Verwenden Sie Anfragen
Jetzt, wo es hier ist, lasst uns im Ozean des Wissens schwimmen!

1. Einführung in Anfragen
Das Wichtigste, um eine Webseite zu erhalten, ist, wie Sie einen Browser simulieren, um eine Anfrage an den Server zu senden. Die Bibliotheksanforderungsbibliothek eines Drittanbieters bietet uns eine voll funktionsfähige Verarbeitungsmethode. Lassen Sie uns einen Blick auf die Leistungsfähigkeit von werfen Anfragen Bibliothek!
2. Installieren Sie die Anforderungsbibliothek
- Benutzer von liunx können direkt den Befehlszeilenmodus verwenden: pip3-Installationsanforderungen
- Benutzer von Windows 10 können auch den Befehlszeilenmodus verwenden: Pip-Installationsanforderungen oder Download über Pycharm (der Tutorial-Link ist hier ).
3. Anforderungsmethode der Anforderungsbibliothek
3.1 request.get (URL , Parameter , Header)
Erstellen Sie ein Anforderungsobjekt an den Server und geben Sie ein Antwortobjekt zurück . Dies ist die gebräuchlichste Methode, stellen Sie sicher, dass Sie ein erfahrener Meister sind. Die Hauptattribute der Antwort sind wie folgt:
- text: Die Zeichenfolgenform des HTTP-Antwortinhalts, dh der Seiteninhalt, der der URL entspricht
- Inhalt: Die binäre Form des Inhalts der HTTP-Antwort
- Kodierung: Die Kodierung des Antwortinhalts, der aus dem HTTP-Header erraten wurde
- status_code: Der Rückgabestatus der HTTP-Anforderung, 200 bedeutet, dass die Verbindung erfolgreich ist, 404 bedeutet, dass ein Fehler aufgetreten ist
- Scheinbare_Codierung: Die aus dem Inhalt analysierte Codierungsmethode für den Antwortinhalt (alternative Codierungsmethode)
- Verlauf: Anforderungsverlauf
- Header: Informationen zum Antwortheader
- Cookies: In der Antwort aufgezeichnete Cookies
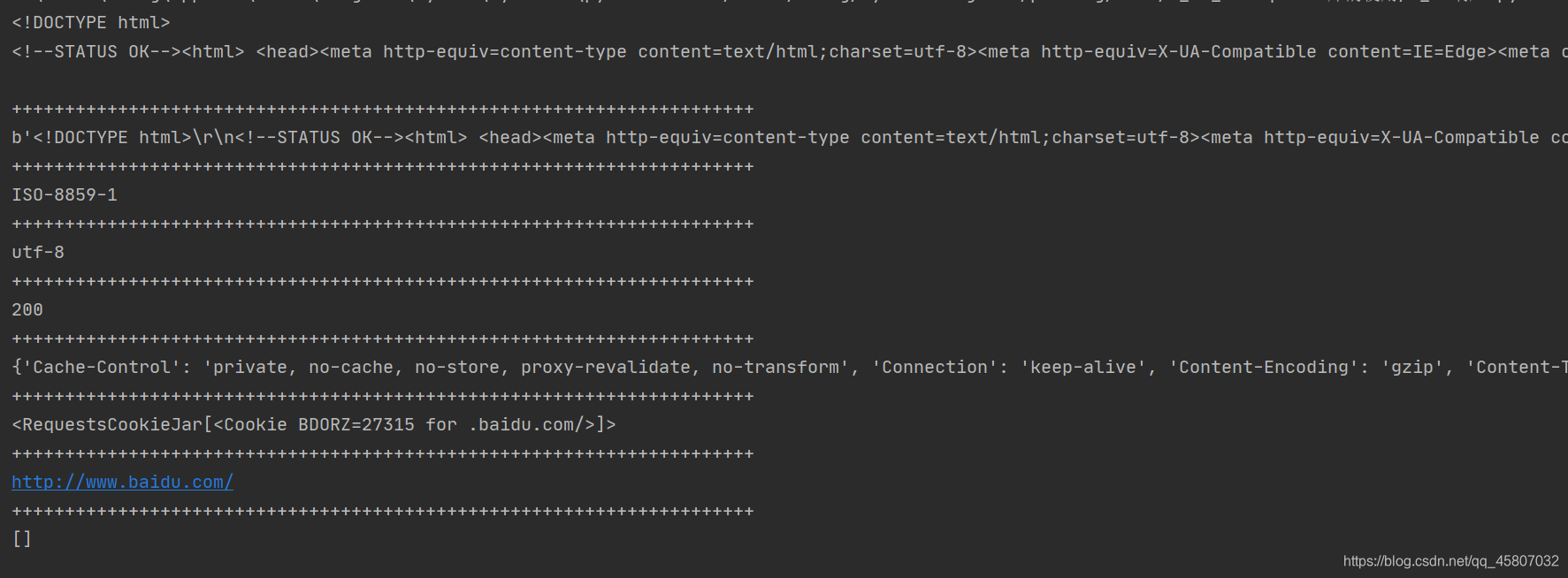
import requests
response = requests.get("http://www.baidu.com")
