KMP-Algorithmus detailliert
Erklären Sie zunächst, welchen KMP-Algorithmus es gibt:
Das vom KMP-Algorithmus zu lösende Problem besteht darin, das Muster in der Zeichenfolge (auch als Hauptzeichenfolge bezeichnet) zu lokalisieren. Einfach ausgedrückt ist dies die Stichwortsuche, die wir normalerweise sagen. Die Musterzeichenfolge ist das Schlüsselwort (im Folgenden P genannt). Wenn sie in einer Hauptzeichenfolge (im Folgenden T genannt) vorkommt, geben Sie ihre spezifische Position zurück, andernfalls -1 (häufig verwendete Mittel).
Über die Lösung dieser Art von Problem
- Brute-Force-Methode, Zeitkomplexität O ( N ∗ MN * M.N.∗M ) (N ist die Länge der Hauptzeichenfolge, M ist die Länge der Musterzeichenfolge), versucht die Musterzeichenfolge, mit jeder Position der Hauptzeichenfolge übereinzustimmen, bis die Übereinstimmung erfolgreich ist.
Beispiel:
Wenn zwei Zeichenfolgen übereinstimmen, wird die P-Zeichenfolge beginnt mit der Hauptzeichenfolge T Das erste Zeichen beginnt zu stimmen, und die rote Position ist die Position, an der das erste Zeichen nicht übereinstimmt. Zu diesem Zeitpunkt ist der Index des nicht übereinstimmenden Zeichens i = j = 3. Die
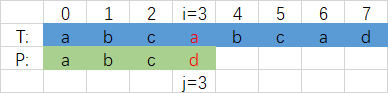
nächste Übereinstimmung besteht darin, dass P von Index 0 und T von Index 1 bis zur Übereinstimmung beginnt und diesen Vorgang dann wiederholt.
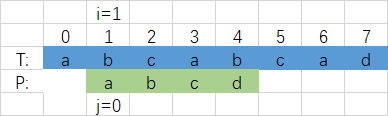
Diese Methode ist zu gewalttätig, also haben wir Eine schnellere Methode einzuführen,KMP-Algorithmus - KMP-Algorithmus Zeitkomplexität O ( NNN ) Die Länge der Hauptzeichenfolge von N
entspricht dem normalen Denken. Wenn für die Übereinstimmung in der obigen Abbildung zum ersten Mal eine Nichtübereinstimmung auftritt, ist es natürlich, an das a in der P-Zeichenfolge und den Index 3 zu denken in der T-Zeichenfolge, nämlich einem übereinstimmenden Zeichen, siehe Figur,
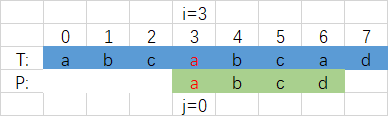
d.h.T i-Indexzeichenfolgenkonstante, wird die P j -String Null, d.h. derVorteilbei dieser Teilübereinstimmung hat gültige Informationen, der Zeiger i wird nicht durch Modifizieren des Zeigers j zurückgehalten, so dass die Musterzeichenfolge Versuchen Sie, so weit wie möglich an einen gültigen Ort zu gelangen.
Betrachten wir noch einmal einen Datensatz.

Wenn T und P im Index 3 nicht übereinstimmen, bewegt sich i gemäß den obigen Angaben nicht und die P-Zeichenfolge bewegt sich an die gültige Position. Wenn der Vergleich das nächste Mal beginnt, wird die Position ist j = 2.
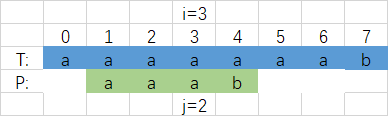
Tatsächlich ist dies wie ein Push-Prozess.Die Position von j wird durchden Wert des längsten gemeinsamen Präfix-Suffixes in der ZeichenfolgevorderNichtübereinstimmung zwischen P und T bestimmt.
Erklären Sie zunächst das Präfix und das Suffix. Nehmen Sie die Zeichenfolge als Beispiel. Das

Präfix sind alle aufeinander folgenden Teilzeichenfolgen, die das erste Zeichen, aber nicht das letzte Zeichen enthalten, wie in der folgenden Abbildung gezeigt. Das

Suffix enthält das letzte Zeichen und enthält nicht die erste. Alle aufeinanderfolgenden Teilzeichenfolgen von Zeichen


