
1. 背景
ZooKeeper(ZK)是一个诞生于 2007 年的分布式应用程序协调服务。尽管出于一些特殊的历史原因,许多业务场景仍然不得不依赖它。比如,Kafka、任务调度等。特别是在 Flink 混合部署 ETCD 解耦 时,业务方曾要求绝对的稳定性,并强烈建议不要使用自建的 ZooKeeper。出于对稳定性的考量,采用了阿里的 MSE-ZK。自从 2022 年 9 月份开始使用至今,得物技术团队没有遇到任何稳定性问题,SLA 的可靠性确实达到了 99.99%。
在 2023 年,部分业务使用了自建的 ZooKeeper(ZK)集群,然后使用过程中 ZK 出现了几次波动,随后得物 SRE 开始接管部分自建集群,并进行了几轮稳定性加固的尝试。接管过程中得物发现 ZooKeeper 在运行一段时间后,内存占用率会不断增加,容易导致内存耗尽(OOM)的问题。得物技术团队对这一现象非常好奇,因此也参与了解决这个问题的探索过程。
2. 探索分析
2.1 确定方向
在排查问题时,非常幸运地发现了一个测试环境的故障现场,该集群中的两个节点恰好处于 OOM 的边缘状态。

有了故障现场,那么一般情况下距离成功终点只剩下 50%。内存偏高,按以往的经验来看,要么是非堆,要么是堆内有问题。从火焰图和 jstat 都能证实:是堆内的问题。

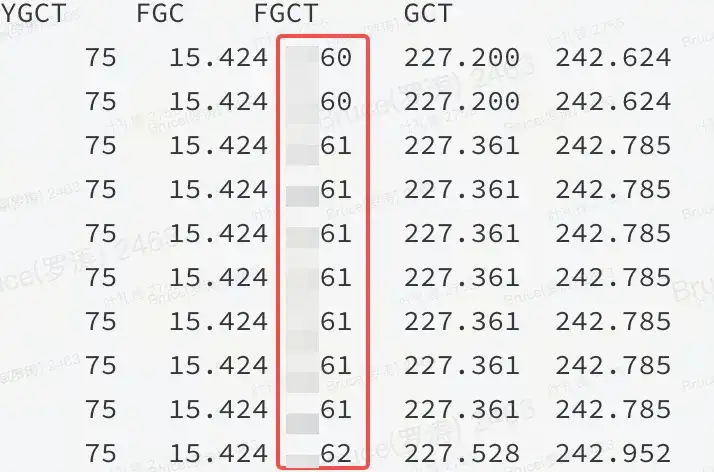
如图所示:说明 JVM 堆内存在某种资源占用了大量的内存,并且 FGC 都无法释放。
2.2 内存分析
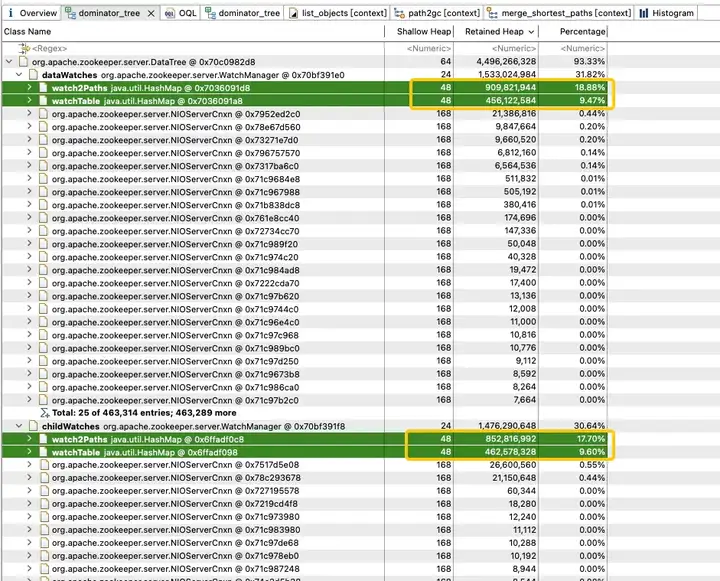
为了探究 JVM 堆中内存占用分布,得物技术团队立即做了一个 JVM 堆 Dump。分析发现 JVM 内存被 childWatches 和 dataWatches 大量占用。
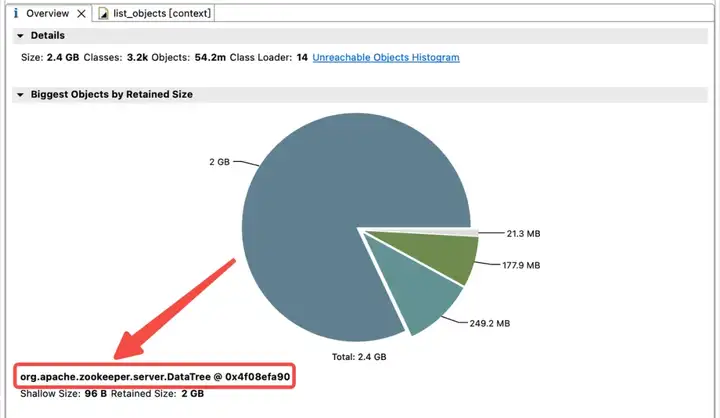
dataWatches:跟踪 znode 节点数据的变化。
childWatches:跟踪 znode 节点结构 (tree) 的变化。
childWatches 和 dataWatches 同源于 WatcherManager。
