一、引言
KAN神经网络(Kolmogorov–Arnold Networks)是一种基于Kolmogorov-Arnold表示定理的新型神经网络架构。该定理指出,任何多元连续函数都可以表示为有限个单变量函数的组合。与传统多层感知机(MLP)不同,KAN通过可学习的激活函数和结构化网络设计,在函数逼近效率和可解释性上展现出潜力。
二、技术与原理简介
1.Kolmogorov-Arnold 表示定理
Kolmogorov-Arnold 表示定理指出,如果 是有界域上的多元连续函数,那么它可以写为单个变量的连续函数的有限组合,以及加法的二进制运算。更具体地说,对于 光滑
其中 和 。从某种意义上说,他们表明唯一真正的多元函数是加法,因为所有其他函数都可以使用单变量函数和 sum 来编写。然而,这个 2 层宽度 - Kolmogorov-Arnold 表示可能不是平滑的由于其表达能力有限。我们通过以下方式增强它的表达能力将其推广到任意深度和宽度。,
2.Kolmogorov-Arnold 网络 (KAN)
Kolmogorov-Arnold 表示可以写成矩阵形式
其中
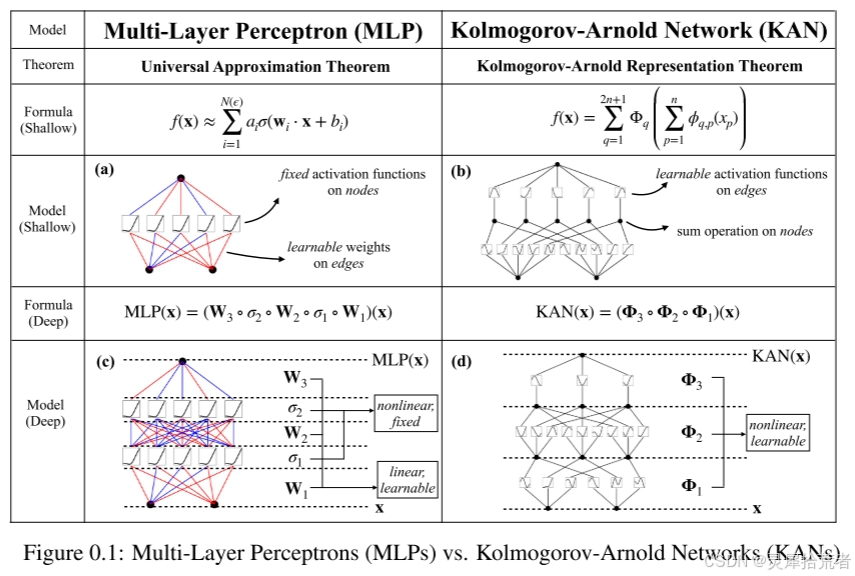
我们注意到 和 都是以下函数矩阵(包含输入和输出)的特例,我们称之为 Kolmogorov-Arnold 层:

其中。
定义层后,我们可以构造一个 Kolmogorov-Arnold 网络只需堆叠层!假设我们有层,层的形状为 。那么整个网络是
相反,多层感知器由线性层和非线错:
KAN 可以很容易地可视化。(1) KAN 只是 KAN 层的堆栈。(2) 每个 KAN 层都可以可视化为一个全连接层,每个边缘上都有一个1D 函数。
三、代码详解
1. 初始化KAN
from kan import *
torch.set_default_dtype(torch.float64)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# create a KAN: 2D inputs, 1D output, and 5 hidden neurons. cubic spline (k=3), 5 grid intervals (grid=5).
