1. Hintergrund und aktuelle Situation
1. Analyse der drei Modi
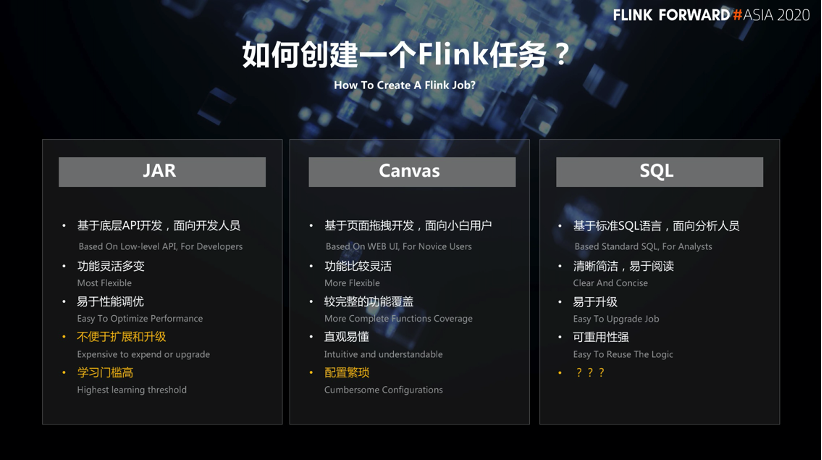
Derzeit gibt es drei Möglichkeiten, Flink-Jobs zu erstellen: JAR-Modus, Canvas-Modus und SQL-Modus. Verschiedene Arten der Übermittlung von Aufgaben richten sich an verschiedene Personengruppen.
■ Jar-Modus
Der Jar-Modus basiert auf der DataStream / DataSet-API und richtet sich hauptsächlich an die zugrunde liegenden Entwickler.
-
Vorteil:
-
Die Funktionen sind flexibel und änderbar, da die zugrunde liegende DataStream / DataSet-API die native API von Flink ist und Sie sie zum Entwickeln beliebiger Operatorfunktionen oder DAG-Diagramme verwenden können.
-
Die Leistungsoptimierung ist bequem und die Leistung jedes Bedieners kann gezielt optimiert werden.
-
Nachteile:
-
Abhängige Aktualisierungen sind umständlich. Unabhängig von der erweiterten Betriebslogik oder dem Upgrade der Flink-Version müssen der Betriebscode und die abhängige Version aktualisiert werden.
-
Die Lernschwelle ist hoch.
■ Canvas-Modus
Der sogenannte Canvas-Modus bietet im Allgemeinen eine visuelle Drag-and-Drop-Oberfläche, mit der Benutzer Drag-and-Drop-Vorgänge auf Schnittstellenbasis ausführen können, um die Bearbeitung von Flink-Jobs abzuschließen. Es richtet sich an einige Anfänger.
-
Vorteil:
-
Die Operation ist bequem und die verschiedenen Operatoren, die im Flink-Job enthalten sind, können einfach auf der Leinwand definiert werden.
-
Die Funktion ist relativ vollständig, sie basiert auf der Entwicklung der Tabellen-API, die Funktionsabdeckung ist relativ vollständig.
-
Das DAG-Diagramm ist leicht zu verstehen und relativ intuitiv. Benutzer können den laufenden Prozess des gesamten Auftrags leicht verstehen.
-
Nachteile:
-
Komplexe Konfiguration: Jeder Bediener muss einzeln konfiguriert werden. Wenn das gesamte DAG-Diagramm sehr kompliziert ist, ist die entsprechende Konfigurationsarbeit sehr umfangreich.
-
Schwierigkeiten bei der Wiederverwendung von Logik: Wenn viele Jobs vorhanden sind, ist es sehr schwierig, die DAG-Logik zwischen verschiedenen Jobs zu teilen.
■ SQL-Modus
Die SQL-Sprache gibt es schon seit langer Zeit und sie hat ihre eigenen Standards, hauptsächlich für Datenanalysten. Solange sie den bestehenden SQL-Standards entsprechen, können Datenanalysten zwischen verschiedenen Plattformen und Computer-Engines wechseln.
-
Vorteil:
-
Klar und prägnant, leicht zu verstehen und zu lesen;
-
Durch die Entkopplung von der Berechnungs-Engine wird SQL von der Berechnungs-Engine und ihrer Version entkoppelt. Für die Migration der Geschäftslogik zwischen verschiedenen Berechnungs-Engines muss nicht oder nur selten das gesamte SQL geändert werden. Wenn Sie die Flink-Version aktualisieren möchten, müssen Sie gleichzeitig die SQL nicht ändern.
-
Die Wiederverwendung von Logik ist praktisch, und unsere SQL-Logik kann durch Erstellen einer Ansicht wiederverwendet werden.
-
Nachteile:
-
Die Grammatik ist nicht einheitlich, z. B. Flow- und Dimensionstabellen-Join. Vor Flink 1.9 wurde die Lateral Table Join-Grammatik verwendet, nach 1.9 wurde sie jedoch in die Grammatik PERIOD FOR SYSTEM_TIME geändert. Diese Grammatik folgt dem SQL ANSI 2011-Standard. Änderungen in der Grammatik führen dazu, dass Benutzer bestimmte Lernkosten haben.
-
Unvollständige Funktionsabdeckung: Das Flink SQL-Modul existiert seit langem nicht mehr, was zu einer unvollständigen Abdeckung seiner Funktionen führt.
-
Die Leistungsoptimierung ist schwierig: Die Ausführungseffizienz eines SQL-Teils wird hauptsächlich von mehreren Teilen bestimmt. Einer ist die vom SQL selbst ausgedrückte Geschäftslogik, der andere Teil ist eine Optimierung des vom Übersetzungs-SQL generierten Ausführungsplans und der dritte Teil Nach dem optimalen Logikausführungsplan bestimmt der Plan beim Übersetzen des nativen Codes in den lokalen Code auch die Ausführungseffizienz von SQL. Für Benutzer kann der Inhalt, den sie optimieren können, auf die von SQL ausgedrückte Geschäftslogik beschränkt sein.