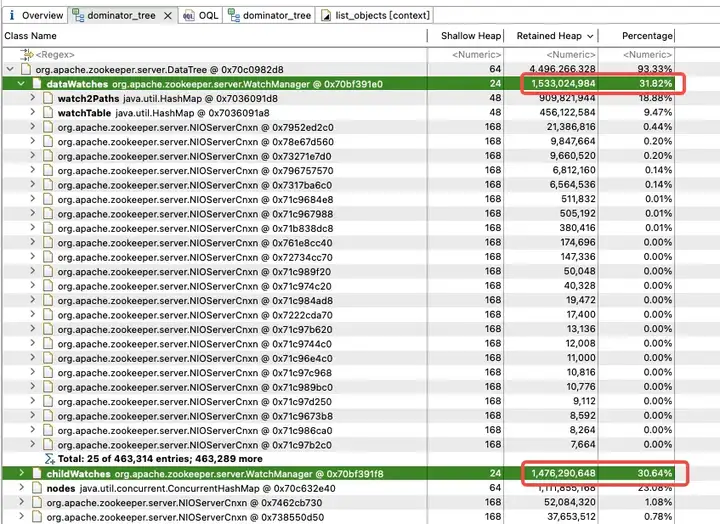
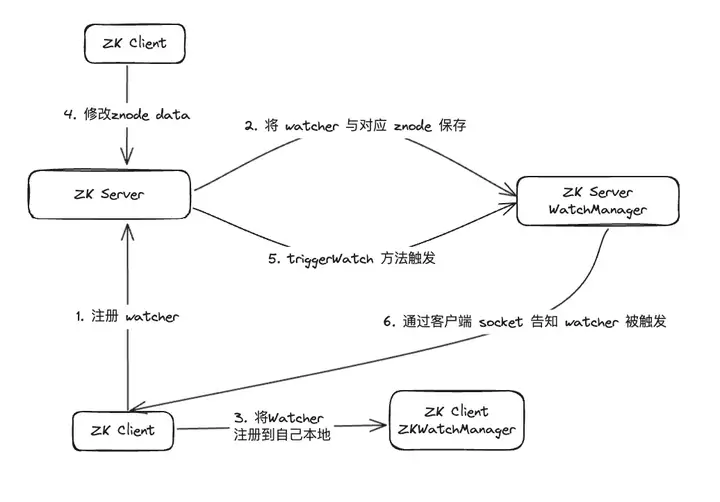
经过资料排查,发现 WatcherManager 主要负责管理 Watcher。ZooKeeper(ZK)客户端首先将 Watcher 注册到 ZooKeeper 服务器上,然后由 ZooKeeper 服务器使用 WatcherManager 来管理所有的 Watcher。当某个 Znode 的数据发生变更时,WatchManager 将触发相应的 Watcher,并通过与订阅该 Znode 的 ZooKeeper 客户端的 socket 进行通信。随后,客户端的 Watch 管理器将触发相关的 Watcher 回调,以执行相应的处理逻辑,从而完成整个数据发布/订阅流程。
进一步分析 WatchManager,成员变量 Watch2Path、WatchTables 内存占比高达 (18.88+9.47)/31.82 = 90%。
而 WatchTables、Watch2Path 存储的是 ZNode 与 Watcher 正反映射关系,存储结构图所示:
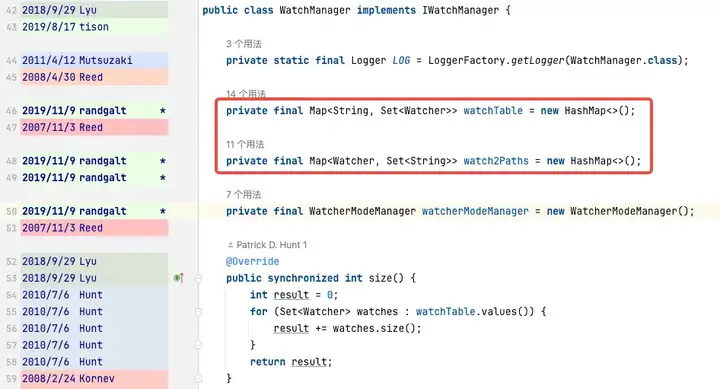
WatchTables【正向查询表】HashMap>
场景:某个 ZNode 发生变化,订阅该 ZNode 的 Watcher 会收到通知。
逻辑:用该 ZNode,通过 WatchTables 找到对应的所有 Watcher 列表,然后逐个发通知。
Watch2Paths【逆向查询表】
HashMap
场景:统计某个 Watcher 到底订阅了哪些 ZNode。
逻辑:用该Watcher,通过 Watch2Paths 找到对应的所有 ZNode 列表。
Watcher 本质是 NIOServerCnxn,可以理解成一个连接会话。
如果 ZNode、和 Watcher 的数量都比较多,并且客户端订阅 ZNode 也比较多,甚至全量订阅。这两张 Hash 表记录的关系就会呈指数增长,最终会是一个天量!
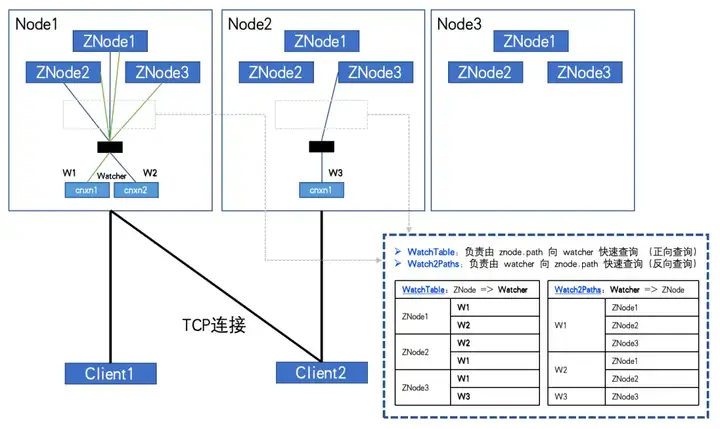
