代码下载地址
本文末尾也有代码全文,可以带你迅速了解部分标签学习的训练流程。
1. generate_partial_labels(targets, num_classes=10, candidate_size=3)
目的:为训练数据集生成部分标签,通过为每个真实标签分配一组候选标签(包括真实标签和一些随机错误标签)来模拟部分标签学习场景。这使得模型在训练时面对的不是单一的真实标签,而是一组可能的标签。
输入:
targets:CIFAR-10 数据集的真实标签列表或数组(例如,0 到 9 的整数)。num_classes:数据集中可能的类别数(默认为 10,对应 CIFAR-10)。candidate_size:每个部分标签集合中的标签数量(默认为 3)。
过程:
- 对
targets中的每个真实标签:- 从真实标签开始,初始化候选列表(
candidates = [target])。 - 使用
np.random.randint从[0, num_classes)范围内随机采样其他标签,直到候选列表长度达到candidate_size。 - 通过检查确保随机标签不在
candidates中,避免重复。
- 从真实标签开始,初始化候选列表(
- 将每个样本的候选标签列表存储在
partial_labels中。
输出:
partial_labels:一个列表的列表,其中每个子列表包含对应样本的candidate_size个标签(包括真实标签)。
示例:
- 如果
targets = [3, 5]且candidate_size = 3,输出可能是[[3, 7, 1], [5, 2, 8]]。
2. PartialLabelDataset(自定义数据集类)
目的:一个自定义的 PyTorch Dataset 类,将 CIFAR-10 图像与其部分标签配对,而不是使用原始的单一标签目标。
输入:
dataset:原始的 CIFAR-10 数据集(这里是trainset)。partial_labels:由generate_partial_labels生成的部分标签列表。
方法:
__init__(self, dataset, partial_labels):- 用原始 CIFAR-10 数据和部分标签初始化数据集。
__getitem__(self, index):- 从原始数据集(
dataset[index])中获取索引index处的图像。 - 忽略原始单一标签目标,返回
partial_labels[index]对应的部分标签(转换为张量)。 - 返回:
(image, partial_label),其中partial_label是形状为(candidate_size,)的张量。
- 从原始数据集(
__len__(self):- 返回数据集中的样本总数(与原始数据集相同)。
输出:
- 一个与 PyTorch
DataLoader兼容的数据集对象,提供(image, partial_label)对。
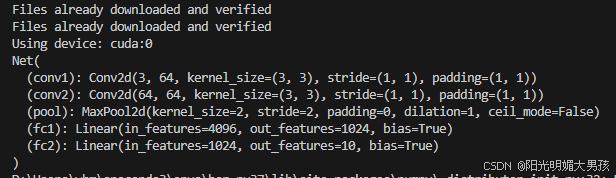
3. Net(神经网络类)
目的:定义一个卷积神经网络 (CNN) 架构,用于对 CIFAR-10 图像进行分类,输出的是原始 logits(未经过 softmax 处理的得分)。
架构:
- 输入:形状为
(3, 32, 32)的图像(3 个通道,32x32 像素)。 - 层:
conv1:卷积层,输入通道 3,输出通道 64,卷积核大小 3x3,填充=1。pool:最大池化层,2x2 卷积核,步幅 2(将空间维度减半)。conv2:卷积层,输入通道 64,输出通道 64,卷积核大小 3x3,填充=1。pool:另一个最大池化层(再次减少空间维度)。fc1:全连接层,从64 * 8 * 8(展平后的特征图)到 1024 个单元。fc2:全连接层,从 1024 到 10(10 个类的 logits)。
前向传播:
- 输入经过
conv1,ReLU 激活,然后池化。 - 输出经过
conv2,ReLU,再次池化(得到64 x 8 x 8的特征图)。 - 将特征图展平为大小为
64 * 8 * 8 = 4096的向量。 - 通过
fc1和 ReLU,然后通过fc2,生成形状为(batch_size, 10)的 logits。
输出:
- 10 个类的原始 logits(不是概率)。
4. train(net, device, dataloader, optimizer, criterion, epoch)
目的:使用部分标签和二元交叉熵损失(适用于多标签场景)训练神经网络。
输入:
net:神经网络模型(Net实例)。device:运行计算的设备(例如"cuda:0"或"cpu")。dataloader:提供(inputs, partial_labels)批次的DataLoader。optimizer:优化算法(例如 SGD)。criterion:损失函数(例如,用于部分标签的BCEWithLogitsLoss)。epoch:当前训练轮次(用于日志记录)。
过程:
- 将网络设置为训练模式(
net.train())。 - 遍历
dataloader中的批次:- 将
inputs(图像)和partial_labels移动到指定device。 - 清零梯度(
optimizer.zero_grad())。 - 前向传播:用
net(inputs)计算 logits。 - 创建形状为
(batch_size, 10)的目标张量,将partial_labels对应的位置设为 1,其余为 0。 - 使用
criterion计算 logits 和目标张量之间的损失。 - 反向传播:计算梯度(
loss.backward())。 - 更新权重(
optimizer.step())。
- 将
- 每 100 个批次打印训练进度。
输出:
- 更新网络权重并定期打印训练损失。
5. test(net, device, testloader)
目的:使用原始单标签目标(而不是部分标签)和标准交叉熵损失在测试集上评估模型。
输入:
net:训练好的神经网络模型。device:计算设备。testloader:测试集的DataLoader,提供(inputs, targets)对。
过程:
- 将网络设置为评估模式(
net.eval())。 - 使用
CrossEntropyLoss(适用于单标签分类)作为损失函数。 - 在无梯度计算的情况下(
torch.no_grad())遍历测试批次:- 将
inputs和targets移动到device。 - 前向传播:用
net(inputs)计算 logits。 - 计算 logits 和真实标签之间的损失(
criterion(outputs, targets))。 - 用最高 logit 值预测类别(
torch.max(outputs, 1))。 - 统计正确预测数并累加总损失。
- 将
- 计算测试集上的平均损失和准确率。
- 打印结果。
输出:
- 打印平均测试损失和准确率。
6. main()
目的:通过设置设备、模型、优化器、损失函数并运行训练/测试循环来协调整个训练和测试过程。
过程:
- 检测并选择设备(如果可用则为
cuda:0,否则为cpu)。 - 实例化
Net模型并将其移动到设备上。 - 定义优化器(
SGD,学习率 0.01,动量 0.9)。 - 定义训练时的损失函数(用于部分标签的
BCEWithLogitsLoss)。 - 运行 2 个轮次的循环:
- 使用
train函数和部分标签数据集训练模型。 - 使用
test函数和原始测试数据集测试模型。
- 使用
- 打印设备和模型信息。
输出:
- 执行训练和测试流程,打印进度和结果。
总结
generate_partial_labels:通过创建候选标签集合模拟部分标签学习。PartialLabelDataset:将 CIFAR-10 适配为部分标签训练。Net:定义一个输出 10 类 logits 的 CNN。train:使用部分标签和二元交叉熵损失训练模型。test:使用单标签目标和交叉熵损失评估模型。main:将所有组件整合成一个训练/测试工作流。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 下载 CIFAR-10 数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
# 生成部分标签
def generate_partial_labels(targets, num_classes=10, candidate_size=3):
partial_labels = []
for target in targets:
candidates = [target]
while len(candidates) < candidate_size:
random_label = np.random.randint(0, num_classes)
if random_label not in candidates:
candidates.append(random_label)
partial_labels.append(candidates)
return partial_labels
# 获取 CIFAR-10 的真实标签并生成部分标签
targets = trainset.targets
partial_labels = generate_partial_labels(targets)
# 自定义数据集类
class PartialLabelDataset(Dataset):
def __init__(self, dataset, partial_labels):
self.dataset = dataset
self.partial_labels = partial_labels
def __getitem__(self, index):
image, _ = self.dataset[index]
partial_label = torch.tensor(self.partial_labels[index], dtype=torch.long)
return image, partial_label
def __len__(self):
return len(self.dataset)
# 创建部分标签数据集和 DataLoader
partial_label_dataset = PartialLabelDataset(trainset, partial_labels)
partial_label_loader = DataLoader(partial_label_dataset, batch_size=4, shuffle=True, num_workers=2)
# 定义网络结构(输出 logits,不加 softmax)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3, padding=1)
self.conv2 = nn.Conv2d(64, 64, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 8 * 8, 1024)
self.fc2 = nn.Linear(1024, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8)
x = F.relu(self.fc1(x))
x = self.fc2(x) # 输出 logits
return x
# 修改训练函数
def train(net, device, dataloader, optimizer, criterion, epoch):
net.train()
for batch_idx, (inputs, partial_labels) in enumerate(dataloader):
inputs = inputs.to(device)
partial_labels = partial_labels.to(device)
optimizer.zero_grad()
outputs = net(inputs) # 输出 logits
# 创建目标张量:部分标签为 1,其他为 0
targets = torch.zeros_like(outputs)
for i in range(len(partial_labels)):
targets[i, partial_labels[i]] = 1 # 将部分标签集合中的标签设为正样本
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {
epoch} [{
batch_idx * len(inputs)}/{
len(dataloader.dataset)} ({
100. * batch_idx / len(dataloader):.0f}%)]\tLoss: {
loss.item():.6f}')
# 修改测试函数(使用单标签的交叉熵损失)
def test(net, device, testloader):
net.eval()
test_loss = 0
correct = 0
criterion = nn.CrossEntropyLoss() # 测试时使用单标签损失
with torch.no_grad():
for inputs, targets in testloader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
test_loss += criterion(outputs, targets).item()
_, predicted = torch.max(outputs, 1)
correct += (predicted == targets).sum().item()
test_loss /= len(testloader.dataset)
print(f'\nTest set: Average loss: {
test_loss:.4f}, Accuracy: {
correct}/{
len(testloader.dataset)} ({
100. * correct / len(testloader.dataset):.0f}%)\n')
# 主函数
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
# 实例化网络
net = Net().to(device)
print(net)
# 定义优化器和训练时的损失函数
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
criterion = nn.BCEWithLogitsLoss() # 用于部分标签的训练
# 训练和测试
for epoch in range(1, 3):
train(net, device, partial_label_loader, optimizer, criterion, epoch)
test(net, device, testloader)
if __name__ == '__main__':
main()
训练过程如下所示