
前言
前面我们学习了使用 Eureka 实现服务注册和服务发现,其中服务使用方的代码中:
//根据应用名称获取服务列表
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
//服务可能有多个,获取第一个
EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(0);
instances 是根据服务名获取的同一个服务的实例列表,而 instance 则是从实力列表中获取一个实例,然后就可以使用这个实例提供的服务,那么就有一个问题,如果我们每次获取的实例都同一个实例的话,那么另外的实例部署的就没有意义了。我们先看看就使用上面的代码,然后部署多个服务之后是否会将多个请求打到不同的实例上:
首先同一个服务我们启动多个,那么如何同时启动多个同一个服务呢?
我这里使用的是 idea 专业版,如果使用的是社区版的话可以自己去查查如何启动多个同类型的服务。
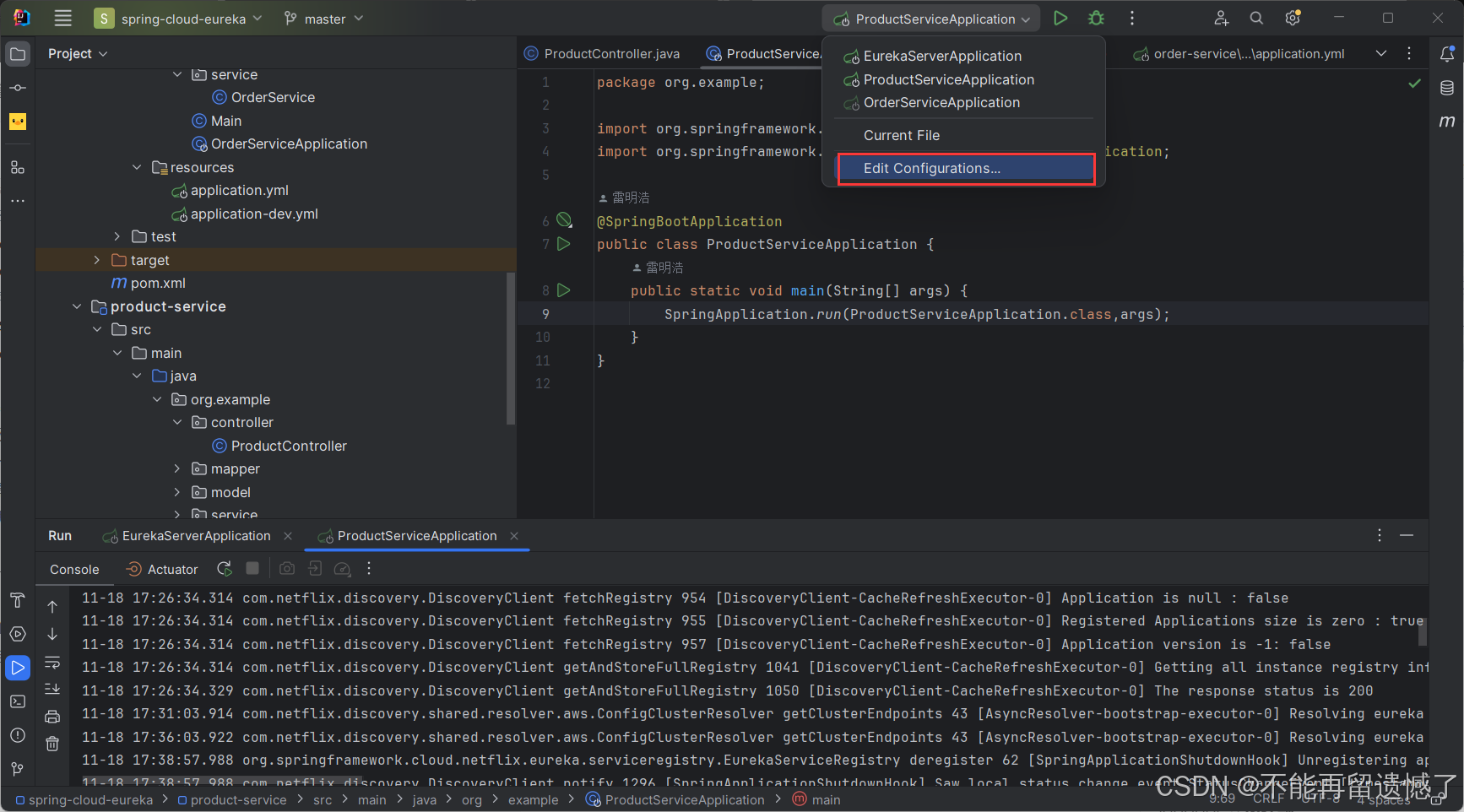
选择 Modify options:
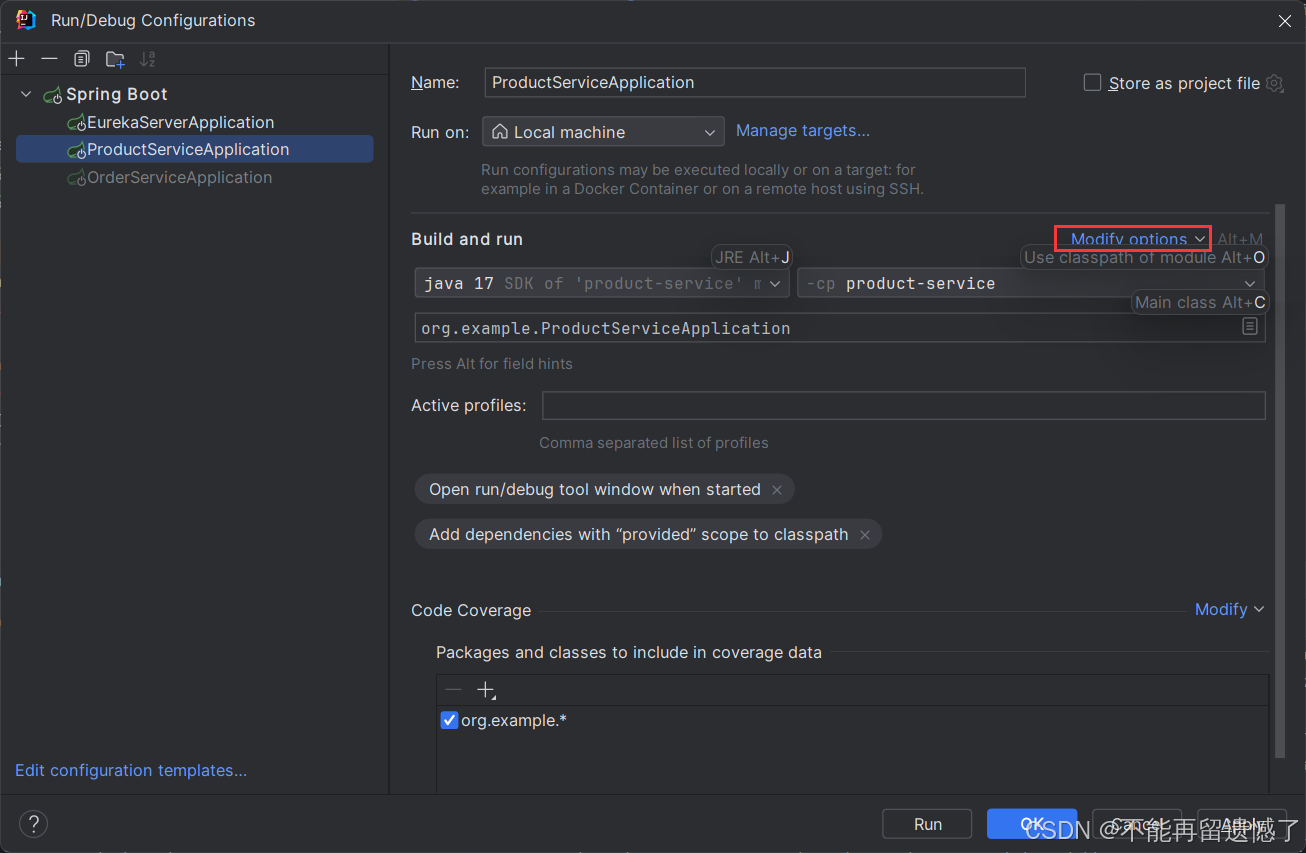
add VM options:
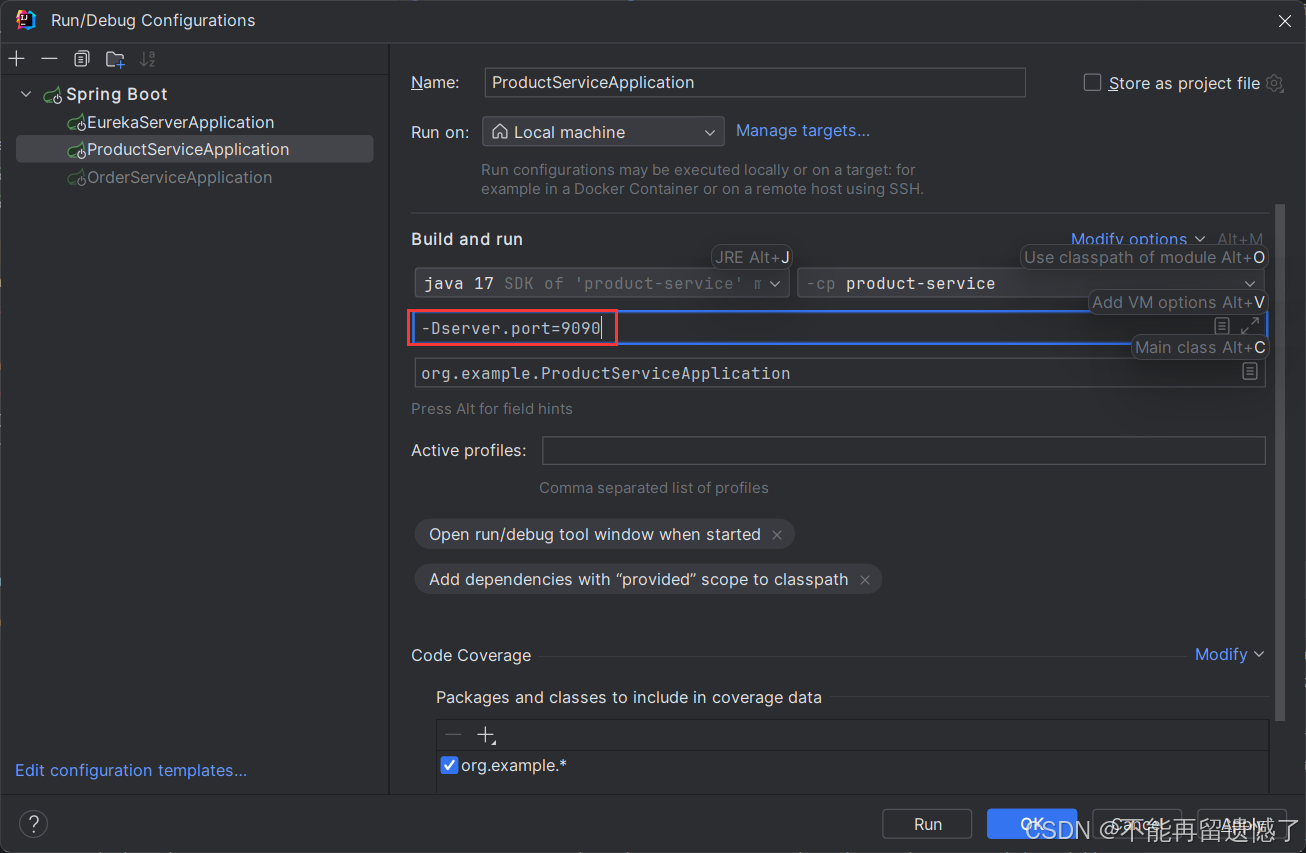
指定服务启动使用的端口号:
然后复制一个 application:
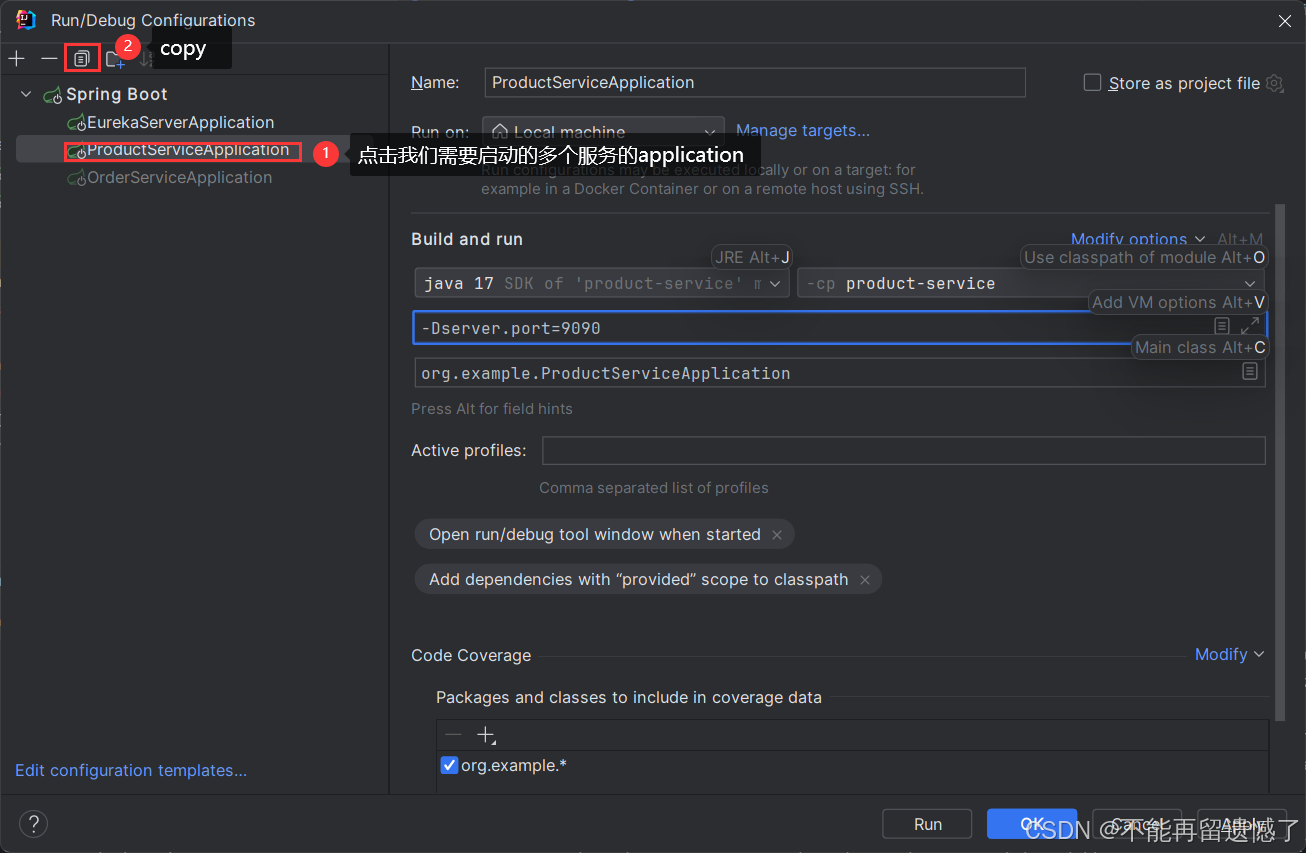
配置端口号:
