1 Generatives Modell und diskriminatives Modell
Unter Berücksichtigung der Eingangsvariablen x berechnet das generative Modell die gemeinsame Wahrscheinlichkeitsverteilung P (x, y) für die Beobachtungen und beschrifteten Daten, um den Zweck der Bestimmung des geschätzten y zu erreichen. Das Diskriminanzmodell sagt y voraus, indem es die bedingte Wahrscheinlichkeitsverteilung P (y | x) löst oder den Wert von y direkt berechnet.
Übliche Diskriminanzmodelle sind lineare Regression, logistische Regression, Support Vector Machine (SVM), traditionelle neuronale Netze (traditionelle neuronale Netze), lineare diskriminative Analyse, bedingtes Zufallsfeld (bedingter Zufall) Feld); gängige generative Modelle sind Naive Bayes (Naive Bayes), Hidden Markov Model (HMM), Bayesian Networks (Bayesian Networks) und Latent Dirichlet Allocation (Latent Dirichlet Allocation).
2 Grundlegende Methoden der chinesischen Wortsegmentierung
Die grundlegenden Methoden der chinesischen Wortsegmentierung können in Methoden unterteilt werden, die auf grammatikalischen Regeln basieren, Methoden, die auf Wörterbüchern basieren, und Methoden, die auf Statistiken basieren.
Die Grundidee der auf grammatikalischen Regeln basierenden Wortsegmentierung besteht darin, gleichzeitig mit der Wortsegmentierung eine syntaktische und semantische Analyse durchzuführen und syntaktische Informationen und semantische Informationen zu verwenden, um eine Teil-der-Sprache-Kennzeichnung durchzuführen, um die Mehrdeutigkeit der Wortsegmentierung zu lösen. Da die vorhandenen grammatikalischen Kenntnisse und Syntaxregeln sehr allgemein und komplex sind, ist die durch grammatikalische und regelbasierte Wortsegmentierung erzielte Genauigkeit bei weitem nicht zufriedenstellend. Derzeit werden solche Wortsegmentierungssysteme selten verwendet.
Bei der wörterbuchbasierten Methode kann sie weiter in eine Methode mit maximaler Übereinstimmung, eine Methode mit maximaler Wahrscheinlichkeit, eine Methode mit kürzestem Pfad usw. unterteilt werden. Die Methode der maximalen Übereinstimmung bezieht sich auf die Auswahl einer Anzahl von Wörtern in einer Zeichenfolge als Wort in einer bestimmten Reihenfolge und die Suche in einem Wörterbuch. Gemäß dem Scanverfahren kann es unterteilt werden in: maximale Vorwärtsanpassung, maximale Rückwärtsanpassung, bidirektionale maximale Übereinstimmung und minimale Segmentierung. Die Methode mit maximaler Wahrscheinlichkeit bezieht sich darauf, dass eine zu segmentierende chinesische Zeichenfolge mehrere Wortsegmentierungsergebnisse enthalten kann und diejenige mit der höchsten Wahrscheinlichkeit als Wortsegmentierungsergebnis der Wortzeichenfolge verwendet wird. Die Methode mit dem kürzesten Pfad bezieht sich auf die Auswahl eines Pfads mit den wenigsten Wörtern im Wortdiagramm.
Das Grundprinzip der statistischen Wortsegmentierung besteht darin, anhand der statistischen Häufigkeit der Zeichenfolge im Korpus zu bestimmen, ob eine Zeichenfolge ein Wort darstellt. Ein Wort ist eine Kombination von Wörtern. Je häufiger benachbarte Wörter vorkommen, desto wahrscheinlicher ist es, dass es ein Wort bildet. Daher kann die Häufigkeit oder Wahrscheinlichkeit des gleichzeitigen Auftretens von Wörtern neben Wörtern ihre Glaubwürdigkeit als Wörter besser widerspiegeln. Häufig verwendete Methoden sind HMM (Hidden Markov Model), MAXENT (Maximum Entropy Model), MEMM (Maximum Entropy Hidden Markov Model), CRF (Conditional Random Field).
3 Vergleichende Analyse von CRF-Modell, HMM-Modell und MEMM-Modell
Referenz https://www.cnblogs.com/hellochennan/p/6624509.html
4 Viterbi-Algorithmus
5ID3-Algorithmus
Die Kernidee des ID3-Algorithmus besteht darin, Attribute für die Messung des Informationsgewinns auszuwählen und das Attribut mit dem größten Informationsgewinn nach dem Teilen zum Teilen auszuwählen. Die Einschränkung des ID3-Algorithmus besteht darin, dass seine Attribute nur diskrete Werte annehmen können. Um den Entscheidungsbaum auf kontinuierliche Attributwerte anwendbar zu machen, kann ein erweiterter Algorithmus C4.5 von ID3 verwendet werden. Die BC-Optionen sind alle Merkmale des ID3-Algorithmus. Der vom ID3-Algorithmus generierte Entscheidungsbaum ist ein Multi-Fork-Baum, und die Anzahl der Verzweigungen hängt davon ab, wie viele verschiedene Werte das Split-Attribut hat.