-
Schwierigkeiten beim Auffinden des Problems: SQL ist ein vollständiger Ausführungsprozess. Wenn wir feststellen, dass einige Daten falsch sind, ist es schwieriger herauszufinden, welcher Operator das Problem gezielt hat. Wenn wir das Problem von Flink SQL lokalisieren möchten, können wir im Allgemeinen nur unsere gesamte SQL-Logik weiter optimieren und dann weiterhin versuchen, eine Ausgabe durchzuführen. Diese Kosten sind sehr hoch. Die Echtzeit-Computerplattform von Tencent wird dieses Problem später beheben, indem Ablaufverfolgungsprotokolle und Metrikinformationen hinzugefügt und auf der Produktseite ausgegeben werden, um Benutzern das Auffinden von Problemen bei der Verwendung von Flink SQL zu erleichtern.
2. Aktuelle Arbeit der Echtzeit-Computerplattform von Tencent
■ Erweiterte Syntax
Die Funktionsgrammatik für Fenstertabellen ist definiert, um Benutzern die Implementierung von fensterbasierten Flow-Join-, Schnitt- und Zusammenführungsoperationen zu erleichtern. Darüber hinaus implementiert es eine eigene Flow- und Dimensionstabelle Join-Grammatik.
■ Neue Funktionen
Einige neue Funktionen umfassen zwei neue Fenstertypen: Inkrementelles Fenster und Erweitertes Tumble-Fenster. Die Entkopplung von Ereigniszeitfeld und Tabellenquelle wurde realisiert. In vielen Fällen kann das Ereigniszeitfeld nicht durch das Tabellenquellenfeld definiert werden. Beispielsweise ist die Tabellenquelle eine Unterabfrage oder ein bestimmtes Zeitfeld wird von einer Funktion konvertiert, und Sie möchten diese verwenden Zwischengenerationen. Das Zeitfeld ist derzeit nicht als Ereigniszeitfeld verfügbar. Unsere aktuelle Lösung besteht darin, dem Benutzer die Auswahl eines beliebigen Zeitfelds in der physischen Tabelle zu ermöglichen, um das Zeitattribut des Fensters zu definieren und den WaterMark auszugeben.
■ Leistungsoptimierung
-
Optimierung des Nachteilsflusses;
-
Inline-UDF: Wenn dieselbe UDF sowohl in LogicalProject als auch in der Where-Bedingung angezeigt wird, wird die UDF mehrmals aufgerufen. Extrahieren Sie die UDF, die im Logikausführungsplan wiederholt aufgerufen wird, und speichern Sie das Ausführungsergebnis der UDF zwischen, um mehrere Aufrufe zu vermeiden.
■ Bucket Join
In der Dimensionstabelle Join der Flusstabelle gibt es ein Problem mit dem Kaltstart von Daten. Wenn die Flink-Task beim Start eine große Menge externer Daten lädt, kann leicht ein Gegendruck verursacht werden. Sie können die Statusprozessor-API und andere Mittel verwenden, um alle Daten beim Start vorab in den Speicher zu laden. Bei dieser Lösung tritt jedoch ein Problem auf. Das Laden der Dimensionstabellendaten in alle Unteraufgaben führt zu einem hohen Speicherverbrauch. Daher besteht unsere Lösung darin, in der Definition der Dimensionstabelle Bucket-Informationen anzugeben. Wenn der Flow und die Dimensionstabelle zusammengefügt werden, werden die Daten des entsprechenden Shards in der Dimensionstabelle basierend auf den Bucket-Informationen und dem Flow geladen Die Tabelle wird während des Ausführungsplans übersetzt. Rufen Sie die Bucket-Informationen ab, um sicherzustellen, dass die Daten in den Flow- und Dimensionstabellen basierend auf denselben Bucket-Informationen verknüpft werden. Diese Methode kann das Speicherverbrauchsproblem, das durch das Vorladen der vollständigen Dimensionstabellendaten verursacht wird, erheblich reduzieren.
2. Erweiterung der Fensterfunktion
Die Echtzeit-Computerplattform von Tencent basiert für einige Erweiterungen auf der vorhandenen Flink SQL-Grammatik und definiert außerdem zwei neue Fenstertypen.
1. Neuer Fensterbetrieb
Die vorhandenen Anforderungen lauten wie folgt: Es ist erforderlich, eine Verknüpfungsoperation oder eine Zusammenführungsoperation für ein bestimmtes Zeitfenster für die beiden Streams auszuführen.
Verwenden Sie Flink SQL, um einen Dual-Stream-Join basierend auf einem bestimmten Fenster durchzuführen. Es gibt zwei vorhandene Lösungen: Die erste Lösung besteht darin, zuerst Join und dann Group By durchzuführen, und die zweite ist Interval Join. Lassen Sie uns zunächst analysieren, ob die erste Option die Nachfrage befriedigen kann.
■ 1.1 Zuerst beitreten und dann das Fenster öffnen
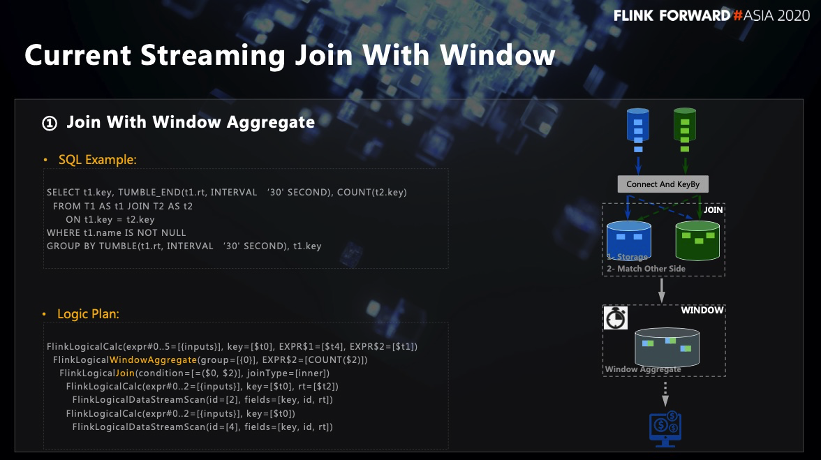
Die Logik, zuerst zu verbinden und dann das Fenster zu öffnen, ist in der obigen Abbildung dargestellt. Gemäß dem logischen Ausführungsplan können Sie sehen, dass sich der Verknüpfungsknoten unter dem Knoten Fensteraggregat befindet, sodass zuerst der Fluss und der Flussverknüpfung ausgeführt werden und dann Das Fensteraggregat wird nach Abschluss des Joins erstellt.
