Inschrift
Fragen aus der chinesischen Community von Elasticsearch -
Es gibt kein eindeutiges inkrementelles Feld und kein eindeutiges inkrementelles Zeitfeld für Tabellen in MySQL. Wie kann mit logstash ein inkrementeller Echtzeitdatenimport von MySQL nach es realisiert werden?
Sowohl logstash als auch kafka_connector unterstützen nur die inkrementelle Synchronisation von Daten basierend auf der selbstinkrementierenden ID oder der Aktualisierung des Zeitstempels.
Zurück zur Frage selbst: Was soll ich tun, wenn die Bibliothekstabelle keine verwandten Felder enthält?
Dieser Artikel enthält relevante Diskussionen und Lösungen.
1. Binlog-Erkennung
1.1 Was ist binlog?
Binlog ist ein Binärprotokoll, das von der MySQL-Serverschicht verwaltet wird. Es ist ein völlig anderes Protokoll als das Wiederherstellungs- / Rückgängig-Protokoll in der InnoDB-Engine. Es wird hauptsächlich zum Aufzeichnen von SQL-Anweisungen verwendet, die MySQL-Daten aktualisieren oder möglicherweise aktualisieren, und zum Verwenden von "Transaktionen". Das Formular wird auf der Festplatte gespeichert.
Die Hauptfunktionen sind:
- 1) Replikation: Um das Ziel konsistenter Master-Slave-Daten zu erreichen.
- 2) Datenwiederherstellung: Stellen Sie Daten mit dem Tool mysqlbinlog wieder her.
- 3) Inkrementelle Sicherung.
1.2 Alis Kanal realisiert eine inkrementelle MySQL-Synchronisation
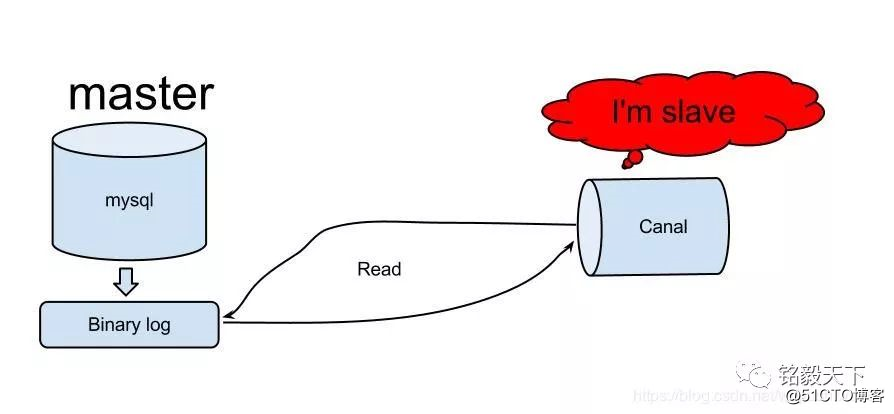
Ein Bild sagt mehr als tausend Worte. Canal ist eine in Java entwickelte Middleware, die auf einer inkrementellen Datenbankanalyse basiert und inkrementelle Datenabonnements und -verwendung ermöglicht.
Derzeit unterstützt Canal hauptsächlich das Parsing von MySQL-Binlog, und der Canal-Client wird verwendet, um die zugehörigen Daten nach Abschluss des Parsing zu verarbeiten. Zweck: inkrementelles Datenabonnement und -verbrauch.
Zusammenfassend kann die Verwendung von binlog die Einschränkungen von logstash oder kafka-connector ohne selbstinkrementierende ID oder ohne Zeitstempelfeld durchbrechen und eine inkrementelle Synchronisation erreichen.
2. Synchronisationsmethode basierend auf binlog
1) Debezium Open Source Projekt basierend auf kafka Connect, Adresse: https://debezium.io/
2) Unabhängige Anwendungen, die nicht auf Dritte angewiesen sind: Maxwell Open Source-Projekt, Adresse: http://maxwells-daemon.io/
Da conluent (die Enterprise-Version von kafka, die mit zookeeper, kafka, ksql, kafka-connector usw. geliefert wird) bereitgestellt wurde, ist dieser Artikel nur für Debezium bestimmt.
3. Einführung in Debezium
Debezium ist eine verteilte Open-Source-Synchronisationsplattform, die dynamische Datenänderungen in Echtzeit erfasst. Echtzeiterfassung von Datenquellen (MySQL, Mongo, PostgreSql): Hinzufügen (Einfügen), Aktualisieren (Aktualisieren), Löschen (Löschen), Echtzeitsynchronisation mit Kafka, starke Stabilität und sehr schnell.
Eigenschaften:
- 1) Einfach. Die Anwendung muss nicht geändert werden. Kann externe Dienste bereitstellen.
- 2) Stabil. Behalten Sie jede Änderung in jeder Zeile im Auge.
- 3) Schnell. Es basiert auf Kafka, ist skalierbar und kann nach offizieller Überprüfung Daten mit großer Kapazität verarbeiten.