model = KAN(width=[2,5,1], grid=3, k=3, seed=42, device=device)- PyTorch 张量的默认数据类型设置为
float64(双精度浮点数) - width:指定网络每一层的神经元数量。这里网络有 2 个输入神经元,5 个隐藏神经元,1 个输出神经元。
- grid:指定样条网格的区间数量。区间越多,样条的灵活性越高。
- k:指定样条的阶数。三次样条(
k=3)通常用于平滑插值。 - seed:设置随机种子,以确保结果可复现。
- device:指定模型创建和运行的设备(CPU 或 GPU)。
2.创建数据集
from kan.utils import create_dataset
# create dataset f(x,y) = exp(sin(pi*x)+y^2)
f = lambda x: torch.exp(torch.sin(torch.pi*x[:,[0]]) + x[:,[1]]**2)
dataset = create_dataset(f, n_var=2, device=device)
dataset['train_input'].shape, dataset['train_label'].shape- 导入
create_dataset函数: 从kan.utils模块导入create_dataset函数,这个函数用于生成数据集。 - 定义目标函数
f: 定义了一个匿名函数f,它接受一个包含 x 和 y 值的张量作为输入,并计算exp(sin(pi*x) + y^2)的值。x[:,[0]]和x[:,[1]]用于提取张量x的第一列(x 值)和第二列(y 值),并保持其为二维张量。 - 创建数据集: 调用
create_dataset函数,传入目标函数f,输入变量的个数n_var=2,以及设备device。create_dataset函数会生成训练集、验证集和测试集,并使用目标函数f计算每个样本的标签。 - 打印数据集形状: 打印训练集输入和标签的形状,以便了解数据集的大小和维度。
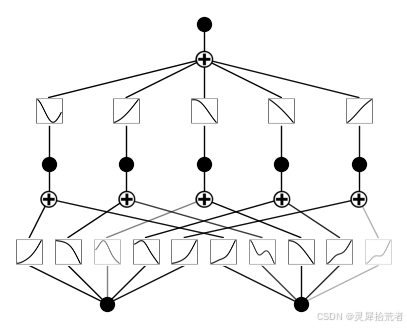
3.初始化时绘制 KAN
# plot KAN at initialization
model(dataset['train_input']);
model.plot()-
model(dataset['train_input']): 这行代码将训练数据集的输入dataset['train_input']传递给model。 这行代码的作用是让模型进行一次前向传播,使用训练数据作为输入。 由于模型在初始化后还没有经过训练,这次前向传播的结果是模型在随机初始化状态下的输出。 -
model.plot(): 这行代码调用model对象的plot()方法。 用于可视化KAN模型的结构。
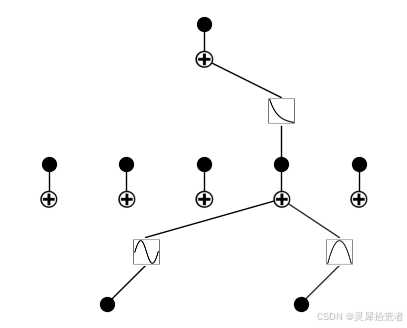
4.使用稀疏正则化训练 KAN并绘图
# train the model
model.fit(dataset, opt="LBFGS", steps=50, lamb=0.001);
model.plot()-
model.fit(dataset, ...): 调用model对象的fit()方法来训练模型。fit()方法通常接受数据集作为输入,并使用指定的优化器和训练参数来更新模型的权重和偏置。 -
dataset: 将之前创建的数据集dataset传递给fit()方法。 -
opt="LBFGS": 指定使用 LBFGS (Limited-memory Broyden–Fletcher–Goldfarb–Shanno) 优化器。 LBFGS 是一种拟牛顿优化算法,通常用于训练参数较少的模型。 -
steps=50: 指定训练的步数(或迭代次数)为 50。 模型将使用 LBFGS 优化器更新权重和偏置 50 次。 -
lamb=0.001: 指定正则化系数为 0.001。 正则化是一种防止过拟合的技术,通过在损失函数中添加一个惩罚项来限制模型参数的大小。lamb通常表示 L2 正则化系数,它会惩罚模型中较大的权重。
5.修剪 KAN 并重新绘制
model = model.prune()
model.plot()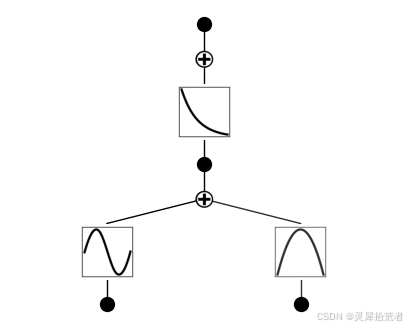
6.继续训练并重新绘制
model.fit(dataset, opt="LBFGS", steps=50);7.对剪枝后的模型进行微调或精炼
model = model.refine(10)8.继续训练并重新绘制
model.fit(dataset, opt="LBFGS", steps=50);8.自动或手动将激活函数设置为符号
mode = "auto" # "manual"
if mode == "manual":
# manual mode
model.fix_symbolic(0,0,0,'sin');
model.fix_symbolic(0,1,0,'x^2');