# 响应的内容文本
print(response.text)
print("+"*70)
# 响应的内容(二进制形式)
print(response.content)
print("+"*70)
# 从响应头部中得到的编码方式
print(response.encoding)
print("+"*70)
# 响应体中得到的编码方式
print(response.apparent_encoding)
print("+"*70)
# 状态码,用查看请求状态
print(response.status_code)
print("+"*70)
# 响应的头部
print(response.headers)
print("+"*70)
# 响应cookies
print(response.cookies)
print("+"*70)
# url
print(response.url)
print("+"*70)
# 请求历史
print(response.history)
Die Parameter-URL bezieht sich auf die URL der Webseite, die gecrawlt werden muss, und die Parameter-Header beziehen sich auf die Header- Informationen , die übergeben werden müssen , z. B. User-Agent, Cookies usw .; params ist der Parameter , der sein muss bestanden , lautet der Beispielcode wie folgt:
import requests
url1 ="http://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
response1 = requests.get(url1,headers=headers)
print(response1.content)
print(response1.text) # 注意区分两者区别
# 抓取二进制数据,如图片,视频等
url2 = "http://github.com/favicon.ico"
response2 = requests.get(url2,headers=headers)
p = open("github.ico","wb")
p.write(response2.content)
print("图片下载完成")
p.close()
Die heruntergeladenen Bilder sind wie folgt:

3.2 request.post (URL, Daten , Datei)
Die Methode zum Senden einer POST-Anforderung an eine HTML-Seite . Die Parameterdaten sind die übermittelten Daten (normalerweise ein Wörterbuch oder ein JSON- Typ), die Datei ist die hochgeladene Datei.
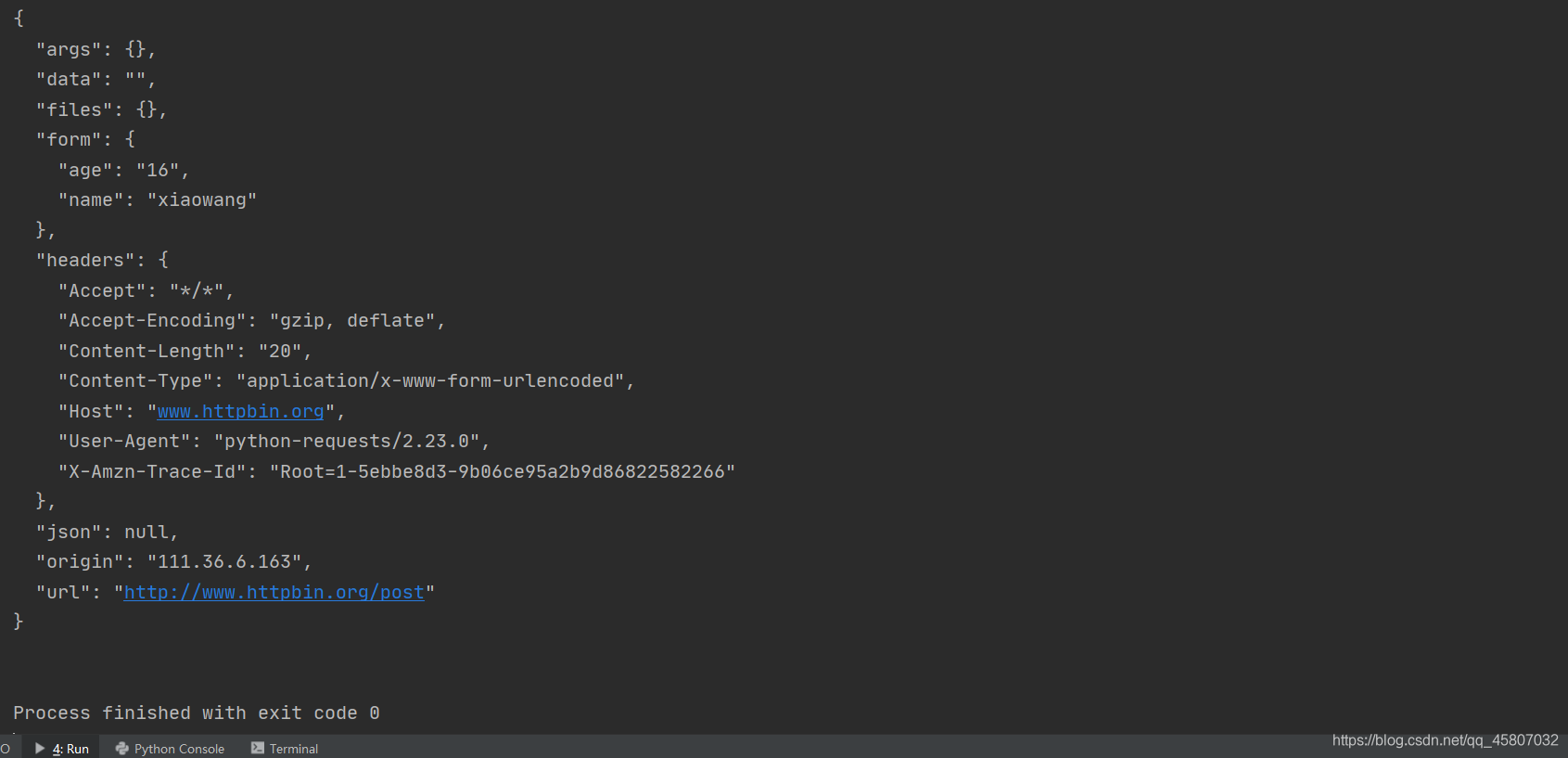
import requests
url='http://www.httpbin.org/post'
data = {
'name':'xiaowang',
'age':'16'
}
response = requests.post(url,data=data)
print(response.text)
Das laufende Ergebnis ist wie folgt, es ist ersichtlich, dass die übermittelten Daten im Formular gespeichert sind .
3.3 request.put ()
Methode zum Senden einer PUT-Anfrage an eine HTML-Seite .