Wie aus dem Flussdiagramm auf der rechten Seite der Abbildung ersichtlich ist, führen die beiden Streams zuerst eine Verbindung durch und führen dann die Keyby-Operation basierend auf dem Join-Schlüssel aus, um sicherzustellen, dass die Daten mit demselben Join-Schlüssel in den beiden Streams ausgeführt werden können zur gleichen Aufgabe gemischt werden. Der linke Stream speichert die Daten in seinem eigenen Status und wechselt gleichzeitig zum Abgleich in den rechten Stream-Status. Wenn er übereinstimmen kann, gibt er das übereinstimmende Ergebnis an den Downstream aus. Bei diesem Schema gibt es zwei Probleme:
-
Status kann nicht bereinigt werden : Da Join vor dem Öffnen des Fensters keine Fensterinformationen in Join enthält, kann der Join-Status der beiden Upstream-Streams nicht bereinigt werden, selbst wenn das Downstream-Fenster die Berechnung auslöst und abschließt. Sie können dies höchstens Verwenden Sie zum Bereinigen nur TTL-basierte Methoden.
-
Die Semantik kann die Anforderung nicht erfüllen : Die ursprüngliche Anforderung besteht darin, die Daten in die beiden Streams basierend auf demselben Zeitfenster aufzuteilen und dann zu verbinden. Die aktuelle Lösung kann diese Anforderung jedoch nicht erfüllen, da sie zuerst den Join ausführt und die Daten nach dem Join Then verwendet Wenn Sie das Fenster öffnen, kann diese Methode nicht sicherstellen, dass die Daten, die am Join in den beiden Streams teilnehmen, auf demselben Fenster basieren.
■ 1.2 Intervallverknüpfung

Im Vergleich zur vorherigen Schreibmethode besteht der Vorteil von Interval Join darin, dass es kein Problem gibt, dass der Status nicht bereinigt werden kann, da die Daten des linken und rechten Streams basierend auf einem bestimmten Fenster gescannt werden können Zustand kann aufgeräumt werden.
Im Vergleich zur ersten Lösung kann diese Lösung jedoch eine schlechtere Datengenauigkeit aufweisen, da die Aufteilung von Fenstern nicht auf einem bestimmten Fenster basiert, sondern von Daten gesteuert wird, dh, die aktuellen Daten können ein weiterer Join-Stream sein. Der Bereich der obigen Daten basieren auf der Ereigniszeit, die von den aktuellen Daten getragen wird. Es gibt immer noch eine gewisse Lücke zwischen der Semantik dieser Fensterteilung und unseren Bedürfnissen.
Stellen Sie sich zwei vorhandene Streams mit inkonsistenten Raten vor. Die beiden Grenzen von niedrig und oben werden verwendet, um den Datenbereich des linken und des rechten Streams zu begrenzen, der verbunden werden kann. Unter solchen starren Bereichsbeschränkungen gibt es immer einige gültige Daten auf dem rechter Strom, der in die Zeit fällt. Außerhalb des Fensters [links + niedrig, links + oben] ist die Berechnung nicht genau genug. Daher ist es besser, das Zeitfenster gemäß der Fensterausrichtungsmethode zu teilen, damit die Daten mit derselben Ereigniszeit in den beiden Streams in dasselbe Zeitfenster fallen.
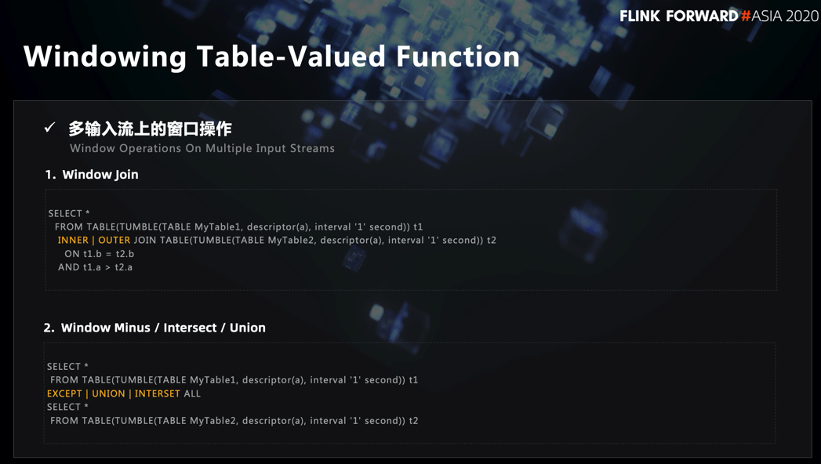
■ 1.3 Fenstertabellenwertfunktion
Tencent hat die Grammatik der Fenstertabellenwertfunktion erweitert, die die Anforderungen von "Verknüpfungsoperation oder Zusammenführungsoperation für ein bestimmtes Zeitfenster in zwei Streams" erfüllen kann. Es gibt eine Beschreibung dieser Grammatik im SQL 2016-Standard, und die Grammatik ist bereits in Calcite1.23 vorhanden.
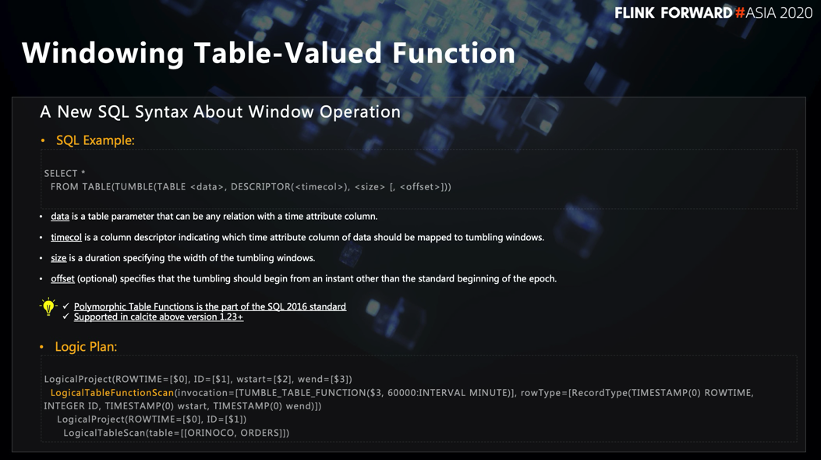
Die Quelle in der Syntax der Fenstertabellenwertfunktion kann ihre gesamte Semantik klar beschreiben. Die From-Klausel enthält alle Informationen, die für die Fensterdefinition erforderlich sind, einschließlich Tabellenquelle, Ereigniszeitfeld, Fenstergröße usw.
