니다. 성능 향상을 위해 배치를 늘리는 데 좋습니다.
배압 속도 제한기는 가상 머신의 네트워크 카드 대기열을 배압하기 때문에 가상 머신의 나가는 데이터 패킷만 제한할 수 있지만 수신 방향에서 가상 머신의 트래픽은 제한할 수 없습니다. 이는 물리적 네트워크 카드의 데이터 패킷을 배압할 수 없기 때문입니다. 물리적 네트워크 카드의 데이터 패킷은 다른 가상 네트워크 카드로 전송될 수 있습니다. 각 네트워크 카드의 속도 제한 값이 다릅니다. 정확한 속도를 계산할 수 없습니다. 시점 이전에 패킷을 폴링할 필요가 없습니다. 또한 물리적 네트워크 카드의 큐가 가득 차면 패킷만 손실되고 가상 머신 네트워크 카드의 큐가 가득 차면 TCP 프로토콜 스택에 배압을 가할 수 있으므로 둘의 효과는 다릅니다.
따라서 인바운드 트래픽 제한 측면에서 타임 스탬프를 허용하는 아이디어를 계속합니다. 현재 시간이 허용 시간을 초과하면 모든 패킷이 해제되고 그렇지 않으면 모든 패킷이 폐기됩니다.
두 번째 개선: 캐러셀 속도 제한기
Carousel 속도 제한기는 SIGCOMM 17'의 논문에서 Google이 제안한 속도 제한기 알고리즘[2]입니다. 미만 타임 스탬프가 발행되면 일정 시간 동안 캐시됩니다. 즉, 패킷 손실 대신 데이터 패킷이 지연되어 전송됩니다.
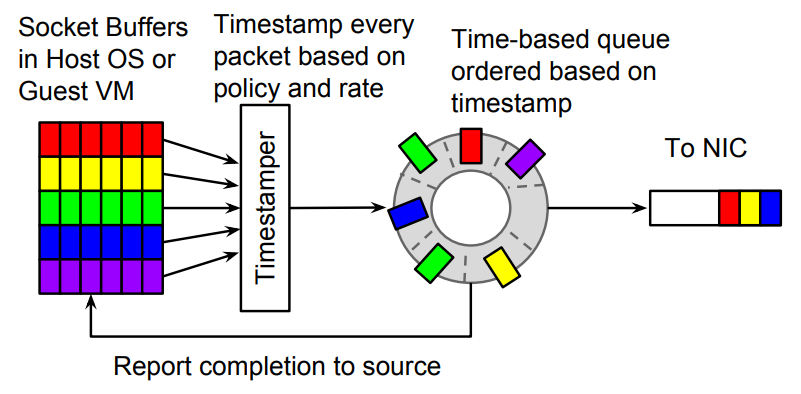
그림 5 회전식 속도 제한기
이 알고리즘의 기본 원리를 기반으로 OVS-DPDK에 유사한 속도 제한기를 구현했습니다. 알고리즘의 매개변수를 결정하는 프로세스에는 많은 세부 사항이 있습니다. 실제 사용되는 속도 제한기의 속도 범위는? 300Kpps입니까 아니면 3Mpps입니까? 이들은 알고리즘의 매개변수 설정을 직접 결정하며 자세한 내용은 설명하지 않습니다.
Carousel의 가장 큰 이점 중 하나는 캐싱의 도입입니다. 타임 휠의 본질은 캐시로 TCP 트래픽에 대한 명백한 이점이 있으며 동시에 타임 휠은 가상 머신의 인바운드 트래픽이 역압을 받을 수 없는 문제를 해결하여 모든 트래픽을 아래에서 통합할 수 있습니다. 한 번 바퀴. 약간 예상치 못한 세 번째 이점은 데이터 패킷이 손실되지 않고 지연되기 때문에 계단식 보상이 어느 정도 필요하지 않다는 것입니다. 패킷 손실이 없으면 계단식 보상이 필요하지 않습니다.
아래 그림은 iperf 도구를 사용하여 가상 머신의 안팎 방향을 100초 동안 테스트하여 10Gbps의 속도 제한에서 기존 배압 속도 제한기와 새로운 Carousel 속도 제한기를 사용하는 비교 효과를 보여줍니다.
가로축은 시간(s)이고 세로축은 처리량(Gbps), 즉 초당 iperf가 보고하는 현재 처리량 성능입니다. 인바운드 트래픽이 500Mbps 증가한 것을 알 수 있습니다. 10Gbps에 훨씬 더 가깝습니다.
