1. Einführung in
dplyr dplyr ist ein Datenanalysepaket in R-Sprache, ähnlich wie Pandas in Python, das sehr bequeme Datenverarbeitungs- und Analysevorgänge für Daten vom Typ Datenrahmen ausführen kann. Zuerst war ich auch von dem seltsamen Namen dplyr überrascht. Ich fand eine der Erklärungen-d steht für dataframe-plyr ist ein Homophon für eine Zange in Englisch
dplyr ist wie die meisten R-Pakete eine funktionale Programmierung, die sich stark von der objektorientierten Python-Programmierung unterscheidet. Der Vorteil ist, dass Anfänger diese Art des funktionalen Denkens eher akzeptieren, das einem Fließband ähnelt. Jede Funktion ist eine Werkstatt, und mehrere Werkstätten erledigen gemeinsam eine Produktionsaufgabe (Datenanalyse).
In dplyr gibt es ein Pipe-Symbol%>%. Die linke Seite des Symbols repräsentiert die Eingabe von Daten und die rechte Seite repräsentiert die nachgeschaltete Datenverarbeitungsverbindung.
2. Installieren und importieren Sie
die Funktion p_load der dplyr-Bibliothek, die die pacman-Bibliothek enthält
- install.packages ("dplyr")
- Bibliothek (dplyr)
ist einfacher zu bedienen
pacman :: p_load ("dplyr")
**3. 读取数据**
#Stellen Sie das Arbeitsverzeichnis setwd ein ("/ Users / thunderhit / Desktop / dplyr_learn")
# CSV- Daten importieren aapl <- read.csv ('aapl.csv',
Header = TRUE,
sep = ',',
stringsAsFactors = FALSE)%>% as_tibble ()
head ( aapl )
A tibble: 6 × 6

查看数据类型Klasse (aapl)
'tbl_df'
'tbl'
'data.frame'
查看数据的字段
Spaltennamen (aapl)
'Date'
'Open'
'High'
'Low'
'Close'
'Volume'
查看记录数、字段数dim (aapl)
251
6
**4. dplyr常用函数**
**4.1 Arrange**
对appl数据按照字段Volume进行降序排序arrangieren (aapl, -Volume)
A tibble: 6 × 6

我们也可以用管道符 %>% ,两种写法得到的运行结果是一致的,可能用久了会觉得管道符 %>% 可读性更强,后面我们都会用 %>% 来写代码。aapl%>% arrangieren (-Volume)
A tibble: 6 × 6

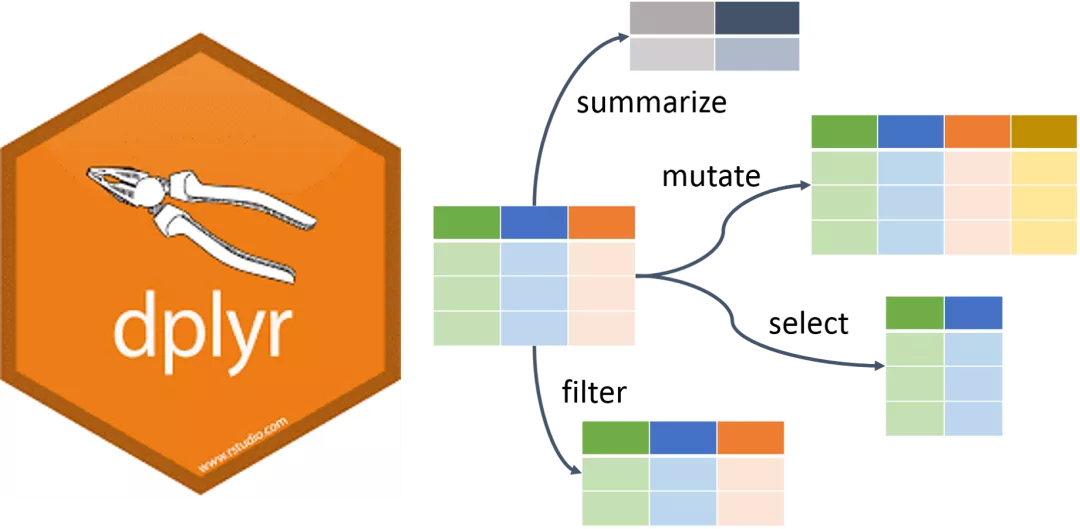
**4.2 Select**
选取 Date、Close和Volume三列aapl%>% select (Datum, Abschluss, Lautstärke)

只选取Date、Close和Volume三列,其实另外一种表达方式是“排除Open、High、Low,选择剩下的字段的数据”。aapl%>% select (-c ("Öffnen", "Hoch", "Niedrig"))

**4.3 Filter**
按照筛选条件选择数据#Wählen Sie aus den Daten die Transaktionsdaten mit einem Aktienkurs von mehr als 150 USD
aapl%>% Filter (Schließen> = 150).

从数据中选择appl - 股价大于150美元 且 收盘价大于开盘价 的交易数据aapl%>% filter ((Schließen> = 150) & (Schließen> Öffnen))

**4.4 Mutate**
将现有的字段经过计算后生成新字段。# Definieren Sie das Ergebnis des besten Preises Hoch minus des niedrigsten Preises Niedrig als maxDif und nehmen Sie log aapl
%>% mutate (maxDif = Hoch-Niedrig,
log_maxDif = log (maxDif))

得到记录的位置(行数)aapl%>% mutate (n = row_number ())

**4.5 Group_By**
对资料进行分组,这里导入新的 数据集 weather
# Import von CSV - Daten Wetter <- read.csv ( 'weather.csv',
= Kopf TRUE,
sep = '',
stringsAsFactors = FALSE)%>% as_tibble ()
Wetter

按照城市分组Wetter%>% group_by (Stadt)
Damit jeder die Auswirkungen der Gruppierung sehen kann, berechnen wir die Durchschnittstemperatur nach Stadt.
Wetter%>% group_by (Stadt)%>% zusammenfassen (mittlere_Temperatur = Mittelwert (Temperatur))
`summarise()` ungrouping output (override with `.groups` argument)
Wetter%>% zusammenfassen (mittlere_Temperatur = Mittelwert (Temperatur))