Hier möchte ich ein nächstes Array für die Musterzeichenfolge finden. next [i] repräsentiert den Wert des längsten gemeinsamen Präfix-Suffix der ersten i-1-Zeichen. Künstliche Vorschriften next [0] = - 1, next [1] = 0;
- Denn wenn es nur ein Zeichen gibt, gibt es kein Zeichen davor, also ist es bedeutungslos.
- Wenn zwei Zeichen vorhanden sind, nehmen Sie als Beispiel die obige P-Zeichenfolge. Als nächstes [1] wird der Wert des längsten gemeinsamen Präfix-Suffixes von a vor b ermittelt. Da jedoch nur ein Zeichen vorhanden ist, enthält das Präfix nicht das letzte Zeichen und Das Suffix enthält nicht das erste widersprüchliche Zeichen, daher ist der Wert 0.
Für next [6] ist das längste gemeinsame Präfix und Suffix des vorderen abcabc abc, also next [6] = 3
So lösen Sie das nächste Array
Beginnen Sie mit next [2]. Wie bereits erwähnt, sind die Positionen 0 und 1 künstlich festgelegte Werte. Unten ist die Lösungsmethode von next [i] (i> = 2).
- Zunächst muss hier ein Wert von k angegeben werden. Der Wert von k repräsentiert den Wert von next [i-1], dh den Wert des längsten gemeinsamen Präfixes und Suffixes in den ersten i-2-Zeichen.
- Beim Lösen von next [i] muss verglichen werden, ob das i-1-te Zeichen und das k-te Zeichen gleich sind
- Wenn das gleiche, ist next [i] = next [i-1] +1;
- Ansonsten ist k = next [k], bis k = 0;
Zum Beispiel:
Anfangswert k = 0; nex [0] = - 1, next [1] = 0; wenn

i = 2, bedeutet p [1]! = P [k] (k = 0) b! = A
k = 0 // Das heißt, es hat das Ende erreicht und es wurde noch nicht abgeglichen. Da k == 0 ist, sei next [2] = 0; wenn

i = 3, p [2]! = P [k] (k = 0), weil k = = 0, also sei next [3] = 0, wenn

i = 4 am Ende ist , p [3] == p [k] (k = 0), also lass next [4 ] = ++ k; Das heißt, next [4] = 1; wenn

i = 5, p [4] = p [k] (k = 1), also next [5] = ++ k; nämlich next [5 ] = 2; das

gleiche Get next [6] = 3

Aber ich habe es erst herausgefunden, nachdem ich es wieder ausgeführt habe. . . Die Verwendung von k = next [k] wird in diesem Beispiel nicht verwendet. Dann werde ich den P-String so modifizieren, dass c mit dem Index 5 zu a wird. Wenn