3.4 Anfragen.Kopf ()
Eine Methode zum Abrufen der Header- Informationen einer HTML-Seite .
3.5 request.patch ()
Senden Sie eine teilweise Änderungsanforderung an die HTML-Seite .
3.6 request.delete ()
Senden Sie eine Löschanforderung an die HTML-Seite .

4. Ausnahme der Anforderungsbibliothek
- request.HTTPError: Der Status der HTTP-Webseite ist abnormal , der Statuscode lautet unter normalen Umständen 200
- request.Timeout: Ausnahmebedingung für Anforderungszeitlimit (der gesamte Zeitraum von der Initiierung der URL-Anforderung bis zum Abrufen des Inhalts)
- request.URLRequired: URL fehlt Ausnahme
- request.ConnectTimeout: Bezieht sich nur auf die Verbindung zur Timeout-Ausnahme des Remoteservers
- request.ConnectionError: Anormale Netzwerkverbindungsfehler , z. B. DNS-Abfragefehler, verweigerte Verbindung usw.
- request.TooManyRedirects: Die maximale Anzahl von Weiterleitungen wird überschritten, und es tritt eine Umleitungsausnahme auf .

5. Pflegen Sie die Sitzung
5.1 Warum sollte ich eine Sitzung aufrechterhalten?
Wenn Sie Anforderungsmethoden wie das mehrfache Anfordern einer Webseite direkt verwenden, erkennt der andere Teilnehmer unter normalen Umständen nicht, dass es sich um eine Sitzung handelt, dh , jede Anforderung ist eine neue Sitzung . Wenn Sie sich anmelden müssen, müssen Sie die Website-Informationen mehrmals crawlen. Anschließend wird ein Fehler generiert (die erste Anforderung ist die Anmeldung, die zweite Anforderung ist jedoch nicht die Anmeldung). Zu diesem Zeitpunkt spielt die Aufrechterhaltung der Sitzung eine entsprechende Rolle. Das von der Anforderungsbibliothek bereitgestellte Sitzungsobjekt kann uns dabei helfen, eine Sitzung einfach zu verwalten, ohne sich um andere Probleme kümmern zu müssen. Werfen wir einen Blick auf die Rolle der Sitzung!