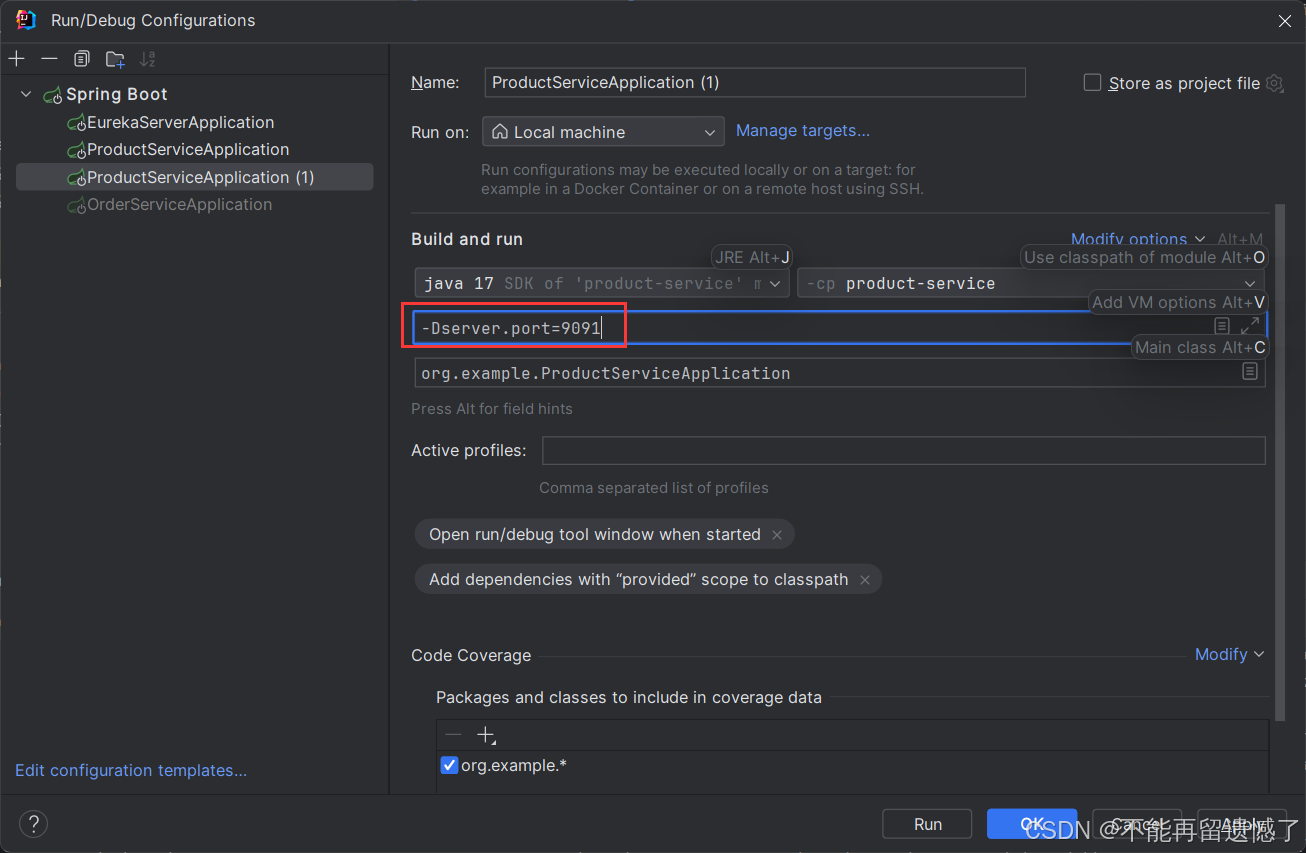
同样的操作再复制一份,然后启动每个application:
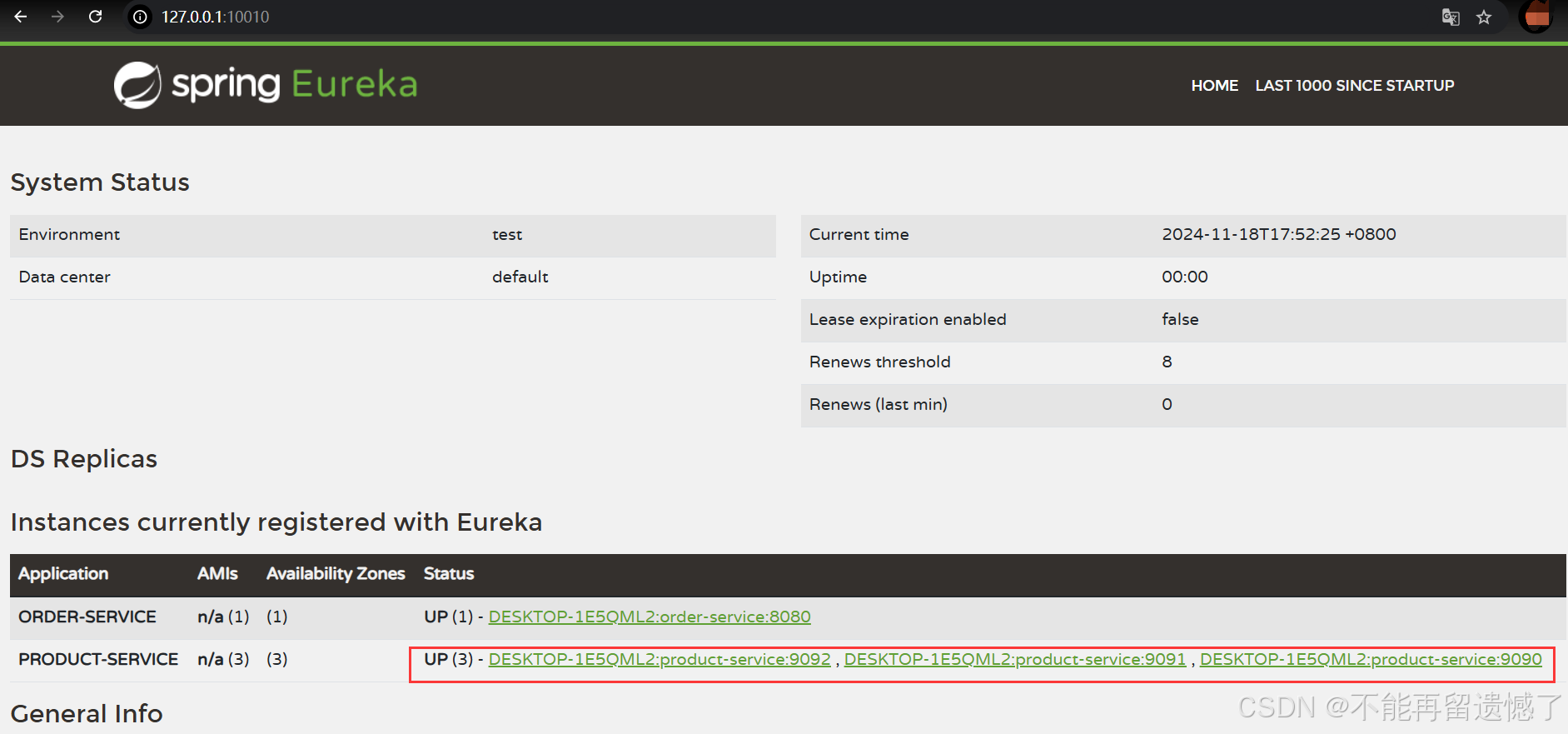
在 eureka 注册中心看看服务是否注册成功:
然后我们多次访问 127.0.0.1:8080/order/1,看看这几次服务都打在了哪个实例上:
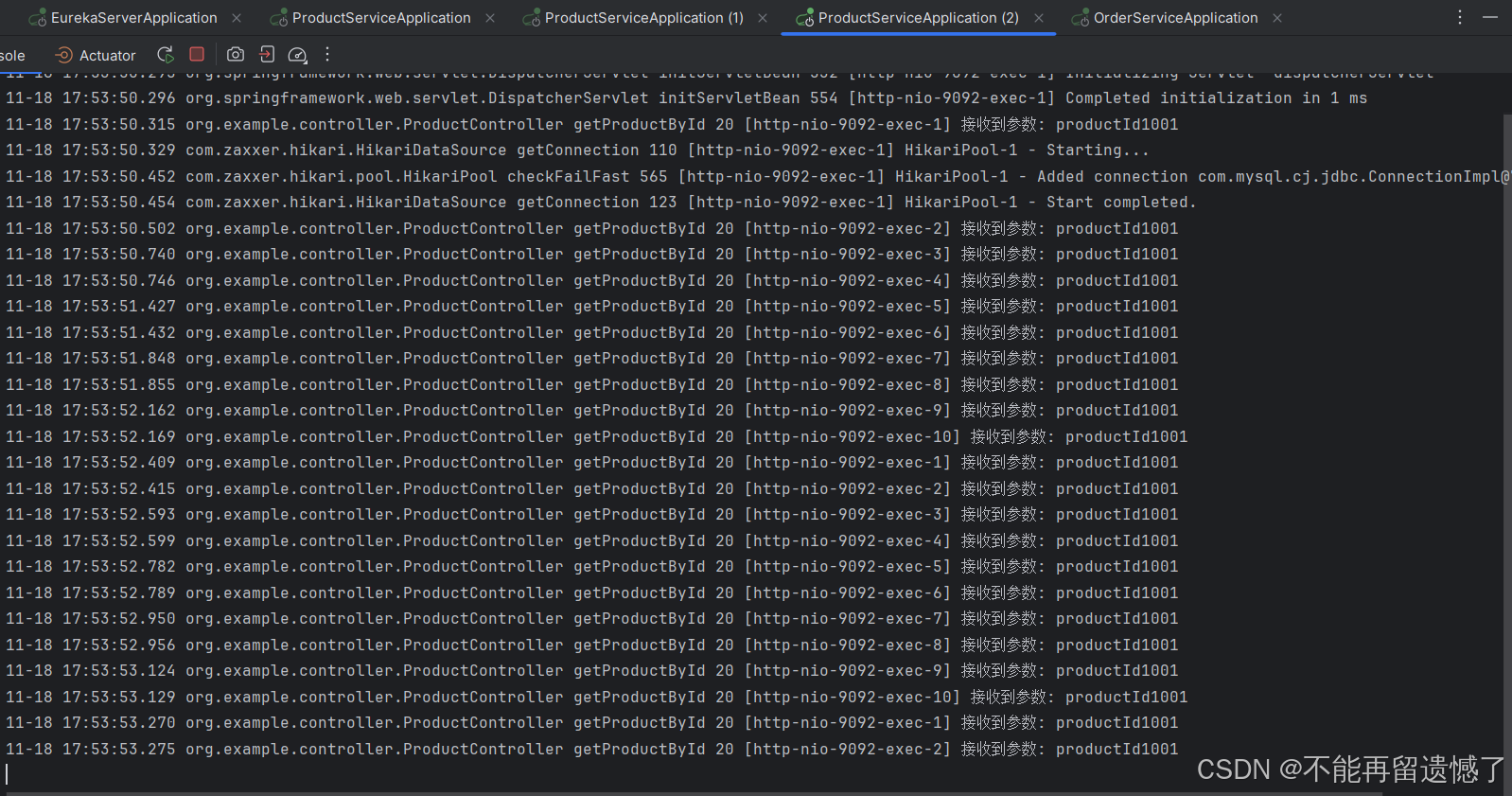
可以看到这些请求全部都打在了 ProductServiceApplication(2)这个服务上,而其他的服务一次请求都没处理。
那么我们如何做到将请求合理的分配到不同的实例上面呢?
解决方案
我们可以定义一个原子类,然后根据访问服务的次数来将请求打到不同的实例上面:
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
@Autowired
private DiscoveryClient discoveryClient;
private static AtomicInteger atomicInteger = new AtomicInteger(1);
public OrderInfo selectOrderById(Integer id) {
OrderInfo orderInfo = orderMapper.selectOrderById(id);