当全订阅时,如图演示:
当 ZNode数量:3,Watcher 数量:2 WatchTables 和 Watch2Paths 会各有 6 条关系。
当 ZNode数量:4,Watcher 数量:3 WatchTables 和 Watch2Paths 会各有 12 条关系。
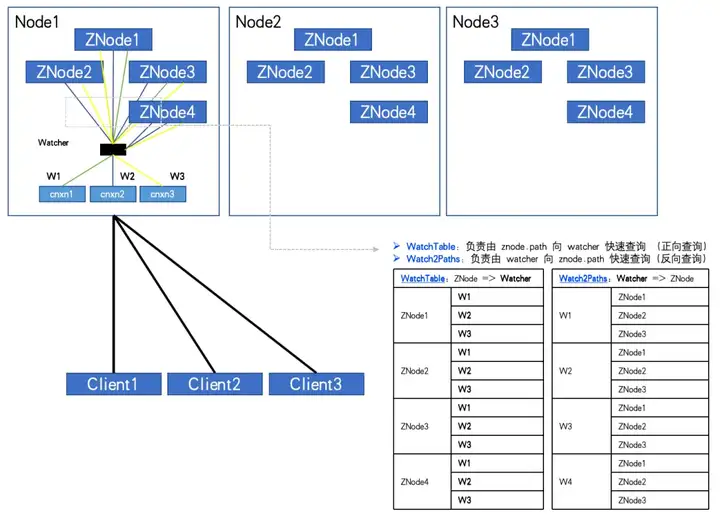
通过监控发现,异常的 ZK-Node。ZNode 数量大概有 20W,Watcher 数量是5000。而 Watcher 与 ZNode 的关系条数达到了 1 亿。
如果存储每条关系的需要 1 个 HashMap&Node(32Byte),由于是两个关系表,double 一下。那么其它都不要计算,光是这个“壳”,就需要 2*10000^2*32/1024^3 = 5.9GB 的无效内存开销。
2.3 意外发现
通过上面的分析可以得知,需要避免客户端出现对所有 ZNode 进行全面订阅的情况。然而,实际情况是,许多业务代码确实存在这样的逻辑,从 ZTree 的根节点开始遍历所有 ZNode,并对它们进行全面订阅。
或许能够说服一部分业务方进行改进,但无法强制约束所有业务方的使用方式。因此,解决这个问题的思路在于监控和预防。然而,遗憾的是,ZK 本身并不支持这样的功能,这就需要对 ZK 源码进行修改。
通过对源码的跟踪和分析,发现问题的根源又指向了 WatchManager,并且仔细研究了这个类的逻辑细节。经过深入理解后,发现这段代码的质量似乎像是由应届毕业生编写的,存在大量线程和锁的不恰当使用问题。通过查看 Git 记录,发现这个问题可以追溯到 2007 年。然而,令人振奋的是,在这一段时间内,出现了 WatchManagerOptimized(2018),通过搜索 ZK 社区的资料,发现了 [ZOOKEEPER-1177],即在 2011 年,ZK 社区就已经意识到了大量 Watch 导致的内存占用问题,并最终在 2018 年提供了解决方案。正是这个WatchManagerOptimized 的功劳,看来 ZK 社区早就进行了优化。
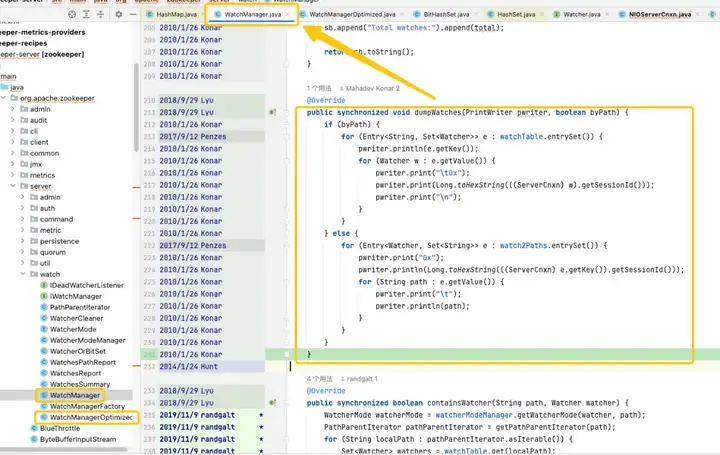