6 Überanpassungsprobleme
Die Hauptgründe für eine Überanpassung beim maschinellen Lernen sind: (1) Verwendung zu komplexer Modelle, (2) die Daten sind verrauscht und (3) es gibt nur wenige Trainingsdaten.
Die entsprechenden Methoden zur Reduzierung der Überanpassung sind: (1) Vereinfachung der Modellannahmen oder Verwendung von Strafbegriffen zur Begrenzung der Modellkomplexität; (2) Durchführung einer Datenbereinigung zur Reduzierung des Rauschens und (3) Erfassung weiterer Trainingsdaten.
7 Berechnen Sie die bedingte Entropie H (Y | X)
Es gibt zwei Berechnungsformeln für die bedingte Entropie
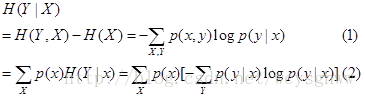
Wählen Sie die entsprechende Formel aus, um sie anhand der im Titel angegebenen Wahrscheinlichkeit zu berechnen
8Fisher lineare Diskriminanzfunktion
http://blog.csdn.net/yujianmin1990/article/details/48007589
Die lineare Diskriminanzfunktion von Fisher besteht darin, Merkmalsvektoren im mehrdimensionalen Raum auf eine gerade Linie zu projizieren, dh die Dimension auf eine Dimension zu komprimieren. Das Kriterium zum Finden dieser optimalen Geraden ist das Fisher-Kriterium: Die Projektion der beiden Arten von Proben im eindimensionalen Raum sollte innerhalb der Klasse so dicht wie möglich sein, so weit wie möglich zwischen den Klassen, dh der Unterschied zwischen dem Mittelwert der beiden Arten von Proben nach der Projektion sollte so groß wie möglich sein Die Varianz ist so gering wie möglich. Im Allgemeinen kann das lineare Kriterium von Fisher für den Fall, dass die Datenverteilung der Gaußschen Verteilung ähnlich ist, einen guten Klassifizierungseffekt erzielen.
9HMM-Parameterschätzungsmethode
EM-Algorithmus: Nur die Beobachtungssequenz, zustandslose Sequenz zum Lernen der Modellparameter,
dh Baum-Welch-Algorithmus Viterbi-Algorithmus: Verwenden Sie die dynamische Programmierung, um das HMM-Vorhersageproblem zu lösen, nicht die Parameterschätzung.
Vorwärts- und Rückwärtsalgorithmus: Wird zur Berechnung der Wahrscheinlichkeit der
maximalen Wahrscheinlichkeit verwendet Zufällige Schätzung: Der überwachte Lernalgorithmus, wenn sowohl die Beobachtungssequenz als auch die entsprechende Zustandssequenz existieren, um die Parameter zu schätzen
10 Verständnis des Naive Bayes-Klassifikators
Die Bedingung von Naive Bayes ist, dass jede Variable unabhängig voneinander ist. Im Bayes'schen Theoriesystem gibt es eine wichtige Annahme der bedingten Unabhängigkeit: Es wird angenommen, dass alle Merkmale unabhängig voneinander sind, so dass die gemeinsame Wahrscheinlichkeit aufgeteilt werden kann.
Wenn stark korrelierte Merkmale zweimal in das Modell eingeführt werden, was die Bedeutung dieses Merkmals erhöht, wird seine Leistung verringert, da die Daten stark korrelierte Merkmale enthalten. Der richtige Ansatz besteht darin, die Korrelationsmatrix von Merkmalen zu bewerten und diese stark korrelierten Merkmale zu entfernen.
11 Mahalanobis-Distanzanwendung
Der Mahalanobis-Abstand basiert auf der Chi-Quadrat-Verteilung, einer statistischen Methode zur Messung mehrerer Ausreißer.
Wenn die Kovarianzmatrix eine Identitätsmatrix ist (jeder Probenvektor ist unabhängig und identisch verteilt), ist dies der euklidische Abstand.
Wenn die Kovarianzmatrix diagonal ist, wird die Formel zum standardisierten euklidischen Abstand.