//String url = "http://127.0.0.1:9090/product/" + orderInfo.getProductId();
//根据应用名称获取服务列表
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
int index = atomicInteger.getAndIncrement() % instances.size();
//服务可能有多个,获取第一个
EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(index);
//拼接url
String url = instance.getUri() + "/product/" + orderInfo.getProductId();
ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}
}
使用 AtomicInteger 来记录访问服务的次数,然后模上实例的个数,这样就能使得请求能够均匀的打在每个实例上,但是上面的代码是有问题的,我们每次通过 discoveryClient.getInstances("product-service") 获取的实例列表的顺序可能是不同的,所以更好的做法是只获取一次实例列表:
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
@Autowired
private DiscoveryClient discoveryClient;
private static AtomicInteger atomicInteger = new AtomicInteger(1);
private List<ServiceInstance> instances;
/**
* 在bean初始化完成之后,自动执行
*/
@PostConstruct
public void init() {
instances = discoveryClient.getInstances("product-service");
}
public OrderInfo selectOrderById(Integer id) {
OrderInfo orderInfo = orderMapper.selectOrderById(id);
//String url = "http://127.0.0.1:9090/product/" + orderInfo.getProductId();
//根据应用名称获取服务列表
int index = atomicInteger.getAndIncrement() % instances.size();
//服务可能有多个,获取第一个
EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(index);
//拼接url
String url = instance.getUri() + "/product/" + orderInfo.getProductId();
ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}