有趣的是,ZK 默认情况下并未启用这个类,即使在最新的 3.9.X 版本中,默认仍然使用 WatchManager。也许是因为 ZK 年代久远,渐渐地人们对其关注度降低了。通过询问阿里的同事,确认了 MSE-ZK 也启用了 WatchManagerOptimized,这进一步证实了得物技术团队关注的方向是正确的。
2.4 优化探索
锁的优化
在默认版本中,使用的 HashSet 是线程不安全的。在这个版本中,相关操作方法如 addWatch、removeWatcher 和 triggerWatch 都是通过在方法上添加了 synchronized 重型锁来实现的。而在优化版中,采用了 ConcurrentHashMap 和 ReadWriteLock 的组合,以更精细化地使用锁机制。这样一来,在添加 Watch 和触发 Watch 的过程中能够实现更高效的操作。
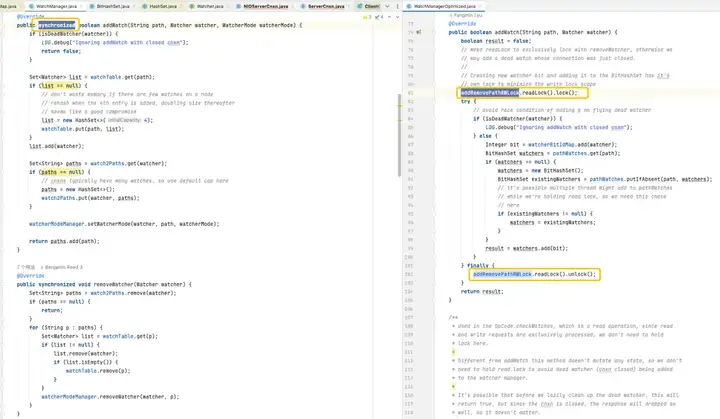
存储优化
这是关注的重点。从 WatchManager 的分析可以看出,使用 WatchTables 和 Watch2Paths 存储效率并不高。如果 ZNode 的订阅关系较多,将会额外消耗大量无效的内存。
感到惊喜的是,WatchManagerOptimized 在这里使用了“黑科技” -> 位图。
利用位图将关系存储进行了大量的压缩,实现了降维优化。
Java BitSet 主要特点:
- 空间高效:BitSet 使用位数组存储数据,比标准的布尔数组需要更少的空间。
- 处理快速:进行位操作(如 AND、OR、XOR、翻转)通常比相应的布尔逻辑操作更快。
- 动态扩展:BitSet 的大小可以根据需要动态增长,以容纳更多的位。
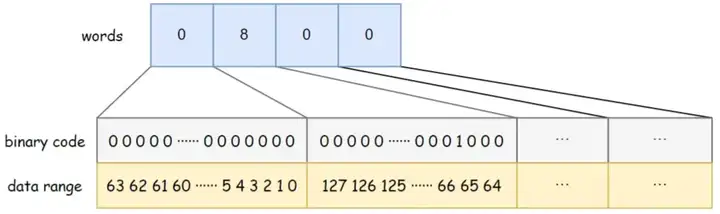
BitSet 使用一个 long[] words 来存储数据,long 类型占 8 字节,64 位。数组中每个元素可以存储 64 个数据,数组中数据的存储顺序从左到右,从低位到高位。比如下图中的 BitSet 的 words 容量为 4,words[0] 从低位到高位分别表示数据 0~63 是否存在,words[1] 的低位到高位分别表示数据 64~127 是否存在,以此类推。其中 words[1] = 8,对应的二进制第 8 位为 1,说明此时 BitSet 中存储了一个数据 {67}。