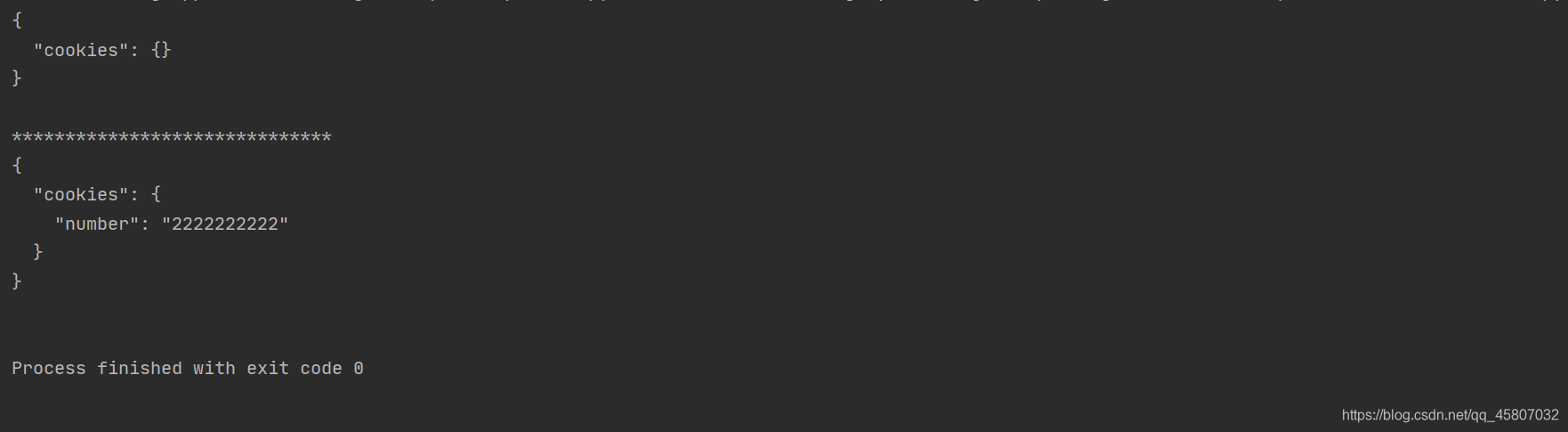
import requests
# 普通的多次的登录并不会保存相同的cookies
r1 = requests.get("http://www.httpbin.org/cookies/set/number/11111111111")
r2 = requests.get("http://www.httpbin.org/cookies")
print(r2.text)
print("*"*30)
s = requests.session() # 建立会话对象
s.get("http://www.httpbin.org/cookies/set/number/2222222222") # 通过会话对象进行请求操作,设置cookies
response = s.get("http://www.httpbin.org/cookies") # 同一会话再次请求,查询cookies
print(response.text)
Die Ergebnisse sind wie folgt. Es kann festgestellt werden, dass Sitzung r1 unter normalen Umständen die Cookies für diese Sitzung setzt, die Cookies jedoch bei erneuter Anforderung nicht mehr dieselben sind, was darauf hinweist, dass es sich nicht mehr um dieselbe Sitzung handelt und die beiden Cookies im Sitzungsstatus identisch sind Dies zeigt an, dass dies dieselbe Sitzung ist. Daher wird die Sitzung häufig für Vorgänge mit simulierter Anmeldung verwendet .
6. Überprüfung des SSL-Zertifikats
Einige verschlüsselte Websites müssen von der offiziellen CA-Organisation als vertrauenswürdig eingestuft werden . Wenn sie nicht zertifiziert sind, treten Fehler bei der Zertifikatsüberprüfung auf .