}
然后我们在启动,并且使用服务,看看请求是否均匀的打在了每个实例上:



那么这样就实现了一个简单的负载均衡。
什么是负载均衡
负载均衡(Load Balancing)是一种网络技术,用于在多台服务器或资源之间均匀分配工作负载,从而提高系统的可用性、性能和可靠性。负载均衡可以防止单一资源过载,同时保证系统的高效运行和持续服务。
上面我们实现了一个简单的轮询的负载均衡,但是真实的业务场景实现的负载均衡会更加复杂,可能会根据机器的配置进行负载均衡,配置高的分配的流量高,配置低的分配流量低。
负载均衡分为服务端负载均衡和客户端复杂均衡。
服务端负载均衡:指在服务端进行负载均衡的算法分配,比较有名的服务端负载均衡器是 Nginx,请求先到达 Nginx 负载均衡器,然后通过负载均衡算法,在多个服务器之间选择一个服务器进行访问。
客户端负载均衡:在客户端进行负载均衡的算法分配。把负载均衡的功能以库的方式集成到客户端,而不再是由一台指定的负载均衡设备集中提供。比如Spring Cloud的Ribbon,请求发送到客户端,客户端从注册中心(比如Eureka)获取服务列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问。
Ribbon是Spring Cloud早期的默认实现,由于不再维护,所以最新版本的Spring Cloud负载均衡集成的是Spring Cloud LoadBalancer(Spring Cloud官方维护)。