WatchManagerOptimized 使用 BitMap 来存储所有的 Watcher。这样即便是存在1W的 Watcher。位图的内存消耗也只有8Byte*1W/64/1024=1.2KB。如果换成 HashSet ,则至少需要 32Byte*10000/1024=305KB,存储效率相差近 300 倍。
WatchManager.java:
private final Map<String, Set<Watcher>> watchTable = new HashMap<>();
private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:
private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();
private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();
ZNode到 Watcher 的映射存储,由 Map 换成了 ConcurrentHashMapBitHashSet>。也就是说不再存储 Set,而是用位图来存储位图索引值。
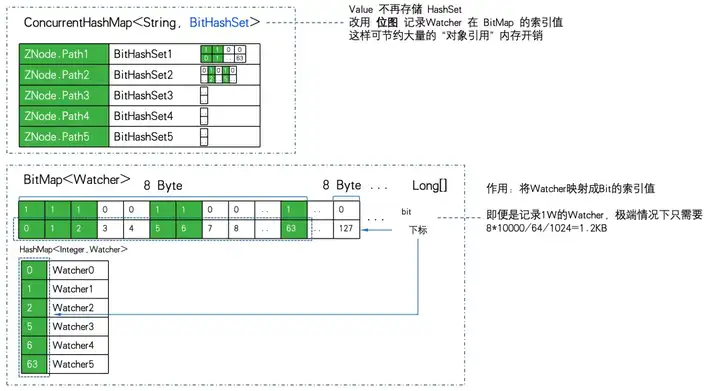
用 1W 的 ZNode,1W 的 Watcher,极端点走全订阅(所有的 Watcher 订阅所有的 ZNode),做存储效率 PK:

可以看到 11.7MB PK 5.9GB,内存的存储效率相差:516 倍。
逻辑优化
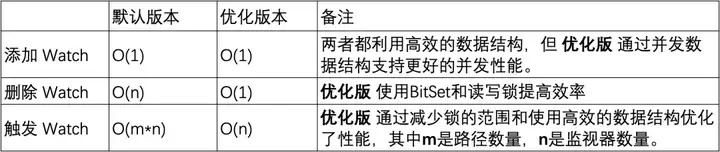
添加监视器:两个版本都能够在常数时间内完成操作,但是优化版通过使用 ConcurrentHashMap 提供了更好的并发性能。
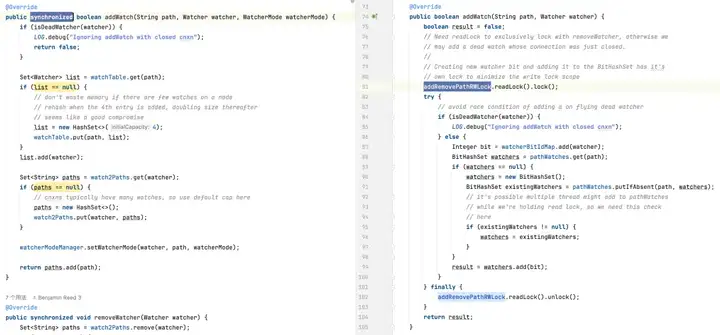