Wie aus dem logischen Plan in der obigen Abbildung ersichtlich ist, fügt diese Grammatik LogicalTableScan einen Knoten mit dem Namen LogicalTableFunctionScan hinzu. Darüber hinaus verfügt der LogicalProject-Knoten (Ausgabeknoten) über zwei weitere Felder mit den Namen WindowStart und WindowEnd. Basierend auf diesen beiden Feldern können die Daten in einem bestimmten Fenster zusammengefasst werden. Basierend auf den oben genannten Prinzipien kann die Syntax der Fenstertabellenfunktion die folgenden Aktionen ausführen
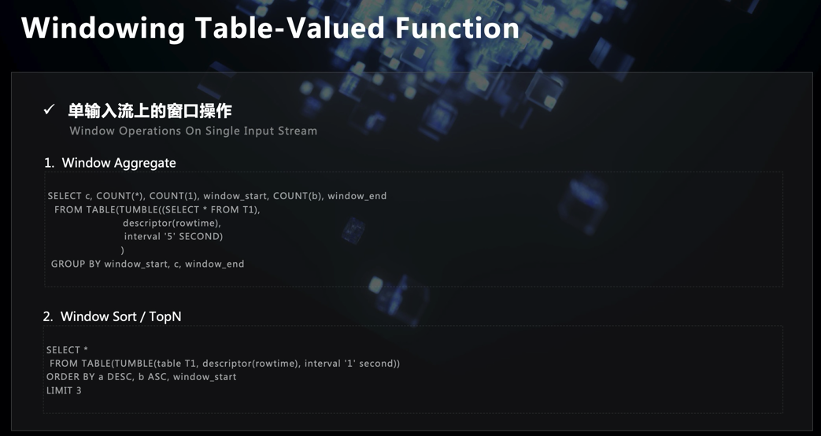
-
In einem einzelnen Stream kann ein Zeitfenster wie die vorhandene Syntax des Gruppenfensters unterteilt werden. Die Schreibmethode ist wie in der obigen Abbildung dargestellt, und alle Fensterinformationen werden in die From-Klausel eingefügt, und anschließend wird Group By ausgeführt. Diese Schreibweise sollte eher dem Verständnis der Öffentlichkeit für Zeitfenster entsprechen und ist etwas intuitiver als die derzeitige Schreibweise des Gruppenfensters in Flink SQL. Wir haben einen Trick gemacht, als wir die Grammatik der Windowing Table-Valued Function in den einzelnen Stream übersetzt haben. Bei der Implementierung der physischen Übersetzung dieses SQL haben wir sie nicht in eine bestimmte DataStream-API übersetzt, sondern ihren logischen Ausführungsplan direkt in The umgewandelt Der logische Ausführungsplan des aktuellen Gruppenfensters, dh der Code, der den zugrunde liegenden physischen Ausführungsplan gemeinsam nutzt, entspricht lediglich einem logischen Ausführungsplan.
Darüber hinaus können Sie für die Daten im Fenster eine Sortier- oder TopN-Ausgabe durchführen, da die Syntax der Fenstertabellenwertfunktion die Daten im Voraus in bestimmte Fenster unterteilt hat. Teilen Sie, wie in der obigen Abbildung gezeigt, zuerst das Fenster in der From-Klausel, und folgen Sie dann unmittelbar nach und nach Limit, um die Sortier- und TopN-Semantik direkt auszudrücken.
-
Bei zwei Streams kann es die ursprünglichen Anforderungen von "Join-Operation oder Cross-Merge-Operation für zwei Streams für ein bestimmtes Zeitfenster" erfüllen. Die Syntax ist wie in der obigen Abbildung dargestellt. Erstellen Sie zunächst die Fenstertabelle der beiden Fenster und verwenden Sie dann das Schlüsselwort Join, um die Verknüpfungsoperation auszuführen. Die Schnitt- und Zusammenführungsoperation ist dieselbe wie die Schnittmenge und Differenzoperation der traditionellen Datenbank SQL.
■ 1.4 Implementierungsdetails
Im Folgenden werden einige Details unserer Implementierung der Syntax der Fenstertabellenwertfunktion kurz vorgestellt.
-
1.4.1 Ausbreitung von Fenstern
Die ursprüngliche Übersetzungsmethode für logische Pläne basiert auf LogicalTableScan, wird dann in die Funktion "Fenstertabellenwert" übersetzt und schließlich in die OrderBy-Limit-Klausel übersetzt. Der gesamte Prozess speichert den Status viele Male, was einen relativ hohen Leistungsverbrauch darstellt. Daher wurden die folgenden Optimierungen vorgenommen, um mehrere logische Relnodes für die Übersetzung zusammenzuführen, wodurch die Generierung von Zwischenverbindungscodes reduziert und die Leistung verbessert werden kann .
-
1.4.2 Zeitattributfeld
Sie können die Syntax von Windowing Table-Valued Function sehen:
SELECT * FROM TABLE(TUMBLE(TABLE <data>, DESCRIPTOR(<timecol>), <size> [, <offset>]))
Tabelle <Daten> kann nicht nur eine Tabelle, sondern auch eine Unterabfrage sein. Wenn Sie das Zeitattribut beim Definieren des Ereigniszeitfelds an die Tabellenquelle binden und die Tabellenquelle zufällig eine Unterabfrage ist, entspricht dies derzeit nicht unseren Anforderungen. Wenn wir also die Grammatik implementieren, entkoppeln wir das Zeitattributfeld von der Tabellenquelle. Im Gegenteil, der Benutzer verwendet ein beliebiges Zeitfeld in der physischen Tabelle als Zeitattribut, um ein Wasserzeichen zu generieren.