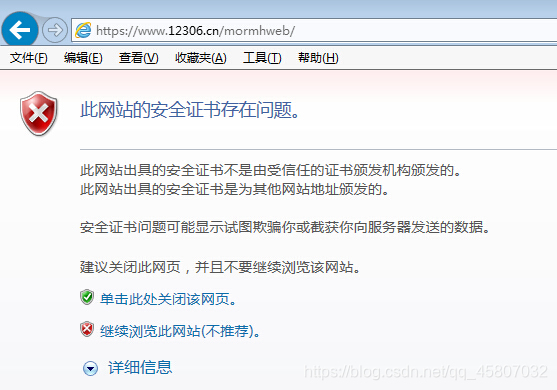
Wenn wir beim Crawlen die Website direkt anfordern, wird die Ausnahme SSLError ausgelöst , die auf einen Zertifikatüberprüfungsfehler hinweist. Keine Sorge, die Anforderungsbibliothek hat bereits über eine Lösung für uns nachgedacht. Es stellt einen Parameter überprüfen , was von True Standard (das Zertifikat nicht überprüft) , wir es nur auf False einstellen müssen. Zu diesem Zeitpunkt erhalten wir jedoch eine Warnung , und wir können damit umgehen , indem wir die Warnung ignorieren . Details wie folgt:
import requests
from requests.packages import urllib3
urllib3.disable_warnings() # 忽视警告
response = requests.get("https://www.12306.cn")
print(response.status_code)
Crawlen Sie zu diesem Zeitpunkt die Website erneut und Sie können sie normal besuchen.

7. Proxy-Einstellungen
7.1 Was ist ein Proxy?
Während des eigentlichen Crawlerprozesses erkennt der Server die Zugriffshäufigkeit einer bestimmten IP-Adresse. Da die Crawlerhäufigkeit des Crawlers zu schnell ist , zeigen einige Websites eine Überprüfungsaufforderung an oder blockieren die IP-Adresse direkt oder geben die falschen Dateninformationen leise zurück . Um dieses Problem zu lösen, müssen wir unsere IP-Adresse verschleiern und dann einen Proxy. Der Proxy ist eigentlich ein Proxyserver , und seine Funktion besteht darin, Benutzer zu vertreten, um Netzwerkinformationen abzurufen. Optisch ist es ein Agent. Verwenden Sie Agenten, um Daten für uns zu crawlen, damit wir das Problem lösen können.

7.2 Proxy einrichten
Die leistungsfähigen Anfragen ein Parametersatz auf Proxies für uns den Proxy einzurichten. Der Parameter Proxys ist ein Wörterbuch, der Schlüssel ist das Protokoll und der Schlüssel ist die IP und der Port. Die Details sind wie folgt (der Agent hier ist nicht real):
import requests
proxies = {
"http":"127.0.0.1:1314",
"https":"127.0.0.1:2345"
}
response = requests.get(url,proxies)
print(response.text)
Wenn der Proxyserver einen Benutzernamen und ein Kennwort benötigt , können Sie diese wie folgt festlegen:
proxies = {
"http":"username:[email protected]:1314",
"https":"username:[email protected]:2345"
8. Timeout-Einstellungen
Es dauert eine gewisse Zeit, bis wir den übergeordneten Server anfordern und seine Antwort erhalten. Wir warten manchmal besonders lange. Um zu verhindern , dass der Server rechtzeitig eine Antwort erhält , stellt die Anforderungsbibliothek einen Zeitüberschreitungsparameter t imeout bereit . Wenn innerhalb der angegebenen Zeit keine Antwort eingeht, wird eine Ausnahme ConnectTimeout ausgelöst. Wir können also damit umgehen , indem wir die catch-Ausnahme setzen .
import requests
response = requests.get("http://www.baidu.com",timeout=0.01)
print(response)

9. Identitätsprüfung
Beim Zugriff auf das Internet können Authentifizierungsprobleme auftreten . Zu diesem Zeitpunkt tritt eine Ausnahme auf, wenn Sie sich direkt anmelden. Der auth- Parameter der Anforderungsbibliothek bietet uns eine Anmeldemethode. auth ist ein Tupel, Element 1 ist der Benutzername und Element 2 ist das Passwort.
import requests
auth = ("username","password") # 元组,用户名,密码
response = requests.get("http://www.baidu.com",auth=auth) # 此url请更换
print(response.status_code)
10. Anforderungsmethode
我们可以将请求表示为**数据结构**,将各个参数都通过一个request来表示,这样我们就可以将请求当做**独立的对象**来看待,这在后续进行**队列调度**时会非常方便。如下实例:
import requests
url = "http://www.httpbin.org/post"
data={
"name":"xiaoming",
"age":"18"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
s = requests.Session()
request = requests.Request("post",url,data=data,headers=headers)
prepared = s.prepare_request(request)
response = s.send(prepared)
print(response.text)
Ab heute werden von Zeit zu Zeit Artikel über Crawler veröffentlicht, und der Inhalt ist etwas unzureichend. Ich möchte alle um Ihren Rat bitten, verzeihen Sie mir!