删除监视器:默认版可能需要遍历整个监视器集合来找到并删除监视器,导致时间复杂度为 O(n)。而优化版利用 BitSet 和 ConcurrentHashMap,在大多数情况下能够快速定位和删除监视器,O(1)。
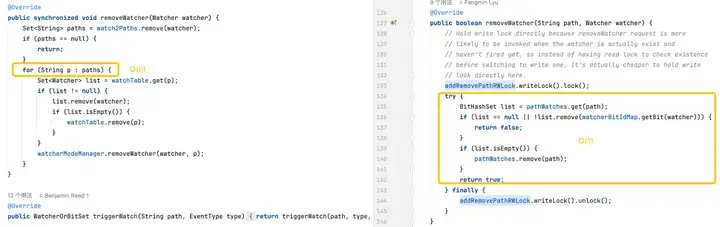
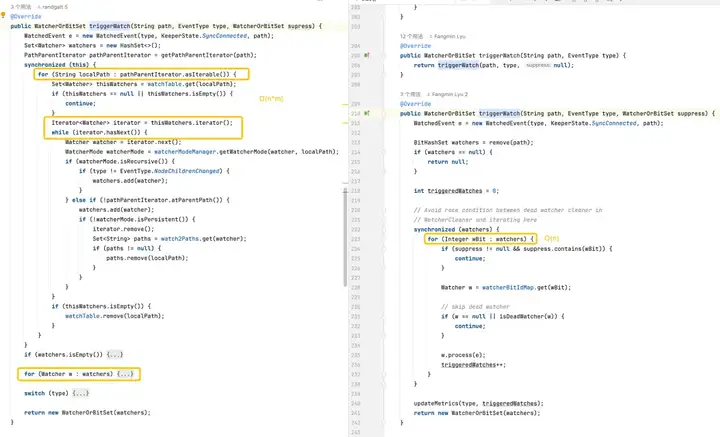
触发监视器:默认版的复杂度较高,因为它需要对每个路径上的每个监视器进行操作。优化版通过更高效的数据结构和减少锁的使用范围,优化了触发监视器的性能。
3. 性能压测
3.1 JMH 微基准测试
ZooKeeper 3.6.4 源码编译, JMH micor 压测 WatchBench。
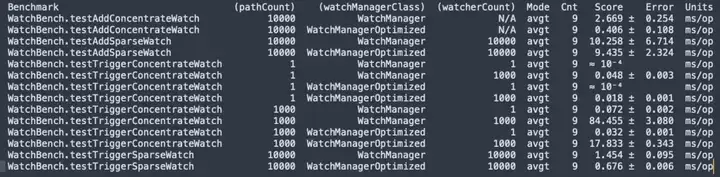
pathCount:表示测试中使用的 ZNode 路径数目。watchManagerClass:表示测试中使用的 WatchManager 实现类。
watcherCount:表示测试中使用的观察者(Watcher)数目。
Mode:表示测试的模式,这里是 avgt,表示平均运行时间。
Cnt:表示测试运行的次数。
Score:表示测试的得分,即平均运行时间。
Error:表示得分的误差范围。
Units:表示得分的单位,这里是毫秒/操作(ms/op)。
- ZNode 与 Watcher 100 万条订阅关系,默认版本使用 50MB,优化版只需要 0.2MB,而且不会线性增加。
- 添加 Watch,优化版(0.406 ms/op)比默认版(2.669 ms/op)提升 6.5 倍。
- 大量触发Watch ,优化版(17.833 ms/op)比默认版(84.455 ms/op)提升 5 倍。
3.2 性能压测
接下来在一台机器 (32C 60G) 搭建一套 3 节点 ZooKeeper 3.6.4 使用优化版与默认版进行容量压测对比。
场景一:20W znode 短路径
Znode 短路径: /demo/znode1

场景二:20W znode 长路径
Znode 长路径: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