-
1.4.3 Zeitwasserzeichen
Die Logik der Verwendung von Wasserzeichen ist dieselbe wie in anderen Grammatiken. Das Mindestzeitwasserzeichen aller Eingabeaufgaben der beiden Streams bestimmt das Zeitwasserzeichen des Fensters, um die Fensterberechnung auszulösen.
-
1.4.4 Einschränkungen verwenden
Derzeit gibt es einige Einschränkungen bei der Verwendung der Funktion "Fenstertabellenwert". Zunächst müssen die Fenstertypen der beiden Streams gleich sein, und auch die Fenstergröße ist gleich. Die Funktionen für das Sitzungsfenster wurden jedoch noch nicht implementiert.
2. Neuer Fenstertyp
Die folgende Einführung wird auf zwei neue Fenstertypen erweitert.
■ 2.1 Inkrementelles Fenster
Es gibt die folgenden Anforderungen: Benutzer möchten in der Lage sein, innerhalb eines Tages eine PV / UV-Kurve zu zeichnen, dh mehrere Ergebnisse an einem Tag oder in einem großen Fenster auszugeben, anstatt auf das Ende des Fensters zu warten, um die gleichmäßig auszugeben Ergebnisse einmal. Als Reaktion auf diese Nachfrage haben wir das Inkrementalfenster erweitert.
-
2.1.1 Mehrere Trigger
Basierend auf Tumble Window, angepasster inkrementeller Trigger. Dieser Trigger stellt sicher, dass die Fensterberechnung nicht nur nach dem Ende von Windows ausgelöst wird, sondern jede in SQL definierte Intervallperiode eine Fensterberechnung auslöst.
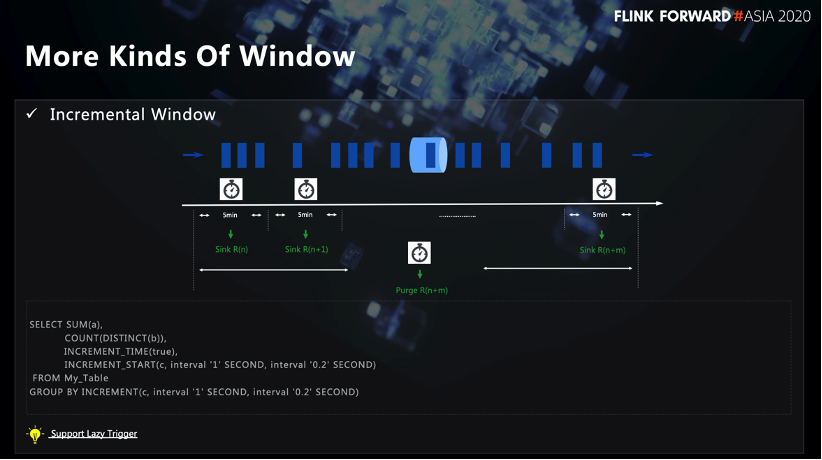
Wie im SQL-Fall in der obigen Abbildung beträgt die Gesamtfenstergröße eine Sekunde und wird alle 0,2 Sekunden ausgelöst, sodass innerhalb des Fensters 5 Fensterberechnungen ausgelöst werden. Das nächste Ausgabeergebnis wird basierend auf dem vorherigen Ergebnis berechnet.
-
2.1.2 Lazy Trigger
Eine Optimierung namens Lazy Trigger for Incremental Window wurde durchgeführt. Im eigentlichen Produktionsprozess gibt derselbe Schlüsselwert eines Fensters das gleiche Ergebnis aus, nachdem die Fensterberechnung mehrmals ausgelöst wurde. Für Downstreams ist es nicht erforderlich, diese Art von Daten wiederholt zu empfangen. Wenn Lazy Trigger konfiguriert ist und sich unter demselben Schlüssel im selben Fenster befindet, ist der nächste Ausgabewert genau der gleiche wie der vorherige, und der Downstream empfängt diese Aktualisierungsdaten nicht, wodurch der Downstream-Speicherdruck und der gleichzeitige Druck verringert werden .
■ 2.2 Erweitertes Tumble-Fenster

Es gibt die folgenden Anforderungen: Der Benutzer hofft, dass nach dem Auslösen des Tumble-Fensters die verspäteten Daten nicht verworfen werden, sondern die Fensterberechnung erneut ausgelöst wird. Wenn Sie die DataStream-API verwenden, können Sie SideOutput verwenden, um die Anforderungen zu erfüllen. Für SQL gibt es derzeit jedoch keine Möglichkeit, dies zu tun. Daher wird das vorhandene Tumble-Fenster erweitert und die verspäteten Daten werden ebenfalls erfasst. Gleichzeitig lösen die verspäteten Daten die Fensterberechnung nicht aus und geben sie nicht jedes Mal nachgelagert aus, sondern definieren einen Auslöser und das Zeitintervall neu wird verwendet. Die in SQL definierte Fenstergröße, um die Häufigkeit des Sendens von Daten nachgeschaltet zu verringern.
Gleichzeitig verwendet der seitliche Ausgabestream auch die Fensterlogik, um beim Sammeln von Daten eine weitere Aggregation durchzuführen. Hierbei ist zu beachten, dass, wenn der Downstream eine HBase-ähnliche Datenquelle für dasselbe Fenster und denselben Schlüssel ist, die vorherigen Daten, die normalerweise vom Fenster ausgelöst wurden, durch die späten Daten überschrieben werden. Theoretisch ist die Wichtigkeit von späten Daten dieselbe wie die vom normalen Fenster ausgelösten Daten und kann sich nicht gegenseitig abdecken. Schließlich führt der Downstream eine zweite Aggregation von normalen Daten und verzögerten Daten unter demselben Schlüssel in demselben Fenster durch.
Drei, Optimierung des Retracement-Flusses
Als nächstes werde ich einige Optimierungen vorstellen, die am Retracement-Stream vorgenommen wurden.
1. Mehrdeutigkeit der Flusstabelle
Überprüfen Sie einige Konzepte zu Retracement-Flows in Flink SQL.
Lassen Sie mich zunächst die fortlaufende Abfrage einführen. Im Vergleich zu den Merkmalen der Stapelverarbeitung und der Ausgabe eines Ergebnisses ist die Aggregation des Streams ein Datenelement aus dem Upstream, und der Downstream erhält ein aktualisiertes Datenelement, d. H. wird das Ergebnis ständig durch die Upstream-Daten aktualisiert. Daher kann stromabwärts desselben Schlüssels mehrere Aktualisierungsergebnisse empfangen.