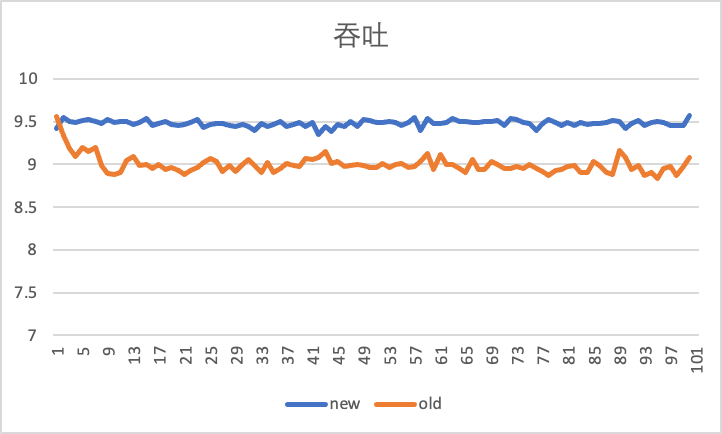
아웃바운드 처리량 성능을 보면 Carousel 속도 제한기가 더 안정적임을 알 수 있습니다.

이러한 개선의 원천은 TCP 트래픽에 대한 캐싱의 평활화 효과에서 비롯됩니다.
향후 개선 사항 및 요약
1. 추가 개선
대출 메커니즘의 배압 속도 제한에 따라 속도 제한 값이 크면 대출로 인해 초과 전송된 데이터 패킷이 전체 속도 제한 지터에 미치는 영향이 제한됩니다. 예를 들어 속도 제한이 1G인 경우 특정 순간에 몇 개의 패킷이 초과 전송되는 경우 속도 제한의 지터에 미치는 영향은 상대적으로 작습니다. 그러나 속도 제한 값이 작은 경우(예: 5Mbps) 여러 데이터 패킷을 과도하게 보내는 영향이 상대적으로 커집니다. 이때 타임스탬프를 통해 가상 머신 포트의 폴링을 제어하면 ON-OFF 효과가 발생하는데, 가상 머신 입장에서는 아웃바운드 트래픽의 경로에 게이트가 있는 것으로 보이며, 잠시 그리고 잠시 문을 닫았습니다.
그러나 이것은 가상머신 송신단의 관점에서 본 것일 뿐이며, 수신단의 타임휠 조정으로 인해 상대적으로 속도가 안정될 것입니다. 송신 측에서 상대적으로 안정적인 경험을 제공하기 위해서는 역압의 영향을 미세 조정하여 초과 송신 가능성을 줄여야 합니다.
또한 포트 입도에 따른 속도 제한은 제어 포트를 폴링하여 구현할 수 있지만 입도가 포트보다 작은 속도 제한의 경우 배압을 구현하기가 쉽지 않습니다. 더 세분화된 배압을 달성하기 위해 Google은 virtio의 기능을 사용하여 더 세분화된 배압을 달성하기 위해 종이 PicNIC[3]에서 Carousel 위에 OOO 완료(비순차 완료)를 지원했습니다. 최적화된 속도 제한기는 아이디어를 제공합니다.
2. 활성 속도 제한(ECN 기반 또는 TCP 창 옵션 수정)
우리는 vSwitch에서 TCP 창을 추적하고 수정할 수 있으며 보다 안정적인 TCP 처리량을 얻기 위해 작은 창을 협상할 수 있습니다. 동시에 ECN 마크도 vSwitch에서 감지할 수 있는데, 이는 가상 머신 내부로 직간접적으로 피드백되거나 vSwitch의 폴링 주파수에 영향을 미칩니다.
3. 향상된 잠금 메커니즘
위의 모든 속도 제한기 개선 사항은 네트워크를 대상으로 합니다.시스템에 멀티 코어가 존재하기 때문에 속도 제한기의 세분성은 종종 스레드에 걸쳐 있습니다.잠금 없는 속도 제한기를 설계하는 방법도 탐색할 가치가 있는 방향입니다. .
4. 요약
속도 제한 장치의 개선 내역에서 현재 알고리즘이 실제 장면과 점점 더 관련이 있음을 알 수 있습니다. 알고리즘은 더 이상 독립적인 구성 요소가 아니라 실제 운영 체제 및 제품 기능과 점점 더 밀접하게 결합됩니다.
참조
[1] eBPF에서의 트래픽 폴리싱: 토큰 버킷 알고리즘 적용
[2] 캐러셀: 최종 호스트에서 확장 가능한 트래픽 셰이핑, SIGCOMM 2017.
[3] PicNIC: 예측 가능한 가상화 NIC, SIGCOMM 2019