- Watch 内存占用跟 ZNode 的 Path 长度有关。
- Watch 的数量在默认版是线性上涨,在优化版中表现非常好,这对内存占用优化来说改善非常明显。
3.3 灰度测试
基于前面的基准测试和容量测试,优化版在大量 Watch 场景内存优化明显,接下来开始对测试环境的 ZK 集群进行灰度升级测试观察。
第一套 ZooKeeper 集群 & 收益
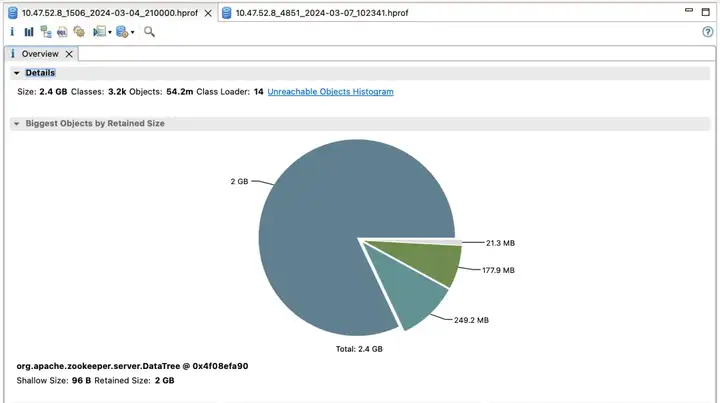
默认版
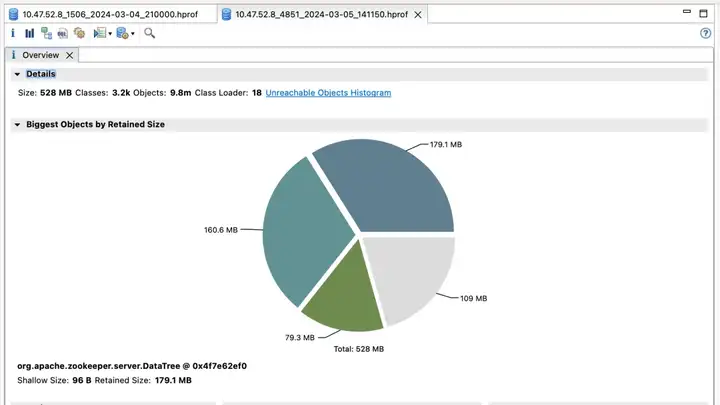
优化版


效果收益:
- election_time (选举耗时):降低 60%
- fsync_time (事务同步耗时):降低 75%
- 内存占用:降低 91%
第二套 ZooKeeper 集群 & 收益
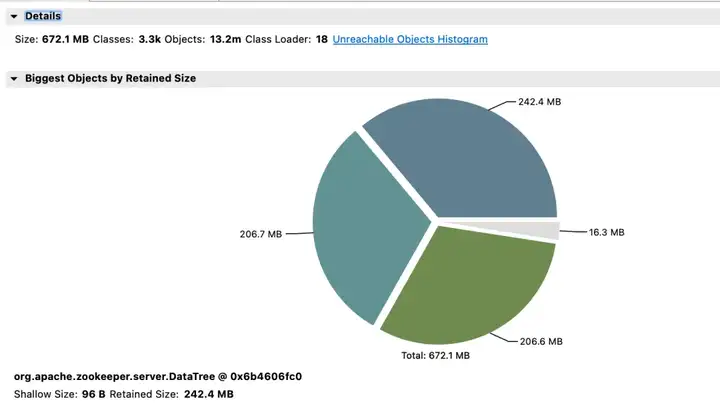
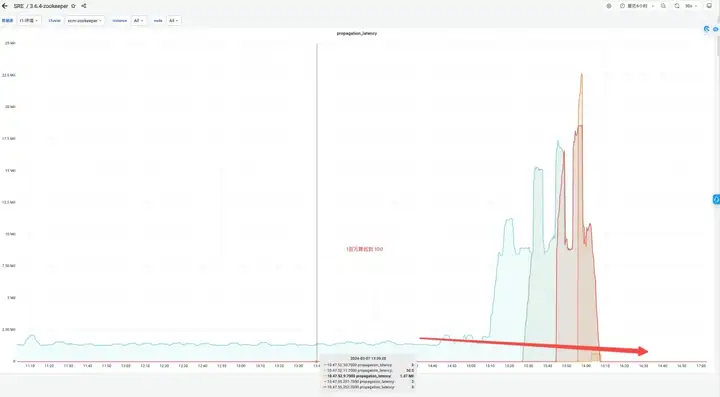


效果收益:
- 内存:变更前 JVM Attach 响应无法响应,采集数据失败。
- election_time(选举耗时):降低 64%。
- max_latency(读延迟):降低 53%。
- proposal_latency(选举处理提案延迟):1400000 ms --> 43 ms。
- propagation_latency(数据的传播延迟):1400000 ms --> 43 ms。
第三套 ZooKeeper 集群 & 收益
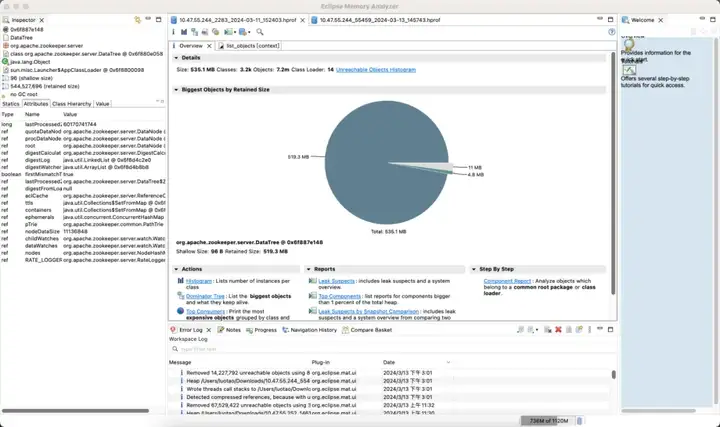
默认版
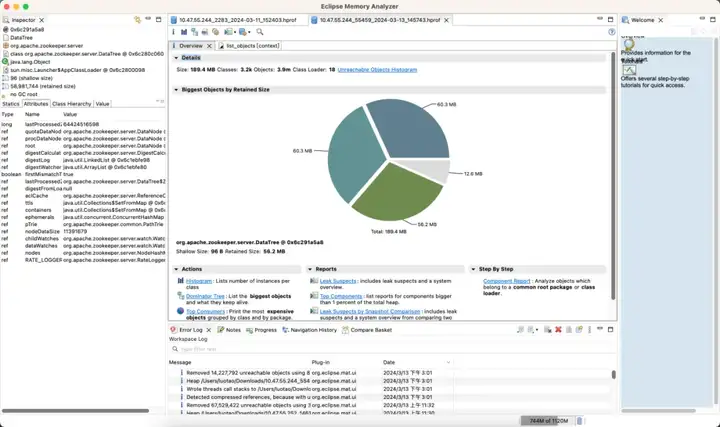
优化版
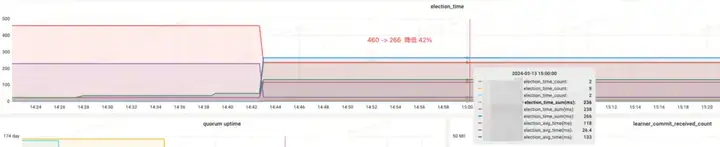

效果收益:
- 内存:节省 89%
- election_time(选举耗时):降低 42%
- max_latency(读延迟):降低 95%
- proposal_latency(选举处理提案延迟):679999 ms --> 0.3 ms