2. Retracement-Fluss
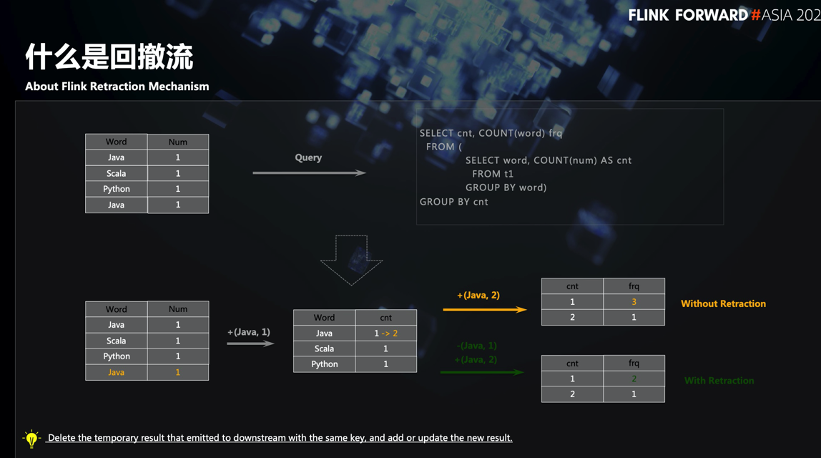
Nehmen Sie die SQL in der obigen Abbildung als Beispiel. Wenn das zweite Java den Aggregationsoperator erreicht, aktualisiert es den vom ersten Java generierten Status und sendet das Ergebnis an den Downstream. Wenn der Downstream die Ergebnisse mehrerer Aktualisierungen nicht verarbeitet, führt dies zu falschen Ergebnissen. Als Reaktion auf dieses Szenario führte Flink SQL das Konzept des Retracement-Flusses ein.
Der sogenannte Retracement-Ablauf besteht darin, ein Flag vor den Originaldaten einzufügen und es mit True / False zu identifizieren. Wenn das Flag False ist, bedeutet dies, dass es sich um eine Retracement-Nachricht handelt, und es informiert den Downstream, die Daten zu löschen. Wenn das Flag True ist, führt der Downstream den Einfügevorgang direkt aus.
■ 2.1 Wann wird der Retracement-Fluss stattfinden?
Derzeit gibt es vier Szenarien für den in Flink SQL generierten Retracement-Ablauf:
-
Aggregat ohne Fenster (Aggregatszene ohne Fenster)
-
Rang
-
Über Fenster
-
Links / Rechts / Vollständige äußere Verbindung
Erklären Sie, warum Outer Join ein Retracement erzeugt. Nehmen Sie als Beispiel Left Outer Join und nehmen Sie an, dass die Daten des linken Streams vor den Daten des rechten Streams eintreffen. Die Daten des linken Streams scannen den Status der Daten des rechten Streams. Wenn keine Daten vorhanden sind kann verbunden werden, der linke Stream kennt den rechten Stream nicht. Existiert dieses Datenelement wirklich in der Mitte oder sind die entsprechenden Daten im rechten Stream zu spät. Um die Semantik des äußeren Joins zu erfüllen, generieren die Daten des linken Streams weiterhin Join-Daten und senden sie nachgeschaltet, ähnlich wie bei MySQL Left Join. Die Felder des linken Streams werden mit normalen Tabellenfeldwerten und den entsprechenden Feldern von gefüllt Der rechte Stream wird mit Null gefüllt und dann an den Downstream ausgegeben, wie in der folgenden Abbildung dargestellt:
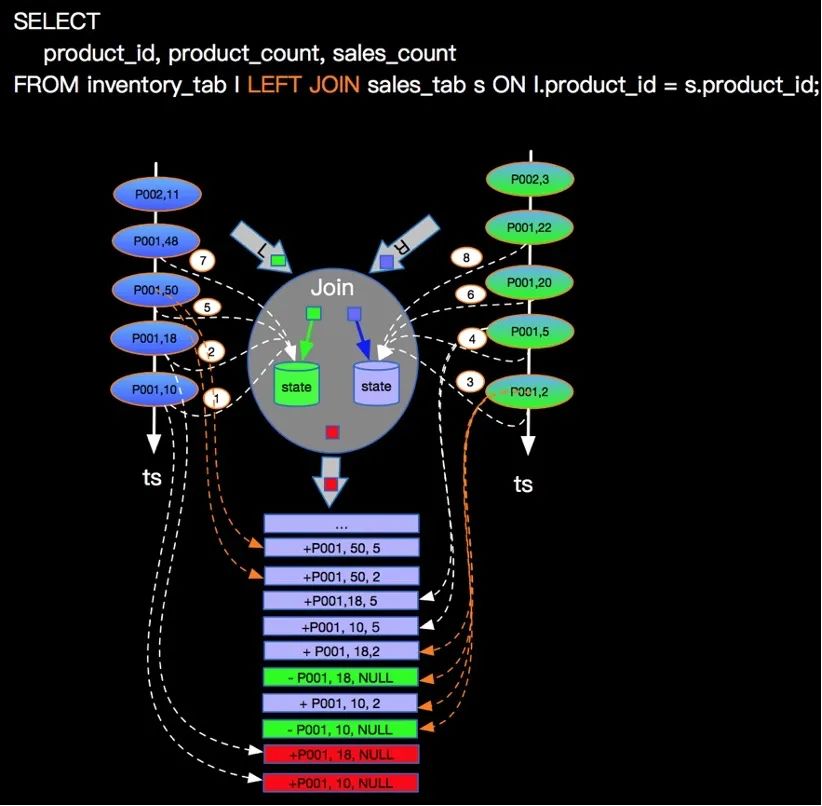
(Das Bild stammt aus der Yunqi Community)
Wenn später die entsprechenden Daten des rechten Streams eintreffen, wird der Status des linken Streams gescannt und erneut Join ausgeführt. Um die Richtigkeit der Semantik sicherzustellen, werden zu diesem Zeitpunkt die speziellen Daten, die zuvor an den ausgegeben wurden Downstream muss zurückgezogen werden und gleichzeitig werden die Daten des letzten Joins an den Downstream ausgegeben. Beachten Sie, dass für denselben Schlüssel, wenn ein Retracement auftritt, das zweite Retracement nicht erfolgt, da die entsprechenden Daten in einem anderen Stream verbunden werden können, wenn die Daten des Schlüssels später eintreffen.