i = 6, k = 2, p [6]! = P [2], k = next [k], das ist k = 0
p [0] == p [6], also weiter [6] = ++ k = 1;
Sie können P in zwei Teile teilen und sich das
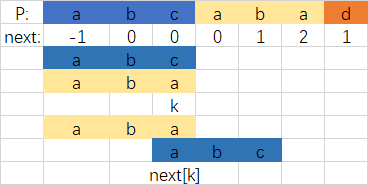
nächste Array ansehen .
Als nächstes folgt der Teil des KMP-Algorithmus
- Geben Sie zwei Zeichenfolgen s1, s2 ein (s1 ist die Hauptzeichenfolge, s2 ist die Musterzeichenfolge)
- Holen Sie sich das nächste Array von s2
- Definieren Sie zwei Zeiger i1 und i2, um die Position von s1 bzw. die Position von s2 darzustellen
- Wenn s1 [i1] == s2 [i2], i1 ++, i2 ++
- Ansonsten i2 = next [i2]
- Wenn i2 auf 0 verschoben wird, dh als nächstes [i2] == - 1, stimmt i1 ++ mit dem ersten der Musterzeichenfolge überein und stimmt nicht überein und kann nur mit dem nächsten der Hauptzeichenfolge übereinstimmen.
- Beurteilen Sie abschließend, ob i2 gleich der Länge von s2 ist, was gleich i1-i2 ist, andernfalls -1
Zum Beispiel wurde das
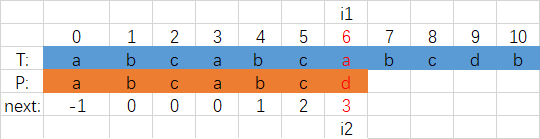
nächste Array von P-Strings berechnet, und die beiden Strings unterscheiden sich, wenn i1 = i2 = 6. Zu diesem Zeitpunkt bewegt sich i1 nicht, i2 = next [6] = 3. Wie in der folgenden Abbildung gezeigt
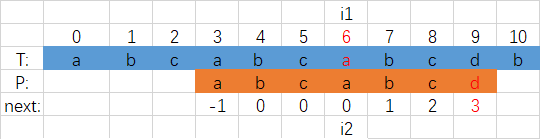
kann die Übereinstimmung erfolgreich sein und i1 -i2 = 3 zurückgeben.
Unten ist der Code ()
Finde das nächste Array
void get_next()
{
Next[0]=-1;
Next[1]=0;
int i=2,k=0;//i是模式串的起始位置,即从第三个字符开始匹配,k是i-1个字符要匹配的位置
int len=s2.size();
while(i<len)
{
if(s2[i-1]==s2[k])//如果i-1和k相等,i后移准备匹配下一个位置,k后移
Next[i++]=++k;
else if(k>0)//没有匹配成功,k移动到next[k]的位置
k=Next[k];
else
Next[i++]=0;//移动到头了,next[i]只能为0了
}
}
km²
int kmp()
{
int i1=0,i2=0;
int len1=s1.size();
int len2=s2.size();
get_next();//获得Next数组
while(i1<len1&&i2<len2)//i1没到头,i2也没到头
{
if(s1[i1]==s2[i2])//相等就齐头并进
{
i1++;
i2++;
}
else if(next[i2]==-1)//模式串到头都没有和主串能匹配的字符,主串往后移
i1++;
else
i2=next[i2];//匹配不成功,i2移动
}
return i2==len2?i1-i2:-1;//i2到头证明匹配成功,否则返回-1
}
Vorlagenfrage: HDU-1711
Pit: Dies ist eine Zahl, kein Zeichen. Verwenden Sie ein ganzzahliges Array, um den
AC-Code zu empfangen
#include<iostream>
#include<cstdio>
#include<string.h>
#include<queue>
#include<cmath>
#include<fstream>
using namespace std;
int Next[200005];
int s1[1000005];
int s2[1000005];
int a,b;
void get_next()
{
Next[0]=-1;
Next[1]=0;
int i=2,k=0;//i是模式串的起始位置,即从第三个字符开始匹配,k是i-1个字符要匹配的位置
int len=b;
while(i<len)
{
if(s2[i-1]==s2[k])//如果i-1和k相等,i后移准备匹配下一个位置,k后移
Next[i++]=++k;
else if(k>0)//没有匹配成功,k移动到next[k]的位置
k=Next[k];
else
Next[i++]=0;//移动到头了,next[i]只能为0了
}
}
int kmp()
{
int i1=0,i2=0;
get_next();
int len1=a;
int len2=b;
while(i2<len2&&i1<len1)//i1没到头,i2也没到头
{
if(s1[i1]==s2[i2])//相等就齐头并进
{
i1++;
i2++;
}
else if(Next[i2]==-1)//模式串到头都没有和主串能匹配的字符,主串往后移
i1++;
else
i2=Next[i2];//匹配不成功,i2移动
}
return i2==len2?i1-i2:-1;//i2到头证明匹配成功,否则返回-1
}
int main(void)
{
int t;
cin>>t;
while(t--)
{
//memset(Next,0,sizeof(Next));
int ans=kmp();
if(ans!=-1)
cout<<ans+1<<endl;
else
cout<<ans<<endl;
}
return 0;
}
Logu P3375
Pit Point: Das nächste Array enthält nicht den längsten Präfix-Suffix-Wert der ersten n-1 Zeichen. Daher füge ich am Anfang ein nutzloses Zeichen hinzu und gebe das nächste Array bei der Ausgabe von 1 aus.
AC-Code
#include<iostream>
#include<cstdio>
#include<string.h>
#include<queue>
#include<cmath>
using namespace std;
int next[2000005];
string s1,s2;
void get_next()
{
next[0]=-1;
next[1]=0;
int i=2,k=0;//i是模式串的起始位置,即从第三个字符开始匹配,k是i-1个字符要匹配的位置
int len=s2.size();
while(i<len)
{
if(s2[i-1]==s2[k])//如果i-1和k相等,i后移准备匹配下一个位置,k后移
next[i++]=++k;
else if(k>0)//没有匹配成功,k移动到next[k]的位置
k=next[k];
else
next[i++]=0;//移动到头了,next[i]只能为0了
}
}
int kmp()
{
int i1=0,i2=0;
get_next();
s2=s2.substr(0,s2.size()-1);
int len1=s1.size();
int len2=s2.size();
while(i1<len1)//i1没到头,i2也没到头
{
if(s1[i1]==s2[i2])//相等就齐头并进
{
i1++;
i2++;
}
else if(next[i2]==-1)//模式串到头都没有和主串能匹配的字符,主串往后移
i1++;
else
i2=next[i2];//匹配不成功,i2移动
if(i2==len2)
{
printf("%d\n",i1-i2+1);
i2=next[i2]; //再次匹配
i1--;
}
}
//return i2==len2?i1-i2:-1;//i2到头证明匹配成功,否则返回-1
}
int main(void)
{
cin>>s1>>s2;
s2+="$";
kmp();
next[0]++;
int len=s2.size();
for(int i=1;i<=len;i++)
{
printf("%d ",next[i]);
}
return 0;
}
Ich habe es den ganzen Nachmittag geschrieben, aber es ist fertig. Bitte gib mir einen Daumen hoch, wenn du es gesehen hast, danke