model.fix_symbolic(1,0,0,'exp');
elif mode == "auto":
# automatic mode
lib = ['x','x^2','x^3','x^4','exp','log','sqrt','tanh','sin','abs']
model.auto_symbolic(lib=lib)-
mode = "auto" # "manual": 定义一个变量mode,用于控制选择手动模式还是自动模式。 当前设置为"auto",表示使用自动模式。 注释"manual"表明可以将其更改为"manual"以启用手动模式。 -
if mode == "manual":: 如果mode的值为"manual",则执行以下代码块(手动模式)。model.fix_symbolic(0,0,0,'sin'): 调用model对象的fix_symbolic()方法,将第 0 层第 0 个神经元的第 0 个基函数固定为'sin'函数。model.fix_symbolic(0,1,0,'x^2'): 调用model对象的fix_symbolic()方法,将第 0 层第 1 个神经元的第 0 个基函数固定为'x^2'函数。model.fix_symbolic(1,0,0,'exp'): 调用model对象的fix_symbolic()方法,将第 1 层第 0 个神经元的第 0 个基函数固定为'exp'函数。
在手动模式下,需要显式地指定每个神经元使用的符号函数。
fix_symbolic()方法的参数可能表示: * 第一个参数:层数 * 第二个参数:神经元索引 * 第三个参数:基函数索引 (KAN 模型的每个神经元可能使用多个基函数的组合) * 第四个参数:符号函数的名称 (例如'sin','x^2','exp') -
elif mode == "auto":: 如果mode的值为"auto",则执行以下代码块(自动模式)。lib = ['x','x^2','x^3','x^4','exp','log','sqrt','tanh','sin','abs']: 定义一个列表lib,包含了一组可供选择的符号函数。model.auto_symbolic(lib=lib): 调用model对象的auto_symbolic()方法,自动为 KAN 模型中的神经元选择符号函数。auto_symbolic()方法会根据某种策略(例如最小化损失函数、最大化模型复杂度等),从lib列表中选择合适的符号函数,并将其分配给模型中的神经元。
9.继续训练以接近机器精度
model.fit(dataset, opt="LBFGS", steps=50);10.获取符号公式
from kan.utils import ex_round
ex_round(model.symbolic_formula()[0][0],4)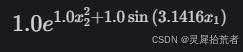
四、总结与思考
KAN神经网络通过融合数学定理与深度学习,为科学计算和可解释AI提供了新思路。尽管在高维应用中仍需突破,但其在低维复杂函数建模上的潜力值得关注。未来可能通过改进计算效率、扩展理论边界,成为MLP的重要补充。
1. KAN网络架构
-
关键设计:可学习的激活函数:每个网络连接的“权重”被替换为单变量函数(如样条、多项式),而非固定激活函数(如ReLU)。分层结构:输入层和隐藏层之间、隐藏层与输出层之间均通过单变量函数连接,形成多层叠加。参数效率:由于理论保证,KAN可能用更少的参数达到与MLP相当或更好的逼近效果。
-
示例结构:输入层 → 隐藏层:每个输入节点通过单变量函数
连接到隐藏节点。隐藏层 → 输出层:隐藏节点通过另一组单变量函数
组合得到输出。
2. 优势与特点
-
高逼近效率:基于数学定理,理论上能以更少参数逼近复杂函数;在低维科学计算任务(如微分方程求解)中表现优异。
-
可解释性:单变量函数可可视化,便于分析输入变量与输出的关系;网络结构直接对应函数分解过程,逻辑清晰。
-
灵活的函数学习:激活函数可自适应调整(如学习平滑或非平滑函数);支持符号公式提取(例如从数据中恢复物理定律)。
3. 挑战与局限
-
计算复杂度:单变量函数的学习(如样条参数化)可能增加训练时间和内存消耗。需要优化高阶连续函数,对硬件和算法提出更高要求。
-
泛化能力:在高维数据(如图像、文本)中的表现尚未充分验证,可能逊色于传统MLP。
-
训练难度:需设计新的优化策略,避免单变量函数的过拟合或欠拟合。
4. 应用场景
-
科学计算:求解微分方程、物理建模、化学模拟等需要高精度函数逼近的任务。
-
可解释性需求领域:医疗诊断、金融风控等需明确输入输出关系的场景。
-
符号回归:从数据中自动发现数学公式(如物理定律)。
5. 与传统MLP的对比

6. 研究进展
-
近期论文:2024年,MIT等团队提出KAN架构(如论文《KAN: Kolmogorov-Arnold Networks》),在低维任务中验证了其高效性和可解释性。
-
开源实现:已有PyTorch等框架的初步实现。