4. Synchrone Architektur
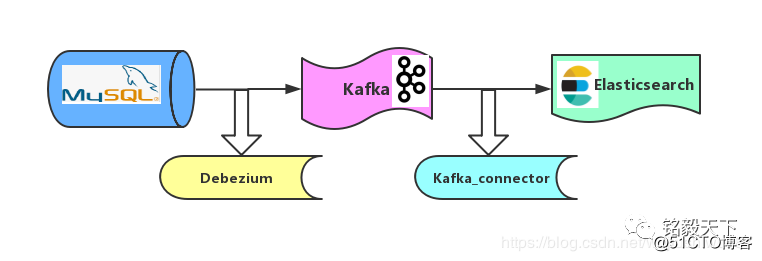
Wie in der Abbildung gezeigt, übernimmt die Synchronisationsstrategie von MySQL zu ES den Mechanismus "Kurve zur Rettung des Landes".
Schritt 1: Synchronisieren Sie MySQL-Daten basierend auf dem Binlog-Mechanismus von Debezium mit Kafka.
Schritt 2: Synchronisieren Sie die Kafka-Daten basierend auf dem Kafka_connector-Mechanismus mit Elasticsearch.
5. Debezium realisiert die Echtzeitsynchronisation von MySQL mit ES zum Hinzufügen, Löschen und Ändern
Softwareversion:
konfluent: 5.1.2 -
Debezium: 0.9.2_Final;
MySQL: 5.7.x.
Elasticsearch: 6.6.1
5.1 Debezium-Installation
Informationen zur Installation und Bereitstellung von Confluent finden Sie unter: http://t.cn/Ef5poZk. Daher werde ich hier nicht auf Details eingehen .
Bei der Installation von Debezium muss nur das komprimierte Paket von debezium-connector-mysql entpackt und im dekomprimierten Plug-In-Verzeichnis (share / java) von Confluent abgelegt werden.
Download-Link des komprimierten MySQL Connector-Plugin-Pakets:
Achten Sie darauf, Confluent neu zu starten, damit Debezium wirksam wird.
5.2 MySQL-Binlog und andere verwandte Konfigurationen.
Debezium verwendet den Binlog-Mechanismus von MySQL, um dynamische Datenänderungen zu überwachen. Daher muss MySQL Binlog im Voraus konfigurieren.
Die Kernkonfiguration lautet wie folgt: Fügen Sie die folgende Konfiguration unter mysqld in /etc/my.cnf des MySQL-Computers hinzu.
1[mysqld]
2
3server-id = 223344
4log_bin = mysql-bin
5binlog_format = row
6binlog_row_image = full
7expire_logs_days = 10Starten Sie dann MySQL neu, damit binlog wirksam wird.
1systemctl start mysqld.service5.3 Konfigurieren Sie den Stecker.
Konfigurieren Sie das konfluente Pfadverzeichnis: / etc.
Befehl zum Erstellen eines Ordners:
1mkdir kafka-connect-debeziumSpeichern Sie die Konfigurationsinformationen des Connectors in mysql2kafka_debezium.json:
1[root@localhost kafka-connect-debezium]# cat mysql2kafka_debezium.json
2{
3 "name" : "debezium-mysql-source-0223",
4 "config":
5 {
6 "connector.class" : "io.debezium.connector.mysql.MySqlConnector",
7 "database.hostname" : "192.168.1.22",
8 "database.port" : "3306",
9 "database.user" : "root",
10 "database.password" : "XXXXXX",
11 "database.whitelist" : "kafka_base_db",
12 "table.whitlelist" : "accounts",
13 "database.server.id" : "223344",
14 "database.server.name" : "full",
15 "database.history.kafka.bootstrap.servers" : "192.168.1.22:9092",
16 "database.history.kafka.topic" : "account_topic",
17 "include.schema.changes" : "true" ,
18 "incrementing.column.name" : "id",
19 "database.history.skip.unparseable.ddl" : "true",
20 "transforms": "unwrap,changetopic",
21 "transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope",
22 "transforms.changetopic.type":"org.apache.kafka.connect.transforms.RegexRouter",
23 "transforms.changetopic.regex":"(.*)",
24 "transforms.changetopic.replacement":"$1-smt"
25 }
26}Beachten Sie die folgende Konfiguration:
- "database.server.id" entspricht der Konfiguration der Server-ID in MySQL.
- "database.whitelist": Der Name der zu synchronisierenden MySQL-Datenbank.
- "table.whitlelist": Der Name der zu synchronisierenden Mysq-Tabelle.
- Wichtig: "database.history.kafka.topic": Speichert die Shcema-Datensatzinformationen der Datenbank, nicht das Thema.
- "database.server.name": Der logische Name, jeder Connector ist eindeutig, als Präfixname des Kafka-Themas, in das Daten geschrieben werden.
Pit 1: Transformiert die zugehörige 5-Zeilen-Konfigurationsfunktion zum Schreiben der Datenformatkonvertierung.
Wenn nicht, enthalten die Eingabedaten: vor, nach, vor und nach der Datensatzänderung sowie Metadateninformationen (Quelle, op, ts_ms usw.).
Diese Informationen werden beim anschließenden Schreiben von Daten in Elasticsearch nicht benötigt. (Achten Sie darauf, Ihre eigenen Geschäftsszenarien zu kombinieren).