- propagation_latency(数据的传播延迟):928000 ms--> 5 ms
4. 总结
通过之前的基准测试、性能压测以及灰度测试,发现了 ZooKeeper 的 WatchManagerOptimized。这项优化不仅节省了内存,还通过锁的优化显著提高了节点之间的选举和数据同步等指标,从而增强了 ZooKeeper 的一致性。还与阿里 MSE 的同学进行了深度交流,各自在极端场景模拟压测,并达成了一致的看法:WatchManagerOptimized 对 ZooKeeper 的稳定性提升显著。总体而言,这项优化使得 ZooKeeper 的 SLA 提升了一个数量级。
ZooKeeper 有许多配置选项,但大部分情况下不需要调整。为提升系统稳定性,建议进行以下配置优化:
- 将 dataDir(数据目录)和 dataLogDir(事务日志目录)分别挂载到不同的磁盘上,并使用高性能的块存储。
- 对于 ZooKeeper 3.8 版本,建议使用 JDK 17 并启用 ZGC 垃圾回收器;而对于 3.5 和 3.6 版本,可使用 JDK 8 并启用 G1 垃圾回收器。针对这些版本,只需要简单配置 -Xms 和 -Xmx 即可。
- 将 SnapshotCount 参数默认值 100,000 调整为 500,000,这样可以在高频率 ZNode 变动时显著降低磁盘压力。
- 使用优化版的 Watch 管理器 WatchManagerOptimized。
本文为阿里云原创内容,未经允许不得转载。
高中生自创开源编程语言作为成人礼——网友锐评:依托答辩 Apple 发布 M4 芯片 RustDesk 由于诈骗猖獗,暂停国内服务 云风从阿里离职,未来计划制作 Windows 平台的独立游戏 淘宝 (taobao.com) 重启网页版优化工作 程序员的归宿 Visual Studio Code 1.89 发布 Java 17 是最常用的 Java LTS 版本 Windows 10 市场份额达 70%,Windows 11 持续下滑 开源日报 | 谷歌扶持鸿蒙上位;开源Rabbit R1;Docker加持的安卓手机;微软的焦虑和野心;海尔电器把开放平台关了