■ 2.2 Umgang mit Retracement-Nachrichten
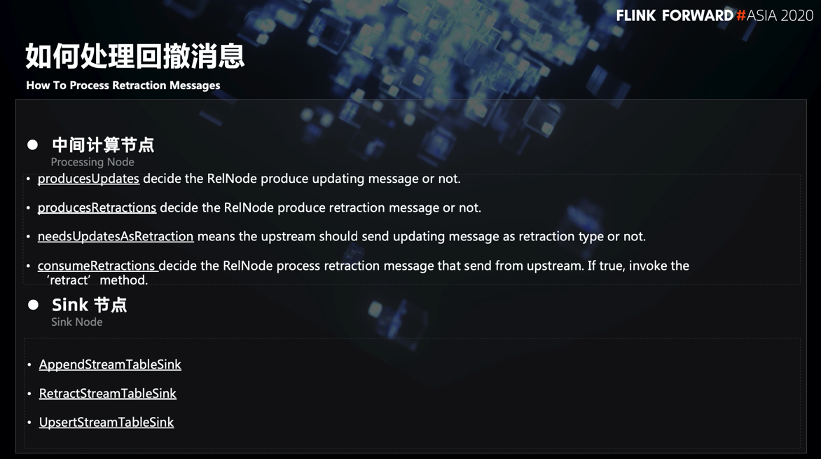
Im Folgenden wird die Logik der Verarbeitung von Retracement-Nachrichten in Flink vorgestellt.
Bei Zwischencomputerknoten wird dies durch die 4 Flags in der obigen Abbildung gesteuert. Diese Flags geben an, ob der aktuelle Knoten Aktualisierungsinformationen oder Rückzugsinformationen generiert und ob der aktuelle Knoten diese Rückzugsinformationen verwendet. Diese 4 Flags können die gesamte Logik der Erzeugung und Verarbeitung von Retract bestimmen.
Für Senkenknoten gibt es derzeit drei Senkentypen in Flink: AppendStreamTableSink, RetractStreamTableSink und UpsertStreamTableSink. Wenn es sich bei den von AppendStreamTableSink empfangenen Upstream-Daten um eine Retract-Nachricht handelt, wird ein Fehler direkt gemeldet, da nur die Append-Only-Semantik beschrieben werden kann. RetractStreamTableSink kann Retract-Informationen verarbeiten. Wenn der Upstream-Operator eine Retract-Nachricht sendet, wird die Nachricht gelöscht. Wenn der Upstream-Operator normale Aktualisierungsinformationen sendet, führt er einen Einfügevorgang für die Nachricht aus. UpsertStreamTableSink kann als einige Leistungsoptimierungen für RetractStreamTableSink verstanden werden. Wenn die Sink-Datenquelle idempotente Vorgänge unterstützt oder Aktualisierungsvorgänge basierend auf einem bestimmten Schlüssel unterstützt, übergibt UpsertStreamTableSink den vorgelagerten Upsert-Schlüssel während der SQL-Übersetzung an den Table Sink und führt dann den Aktualisierungsvorgang basierend auf dem Schlüssel aus.
■ 2.3 Zugehörige Optimierung
Wir nehmen die folgenden Optimierungen basierend auf dem Drawdown-Ablauf vor.
-
2.3.1 Optimierung von Zwischenknoten
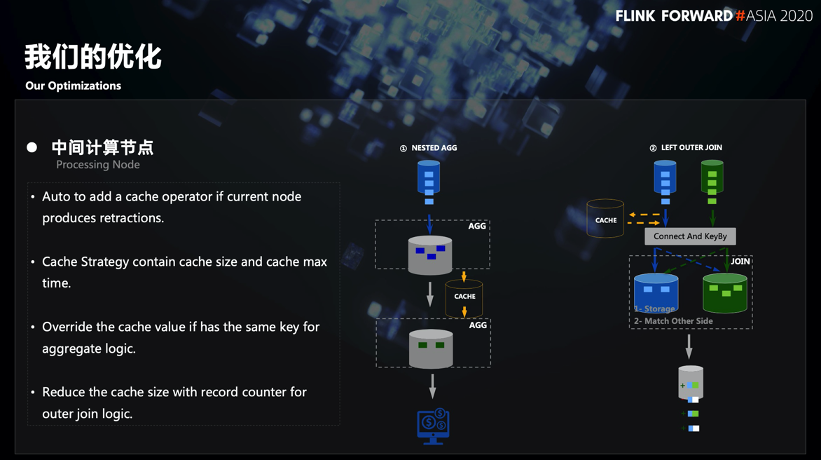
Einer der grundlegendsten Gründe für das Generieren von Drawdown-Informationen besteht darin, Aktualisierungsergebnisse mehrmals kontinuierlich an Downstream zu senden. Um die Häufigkeit von Aktualisierungen und die Parallelität zu verringern, können Sie daher einen Teil der Aktualisierungsergebnisse akkumulieren, bevor Sie sie versenden. Wie in FIG.
-
Das erste Szenario ist ein verschachteltes AGG-Szenario (z. B. zwei Zählvorgänge). Wenn die erste Schicht Group By versucht, das Aktualisierungsergebnis an den Downstream zu senden, wird zuerst ein Cache erstellt, wodurch die Häufigkeit des Sendens von Daten an den Downstream verringert wird . Wenn die Cache-Triggerbedingung erreicht ist, wird das Aktualisierungsergebnis an den Downstream gesendet.