(2) Die Vor- und Nachteile der Mahalanobis-Distanz: Die Dimension ist irrelevant und die Interferenz der Korrelation zwischen Variablen ist ausgeschlossen.
12 Der Unterschied zwischen "Bootstrap" und "Boosting"
13 Verständnis der Probleme von Überanpassung / hoher Varianz und Unteranpassung / hoher Vorspannung
Eine Überanpassung ist darauf zurückzuführen, dass das trainierte Modell zu kompliziert ist. Der Fehler im Trainingssatz ist gering, aber die Generalisierungsfähigkeit ist schwach. Die allgemeinen Lösungen sind:
收集更多的训练数据;简化特征;增加正则化项的系数lambda
欠拟合是模型没有充分学到数据中的信息,在训练集和测试集上的误差都很大,一般的解决办法有:
增加特征;增加多项式特征;减小正则化项的系数。
14对svm常用的几种核函数的理解
SVM核函数包括线性核函数、多项式核函数、径向基核函数、高斯核函数、幂指数核函数、拉普拉斯核函数、ANOVA核函数、二次有理核函数、多元二次核函数、逆多元二次核函数以及Sigmoid核函数. 核函数的定义并不困难,根据泛函的有关理论,只要一种函数 K ( x i , x j ) 满足Mercer条件,它就对应某一变换空间的内积.对于判断哪些函数是核函数到目前为止也取得了重要的突破,得到Mercer定理和以下常用的核函数类型: (1)线性核函数 K ( x , x i ) = x ⋅ x i (2)多项式核 K ( x , x i ) = ( ( x ⋅ x i ) + 1 ) d (3)径向基核(RBF) K ( x , x i ) = exp ( − ∥ x − x i ∥ 2 σ 2 ) Gauss径向基函数则是局部性强的核函数,其外推能力随着参数 σ 的增大而减弱。多项式形式的核函数具有良好的全局性质。局部性较差。 (4)傅里叶核 K ( x , x i ) = 1 − q 2 2 ( 1 − 2 q cos ( x − x i ) + q 2 ) (5)样条核 K ( x , x i ) = B 2 n + 1 ( x − x i ) (6)Sigmoid核函数 K ( x , x i ) = tanh ( κ ( x , x i ) − δ ) 采用Sigmoid函数作为核函数时,支持向量机实现的就是一种多层感知器神经网络,应用SVM方法,隐含层节点数目(它确定神经网络的结构)、隐含层节点对输入节点的权值都是在设计(训练)的过程中自动确定的。而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最小值,也保证了它对于未知样本的良好泛化能力而不会出现过学习现象。 核函数的选择 在选取核函数解决实际问题时,通常采用的方法有: 一是利用专家的先验知识预先选定核函数; 二是采用Cross-Validation方法,即在进行核函数选取时,分别试用不同的核函数,归纳误差最小的核函数就是最好的核函数.如针对傅立叶核、RBF核,结合信号处理问题中的函数回归问题,通过仿真实验,对比分析了在相同数据条件下,采用傅立叶核的SVM要比采用RBF核的SVM误差小很多. 三是采用由Smits等人提出的混合核函数方法,该方法较之前两者是目前选取核函数的主流方法,也是关于如何构造核函数的又一开创性的工作.将不同的核函数结合起来后会有更好的特性,这是混合核函数方法的基本思想.
15KNN算法的适用场景:
样本较少但典型性好
16对随机森林参数的理解
增加树的深度可能导致过拟合;增加树的数目可能导致欠拟合。
17对时间序列模型的理解
AR模型是一种线性预测,即已知N个数据,可由模型推出第N点前面或后面的数据(设推出P点),所以其本质类似于插值。
MA模型(moving average model)滑动平均模型,其中使用趋势移动平均法建立直线趋势的预测模型。
ARMA模型(auto regressive moving average model)自回归滑动平均模型,模型参量法高分辨率谱分析方法之一。这种方法是研究平稳随机过程有理谱的典型方法。它比AR模型法与MA模型法有较精确的谱估计及较优良的谱分辨率性能,但其参数估算比较繁琐。
GARCH模型称为广义ARCH模型,是ARCH模型的拓展,由Bollerslev(1986)发展起来的。它是ARCH模型的推广。GARCH(p,0)模型,相当于ARCH(p)模型。GARCH模型是一个专门针对金融数据所量体订做的回归模型,除去和普通回归模型相同的之处,GARCH对误差的方差进行了进一步的建模。特别适用于波动性的分析和预测,这样的分析对投资者的决策能起到非常重要的指导性作用,其意义很多时候超过了对数值本身的分析和预测。
本题题目及解析来源:@刘炫320
链接:http://blog.csdn.net/column/details/16442.html