Grundsätze für die Formatkonvertierung: http://t.cn/EftoaIi
5.4 Starten Sie den Stecker
1curl -X POST -H "Content-Type:application/json"
2--data @mysql2kafka_debezium.json.json
3http://192.168.1.22:18083/connectors | jq5.5 Stellen Sie sicher, dass das Schreiben erfolgreich ist.
5.5.1 Kafka-Thema anzeigen
1 kafka-topics --list --zookeeper localhost:2181Hier sehen Sie die Informationen, die in das Datenthema geschrieben wurden.
Achten Sie auf das Format des neu geschriebenen Datenthemas: database.schema.table-smt besteht aus drei Teilen.
Themenname dieses Beispiels:
full.kafka_base_db.account-smt
5.5.2 Das Schreiben zur Überprüfung der Verbrauchsdaten ist normal
1./kafka-avro-console-consumer --topic full.kafka_base_db.account-smt --bootstrap-server 192.168.1.22:9092 --from-beginningZu diesem Zeitpunkt hat Debezium die MySQL-Synchronisations-Kafka abgeschlossen.
In 6 realisiert der Kafka-Konnektor die Kafka-Synchronisation Elasticsearch
6.1 Einführung in den Kafka-Stecker
Siehe offizielle Website: https://docs.confluent.io/current/connect.html
Kafka Connect ist ein Framework zum Verbinden von Kafka mit externen Systemen (z. B. Datenbanken, Schlüsselwertspeichern, Abrufsystemindizes und Dateisystemen).
Der Connector erkennt, dass allgemeine Datenquellendaten (wie MySQL, Mongo, Pgsql usw.) in Kafka geschrieben werden oder Kafka-Daten in die Zieldatenbank geschrieben werden, oder Sie können Ihren eigenen Connector entwickeln.
6.2, Synchronisierungskonfiguration für Kafka-ES-Steckverbinder
Konfigurationspfad:
1/home/confluent-5.1.0/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.propertiesKonfigurationsinhalt:
1"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
2"tasks.max": "1",
3"topics": "full.kafka_base_db.account-smt",
4"key.ignore": "true",
5"connection.url": "http://192.168.1.22:9200",
6"type.name": "_doc",
7"name": "elasticsearch-sink-test"6.3 Kafka-ES-Startstecker
Befehl starten
1confluent load elasticsearch-sink-test
2-d /home/confluent-5.1.0/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties6.4 RESTFul-API-Ansicht für Kafka-Connector
Die Connector-Details von Mysql2kafka und kafka2ES können mithilfe eines Postboten oder eines Browsers oder einer Befehlszeile angezeigt werden.
1curl -X GET http://localhost:8083/connectors7. Pit Replay.
Pit 2: Während des Synchronisierungsprozesses können Fehler auftreten, zum Beispiel: Das Kafka-Thema kann keine Daten verbrauchen.
Die Ideen zur Fehlerbehebung lauten wie folgt:
-
1) Bestätigen Sie, ob das konsumierte Thema das Thema des Datenschreibens ist.
- 2) Stellen Sie sicher, dass während der Synchronisation kein Fehler vorliegt. Mit dem Connector können Sie die folgenden Befehle anzeigen.
1curl -X GET http://localhost:8083/connectors-xxx/statusPit 3: Mysql2ES erkennt das Datumsformat nicht.
Dies ist das Problem des MySQL-JAR-Pakets. Die Lösung: Konfigurieren Sie die Zeitzoneninformationen in my.cnf.
Pit 4: Kafka2ES, ES schreibt keine Daten.
Ideen zur Fehlerbehebung:
- 1) Vorschlag: Erstellen Sie zunächst einen Index, der mit dem Themennamen übereinstimmt. Hinweis: Die Zuordnung ist statisch angepasst, nicht die dynamische Identifizierung und Generierung.
- 2) Analysieren Sie die Fehlerursache über den Konnektor / Status und analysieren Sie sie Schritt für Schritt.
8. Zusammenfassung
-
Die Realisierung von binlog durchbricht die Begrenzung des Feldes. Tatsächlich wurde die Go-MySQL-Elasticsearch der Branche implementiert.
-
Vergleich: Logstash, Kafka-Konnektor, obwohl Debezium "Kurve, um das Land zu retten" zwei Schritte, um Echtzeit-Synchronisation zu erreichen, aber die Stabilität + Echtzeit-Leistung ist relativ gut.
- Empfehlen Sie jedem zu verwenden. Wenn Sie eine gute Synchronisationsmethode haben, hinterlassen Sie bitte eine Nachricht zum Besprechen und Austauschen.
Referenz:
[1] http://t.cn/EftX2p8
[2] http://t.cn/EftXJU6
[3] http://t.cn/EftXO8c
[4] http://t.cn/EftXn9M
[5] http://t.cn/EftXeOc
Empfohlene Lektüre:
Blockbuster | Elasticsearch Methodology Cognitive List (Frühjahrsfest-Update 2019) 
Elasticsearch Basic, Advanced und aktueller erster öffentlicher Account