-
Das zweite Szenario ist Outer Join. Wie bereits erwähnt, generiert Outer Join eine Retracement-Nachricht, da die Datenraten links und rechts nicht übereinstimmen. Nehmen Sie als Beispiel Left Outer Join, Sie können die Daten des linken Streams zwischenspeichern. Wenn die Daten des linken Streams eintreffen, werden sie im Status des rechten Streams gesucht. Wenn sie die Daten finden können, die mit ihnen verknüpft werden können, werden sie nicht zwischengespeichert. Wenn die entsprechenden Daten nicht gefunden werden können, werden die Daten dieses Schlüssels gespeichert Zuerst zwischengespeichert und wenn bestimmte Auslöser erreicht sind. Wenn die Bedingungen erfüllt sind, suchen Sie erneut im richtigen Stream-Status. Wenn die entsprechenden Daten immer noch nicht gefunden werden, senden Sie ein Join-Datenelement mit einem Nullwert nachgeschaltet. Nach rechts Wenn die entsprechenden Daten des Streams eintreffen, wird der Cache, der dem Schlüssel im Cache entspricht, geleert. Anschließend wird eine Retracement-Nachricht nachgeschaltet.
Dadurch wird die Häufigkeit des Sendens von Retracement-Nachrichten nachgeschaltet.
-
2.3.2 Sinkknotenoptimierung

Für den Sink-Knoten wurden einige Optimierungen vorgenommen, und zwischen dem AGG-Knoten und dem Sink-Knoten wurde ein Cache erstellt, um den Druck auf den Sink-Knoten zu verringern. Wenn die Retracement-Nachrichten im Cache aggregiert werden und die Triggerbedingung des Cache erreicht ist, werden die aktualisierten Daten einheitlich an den Senkenknoten gesendet. Nehmen Sie das SQL in der folgenden Abbildung als Beispiel:
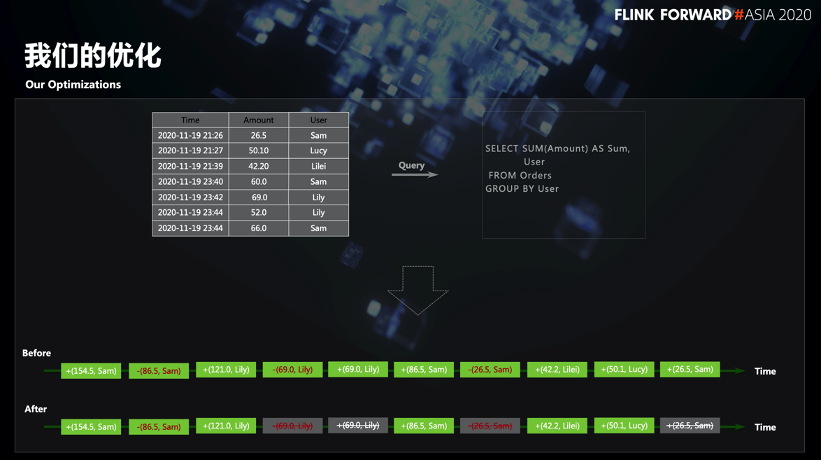
In den Ausgabeergebnissen vor und nach der Optimierung können Sie sehen, dass nach der Optimierung die nachgelagerte Datenmenge reduziert wird. Wenn beispielsweise Benutzer Sam versucht, eine Rückrufnachricht an den Downstream zu senden, befindet sich eine Cache-Schicht zuerst verwendet, und die Menge der nachgeschalteten Daten kann viel reduziert werden.
Viertens zukünftige Planung
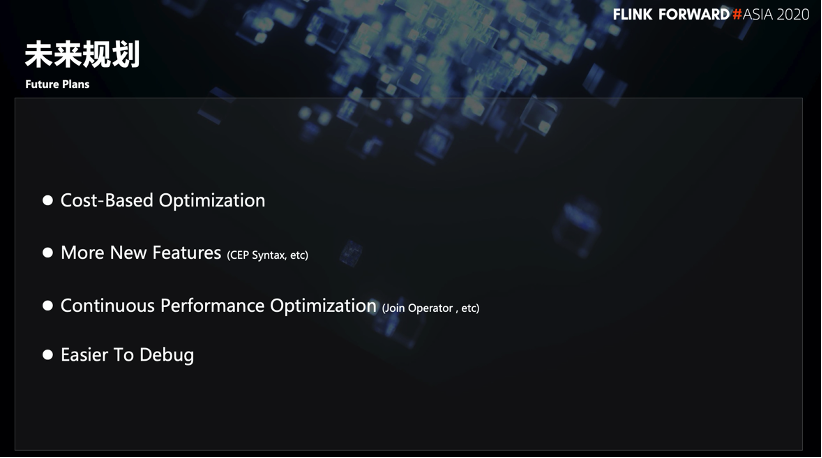
Lassen Sie uns den Folgearbeitsplan unseres Teams vorstellen:
-
Kostenbasierte Optimierung : Die Optimierung des logischen Ausführungsplans von Flink SQL basiert weiterhin auf RBO (Rule Based Optimization). Unser Team möchte etwas basierend auf dem CBO tun, und die Hauptaufgabe besteht darin, statistische Informationen zu sammeln. Die statistischen Informationen stammen nicht nur von Flink SQL selbst, sondern können auch von anderen Produkten im Unternehmen stammen, z. B. Metadaten, Datenverteilung, die verschiedenen Schlüsseln entspricht, oder andere Datenanalyseergebnisse. Indem wir mit anderen Produkten im Unternehmen fertig werden, können wir die genauesten statistischen Daten erhalten und den besten Ausführungsplan erstellen.
-
Weitere neue Funktionen (CEP-Syntax usw.) : Definieren Sie eine CEP-Grammatik basierend auf Flink SQL, um die Anforderungen einiger Benutzer in Bezug auf CEP zu erfüllen.
-
Kontinuierliche Leistungsoptimierung (Join-Operator usw.) : Unser Team führt nicht nur die Optimierung der Ausführungsplanebene durch, sondern auch eine fein abgestimmte Optimierung des Join-Operators oder der Datenmischung.
-
Einfacher zu debuggen : Schließlich geht es um das Debuggen und Positionieren von Flink SQL-Aufgaben. Derzeit fehlt Flink SQL in diesem Aspekt relativ, insbesondere bei dem Problem der Fehlausrichtung von Online-Daten, das nur sehr schwer zu beheben ist. Unsere aktuelle Idee ist es, SQL so zu konfigurieren, dass während der Ausführung einige Trace-Informationen oder einige Metrik-Informationen ausgespuckt und dann an andere Plattformen gesendet werden. Helfen Sie den Benutzern anhand dieser Ablaufverfolgungs- und Metrikinformationen, den Problemoperator zu finden.