所以我们这篇文章学习的就是 Spring Cloud LoadBalancer。
Spring Cloud Balancer
如何使用Spring Cloud Balancer 实现负载均衡,这个其实很简单,我们只需要在 RestTemplate 这个 Bean 上添加 @LoadBalanced 注解就可以了:
@Configuration
public class BeanConfig {
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
修改 IP 端口号为服务名称:
public OrderInfo selectOrderById(Integer id) {
OrderInfo orderInfo = orderMapper.selectOrderById(id);
String url = "http://product-service/product/" + orderInfo.getProductId();
ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}
然后我们再启动三个服务并且多次调用服务,看看是否将这些请求均匀的分配给了不同的实例:



负载均衡策略
负载均衡策略是一种思想,无论是哪一种负载均衡器,他们的负载均衡策略都是相似的,Spring Cloud LoadBalancer 仅支持两种负载均衡策略:轮询策略和随机策略。
- 轮询:轮询策略是指服务器轮流处理用户的请求。这是一种实现最简单,也最常用的策略。
- 随机选择:随机选择策略是指随机选择一个后端服务器来处理新的请求。
Spring Cloud LoadBalancer 默认的负载均衡策略是轮询策略,实现的是RoundRobinLoadBalancer,如果想让客户但负载均衡实现随机均衡策略也很简单:
这里是 Spring 的官方文档:https://docs.spring.io/spring-cloud-commons/reference/spring-cloud-commons/loadbalancer.html
package org.example.config;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.loadbalancer.core.RandomLoadBalancer;
import org.springframework.cloud.loadbalancer.core.ReactorLoadBalancer;
import org.springframework.cloud.loadbalancer.core.ServiceInstanceListSupplier;
import org.springframework.cloud.loadbalancer.support.LoadBalancerClientFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.core.env.Environment;
public class LoadBalancerConfig {
@Bean
ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name,
ServiceInstanceListSupplier.class),name);
}
}
注意:
- 该类不能使用Configuration注解
- 需要在组件扫描的范围内
然后我们需要需要在 RestTemplate 配置类的上方使用 @LoadBalancerClient 或者 @LoadBalancerClients注解,可以对不同的服务提供方配置不同的客户端负载均衡算法策略。
@LoadBalancerClient注解用于为特定的微服务客户端配置负载均衡。@LoadBalancerClients注解用于批量配置多个微服务的负载均衡。
因为我这里只有一个服务,所以就是用 @LoadBalancerClient 注解:
@LoadBalancerClient(name = "product-service",configuration = LoadBalancerConfig.class)
@Configuration
public class BeanConfig {
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
- name:指定该负载均衡策略对哪个服务生效(服务提供方)
- configuration:该负载均衡策略由哪个负载均衡策略实现
在启动一下看看这个随机分配策略是否生效:


