CeresDB ist eine hochleistungsfähige, verteilte Cloud-native Zeitreihendatenbank, die in Rust geschrieben ist. Das Entwicklungsteam gab kürzlich bekannt , dass nach fast einem Jahr Open-Source-Forschung und -Entwicklung die Zeitreihendatenbank CeresDB 1.0 offiziell veröffentlicht wurde und die Produktionsverfügbarkeitsstandards erreicht .
CeresDB 1.0 offizielle chinesische Dokumentation: https://docs.ceresdb.io/cn/
Einführung in die Kernfunktionen von CeresDB 1.0
Speicher-Engine
-
Unterstützung von spaltenförmigem Hybridspeicher
-
Effizienter XOR-Filter
Cloudnativ verteilt
-
Realisieren Sie die Trennung von Computing und Storage (Unterstützung von OSS als Datenspeicher, WAL-Implementierung unterstützt OBKV, Kafka)
-
Unterstützung der HASH-Partitionstabelle
Bereitstellung und O&M
-
Unterstützung der eigenständigen Bereitstellung
-
Unterstützen Sie die verteilte Cluster-Bereitstellung
-
Unterstützen Sie Prometheus + Grafana beim Aufbau einer Selbstüberwachung
Lese-Schreib-Protokoll
-
Unterstützt SQL-Abfrage und -Schreiben
-
Implementierung des integrierten Hochleistungs-Lese- und Schreibprotokolls von CeresDB und Bereitstellung eines mehrsprachigen SDK
-
Unterstützt Prometheus, kann als Remote-Speicher von Prometheus verwendet werden
Mehrsprachiges Lese- und Schreib-SDK
- Implementierte Client-SDKs in vier Sprachen: Java, Python, Go, Rust
Einführung in die CeresDB-Architektur
CeresDB stellt eine Zeitreihendatenbank dar. Im Vergleich zu klassischen Zeitreihendatenbanken ist es das Ziel von CeresDB, Daten sowohl im Zeitreihen- als auch im Analysemodus gleichzeitig verarbeiten zu können und effizientes Lesen und Schreiben bereitzustellen.
In einer klassischen Zeitreihendatenbank generiert Tagdie Spalte ( InfluxDBaufgerufen Tag, Prometheusaufgerufen Label) normalerweise einen invertierten Index dafür, aber in der tatsächlichen Verwendung Tagist die Kardinalität der Spalte in verschiedenen Szenarien unterschiedlich——— in einigen In dem Szenario Tagist die Kardinalität sehr hoch (die Daten in diesem Szenario werden als analytische Daten bezeichnet), und das Lesen und Schreiben auf der Grundlage des invertierten Index wird dafür einen hohen Preis zahlen. Andererseits kann die in analytischen Datenbanken übliche Scanning + Pruning-Methode solche analytischen Daten effizienter verarbeiten.
Daher besteht das grundlegende Designkonzept von CeresDB darin, ein hybrides Speicherformat und entsprechende Abfragemethoden zu übernehmen, um Zeitreihendaten und Analysedaten gleichzeitig effizient zu verarbeiten.
Die folgende Abbildung zeigt die Architektur der eigenständigen Version von CeresDB
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
Leistungsoptimierung und experimentelle Ergebnisse
CeresDB verwendet eine Kombination aus spaltenbasiertem Hybridspeicher, Datenpartitionierung, Bereinigung und effizientem Scannen, um das Problem der schlechten Schreibabfrageleistung unter massiven Zeitvorgaben (hohe Kardinalität) zu lösen.
Schreiboptimierung
CeresDB verwendet das LSM-ähnliche Schreibmodell (Log-Structured Merge-Tree), das beim Schreiben keine komplexen invertierten Indizes verarbeiten muss, sodass die Schreibleistung besser ist.
Abfrageoptimierung
Die folgenden technischen Mittel werden hauptsächlich verwendet, um die Abfrageleistung zu verbessern:
Beschneidung:
-
Min/Max-Pruning: Die Baukosten sind relativ niedrig und die Leistung ist in bestimmten Szenarien besser
-
XOR-Filter: Verbessern Sie die Filtergenauigkeit der Zeilengruppe in der Parquet-Datei
Effizientes Scannen:
-
Parallelität zwischen mehreren SSTs: Mehrere SST-Dateien gleichzeitig scannen
-
Interne Parallelität eines einzelnen SST: Unterstützt die Parquet-Schicht, um mehrere Zeilengruppen parallel zu ziehen
-
Kleine E/A zusammenführen: Führen Sie für Dateien auf OSS kleine E/A-Anforderungen zusammen, um die Pull-Effizienz zu verbessern
-
Lokaler Cache: Cache-Dateien, die von OSS abgerufen werden, unterstützen Arbeitsspeicher und Festplatten-Cache
Ergebnisse von Leistungstests
Leistungstests wurden mit TSBS durchgeführt. Die Druckmessparameter sind wie folgt:
-
10 Etiketten
-
10 Felder
-
Timeline (Tags-Kombinationsnummer) 100w-Level
Konfiguration der Druckprüfmaschine: 24c90g
InfluxDB-Version: 1.8.5
CeresDB-Version: 1.0.0
Leistungsvergleich schreiben
Die Schreibleistung von InfluxDB nimmt mit der Zeit weiter ab. Nachdem das Schreiben von CeresDB stabil ist, ist die Schreibrate tendenziell stabil und die Gesamtschreibleistung ist mehr als das 1,5-fache der von InfluxDB (die Lücke kann nach einer gewissen Zeit mehr als doppelt so groß sein).
In der Abbildung unten enthält eine einzelne Zeile 10 Felder.
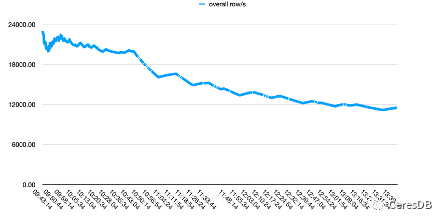
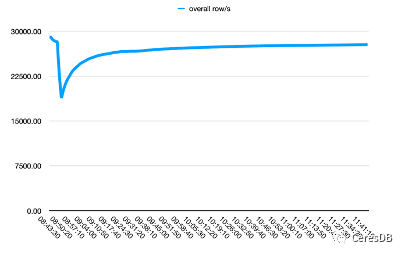
Das Bild oben ist Influxdb und das Bild unten ist CeresDB
Vergleich der Abfrageleistung
Niedrige Screening-Bedingung (Bedingung: os=Ubuntu15.10), CeresDB ist 26-mal schneller als InfluxDB, die spezifischen Daten lauten wie folgt:
-
CeresDB-Abfragezeit: 15 s
-
InfluxDB-Abfragezeit: 6m43s
Hohe Screening-Bedingungen (weniger Datentreffer, Bedingung: Hostname=[8], zu diesem Zeitpunkt wird der traditionelle invertierte Index theoretisch effektiver sein), dies ist ein Szenario, in dem InfluxDB mehr Vorteile hat, und zu diesem Zeitpunkt unter der Bedingung, dass die Aufwärmphase abgeschlossen ist, ist CeresDB fünfmal langsamer als InfluxDB.
-
CeresDB: 85 ms
-
InfluxDB: 15 ms
Fahrplan 2023
Das Entwicklungsteam sagte, dass sich der Großteil seiner Arbeit im Jahr 2023 nach der Veröffentlichung von CeresDB 1.0 auf Leistung, Verteilung und umgebende Ökologie konzentrieren wird. Insbesondere die Docking-Unterstützung der Umgebungsökologie soll verschiedenen Nutzern die Nutzung von CeresDB erleichtern:
Umgebungsökologie
-
Ökologische Kompatibilität, einschließlich Kompatibilität mit gängigen Zeitreihen-Datenbankprotokollen wie PromQL, InfluxdbQL und OpenTSDB
-
Unterstützung von Betriebs- und Wartungswerkzeugen, einschließlich k8s-Unterstützung, CeresDB-Betriebs- und Wartungssystem, Selbstüberwachung usw.
-
Entwicklertools, einschließlich Datenimport und -export usw.
Leistung
-
Entdecken Sie neue Speicherformate
-
Verbessern Sie verschiedene Arten von Indizes, um die Leistung von CeresDB unter verschiedenen Arbeitslasten zu verbessern
verteilt
-
automatischer Lastausgleich
-
Verbessern Sie Verfügbarkeit und Zuverlässigkeit